Posted by Sam on Jan 14, 2008 at 06:42 AM UTC - 5 hrs
This is a story about my journey as a programmer, the major highs and lows I've had along the way, and
how this post came to be. It's not about how ecstasy made me a better programmer, so I apologize if that's why you came.
In any case, we'll start at the end, jump to
the beginning, and move along back to today. It's long, but I hope the read is as rewarding as the write.
A while back,
Reg Braithwaite
challenged programing bloggers with three posts he'd love to read (and one that he wouldn't). I loved
the idea so much that I've been thinking about all my experiences as a programmer off and on for the
last several months, trying to find the links between what I learned from certain languages that made
me a better programmer in others, and how they made me better overall. That's how this post came to be.
More...
The experiences discussed herein were valuable in their own right, but the challenge itself is rewarding
as well. How often do we pause to reflect on what we've learned, and more importantly, how it has changed
us? Because of that, I recommend you perform the exercise as well.
I freely admit that some of this isn't necessarily caused by my experiences with the language alone - but
instead shaped by the languages and my experiences surrounding the times.
One last bit of administrata: Some of these memories are over a decade old, and therefore may bleed together
and/or be unfactual. Please forgive the minor errors due to memory loss.
How QBASIC Made Me A Programmer
As I've said before, from the time I was very young, I had an interest in making games.
I was enamored with my Atari 2600, and then later the NES.
I also enjoyed a playground game with Donald Duck
and Spelunker.
Before I was 10, I had a notepad with designs for my as-yet-unreleased blockbuster of a side-scrolling game that would run on
my very own Super Sanola game console (I had the shell designed, not the electronics).
It was that intense interest in how to make a game that led me to inspect some of the source code Microsoft
provided with QBASIC. After learning PRINT, INPUT,
IF..THEN, and GOTO (and of course SomeLabel: to go to)
I was ready to take a shot at my first text-based adventure game.
The game wasn't all that big - consisting of a few rooms, the NEWS
directions, swinging of a sword against a few monsters, and keeping track of treasure and stats for everything -
but it was a complete mess.
The experience with QBASIC taught me that, for any given program of sufficient complexity, you really only
need three to four language constructs:
- Input
- Output
- Conditional statements
- Control structures
Even the control structures may not be necessary there. Why? Suppose you know a set of operations will
be performed an unknown but arbitrary amount of times. Suppose also that it will
be performed less than X number of times, where X is a known quantity smaller than infinity. Then you
can simply write out X number of conditionals to cover all the cases. Not efficient, but not a requirement
either.
Unfortunately, that experience and its lesson stuck with me for a while. (Hence, the title of this weblog.)
Side Note: The number of language constructs I mentioned that are necessary is not from a scientific
source - just from the top of my head at the time I wrote it. If I'm wrong on the amount (be it too high or too low), I always appreciate corrections in the comments.
What ANSI Art taught me about programming
When I started making ANSI art, I was unaware
of TheDraw. Instead, I opened up those .ans files I
enjoyed looking at so much in MS-DOS Editor to
see how it was done. A bunch of escape codes and blocks
came together to produce a thing of visual beauty.

Since all I knew about were the escape codes and the blocks (alt-177, 178, 219-223 mostly), naturally
I used the MS-DOS Editor to create my own art. The limitations of the medium were
strangling, but that was what made it fun.
And I'm sure you can imagine the pain - worse than programming in an assembly language (at least for relatively
small programs).
Nevertheless, the experience taught me some valuable lessons:
- Even though we value people over tools, don't underestimate
the value of a good tool. In fact, when attempting anything new to you, see if there's a tool that can
help you. Back then, I was on local BBSs, and not
the 1337 ones when I first started out. Now, the Internet is ubiquitous. We don't have an excuse anymore.
-
I can now navigate through really bad code (and code that is limited by the language)
a bit easier than I might otherwise have been able to do. I might have to do some experimenting to see what the symbols mean,
but I imagine everyone would.
And to be fair, I'm sure years of personally producing such crapcode also has
something to do with my navigation abilities.
-
Perhaps most importantly, it taught me the value of working in small chunks and
taking baby steps.
When you can't see the result of what you're doing, you've got to constantly check the results
of the latest change, and most software systems are like that. Moreover, when you encounter
something unexpected, an effective approach is to isolate the problem by isolating the
code. In doing so, you can reproduce the problem and problem area, making the fix much
easier.
The Middle Years (included for completeness' sake)
The middle years included exposure to Turbo Pascal,
MASM, C, and C++, and some small experiences in other places as well. Although I learned many lessons,
there are far too many to list here, and most are so small as to not be significant on their own.
Therefore, they are uninteresting for the purposes of this post.
However, there were two lessons I learned from this time (but not during) that are significant:
-
Learn to compile your own $&*@%# programs
(or, learn to fish instead of asking for them).
-
Stop being an arrogant know-it-all prick and admit you know nothing.
As you can tell, I was quite the cowboy coding young buck. I've tried to change that in recent years.
How ColdFusion made me a better programmer when I use Java
Although I've written a ton of bad code in ColdFusion, I've also written a couple of good lines
here and there. I came into ColdFusion with the experiences I've related above this, and my early times
with it definitely illustrate that fact. I cared nothing for small files, knew nothing of abstraction,
and horrendous god-files were created as a result.
If you're a fan of Italian food, looking through my code would make your mouth water.
DRY principle?
Forget about it. I still thought code reuse meant copy and paste.
Still, ColdFusion taught me one important aspect that got me started on the path to
Object Oriented Enlightenment:
Database access shouldn't require several lines of boilerplate code to execute one line of SQL.
Because of my experience with ColdFusion, I wrote my first reusable class in Java that took the boilerplating away, let me instantiate a single object,
and use it for queries.
How Java taught me to write better programs in Ruby, C#, CF and others
It was around the time I started using Java quite a bit that I discovered Uncle Bob's Principles of OOD,
so much of the improvement here is only indirectly related to Java.
Sure, I had heard about object oriented programming, but either I shrugged it off ("who needs that?") or
didn't "get" it (or more likely, a combination of both).
Whatever it was, it took a couple of years of revisiting my own crapcode in ColdFusion and Java as a "professional"
to tip me over the edge. I had to find a better way: Grad school here I come!
The better way was to find a new career. I was going to enter as a Political Scientist
and drop programming altogether. I had seemingly lost all passion for the subject.
Fortunately for me now, the political science department wasn't accepting Spring entrance, so I decide to
at least get started in computer science. Even more luckily, that first semester
Venkat introduced me to the solution to many my problems,
and got me excited about programming again.
I was using Java fairly heavily during all this time, so learning the principles behind OO in depth and
in Java allowed me to extrapolate that for use in other languages.
I focused on principles, not recipes.
On top of it all, Java taught me about unit testing with
JUnit. Now, the first thing I look for when evaluating a language
is a unit testing framework.
What Ruby taught me that the others didn't
My experience with Ruby over the last year or so has been invaluable. In particular, there are four
lessons I've taken (or am in the process of taking):
-
The importance of code as data, or higher-order functions, or first-order functions, or blocks or
closures: After learning how to appropriately use
yield, I really miss it when I'm
using a language where it's lacking.
-
There is value in viewing programming as the construction of lanugages, and DSLs are useful
tools to have in your toolbox.
-
Metaprogramming is OK. Before Ruby, I used metaprogramming very sparingly. Part of that is because
I didn't understand it, and the other part is I didn't take the time to understand it because I
had heard how slow it can make your programs.
Needless to say, after seeing it in action in Ruby, I started using those features more extensively
everywhere else. After seeing Rails, I very rarely write queries in ColdFusion - instead, I've
got a component that takes care of it for me.
-
Because of my interests in Java and Ruby, I've recently started browsing JRuby's source code
and issue tracker.
I'm not yet able to put into words what I'm learning, but that time will come with
some more experience. In any case, I can't imagine that I'll learn nothing from the likes of
Charlie Nutter, Ola Bini,
Thomas Enebo, and others. Can you?
What's next?
Missing from my experience has been a functional language. Sure, I had a tiny bit of Lisp in college, but
not enough to say I got anything out of it. So this year, I'm going to do something useful and not useful
in Erlang. Perhaps next I'll go for Lisp. We'll see where time takes me after that.
That's been my journey. What's yours been like?
Now that I've written that post, I have a request for a post I'd like to see:
What have you learned from a non-programming-related discipline that's made you a better programmer?
Hey! Why don't you make your life easier and subscribe to the full post
or short blurb RSS feed? I'm so confident you'll love my smelly pasta plate
wisdom that I'm offering a no-strings-attached, lifetime money back guarantee!
Last modified on Jan 16, 2008 at 07:09 AM UTC - 5 hrs
Posted by Sam on Nov 22, 2007 at 12:04 PM UTC - 5 hrs
Since the gift buying season is officially upon us, I thought I'd pitch in to the rampant consumerism and list some of the toys I've had a chance to play with this year that would mean fun and learning for the programmer in your life. Plus, the thought of it sounded fun.
Here they are, in no particular order other than the one in which I thought of them this morning:
More...
- JetBrains' IntelliJ IDEA: An awesome IDE for Java. So great, I don't mind spending the $249 (US) and using it over the free Eclipse. The Ruby plugin is not too shabby either, the license for your copy is good for your OSX and Windows installations, and you can try it free for 30 days. Martin Fowler thinks IntelliJ changed the IDE landscape. If you work in .NET, they also have ReSharper, which I plan to purchase very soon. Now if only we could get a ColdFusion plugin for IntelliJ, I'd love it even more.
- Programming Ruby, Second Edition: What many in the Ruby community consider to be Ruby's Bible. You can lower the barrier of entry for your favorite programmer to using Ruby, certainly one of the funner languages a lot of people are loving to program in lately. Sometimes, I sit and think about things to program just so I can do it in Ruby.
If they've already got that, I always like books as gifts. Some of my
favorites from this year have been: Code Complete 2, Agile Software Development: Principles, Patterns, and Practices which has a great section on object oriented design principles, and of course,
My Job Went to India.
I have a slew of books I've yet to read this year that I got from last Christmas (and birthday), so I'll have to
list those next year.
-
Xbox 360 and a subscription to
XNA Creator's Club (through Xbox Live Marketplace - $99 anually) so they can deploy their games to their new Xbox. This is without a
doubt the thing I'd want most, since I got into this whole programming thing because I was interested
in making games. You can point them to the
getting started page, and they could
make games for the PC for free, using XNA (they'll need that page to get started anyway, even if you
get them the 360 and Creator's Club membership to deploy to the Xbox).
-
MacBook Pro and pay for the extra pixels. I love mine - so much so,
that I intend to marry it. (Ok, not that much, but I have
been enjoying it.)
The extra pixels make the screen almost as wide as two, and if you can get them an extra monitor I'd do
that too. I've moved over to using this as my sole computer for development, and don't bother with
the desktops at work or home anymore, except on rare occasions. You can run Windows on it, and the
virtual machines are getting really good so that you ought not have to even reboot to use either
operating system.
Even if you don't want to get them the MacBook, a second or third monitor should be met with enthusiasm.
-
A Vacation: Programmers are notoriously working long hours
and suffering burnout, so we often need to take a little break from the computer screen. I like
SkyAuction because all the vacations are package deals, there's often a good variety to choose from (many
different countries), most of the time you can find a very good price, and usually the dates are flexible
within a certain time frame, so you don't have to commit right away to a certain date.
Happy Thanksgiving to those celebrating it, and thanks to all you who read and comment and set me straight when I'm wrong - not just here but in the community at large. I do appreciate it.
Do you have any ideas you'd like to share (or ones you'd like to strike from this list)?
Last modified on Nov 22, 2007 at 12:04 PM UTC - 5 hrs
Posted by Sam on Oct 31, 2007 at 04:26 PM UTC - 5 hrs
When looping over collections, you might find yourself needing elements that match only a certain
parameter, rather than all of the elements in the collection. How often do you see something like this?
foreach(x in a)
if(x < 10)
doSomething;
Of course, it can get worse, turning
into arrow code.
More...
What we really need here is a way to filter the collection while looping over it. Move that extra
complexity and indentation out of our code, and have the collection handle it.
In Ruby we have each
as a way to loop over collections. In C# we have foreach, Java's got
for(ElemType elem : theCollection), and Coldfusion has <cfloop collection="#theCollection#">
and the equivalent over arrays. But wouldn't it be nice to have an each_where(condition) { block; } or
foreach(ElemType elem in Collection.where(condition))?
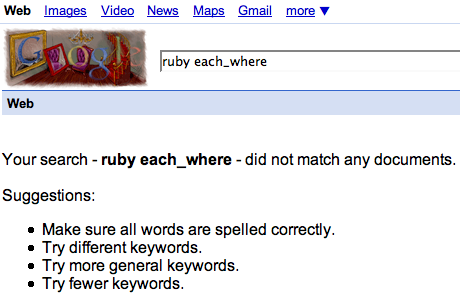
I thought for sure someone would have implemented it in Ruby, so I was surprised at first to see this in my
search results:
However, after a little thought, I realized it's not all that surprising: it is already incredibily easy to filter
a collection in Ruby using the select method.
But what about the other languages? I must confess - I didn't think long and hard about it for Java or C#.
We could implement our own collections such that they have a where method that returns the subset we are
looking for, but to be truly useful we'd need the languages' collections to implement where
as well.
Of these four languages, ColdFusion provides both the need and opportunity, so I gave it a shot.
First, I set up a collection we can use to exercise the code:
<cfset beer = arrayNew(1)>
<cfset beer[1] = structNew()>
<cfset beer[1].name = "Guiness">
<cfset beer[1].flavor = "full">
<cfset beer[2] = structNew()>
<cfset beer[2].name = "Bud Light">
<cfset beer[2].flavor = "water">
<cfset beer[3] = structNew()>
<cfset beer[3].name = "Bass">
<cfset beer[3].flavor = "medium">
<cfset beer[4] = structNew()>
<cfset beer[4].name = "Newcastle">
<cfset beer[4].flavor = "full">
<cfset beer[5] = structNew()>
<cfset beer[5].name = "Natural Light">
<cfset beer[5].flavor = "water">
<cfset beer[6] = structNew()>
<cfset beer[6].name = "Boddington's">
<cfset beer[6].flavor = "medium">
Then, I exercised it:
<cfset daytypes = ["hot", "cold", "mild"]>
<cfset daytype = daytypes[randrange(1,3)]>
<cfif daytype is "hot">
<cfset weWantFlavor = "water">
<cfelseif daytype is "cold">
<cfset weWantFlavor = "full">
<cfelse>
<cfset weWantFlavor = "medium">
</cfif>
<cfoutput>
Flavor we want: #weWantFlavor#<br/><br/>
Beers with that flavor: <br/>
<cf_loop collection="#beer#" item="aBeer" where="flavor=#weWantFlavor#">
#aBeer.name#<br/>
</cf_loop>
</cfoutput>
Obviously, that breaks because don't have a cf_loop tag. So, let's create one:
<!--- loop.cfm --->
<cfparam name="attributes.collection">
<cfparam name="attributes.where" default = "">
<cfparam name="attributes.item">
<cfif thistag.ExecutionMode is "start">
<cfparam name="isDone" default="false">
<cfparam name="index" default="1">
<cffunction name="_getNextMatch">
<cfargument name="arr">
<cfloop from="#index#" to="#arrayLen(arr)#" index="i">
<cfset keyValue = attributes.where.split("=")>
<cfset index=i>
<cfif arr[i][keyValue[1]] is keyValue[2]>
<cfreturn arr[i]>
</cfif>
</cfloop>
<cfset index = arrayLen(arr) + 1>
<cfexit method="exittag">
</cffunction>
<cfset "caller.#attributes.item#" = _getNextMatch(attributes.collection,index)>
</cfif>
<cfif thistag.ExecutionMode is "end">
<cfset index=index+1>
<cfset "caller.#attributes.item#" = _getNextMatch(attributes.collection,index)>
<cfif index gt arrayLen(attributes.collection)>
<cfset isDone=true>
</cfif>
<cfif not isDone>
<cfexit method="loop">
<cfelse>
<cfexit method="exittag">
</cfif>
</cfif>
It works fine for me, but you might want to implement it differently. The particular area of improvement I
see right away would be to utilize the item name in the where attribute. That way,
you can use this on simple arrays and not just assume arrays of structs.
Thoughts anybody?
Last modified on Oct 31, 2007 at 04:29 PM UTC - 5 hrs
Posted by Sam on Sep 25, 2007 at 06:39 AM UTC - 5 hrs
The last bit of advice from Chad Fowler's 52 ways to save your job was to be a generalist, so this week's version is the obvious opposite: to be a specialist.
The intersection point between the two seemingly disparate pieces of advice is that you shouldn't use your lack of experience in multiple technologies to call yourself a specialist in another. Just because you
develop in Java to the exclusion of .NET (or anything else) doesn't make you a Java specialist. To call yourself that,
you need to be "the authority" on all things Java.
More...
Chad mentions a measure he used to assess a job candidate's depth of knowledge in Java: a question of how to make the JVM crash.
I'm definitely lacking in this regard. I've got a pretty good handle on Java, Ruby, and ColdFusion. I've done a small amount of work in .NET and have been adding to that recently. I can certainly write a program that will crash - but can I write one to crash the virtual
machine (or CLR)?
I can relunctantly write small programs in C/C++, but I'm unlikely to have the patience to trace through a large program for fun. I might even still be able to figure out some assembly language if you gave me enough time. Certainly in these lower level items it's not hard to find a way to crash. It's
probably harder to avoid it, in fact.
In ColdFusion, I've crashed the CF Server by simply writing recursive templates (those that cfinclude themselves). (However, I don't know if that still works.) In Java and .NET, I wouldn't know where to start. What about crashing a browser with JavaScript?
So Chad mentions that you should know the internals of JVM and CLR. I should know how JavaScript works in the browser and not just how to getElementById(). With that in mind, these things are going on the to-learn list - the goal being to find a way to crash each of them.
Ideas?
Last modified on Sep 25, 2007 at 06:41 AM UTC - 5 hrs
Posted by Sam on Sep 12, 2007 at 07:11 AM UTC - 5 hrs
This morning ColdFusion got another mention on InfoQ, the news source for all things new and hip (or at least not normally dead and dying). The first time I saw it there was back in the summer.
I wonder if, with the new missing method handler allowing you to write even more dynamic code, and its ability to inter-operate so well with both Java and .NET, we might see a resurgence into more mainstream waters. I'd still like to see better cfscripting options available though (more than can be provided with scriptaGulous).
Posted by Sam on Aug 23, 2007 at 09:16 PM UTC - 5 hrs
The next few days in Houston are busy for programming technophiles. A couple of quick reminders:
BarCampHouston 2 is this Saturday, August 25, 2007 beginning at 9:00 AM at Houston Technology Center.
Update: I had the map wrong since it was wrong on the BarCampHouston wiki page. I hope no one went to the wrong place. Here is the correct one: HTC.
I also decided to take the day off and chill out instead of heading up there.
My apologies to anyone who had planned to say hello!
HouCFUG is hosting a ColdFusion 8 release party on Tuesday, August 28 from noon to 1:00 PM at Ziggy's Healthy Grill where they'll be giving away a licensed copy of CF 8.
Finally, Agile Houston is hosting a session with Robert Martin, object mentor on Tuesday as well. It's at 6:30 PM in PGH 563 on the University of Houston Campus.
I should be at both BarCamp and at Robert's presentation, but I'll be in class during HouCFUG's meeting.
Last modified on Aug 25, 2007 at 09:28 AM UTC - 5 hrs
Posted by Sam on Jul 19, 2007 at 10:26 AM UTC - 5 hrs
In the past you used to give and receive advice that keeping form state in a session was a valid way to approach the problem of forms that span several pages. It's no longer sound advice, and it hasn't been for a while.
Even before tabs became popular, a few of us were right-clicking links and opening-in-new-windows. It's a nice way to get more things done quicker: loading another page while waiting for the first one to load so that you are doing something all the time, rather than spending a significant amount of time waiting. It even works well in web applications - not just general surfing.
More...
But back then, and even until relatively recently when tabs were confined to the realm outside of Internet Explorer, the amount of people who used the approach in web applications was small. So small, in fact, we felt we could be lazy and hold what should have been repeated as hidden form fields within sessions instead.
Now Internet Explorer has tabs, and people are starting to use them. That changes things as people start to internalize the concept and use the productivity-boosting feature in ways that break our applications. Now, instead of presenting a list of customers and expecting our user to click one and edit the associated records until he's complete; our users are opening three or four customers (customerA through customerD) at a time in separate tabs. If you had stored form state in the session, when they think they are editing customerA, they will in fact be changing the record for customerD with a form that is pre-filled with values from customerA. Oops.
Luckily, the fix is relatively easy: just start storing the state in the form instead of the session. Of course, that's only "easy" if the path through your forms is linear. What about the case where many different forms can be traversed in just about any order, sometimes they appear based on what other forms said, and some are required while others can be skipped?
It's still easy if you've got automated tests that cover the possible scenarios. Just strip out the session and add the data to the forms until the tests pass. If you don't have tests, and you are not familiar enough with the different paths to create 100% coverage (or its been so long you forgot the paths), it's not looking good for you. Chances are, you don't have tests. This is a relic from the days before tabbed browsing, and who was doing automated testing then?
But, there is still one way out for you: inject the needed fields into your form after it's been crested but before it has been sent to the browser. I've not yet come across a situation in Rails or Javaland where I needed to do this, so I haven't investigated how to do it there (and Rails is new in the first place, so its unlikely it would be a problem in any application if you've thought to avoid the practice now that tabbed browsing is popular). But in ColdFusion, it is easy. Since Application.cfm is run before the request, you can check what page is being requested from there and intercept it if the page is one on which you need to do this processing. Wrap a cfinclude of that page in cfsavecontent tags, and now you have a string of what will be sent to the browser. Just find the spot you need to insert your data, insert it, and output the resultant string to the browser.
In my case it was especially easy because fortunately, we were only storing the id of the record in the session and I could be sure it needed to be in every form on the page. Thus, my code looked like this (in Application.cfm):
<cfif cgi.script_name is inMyListOfScriptsToIntercept>
<cfsavecontent variable = "toBeOutput">
<cfinclude template = "#cgi.script_name#">
</cfsavecontent>
<cfset toBeOutput = replaceNoCase(toBeOutput,"</form>","<input type="hidden" name="id" value="#form.id#" ></form>,"all")>
</cfif>
If you can get at the data before it is output to the browser, this strategy works well. However, I don't like the magic nature of it when you'll be editing the individual files later and wondering why in the world it works. It's only a hack, so expect to learn the application well enough to test it and put the right fix in later. But, this works well as a temporary solution as you can be more sure it works than you can be sure about the flow of the application when it gets quite complex.
Posted by Sam on Jul 13, 2007 at 09:22 AM UTC - 5 hrs
Software Developer has an article, Ghosts in the Machine: 12 Coding Languages that Never Took Off that spotlights twelve of many thousands of languages that never made it big. Some had potential, others were doomed to begin with.
ColdFusion makes the list. So do Haskell, Delphi, and PowerBuilder.
I don't know that I disagree with the assessment based on the thought that "the vast majority of us all use the same dozen or so."
What do you think of the list? I was surprised to see those four languages included with some of the others, but at the same time you still have to ask, have they made it? And if they did make it, are they still there?
(via Venkat)
Posted by Sam on Jul 01, 2007 at 09:25 PM UTC - 5 hrs
Let me start out by saying the NFJS conference was incredible!
I went in with the intention of blogging as the sessions and days went on, but I was incredibly busy, and felt like my notes didn't do justice to the presentations. So I'm going to review the slides and flesh out my comments, and hopefully do a good job at letting you know what went down.
More...
For this post, I just wanted to give an overview of the symposium in general. As soon as I walked in and found my name badge, I knew these guys were a seriously professional conference, and they would pay attention to the small details to make our experience great.
Why? The badge was inside a nice, hard plastic (think something you might store a baseball card in, but bigger) and worn around a neck clip - the kind you used to see people wearing to hold their keys around their necks. But that wasn't the impressive part - the most impressive was that they put the schedule inside too, upside down on the back side, so all you had to do was flip over the badge and you could read the schedule and room assignments easily.
We also got a nice laptop backpack, a leather notebook where we could store pre-printed slides and code samples from the sessions we attended, as well as a CD with all the presentation material from every session.
Now, that's all useful for going back and having something to reference, but it's also great to have so you can flip through and see a good overview of sessions before you attend, so you know if it will be valuable for you.
The rooms were outstanding. We stayed in the Marriott Austin Airport South. I got the feeling the hotel staff greatly appreciated us being there - I got even better service from them than I normally expect from Marriott. Now, I'm not sure of the weekend rates there, but Thursday they wanted 200 dollars (US), and Sunday they wanted $189 (if I recall correctly). But NFJS was able to negotiate $99 rooms for us for Friday and Saturday. It was certainly nice to get such great service at such a bargain. Of course, it would have been even nicer if the hotel provided free wireless Internet access. NFJS provided it in the conference rooms, but that didn't reach all the way up to our rooms. I'm getting free wireless next door in another Marriott-owned hotel for over 100 dollars less than I would be paying at Marriott proper tonight!
The food was amazing as well. Just good all-around, and even included options for vegetarians that didn't include side-dishes only. I was fairly impressed by that. Also, I think the hotel bar is the cheapest bar in Austin. =)
Everything went extremely smooth from what I could tell. Jay Zimmerman and any other staff (including the hotel) did an excellent job of ensuring that. Oh yeah (read: "most importantly"), the speakers were awesome. They really knew how to entertain and be informative. But, for being a Java-based conference, it was interesting (exciting?) to see how many bashes Java got - and not just from the speakers. I'll probably blog some funny quotes later.
The first night most of the speakers made themselves available (aside from in-between sessions) at the hotel bar. I had dinner with a friend of mine (who I didn't know was going to be there) and Scott Davis, who is an amazingly charismatic guy. The second night a lot of people went to Bruce Tate's house. Someone later told me the group I was hanging out with in the dynamic languages BOF had been invited, but by that time we didn't feel like going to crash the party (not to mention a second-hand invite of "I heard" isn't that strong a thing to go on in the first place).
Also, one of the presenters had Sean Corfield's blog on his bookmarks toolbar, so that was exciting to see (I'll have to go through my notes to remember who).
In any case, I've got tons of sessions to blog about, some of which may contain useful information for you. I'm staying another night in Austin so I won't start tonight (other than this one), but keep a look out for more detailed posts about the actual content of the conference in the coming days.
PS: I'm also looking forward to catching up with all the other blogs and seeing how CFUnited went. But if I see one more post about the iPhone I'm going to have to duct-tape my head like a mummy gets wrapped to avoid exploding.
Last modified on Jul 01, 2007 at 09:30 PM UTC - 5 hrs
Posted by Sam on Jun 26, 2007 at 09:09 AM UTC - 5 hrs
I ran into a couple of stumbling blocks today using a particular company's XML request API, and it made me wonder about the restrictions we put in our software that have no apparent reason.
My plan was simple: create a struct/hash/associative array that matches the structure of the XML document, run it through a 10-line or so function that translates that to XML, and send the data to the service provider. Simple enough - my code doesn't even need to know the structure - the programmer using it would provide that, and the service provider doubles as the validator! My code was almost the perfect code. It did almost nothing, and certainly nothing more than it was meant or needed to do.
But alas, it was not meant to be. Instead, the service provider has a couple of restrictions:
More...
The first was regarding case (as in upper/lower). The XML elements needed to have the same case as described in the documentation (which contained at least one element that wasn't in the real specification anyway). That's fine - I can live with that. But it annoyed me a little that they saw fit to use camelCase. (this is only a machine, after all. I don't think it cares if it can easily read the differentWordsAllBunchedUpTogether.)
At least if they had chosen all upper or all lower I can easily switch the case of my own, but requiring camelCase made my code quite a bit nastier than it needed to be. Now, I have to provide a lookup mechanism for each element in the XML. Of course, if the language I was using was case sensitive, this wouldn't be a big deal at all. However, even though it is not sensitive to case, this is still not that bad of an issue.
But then restriction number two comes along: all elements must be sent in the order they appear in the specification. We're just passing data around here. The XML describes the data in the first place, so what use is ordering it? I understand that parent/child relationships must remain intact, but I cannot see how there could possibly be a good reason that the "firstName" element should come before the "lastName" element. (Can you? I'd love to know!) Why don't we just go to a flat file and forget about the angled brackets altogether?
I might as well have just hard-coded the XML and had a variable for every element/attribute!
Posted by Sam on Jun 21, 2007 at 02:55 PM UTC - 5 hrs
Today I was writing this simple function to recursively create XML based on a struct, and ran into
a minor gotcha:
More...
<cfcomponent>
<cfscript>
function structToXML(struct)
{
var result = "";
for (item in struct)
{
if(not isStruct(struct[item]))
result = result & "<#item#>#struct[item]#</#item#>";
else
result = result & "<#item#>" & structToXML(struct[item]) & "</#item#>";
}
return result;
}
</cfscript>
</cfcomponent>
Can you spot the problem? Its easy to miss: I forgot to var my loop variable, item. I normally remember to put most variables in the var scope, but I often forget to do so when variables are being defined in or by a tag, or in a loop. Things like item, index, and query names. So I spent some time trying to figure out why ColdFusion's stack didn't seem to be working properly: instead of closing the tag with the correct element name, it was closing it with the last used one on recursive calls.
I was about to ask if anyone could help me spot the flaw in my logic when it hit me - the var scope!
Posted by Sam on Jun 21, 2007 at 12:19 PM UTC - 5 hrs
I thought I had read this somewhere, about not being able to use " cf" as a prefix to a function, but when I defined all those functions in scriptaGulous with that prefix, and it let me, I thought maybe I made the whole thing up.
But then today I was having a look through the docs for cfscript, and I found this:
Caution: ... You cannot put a user-defined function whose name begins with any of these strings within this tag:
-
cf
-
cf_
-
_cf
-
coldfusion
-
coldfusion_
-
_coldfusion
However, so far it has let me with no problems. What shall be done?
Posted by Sam on Jun 21, 2007 at 09:11 AM UTC - 5 hrs
Bruce Eckel posted an article on how to use Flex with a Python back end over at Artima.
He said its possible to do the same thing "with any language that has support for creating an XML-RPC server."
In any case, I'm going to look into this in the future (I still haven't hopped onto the bandwagon). Anyone else played with it? What has been your experience?
Posted by Sam on Jun 18, 2007 at 02:50 PM UTC - 5 hrs
This one refers to the 40+ minute presentation by Obie Fernandez on Agile DSL Development in Ruby. (Is InfoQ not one of the greatest resources ever?)
You should really view the video for better details, but I'll give a little rundown of the talk here.
Obie starts out talking about how you should design the language first with the domain expert, constantly refining it until it is good - and only then should you worry about implementing it (this is about the same procedure you'd follow if you were building an expert system as well). That's where most of the Agility comes into play.
More...
Later, he moves on to describe four different types of design for your DSL. This was something I hadn't really thought about before, therefore it was the most interesting for me. Here are the four types:
- Instantiation: The DSL consists simply of methods on an object. This is not much different from normal programming. He says it is "DSLish," perhaps the way Blaine Buxton looks at it.
- Class Macros: DSL as methods on some ancestor class, and subclasses can then use those methods to tweak the behavior of themselves and their subclasses. This follows a declarative style of programming, and is the type of DSL followed by Ruby on Rails (and cfrails) if I understand him correctly.
- Top-level methods: Your application defines the DSL as a set of top-level methods, and then invokes
load with the path to your DSL script. When those methods are called in the configuration file, they modify some central (typically global) data, which your application uses to determine how it should execute. This is like scripting, and (again) if I understood correctly, this is the style my (almost working correctly) Partial Order Planner uses.
- Sandboxing (aka Contexts): Similar to the Instantiation style, but with more magic. Your DSL is defined as methods of some object, but that object is really just a "sandbox." Interaction with the object's methods modifies some state in the sandbox, which is then queried by the application. This is useful for processing user-maintained scripts kept in a database, and you can vary the behavior by changing the execution context.
Note: These are "almost" quotes from the slides/talk (with a couple of comments by myself), but I didn't want to keep rewinding and such, so they aren't exact. Therefore, I'm giving him credit for the good stuff, but I stake a claim on any mistakes made.
The talk uses Ruby as the implementation language for the example internal DSLs, but I think the four types mentioned above can be generalized. At the least, they are possible in ColdFusion - but with Java, I'm not so sure. In particular, I think you'd need mixin ability for the Top-level methods style of DSL.
Next, Obie catalogs some of the features of Ruby you see used quite often in crafting DSLs: Symbols (because they have less noise than strings), Blocks (for delayed evaluation of code), Modules (for cleaner separation of code), Splats (for parameter arrays), the different types of eval (for dynamic evaluation), and define_method and alias_method.
Finally, he winds up the presentation with a bit about BNL. I liked this part because I found Jay Fields' blog and his series of articles about BNL.
As always, comments, questions, and thoughts are appreciated. Flames - not so much.
Posted by Sam on Jun 15, 2007 at 09:18 PM UTC - 5 hrs
Sean Corfield responded in some depth to " Is Rails easy?", and explained what I wish I could have when I said (awkwardly, rereading it now) "I think my cat probably couldn't [code a Rails app]."
Sean makes it quite clear (as did Venkat's original post) that it isn't that using a framework, technology, or tool in general is easy or hard (although, you can certainly do things to make it easier or harder to use). In many cases, what it does for you is easy to begin with - in the case of Rails, it is stuff you do all the time that amounts to time-wasting, repetitive, boring busy-work. Rather, the right way to look at them is that they are tools that make you more productive, and it takes a while to learn to use them.
If you go into them thinking they are easy, you're likely to be disappointed and drop a tool that can really save you time before you learn to use it. And that could be tragic, if you value your time.
Posted by Sam on Jun 15, 2007 at 01:43 PM UTC - 5 hrs
I never thought to do this before today, but all of the sudden I had this idea that it would be nice to have a variety of utility methods for every object. I'm talking about things like respondsTo(methodName), to see if a component has a certain method public, or inspect() as an object oriented way to do getMetaData(object), and just things in general that all objects should be able to do to or for themselves.
Rather than creating a class which would be the equivalent of BaseClassToBeExtendedManuallyByAllOtherClasses, I decided I'd like to just replace component.cfc in the CF7 install. As it happened, the component.cfc that was there (CFusionMX7/wwwroot/WEB-INF/cftags) was a 0 byte file. I just added my code for respondsTo(methodName):
More...
<cfcomponent>
<cffunction name="respondsTo" access="public">
<cfargument name="methodName">
<cfset var result = false>
<cfif structKeyExists(this, methodName) and isCustomFunction(this[methodName])>
<cfset result = true>
</cfif>
<cfreturn result>
</cffunction>
</cfcomponent>
And it worked. No fuss or anything.
Is anyone else doing this? What sorts of object methods have you added? What would you find useful if you had the stomach to do this?
Posted by Sam on Jun 12, 2007 at 04:43 PM UTC - 5 hrs
It's been a couple of months, but cfrails has been "officially" updated (as in, I released a new zip, not just put new code into the repository).
We're a lot closer to 1.0 than one quarter of the way, so soon you should be seeing higher version number jumps. Anyway, here's what's been updated with this release:
More...
-
Added the automatic include of views/layouts/application_header.cfm and views/layouts/application_footer.cfm even when using view CFC (formerly, this only happened if you instructed it to and using .cfm templates for views). Also added auto-include of controller-specific templates simply by placing controllerName_header.cfm and controllerName_footer.cfm in views/layouts.
-
Brought the existing unit tests up to date (amazingly, with all the neglect there was only a couple of very minor problems, mostly due to changing paths).
-
Migrated request processing out of individual applications and into Dispatcher.cfc. This is a major improvement in the DRY arena, and allows me to make changes to the ways requests are processed without having to make them to every application that uses cfrails (Thanks to Dan Lancelot for prodding me to do this a couple of months back).
-
Added some minor Spry integration for form validation - this only works with required text fields at the moment.
-
Added the ability to use primary keys that aren't named "id" (although, still no composite PK support)
-
Changed behavior of a particular file to not catch errors (it was getting hard to debug)
-
Added an onchange attribute for form elements (can edit onchange per column without writing out the entire form)
-
cfrails now automatically creates blank controller, model, and view cfcs if you request one where it doesn't exist. This just makes it easier to develop, and may end up being a setting you turn on and off.
-
Added validations where you can specify a function to call and a message to display upon failure for validating forms (as opposed to simply using the built-in autovalidation based on DBMS metadata).
-
Added support for bigint, tinyint, and smalldatetime data types.
-
Added the ability to call a function when outputting a column in a list (though complete closures are not yet fully integrated)
So, there was a lot done as you can tell. And, MySQL support is coming soon, I promise!
Update: Oh yeah, I forgot what might be the most important part: New, more complete docs on cfrails are available (thanks to cfcdoc).
Last modified on Jun 12, 2007 at 04:47 PM UTC - 5 hrs
Posted by Sam on Jun 07, 2007 at 12:20 PM UTC - 5 hrs
Timothy Farrar brought up an issue about scriptaGulous that I thought was a good one (and one I've worried a bit about).
Should people start using the scriptaGulous library and Adobe decides to start naming functions after tags (i.e., cfQuery()), then a lot of code will break unless they start honoring your functions over theirs instead of throwing errors, as is currently the case.
He suggested using an underscore convention ( _cfQuery(), and Andrew Powell proposed a tagFunctionName() style convention.
But what are the odds Adobe would start naming functions cfTagName()? Any idea from the guys over there would be appreciated, as well as anyone else with any input. Would tagFunctionName() as opposed to cfFunctionName() (or tagQuery() over cfQuery()) work better? I'm partial to the underscore method if it is needed, but obviously I prefer just simple tagName() the most.
What are your thoughts?
Posted by Sam on Jun 04, 2007 at 09:23 AM UTC - 5 hrs
First I wanted to thank Andrew Powell for his gracious offer to help on this project.
Then, the update:
The ScriptaGulous RIAForge page (as does the SVN repository) has a zip with a file that actually compiles now, so you can start using it in your projects.
There are a couple of tags that were removed, such as cfloop and cfoutput, where it doesn't make sense to have them (unless we decide to use closures). Some tags, such as cfmail and cfhttp include extra parameters for their respective "params." The general guideline followed is that it is an array of structs - each struct is full of name/value pairs that represent the param tag's attributes and values you want to give those attributes. Please have a look at the hints, and if they aren't clear, feel free to ask us (or tell us what doesn't work) at the issue tracker at RIAForge or the scriptaGulous Google group.
More...
There has been some suggestion about packaging this into CFCs (and I like that idea). That will happen down the line (when someone has time to sort through and categorize the tags), but I see it as being an option to use instead of simply including the entire file. So basically, I'm thinking related functions/tags will be in separate libraries, and then the respective CFCs will include them, and a monster CFC might aggregate all the individual ones (not sure about the monster CFC, but I think a monster file would be good for include purposes if you choose that route).
I want to stress that I only checked that it compiles. I've got some non-CF work to do over the next couple of days, so if anyone has CF work to do and wants to use it, we'd appreciate any comments on what works, what doesn't, and what works but not how you might expect. Again, feel free to tell us these things using the issue tracker at RIAForge or the scriptaGulous Google group. I'll commit to responding and fixing things relatively quickly (most likely within the same day).
Posted by Sam on Jun 03, 2007 at 12:12 PM UTC - 5 hrs
Last night Thomas Enebo announced on Ruby Talk that JRuby 1.0 RC 3 has been released, and that it "will likely be our final release candidate before our 1.0 release."
I'm interested to deploy a web app trying Ruby on Rails with JRuby (or JRuby on Rails, perhaps), and also in experimenting with Sean Corfield's Scripting for CF 8 to run Ruby within ColdFusion.
Anyone else planning to do good things with JRuby?
Posted by Sam on May 30, 2007 at 01:55 PM UTC - 5 hrs
Today I put some code into the scriptaGulous repository at RIAForge. (scriptaGulous is a function library that intends to duplicate all the ColdFusion tags (where it makes sense) to make them usable in cfscript blocks).
Basically, I wrote a generator to read the taglib.cftld and generate some code for us to start with. I was going to generate some unit tests too, but I've got to move on to doing some other work.
Anyway, I'm sure plenty of the tags/functions actually do work, but when you cfinclude scriptagulous.cfm, you'll get attribute validation errors in some of the tags.
So now on to the next stage of development: making all the tags work. For that, we need your help! (if you want to use this sooner rather than later)
If you'd like to commit to contributing a tag or two (or more!), please join the scriptaGulous Google Group and record which tags you're working on so we don't duplicate our efforts.
Posted by Sam on May 29, 2007 at 01:46 PM UTC - 5 hrs
That's ScriptaGulous with a big-G (not C). The name is kind of cheesy but there's been a lot of talk lately about being able to have all the tags available for scripting in CF. This is something I've wanted personally for a while as well, and it has been on my to-do list for quite some time (ever since 11/22/2006 after a conversation with Ron Jeffries about how "agile" a tag-based language could be on the XP Yahoo! Group). It's been there for so long with no action on my part, I thought starting a project page at RIAForge would get me moving. It's certainly not going to be a particularly hard project to do, as most of it is repetitive busy-work, but I think it will be very useful.
More...
There are no files yet, but here's how I'd like to see it go:
- The code for the CF8 version will be easy since all tags can accept attributeCollection, we just send named parameters to the function and send arguments through attributeCollection
- I'm tentatively thinking all methods should be prefixed with "cf." Thus,
<cfabort> becomes cfabort(), and so on. This has two potential benefits: It makes memorization easy, since we already think in those terms for tags, and any potential naming conflicts with actual CF functions are gone (as far as I can think from the top of my head).
- It's going to take a while to do every tag. I don't want this to be "Sam's project" (though will eventually complete it even if no one contributes), but more of a community project. So if you've got time to do a tag with all the possible combination of attributes (so this will work in previous versions), I'm sure everyone would appreciate the effort. I'll try to commit to doing a tag every other day or so.
- I'm thinking it might be nice to put these into packages of related functions (based on the CF documentation), but I don't know how useful that would be.
- If you already know of something like this, please let me know and I'll gladly drop this one (or if you want to call it ScriptaGulous and host it on RIAForge perhaps we can get them to transfer project ownership).
So, what do you think? Your input and/or participation is/are most welcome!
Posted by Sam on May 29, 2007 at 07:14 AM UTC - 5 hrs
Often when we make a change to some code, if it is not properly designed, the result is that cascading changes need to be done throughout the application because bugs will ripple through the system. That's one of the ideas behind why we want to have low coupling between classes. We also have unit testing to combat the effects of this, but let's just suppose we haven't written any, and haven't used JUnit Factory to create regression tests.
Given that there is a lot of code out there that isn't quite perfect, wouldn't it be nice to have a tool that could analyze changes and where they would affect other code? I can imagine how such a tool might work, but I haven't heard of one before now (that I recall, anyway).
So the point of it all: I heard something about BMC and IBM teaming up on such a tool (my understanding is that BMC started it, and IBM later joined the project). I'm assuming it'd be in Java, but does anyone have information on this? Can anyone confirm or deny the story I heard?
Last modified on May 29, 2007 at 07:15 AM UTC - 5 hrs
Posted by Sam on May 28, 2007 at 04:41 PM UTC - 5 hrs
Ok, this is a well known issue (and I feel like a moron for it taking me so long to figure out), but I couldn't figure it out for the life of me (I was looking in the wrong spot the whole time - who would think CF Studio had anything to do with it?).
For the longest time, my FTP was not working, and today we finally narrowed it down to Allaire FTP & RDS. The only problem is, I couldn't set up an FTP site on it, and I couldn't uninstall it (in fact, it looked about half-uninstalled, as it remained under "My Computer" but the icon was dead and you couldn't do anything with it.
More...
We were looking at 3 different computers and trying to figure out why one used to work, one stopped working long ago, and one worked just fine. We were lucky enough to be doing a fresh install of Windows on one of the computers, and on the clean install FTP worked fine. After installing CF Studio 4.5 (he's old school) the FTP stopped working. Problem found.
To fix it, we just needed this technote from Adobe (which was hard to find because the searches were yielding links to House of Fusion --> Allaire.com --> Macromedia.com --> Page no longer exists on Adobe.com). Anyway, that's what you'll likely need to do to get your FTP working again if you're a CF developer and it stopped working.
Posted by Sam on May 20, 2007 at 08:04 AM UTC - 5 hrs
What if we had functions compile(String sourceCode) and runCompiled(BinaryData compiledCode)? What could you do with it? Could it act as a closure, and bring really dynamic coding to traditionally static languages, perhaps allowing dynamically named variables and functions to languages without them (and much more!)? Could we store our code in a database and mix and match chunks, building programs based on a SQL query?
What do you think? Useful or useless?
Posted by Sam on May 19, 2007 at 01:25 PM UTC - 5 hrs
Peter Bell's presentation on LightWire
generated some comments I found very interesting and thought provoking.
(Perhaps Peter is not simply into application generation, but comment generation as well.)
The one I find most interesting is brought up by several people whose opinions I value -
Joe Rinehart, Sean Corfield,
Jared Rypka-Hauer, and others during and after the presentation.
That is: what is the distinction between code and data, and specifically, is XML code or data
(assuming there is a difference)?
More...
The first item where I see a distinction that needs to be made is on, "what do we mean when we are talking about
XML?" I see two types - XML the paradigm where you use tags to describe data, and the XML you write - as in,
the concrete tags you put into a file (like, "see that XML?"). We're talking about XML you've written, not
the abstract notion of XML.
The second idea: what is code? What is data? Sean Corfield offers what I would consider to be a concice,
and mostly correct definition: "Code executes, non-code (data) does not execute." To make it correct (rather
than partially so), he adds that (especially in Lisp) code can be data, but data is not code. You see this
code-as-data any time you are using closures or passing code around as data. But taking it a bit further -
your source code is always just data to be passed to a compiler or interpreter, which figures out what the
code means, and does what it has been told to do.
So is XML code? Certainly we see it can be: ColdFusion, MXML, and others are languages where your
source code is written (largely) in XML. But what about the broader issue of having a programmatic
configuration file versus a "data-only" config file?
Is the data in the config file executable? It depends on the purpose behind the data. In the case of data
like
<person>
<name>
Bill
</name>
<height>
4'2"
</height>
</person>
I think (assuming there is nothing strange going on) that it is clearly data. Without knowing anything about the
back end, it seems like we're just creating a data structure. But In the case of
DI (and many others uses for config files),
I see it as giving a command to the DI framework to configure a new bean. In essence, as Peter notes,
we've just substituted one concrete syntax for another.
In the case of XML, we're writing (or using)
a parser to send data to an intepreter we've written that figures out what "real" commands to run based on
what the programmer wrote in the configuration file. We've just created a higher level language than we had before
- it is doing the same thing any other non-machine code language does (and you might even argue
about the machine code comment). In the configuration case,
often it is a DSL (in the DI case specifically, used to describe which objects depend on which other
objects and load them for us).
While we don't often have control structures, there is nothing stopping us from implementing them,
and as Peter also notes, just because a language is not
Turing complete), doesn't mean it is not
a programming language. In the end, I see it as code.
Both approaches are known to have their benefits and drawbacks, and choosing one over the other is largely a matter
of personal taste, size and scope of problem, and problem/solution domain. For me, in the worlds of
JIT compiling and interpreted langages, the programmatic way
of doing things tends to win out - especially with large configurations because I prefer to have
the power of control structures to help me do my job (without having to implement them myself).
On the other hand, going the hard-coded XML route is especially popular in the compiled world, if not
for any other reason than you can change configurations without recompiling your application.
I don't make a distinction between the two on terms of XML is data, while programming (or using an in-language DSL)
in your general-purpose language is code. To me, they are both code, and if either is done incorrectly it will
blow-up your program.
Finally, I'm not sure what value we gain from seeing that code is data (and in many cases config data is code),
other than perhaps a new way of looking at problems which might lead us to find better solutions.
But that isn't provided by the distinction itself, just the fact that we saw it.
Comments, thoughts, questions, and requests for clarifications are welcome and appreciated.
Posted by Sam on May 16, 2007 at 07:41 AM UTC - 5 hrs
I've been thinking about it lately, and I cant't seem to think of any (in my admittedly small set of knowledge) other language that allows you to be dynamic by leaving out language constructs (such as the type and returntype attributes of parameters and functions), but that, when you do decide to use them, the language acts statically (and is CF even acting statically when it checks the arguments, or is it acting strongly?).
For all you supermultilingual coders out there: do you know of any other language which is dynamic, but allows you to instruct it to become static like CF does? If there are others, is CF the first?
More...
Is it good to be such a hybrid? I would think it keeps the staticians and dynamos both happy, but I'm not sure if it can (or even should) be quantified as good/bad. Do we want it to continue down the path that leads to having complete static options available (for instance, you can type your variables if you want to, and it will provide benefits of static languages, but leaving them off keeps it dynamic)?
What if you could write Java code as: name = "Johnny"; name=3; (and switch back to having it statically typed in the same class)? What would it look like to do operations on a dyanmically declared variable when a static one is expected? I suppose this has more to do with strong vs. weak typing, really, but would the mere existence of allowing dynamic typing mean the compiler can no longer check any method call for correct argument types? Would the fact that you can declare variables without a type make statiphiles cringe (because they may intend to use the typing and leave it off, and then the compiler won't tell them)?
Does allowing any typing to be done dynamically mean all checks must be performed at runtime? If so, what is the point to adding static features into CF (to make it throw an error perhaps 2 lines prior to where it would have thrown it - at the beginning of the method rather than where the argument is used)?
Does it even make sense to classify a language as a static/dynamic hybrid? (And can I ask any more questions?)
Last modified on May 16, 2007 at 07:42 AM UTC - 5 hrs
Posted by Sam on May 15, 2007 at 01:07 PM UTC - 5 hrs
It might be petty, but those two three-letter words really get to me. They clutter my code almost as much as semicolons, Object obj = new Object() // assign a new object to the object called "obj" which is is of type Object, and angle brackets. I'm want to do something like newCodebase=rereplace(entireCodebase,"[gs]et","","all").
What if we had a new idiom where calling the method without arguments would cause it to return a value (the get), while calling it with an argument would run the setter? Its easy enough to do. What do you think, am I off my head?
Posted by Sam on May 07, 2007 at 09:20 AM UTC - 5 hrs
As I'm getting into little details about the generation cfrails is doing, I had a couple of questions I thought the community could provide some insight on better than my own experiences regarding lists.
One of the great things about generating this stuff is that you can have for free all the bells and whistles that used to take a long time to do. In particular, you can have sorting on columns automatically generated, as well as pagination.
So question 1 is: given that you can have sorting for free, would you rather automatically sort on every column, and specify any columns you did not want to sort on, or would you prefer to not have sorting placed automatically, but just specify which columns to sort on?
And question 2: Given that more and more people are on broadband, is it time to up the 10-record limit on results? I find it annoying to have to reload all the time, and if given the option, I normally up the results/page to 50 or 100. What do you think, would you make the default number of results/page higher (and how high would you take it?), or would you cater to the lowest common denominator?
Posted by Sam on May 02, 2007 at 07:24 AM UTC - 5 hrs
As expected, Ben was a great speaker and gave a good presentation. He said we were quiet, and someone said its because we've read all the blogs about it before he came. He was running a little late, due to some fiasco in Austin where the city commandeered the meeting room and they had to change the venue at the last minute.
Unfortunately, Dave's post about the presentation did act as sort of a spoiler, and Ben didn't give us any scoops (that I noticed). Anyway, that's why I don't have much to add. =)
One important thing though: so far, they have yet to get an error on CF8 running old CF6/7 code (some public facing parts of adobe.com are running on CF8 now, he said). Of course, this is what you would expect, but I remember the nightmare we had moving from 5 to 6 - it wasn't pretty.
Seeing the presentation live did give some perspective to Dave's notes, and it's worth going even without learning anything new. I also wanted to thank the HouCFUG guys for putting all of that together- you guys did a great job (and it was good to meet you!). Finally, congrats to the winners of the raffle prizes. I guess I'm going to have to break out the wallet when 8 comes out. I think I'd buy it just for the inline arrays and structs.
Posted by Sam on May 01, 2007 at 09:51 AM UTC - 5 hrs
Thanks to Dave Shuck's post about Ben Forta's presentation at Dallas/Fort Worth CFUG, I now know a lot more about CF8 than I did before. He has a long list of new features, but the two I'm most excited about are inline arrays and structs! Dave showed a couple of examples:
<cfset MyArray = ["CFIMAGE","CFWINDOW","CFPOD","CFMENU"] />
<cfset MyStruct = {Name="Dave",FavoriteLanguage="CFML",Cool=true} />
Now, if we could just get closures ... =)
Last modified on May 01, 2007 at 09:52 AM UTC - 5 hrs
Posted by Sam on May 01, 2007 at 09:36 AM UTC - 5 hrs
There are a couple of drawbacks (or some incompleteness) to scaffolding being truly useful. The one that seems to be most often cited is that normally (at least in Ruby on Rails, which seems to have popularized it) it looks like crap (it is only scaffolding though). Of course, most who make that complaint also recognize that it is only a starting point from which you should build.
Django has been generating (what I feel is) production-quality "admin" scaffolding since I first heard about it. It looks clean and professional. Compare that to the bare-bones you get by default in Rails, and you're left wondering, "why didn't they do that?" Well, as it happens, it has been done. In particular, there are at least 4 such products for use with Rails: Rails AutoAdmin (which professes to be "heavily inspired by the Django administration system"), ActiveScaffold (which is just entering RC2 status), Hobo, and Streamlined (whose site is down for me at the moment).
More...
My interest lies in the second complaint though - that writing it to a live file (rather than dynamically figuring it out - which I've been calling "synthesis," as opposed to generation) means you can't get the benefits of upgrades to the scaffolding engine (and, it is not following DRY!). But, if you just use the default scaffolding, what happens if it doesn't come out just right (assuming you've even passed the notUgly test in the first place)? Well, thats a big part of what I'm trying to solve with cfrails, by using a DSL that provides tweakability to the scaffolding, without requiring you to write to a file (though, if the tweaks won't work, you are always welcome to go to a file with HTML and the like). The interesting part for me about the RoR plugins above, therefore, is that it appears (I haven't checked them out yet) that at least Hobo contains a DSL, called DRYML, to help along those lines.
I'll be having a closer look at those when free time becomes a bit less scarce. What do you think? Is it the holy grail, or can there be very useful
"scaffolding"?
Last modified on May 01, 2007 at 09:37 AM UTC - 5 hrs
Posted by Sam on May 01, 2007 at 07:09 AM UTC - 5 hrs
For more info, see this post or HouCFUG.
The meeting is at 6 pm. And here's a map.
Last modified on May 01, 2007 at 07:09 AM UTC - 5 hrs
Posted by Sam on Apr 28, 2007 at 03:17 PM UTC - 5 hrs
Base on the suggestion from Rob Wilkerson, I decided to pull
this out into some code that illustrated the point I made in my last post.
For context, see Another great use for closures.
Basically, what's going on is that we have a list() method that takes a query and
dynamically outputs a list of its rows (with a heading column as well). It also has the ability to
call a closure for a cell instead of doing its normal output, if one exists.
More...
Most of the code below is tangential to the example, but as a whole, it illustrates the point I was trying to
make, and shows a practical aspect of closures (using Sean Corfield's Closures for CFMX).
In particular, there are a couple of methods of interest. Rather than passing a closure directly into the method, as one
might normally do, I created a function, onOutputOf(), that puts the closures into a data
structure to be checked by the method. This is only because it made more
sense in my original application to do it that way, since the programmers are not typically calling the
list() function themselves.
Next, there is a method to find a closure for a column if it exists. Rather than have the list function
checking the closure storage data structure itself, I opted to use getClosureToBeRunOnColumn() to
keep the methods as cohesive as I could see.
Of course, the list() method itself shows the use I found for this. And finally, callClosure()
shows how I'm using Closures for CFMX, and the next to last line shows an example of passing in some code as a string.
If you have any questions (or comments on how I can improve this!) please feel free to let me know. I enjoy the
feedback =). I'm done rambling now. Here's the code:
<!--- a simple utility function to make this example work --->
<cffunction name="queryRowToStruct">
<cfargument name="query">
<cfargument name="rowNum">
<cfset var local=structNew()>
<cfset local.result = structNew()>
<cfloop query="arguments.query">
<cfloop list="#arguments.query.columnList#" index="local.col">
<cfset local.result[local.col] = arguments.query[local.col][arguments.rowNum]>
</cfloop>
</cfloop>
<cfreturn local.result>
</cffunction>
<!--- set up a query for the example to use --->
<cfset beers = queryNew("beer,in_stock,rating","varchar,bit,integer")>
<cfset queryAddRow(beers,3)>
<cfset querySetCell(beers,"beer","Boddington's", 1)>
<cfset querySetCell(beers,"in_stock", true, 1)>
<cfset querySetCell(beers,"rating", 8, 1)>
<cfset querySetCell(beers,"beer","Newcastle", 2)>
<cfset querySetCell(beers,"in_stock", false, 2)>
<cfset querySetCell(beers,"rating", 9, 2)>
<cfset querySetCell(beers,"beer","Milwaukee's Beast", 3)>
<cfset querySetCell(beers,"in_stock", true, 3)>
<cfset querySetCell(beers,"rating", 1, 3)>
<cfset closuresToRunOnColumns = arrayNew(1)>
<!---
this function takes all the closures to run on columns
and stores them for later use.
--->
<cffunction name="onOutputOf" output="false">
<cfargument name="column">
<cfargument name="run">
<cfset var singleClosureToRunOnColumn = structNew()>
<cfset singleClosureToRunOnColumn.column = column>
<cfset singleClosureToRunOnColumn.closure = run>
<cfset arrayAppend(closuresToRunOnColumns, singleClosureToRunOnColumn)>
</cffunction>
<!---
given a column name, this function returns the
closure if it exists, "" otherwise
--->
<cffunction name="getClosureToBeRunOnColumn">
<cfargument name="column">
<cfset var local = structNew()>
<cfset local.result = "">
<cfloop from="1" to="#arrayLen(closuresToRunOnColumns)#" index="local.i">
<cfif closuresToRunOnColumns[local.i].column eq column>
<cfset local.result = closuresToRunOnColumns[local.i].closure>
<cfbreak>
</cfif>
</cfloop>
<cfreturn local.result>
</cffunction>
<!---
this function creates and calls the closure so it is easy
for the programmer to just inline his closures
--->
<cffunction name="callClosure">
<cfargument name="closure_code">
<cfargument name="row">
<cfscript>
closure_factory = createObject("component","org.corfield.closure.ClosureFactory");
closure = closure_factory.new(closure_code).bind(outer=row);
closure.call();
</cfscript>
</cffunction>
<!--- this is our generic list function --->
<cffunction name="list" output="true">
<cfargument name="query" required="true">
<cfset var local = structNew()>
<cfset local.columns = query.columnlist>
<cfloop list = "#local.columns#" index="local.col">
#local.col#,
</cfloop>
<br/>
<cfloop query="arguments.query">
<cfloop list="#local.columns#" index="local.col">
<cfsavecontent variable="toBeOutput">
<cfset local.closureToCall = getClosureToBeRunOnColumn(local.col)>
<cfif local.closureToCall is "">
<!--- if the column does not have a closure to run, output it --->
#arguments.query[local.col][currentRow]#
<cfelse>
<!--- otherwise, call the closure --->
<cfset callClosure(local.closureToCall,queryRowToStruct(arguments.query,currentRow))>
</cfif>
</cfsavecontent>
#trim(toBeOutput)#,
</cfloop>
<br/>
</cfloop>
</cffunction>
<!---
Everything above this is hidden in our base class.
Everything below is the stuff the end programmer
needs to deal with.
--->
<!--- here's how the normal list looks --->
<cfset list(beers)>
<br/>
<!---
But when the programmer calls it, he wants to change
it. Instead of outputting 0/1 for in_stock, he wants
it to say "yes" or "no"
Also, he knows by documented convention that whatever variables
are sent to his closure, they will be in a structure called
"arguments"
--->
<cfset onOutputOf(column="in_stock",run="<cfoutput>##yesNoFormat(outer.in_stock)##</cfoutput>")>
<cfset list(beers)>
Posted by Sam on Apr 26, 2007 at 10:54 AM UTC - 5 hrs
Back in December, I had a post about why closures are useful. In particular, I mentioned what I called the "generalized Template Method" pattern as a benefit: basically, you have a function where, when the user calls it, you want them to be able to change its behavior in some way.
I was short of practical examples, but today I came across one. I've got a list() function that behaves identically for each object it is called on. Basically, it figures out what properties the object has that should be listed, and creates a table that lists them for some query result set. Normally, this just outputs the variable's value on a cell with a white background. The slight change in this case was that depending on the value, the list should set a background color to one particular cell.
More...
Being that I've been burned a lot in the past by not following the DRY and OAOO principles, I'm quite fanatacal about following them nowadays. So when I needed the list() function to behave a bit differently for this one type of object, I didn't want to replicate the entire list function -- I just wanted to add a bit of logic in the middle. That's where closures enter the picture.
I decided I'd create a function, onOutputOf(column="column that special stuff needs to be done to", run="function, or code"). So, instead of outputting the value of the cell, the list now knows to run the code provided in the run parameter.
And now, some really complex code doesn't need to be replicated elsewhere. Isn't that sweet?
Last modified on Apr 26, 2007 at 10:54 AM UTC - 5 hrs
Posted by Sam on Apr 24, 2007 at 01:27 PM UTC - 5 hrs
For all you Houston, TX CFers, Ben Forta will be visiting the Houston ColdFusion Users Group a week from today (that's Tuesday, May, 1st, 2007) at 6 pm.
The meeting is at Gulf Coast Regional Blood Center (I hear Ben is a vampire, so we'll need to replenish our supply) which is located at 1400 La Concha Ln, Houston, TX - 77054. That's right behind Reliant Stadium / the Astrodome, so if you park in the lot on Old Spanish Trail at Texans games or the Rodeo (or one of the many other gigs they always have going on there, like my favorite - the monster truck rallies), then you probably walk past it all the time.
If you plan on coming, the HouCFUG guys really want you to RSVP, since there will be food and drinks provided. More info is at the HouCFUG website.
Hope to see you there!
Posted by Sam on Apr 24, 2007 at 09:05 AM UTC - 5 hrs
This morning has been strange. On the drive to work, I started out thinking about encapsulation, and how much I hate the thought of generating a bunch of getAttribute() methods for components that extend cfrails.Model (in cfrails, of course). To top it off, I don't know how I'd generate these methods other than to write them to a file and then cfinclude it. But as I said, I really hate the idea of (say in the views) having to write code like #person.getSocialSecurityNumber()#. That's just ugly.
But then again, I don't like the alternative of leaving them public in the this scope either, because then there is no method to override if you wanted to get or set based on some calculations (of course, you could provide your own, but you'd have to remember to use them, and the attributes themselves would remain public. Currently, this is the way its done, because I feel like providing default getters and setters is not really encapsulating anything on its own. The encapsulation part only enters the game when you are hiding some implementation of how they are calculated or set.
More...
Then, of course there are the generic getters and setters that Peter Bell is often talking about. You know, where you have some implementation like (excuse the pseudocode -- I'm just lazy right now =), but it shows the idea):
function get(attr)
{
if (methodExists("get"+attr)) return callMethod("get"+attr);
else return variables[attr];
}
This is easy enough to implement without resorting to file I/O, and it has the side benefit of allowing you to check if a getAttribute() method already exists, and call it if so. And where this morning starts getting wierd is that I randomly came across this post from David Harris where he and Peter are discussing this strategy in the comments. What a coincidence.
But what I really wanted is something you see in Ruby (and other languages too): the attr_accessor (or reader and writer) in Ruby. You can do something like this:
class Cow
attr_accessor :gender, :cowtype
# or equivalently, we can have writers and readers separate:
# attr_reader :gender, :cowtype
# attr_writer :gender, :cowtype
def initialize(g, t)
@gender= g
@cowtype = t
end
end
elsie = Cow.new("female", "milk")
#if we did not have the attr_reader defined, the next line would choke
puts "Elsie is a " + elsie.cowtype + " cow."
#change the cowtype + this line would break without the writer defined
elsie.cowtype = "meat"
puts "Elsie is now a " + elsie.cowtype + " cow."
#here we'll change the class (this is happening at runtime)
class Cow
# add a setter for cowtype, which overrides the default one
def cowtype=(t)
@cowtype="moo " + t
end
end
#change elsie to a model cow
elsie.cowtype = "model"
#what type of cow is elsie now?
puts "What a hot mamma! She's turned into a " + elsie.cowtype + "!"
#she's a moo model!
See how easy that is?! That's what I really want to be able to do in ColdFusion. And the best part is, it really would only (as far as I can tell) require a couple of changes to the language. The first one being something like if (cowtype= is defined as a method on the object I'm working with) call it when doing an assignment; and the second one is being able to define a method like so:
<cffunction name="cowtype=">
</cffunction>
In any case, the morning got more coincidental when I ran into this post on InfoQ about Adding Properties to Ruby Metaprogramatically, which I'd recommend reading if you're wanting to metaprogram with Ruby (or if you are just interested in that sort of thing).
It's now time for me to crawl back into my hole and write about the wonderful world of The History of Partial-Order Planners. (The good news on that is I'm getting close to the fun part - actually programming one).
So method= is going on my wishlist for CF9, and in the mean time I'll probably end up going the generic getter/setter route. What are your thoughts? What would you go with?
Posted by Sam on Mar 30, 2007 at 03:12 PM UTC - 5 hrs
One of the great benefits of using a framework (in the general sense) is the freedom in portability it often gives you. Rather than writing your own Ajax routines which would need to handle browser incompatibilities, you can rely on Prototype/ Scriptaculous, AjaxCFC, Spry, or a seemingly infinite number of Ajax frameworks available. We see the same phenomenon in our use of ColdFusion, which uses Java to be cross-platform. And, you can get the benefit for databases by using a framework like Transfer or Reactor or ActiveRecord in Ruby (all also have a slew of other benefits). In general, we're simply seeing an abstracting away of the differences between low-level things so we can think at a much higher level than "oh crap, what if they're using Lynx!" (Ok, I'm doubting any of those Ajax frameworks fully support Lynx =), but you get the picture)
More...
I can honestly say I've never had to build an application that needed to be portable between databases, aside from between different versions by the same vendor (although there was once where it might have been nice, since I used the apparently impossible to find in hosting combination of Microsoft SQL Server and Java). My guess is that unless you're building software which is meant to be deployed on different databases (such as a framework, library, or software you plan to sell over and over again which you won't be hosting), you probably haven't needed to do so either... Or at least, not often enough to let it impact your coding.
So today, I started my quest to turn cfrails into a DB-independent framework (as of today, March 30, 2007 it works only with Microsoft SQL Server). Since one of my goals is to limit the amount of configuration the programmer has to provide to get up and running, simply telling cfrails your database metadata (instead of having it look in the database itself) was out of the question (XML or otherwise). I've looked at using CF's getMetaData(query_result) function in the past, but that doesn't have near the amount of data that would be useful for me.
I figured my best bet would be to drop down into Java and use its DatabaseMetaData interface. This way, I could let Java take care of the differences between DB implementations for me. Sure enough, looking over the docs, it had everything I needed. I went ahead and whipped up some code to use it and test it before trying to put it into Coldfusion. If you're interested, here's most of what I needed (only using the jdbc/odbc bridge). If not, feel free to skip this code:
// at the top of the file, you'll need to import java.sql.*
// and of course, define your class as you normally would.
Connection connection=null;
String driverPrefixURL = "jdbc:odbc:";
String dataSource = "ODBC Datasource Name";
String username = "user";
String password = "password";
String catalog = "which database";
String schema = "dbo";
String tableYouWantColumnsFor = "sometable";
try
{
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
connection = DriverManager.getConnection(driverPrefixURL+dataSource, username, password);
DatabaseMetaData dbmeta = connection.getMetaData();
ResultSet cols = dbmeta.getColumns(catalog,schema,tableYouWantColumnsFor,"%");
while (cols.next())
{
// this is all going to be unformatted as-is
System.out.print(cols.getString("COLUMN_NAME") + " ");
System.out.print(cols.getString("DATA_TYPE") + " ");
System.out.print(cols.getString("TYPE_NAME") + " ");
System.out.print(cols.getString("COLUMN_SIZE") + " ");
System.out.print(cols.getString("IS_NULLABLE") + " ");
// no clue why these two lines are throwing errors
//System.out.print(cols.getString("COLUMN_DEF") + " ");
//System.out.print(cols.getString("ORDINAL_POSITION") + " ");
System.out.println(); // skip to the next line
}
connection.close();
}
catch (Exception e)
{
e.printStackTrace();
// probably should be in finally block, but didn't worry about it as this was just a test
try
{
connection.close();
}
catch (Exception ex)
{
System.out.println("Could not close connection - probably wasn't open.");
}
}
(if you need more info, see the docs I linked above -- this is just a small sampling of the metadata available for columns in a table)
Sweet! I didn't really need ORDINAL_POSITION since it already ordered the results by it, and COLUMN_DEF (the column's default value) wasn't all that important (well, I could figure out a way to get that later, anyway). But, when I went to put it into ColdFusion, I realized - I have no clue how I might get the information I need to connect- forget about the fact that I'm not sure the average developer (CF or otherwise) will know what a catalog or schema is, or which one they need to access if they do. Who in the world isn't going to have to go through some work to figure out what driver they need and what the connection URL is?
So, I needed a way to let Java know these things through CF. I thought I could get at least some of that information from the CFAdminAPI (or whatever the proper case and spelling is), but I didn't really like that option. I couldn't think of any other option that would allow me to use Java to get the metadata, so I decided I'd have a look at the codebases for Transfer ORM, Reactor, and DataMgr and see how those smart guys did it. I only browsed, but I didn't find anything useful for me trying to use Java to do the trick. So, it was back to writing a DB-specific implementation for each database I wanted to support.
Luckily for me, even though my design doesn't approach the modularity and complexity of Reactor or Transfer (yet... I'm a big fan of YAGNI and haven't had any reason to break out of the simple design I currently have and Transfer is downright confusing for me to quickly browse it and figure out what's going on), it is quite flexible enough for me to do the different implementations and integrate them with ease. To do so, I only need to refactor the current routine that gets the MSSQL Server metadata, and provide a way to figure out which database type it is looking in (each of these only has to happen once). After that, all that remains is to write a query to get the metadata and convert its output (for each implementation) to the interface the rest of my code expects. Not hard by any means, but it would have been cool for maintenance purposes and greater overall simplicity if I could have let Java handle it.
So now that you've gotten this far in this boring post with no conclusion, have you used Java to get the DB metadata in CF (or even outside of CF)? Have you found a way to do it without making the programmer specify the connection URL and driver?
Posted by Sam on Mar 30, 2007 at 11:48 AM UTC - 5 hrs
A thought occurred to me today- just because something doesn't offer all you need, doesn't mean you can't put it to good reuse. This goes back to Sean Corfield's post about why you should avoid the not-invented-here syndrome, my own post about why I thought I would release cfrails (and some of the decisions therein), and a multitude of others who realize that reinventing the wheel is not generally productive.
I had the realization today (though, I must admit it is quite obvious!) that there would be nothing wrong with adding an extra layer of abstraction, which would in turn add the features you needed to some other product/library/code. So when I thought "well, I can't use Transfer or Reactor" (what ever happened to Arf!?) because they didn't provide all the metadata I needed, I could have still built on top of them. I guess the thought never occurred to me back then.
In any case, it has now. Although I'm far enough along that I don't think doing this will save me any more time, it's something I plan on investigating- at the very least, it could provide a familiar API to use (and of course, the framework would be generating any XML files rather than having the programmer modify them).
So basically, if you think you don't want to use a pre-made product - at least you should look into the possibility of building on top of it.
Posted by Sam on Mar 13, 2007 at 12:35 PM UTC - 5 hrs
Two or three weeks ago, I posted a call for help on the CFCDev mailing list regarding this strange problem I was having regarding sessions. I forget exactly how I described the issue, and I'm too lazy to look it up, so I'll just describe it again (and I'm sure now that I've solved it, this description will be much better than the first one):
Basically, when I posted a form in Adobe ColdFusion 6.1 whose action performed a cflocation with the cgi.query_string appended to the URL, and when links also appended that variable, all the sudden my session would become invalidated. I checked every reference to session. and couldn't find anywhere it would be happening in my code. I couldn't even tell exactly when it was happening even though I put markers in every place I could think of. But finally today I happened to look up at the URL and notice that CFID and CFTOKEN were there multiple times. Clearly that was the problem. After that, I was pretty sure the where the problem lied, so I went straight to it and fixed it.
This was never a problem in CF7, that I have been able to reproduce.
If you'd like to reproduce it in CF6.1, here is some simple code to do so:
More...
Application.cfm
<cfapplication name="test_session_funkiness" sessionmanagement="true">
<cfparam name="session.id" default="0">
<cfif session.id is 0>
<cfset session.id=1>
The session.id was 0.
</cfif>
start.cfm
<cfoutput><a href="middle.cfm?#cgi.query_string#">go to the middle</a></cfoutput>
middle.cfm
<cflocation url="end.cfm?#cgi.query_string#">
end.cfm
we are at the end.
<cfoutput><a href="start.cfm?#cgi.query_string#">do it one more time</a></cfoutput>
If you set those files up and navigate to start.cfm, you'll see that "the session.id was 0." is output in places you wouldn't expect.
I understand the cause, but I would have expected CF to behave as it does in 7, since (I'm guessing that) appending cgi.query_string to your URL would be fairly common practice. And, as a side note, I'm fairly sure I've run into this before - only I had just forgotten (it seeeeemed familiar). That's why I wrote it down this time (and to help anyone who may also have had the problem).
Posted by Sam on Feb 26, 2007 at 06:50 AM UTC - 5 hrs
I know this isn't quite hot off the presses, but I just wanted to let everyone in Houston (or nearby) know that Ben Forta is coming to the Houston ColdFusion User Group to demonstrate the next release of CF - Scorpio.
He'll be here May 1, 2007 downtown - Please visit HouCFUG for more details.
That's right around finals time, but you can bet I will be trying my best to be there! Also, they want you to RSVP as soon as possible so they know how much food/drink to buy, space to reserve, etc, so make sure you do that. I'll be posting a reminder as we get closer to that date as well.
Hope to see you there!
Posted by Sam on Feb 25, 2007 at 12:57 PM UTC - 5 hrs
Sean Corfield's post about the perils of NIH and RTW and Peter Bell's subsequent one entitled Should you Release Your Framework? got me thinking about my own decision to release cfrails.
Sean mentioned that the not-invented here syndrome, along with reinventing the wheel, "plagues any coherent attempt at Open Source within the ColdFusion community - look at the number of half-baked calendars available (and don't get me started on the unit testing frameworks!)." I wanted to add, "and look at all the generation going on!" (as I can think of at least 5 such projects off the top of my head, my own being one of them.
In general, NIH and RTW are bad things. And Sean is right, to a degree. But I also agree with the sentiment of Peter's post: more is better but if it is substantially similar to another project, it may be better to contribute to that one instead.
More...
I'm a big fan of choice, and of learning, so I tend to think that having more choice (to learn from as well) is better, but if choices are substantially similar, one should certainly strongly consider contributing to the similar project. Of course, a question reveals itself here: "how can I be sure what I'm doing is substantially different?" One cannot take the time to review every framework out there, and probably asking for just a couple is too much. In my case, I didn't review all the frameworks I knew about, but I did read up on them, at least. (As a side note, I don't know when Model Glue started generating code, can anyone confirm when for sure - has it always been there?)
I feel like cfrails is "substantially" different than anything I've seen (even CF on Wheels, which I also plan to contribute to), but I always worry if what I'm doing may at some time be considered to be stepping on toes. I don't want to be perceived that way, for sure.
Further, I don't think I'm solving any problem that hasn't been solved before, but I do think I'm doing it in a different way - and I think there is merit in that, even if, in doing so, I am duplicating some of the effort of others (for instance, cfrails has its own ORM, but I felt that changing what I knew about the existing ones might make them more specific than they were intended to be). With all that being said, I think generating code, while certainly being nothing new in computer science or even ColdFusion, is relatively new to being done publicly or in Open Source in ColdFusion. So, even though there are a lot to choose from, right now, it is a good thing, in my opinion, as we are all able to learn from each other, and may discover better ways of doing things.
In the end, as far as the generators go, it seems most of them are quite different in how they tackle the problem, and some of them even in the problems they solve. I think it would be great if those behind the various frameworks would write about how they came about (or, if you don't mind, leave a link here if you've already written it) and what problems they are intended to solve, and how they solve those problems. That might be a great learning exercise for all of us in the community (I plan to write that up for cfrails after the next couple of weeks -- midterms, you know? =) ).
Posted by Sam on Feb 20, 2007 at 06:39 PM UTC - 5 hrs
I'm sure other editors/IDEs have this, and I'm sure plenty of people know about it already,
but I stumbled on it by accident the other day and I wanted to share for those who may be in the dark:
To write in CFEclipse, you simply need to hit Ctrl-Enter (on a Windows machine, anyway).
It's already been a great help!
Posted by Sam on Feb 20, 2007 at 06:34 PM UTC - 5 hrs
I can't remember the last time I used anything resembling a stack or queue (other than what I'm about to blog about). Of course, I've used lists and arrays, but not with the same intent you often see in the use of a typical LIFO or FIFO mechanism. I did have occasion to use the concept in the last couple of updates to cfrails, however, so I thought I'd bring it up in case anyone else came across the same use as I have. Let me explain how I arrived at
the need (which also doubles as a little documentation):
Using cfrails, to make a model you simply go into your project and create a CFC that extends cfrails.model in the model folder. Assuming that file has the same name as a table in your database, you've now got an object (after it is instantiated, of course) with all the basic CRUD methods. The case is similar for the view or controller, where you'd be in the appropriate directory, but name it modelname_view.cfc or modelname_controller.cfc. There is a way to change the name of the table if you don't want the model name to match the table for some reason, but I'll not go over it here, as it's an "undocumented feature" at the moment.
More...
So, now we have a table, let's call it drink. It has columns
id (int, pk, identity), brandname (nvarchar 50), label (nvarchar 50), bottle_date (datetime),
and
description (ntext).
The code currently looks like:
<cfcomponent extends="cfrails.model">
</cfcomponent>
In this case, assuming you have the corresponding controller and view set up, cfrails will show label as "Label" and
bottle_date as "Bottle Date" to the user. description will be capitalized as well. Label will be shown as
an <input type="text"/> and description as a <textarea>.
But while brandname would show up as an input text field too, it will be displayed as "Brandname."
Now, if you had called the column brand_name or brandName, the space would be put in automatically.
That's easy enough to do with new tables, but if you're working on an old one where you had used the convention
numBottles, for instance, it would show up as "Num Bottles," which is not something you want displayed to the user.
Another issue shows up with bottle_date. Since it is a datetime column,
cfrails will display it with a select for each of year, month, day, hour, minute (when I get around to
implementing that). But in this case, you might only care about the month and the year.
How do you solve those two problems? That's where some of the configurations / extended metadata comes in.
One of the goals I have in cfrails is to keep related data together.
I'm not fond of the thought that I might need to have to open an extra file to configure my class. So, if
I want the view to show the name of brandname as "Brand Name," I should be able to do that within
drink_view.cfc (actually, you can hand-code your views in templates if the customization options
don't fit the bill, but I'm not getting into that here either).
What I wanted to be able to do was have my files look like this:
<cfcomponent extends="cfrails.view">
<!--- configuration --->
<cfset setHumanName("brandname", "Brand Name")>
<cfset setFieldType("bottle_date","month/YearDate")>
<!--- some extra functions I need --->
...
</cfcomponent>
(As a side note, you could use the underscore version of those functions as well. Also,
the month/YearDate has not yet been implemented as of Feb. 20, 2007, and is subject to change,
but you get the idea.)
That certainly seems easy enough. But, since the controller has to pass the model into
the view through the view's init() method, that configuration code at the top will be
executed before the view has any knowledge of a field called " brandname."
It was a long time coming, but we've finally reached the point where I needed a stack
(well, the order didn't really matter, so what I implemented wasn't really a stack, but it served
the same purpose).
Instead of running the actual function when it is called, I checked if the component was fully instantiated.
If not, I "stack" each function that needs to be run, along with the supplied parameters.
Then, in the init() method, the stacks are "popped" (it's actually done in a queue fashion, but
it feels odd saying that).
Thoughts?
Last modified on Feb 20, 2007 at 06:36 PM UTC - 5 hrs
Posted by Sam on Feb 14, 2007 at 01:54 PM UTC - 5 hrs
If you're not familiar with what cfrails is, it is a somewhat new framework (I started it in November 2006) for building applications in ColdFusion. It does things like saving records, getting records, populating forms, and data validation automatically for you. It also provides nice abstractions for those things which it can't automatically do based on the database metadata (for instance, you may want a month/year date field, rather than a full date). Since I don't want to take too much of your time describing it, more info on it can be found on this blog post about cfrails 0.2.0 or at the cfrails RIAForge project page.
This update is a super-minor version change, but a significant one.
First, a couple of minor items - I added some more aliases to have functions read better.
For instance, instead of doing set_title_new() to change the default
title on a view's new item form, you can now write newform.set_title(). Similar
additions were made to the record listing table and edit forms. There will probably be other small
aliases as well, as I discover more awkward function names. Some of those
old ones will go away, but I'll keep the ones that aren't awkward. Just as well, I also made a few more aliases of the type camelCaseFunction = camel_case_function, to allow everyone to keep their respective programming styles. However, if you are naming arguments, you're currently at the mercy of whatever I have called them. I plan to standardize soon - its just weird thinking in Ruby and programming in CF - I'm mixing styles a lot.
More...
I also noticed that I needed to mix views on occasion (for instance, a Person_view might need
to display a list of checks written, which would be in another component). For this reason, I
added getModel(modelName) and getView(viewName) to the mix. This is a great
abstraction to remove the long and repetitive createObject calls. The downside is that apparently,
CF6.1 and CF7.0 look components up differently, so these don't work (depending on your directory structure, I think) in the older version of CF.
The most significant addition, however, is that there is now some ability for relationships among tables to be added into your models without much effort: via a call to the autoload_relationship() method in your models. This was a bigger pain than I thought it would be, but well worth the effort.
Overall, I'm starting to get excited about the progress being made on this. I've been using it
to extend an application we had written some time ago, and the results are good. For comparison,
I took one of the "old" modules that was written without cfrails, of similar size to
one I am working on now. The one written using cfrails is a bit smaller in scope and less
complex, so I added in the other 2 "modules" I've been working on using it as well. Whereas the
"old" one was over 500 lines, the 3 parts (two are quite small) using cfrails total to about 65, including white space.
I spend more time marveling at the thing than I do programming (just kidding, of course =) ). Of course,
this isn't any scientific comparison, especially since I'm sure I've grown as a programmer since writing
the other one. But, it is still pretty remarkable. The hardest part is going to be memorizing the function
calls. Well, not that it's hard, but it will take time looking at the (almost non-existent) docs,
which may slow you down.
So, what's ahead? First I need to reconcile differences between CF7 and 6.1. After that, I need to add in abstractions to make "select" form inputs, as well as groups of radio buttons and checkboxes. There are some other abstractions I'm thinking of putting in, but I'm not sure if they add any value or just clutter the interface, so I'm leaving them out for now. Other than that, there are some more options I'd like to put in, like concatenating columns of a (HTML) table, to make the list more customizable. Finally, a few more major things are integration with an Ajax framework, integration with more DBMSs (right now, only SQL Server 2000 and 2005 are supported), and I'm toying with the idea of automatically loading referenced tables when there are columns of the type tablename_id.
The biggest thing is re-writing the documentation. The only docs I have right now are based on version 0.1.0.
Clearly, a lot has changed since then.
Those are the things off the top of my head. Even though the version number is only 0.2.1,
I'm starting to feel awfully close to version 1. The main thing is that I want the interfaces (of the code variety) to be intuitive and easy to use, so I'm getting practice in using it. I may try to write a different application using it before I go to version 1, to make sure that it remains as easy to use in that one as it is in the application I'm using it for now.
Posted by Sam on Feb 12, 2007 at 09:54 AM UTC - 5 hrs
I'm a big fan of ColdFusion, but it is sorely missing some dynamic capabilities that I, for one, would love to see. How often have you seen a new user to CF ask something like, "if I store code in the database, how can I get it to run?" That's some pretty advanced thought, in my eyes. But the standard response is, "you have to write it to a file, and then cfinclude it." Similarly, Sean Corfield's Closures for CFMX accomplishes its feat by writing to the file system.
Why can't evaluate() take a string of code and execute it?
I'd also like to see the ability to create methods dynamically. Why should I need to write a file to generate individual getters and setters for an object (or any other function for that matter)? Well, I could do something like get("property_name"), the generic getter and setter that Peter Bell (and certainly countless others) used in his iterating business object. But what happens when I want some more complex functionality? Wouldn't it be cool to be able to loop over your properties and create methods for each of them? Not only that, if the property hasn't been loaded yet (for instance, its a relationship and you want to load it lazily), you could easily do that too!
More...
What if I want to load some data from the database, but I don't know which data -- only the function name will tell me that? Then, you have to either write out to a file or alias that function to a function that throws an error, examines the line, and figures out what the function was called (hat tip, Per Djurner -- I still love that solution =) ). Even that gets iffy if there are two on one line. Let's take it even further - in the previous case you already know the function name. But why can't I just let the user type what they want for a function, and I figure out what its supposed to do? I'd love to be able to do that.
The point here is that I'm not the only one running into roadblocks when it comes to doing dynamic stuff. Smart people who've been using ColdFusion for many years are having to run workarounds. And not only that, newcomers as well!
So three things I'd like to see (which are all somewhat related) in ColdFusion:
- Evalute a string of code
- A method_missing handler, to figure out what to do if a user calls a non-existent method on a class.
- A way to dynamically write functions (which would probably be about the same as item 1)
And, if there is some capability which exists and I have said it doesn't, please let me know!
Update: I suppose if I really wanted to, I could write a CF interpreter in CF (or drop down into Java). Anyone want to join me on that endeavor? =)
Last modified on Feb 12, 2007 at 10:04 AM UTC - 5 hrs
Posted by Sam on Feb 07, 2007 at 11:13 AM UTC - 5 hrs
If you are using version control, what is your setup like, and why did you choose to do it that way?
In Java development, I've got a repository, and I checkout the code to my desktop, check it back in, etc. So, there is no version control on the production server, though. Of course, there is no point (that I see) to have it on the production server, since you don't need many of your source files, but only the compiled classes (I'm assuming web development here).
But in CF, you'll be using all your source files as the actual files to be run, so you might very well set up source control on the production server, and have that be your main code base (say, checking it out to your development server and editing it from there, or to your desktop). Or, do you simply run the version control on your development server, and FTP any changes to production?
There are other ways, to be sure, so if you're using version control on your ColdFusion projects, I'd like to know the different ways you have it set up, and why you chose to do it that way. Any help is appreciated!
Last modified on Feb 07, 2007 at 11:13 AM UTC - 5 hrs
Posted by Sam on Jan 24, 2007 at 10:39 PM UTC - 5 hrs
When I wrote that PseudoObject.cfc would be useless, I was thinking that all objects created would need 3 file operations, and thus, it would be quite unlikely to perform any better (or even on par with) normal object creation.
Based on the way I implemented it in that post, it would need three file operations.
But sitting in my data management class today, I was reminded of ORM because the professor noted that we wouldn't normally think of methods acting on an entity in the database, while each entity would have every other thing we would find in a typical object.
In any case, I realized you could move the file operations out a bit, and they would only need to be run once if you were building a ton of objects that shared the same type. This, I would think would be a substantial improvement over creating tons of real objects. And where would you do that? In an ORM framework - if you wanted to return an array of structs as objects. Then, each could be manipulated as if they were a real object!
Now, it would be freakin' sweet if you can attach a function to each row of the query like this. I expect it would be straight forward if possible, but if not, we can still see a lot of possibilities for ORMs out there (I'll probably test that tomorrow). I plan to implement something along these lines in cfrails, if it does hold up for thousands of objects.
Last modified on Jan 24, 2007 at 10:41 PM UTC - 5 hrs
Posted by Sam on Jan 24, 2007 at 08:22 AM UTC - 5 hrs
At times, I like to push the limits of the languages I work in, just to see what I can learn. A while back,
I got the idea of using structs as objects in Coldfusion, since instantiating objects is so slow. Of course,
this would only be useful if you had tons of objects, and if it was substantially quicker than creating
real objects. Anyway, I decided to see what I could come up with.
Unfortunately, I don't think this would be any more efficient (and possibly less),
because I need to do three file operations. But, I thought I'd share what I came up with regardless.
Basically, what happens is that you tell pseudo_object.cfc what object you want to create, and it creates
a fake object that behaves like a real one. It reads the CFC
you tell it you want an object of. It creates a struct, finds the name of the variable you stored it in
(multiple references won't matter, to my knowledge), rewrites the methods to use the scope+name of
that variable, plus an extra this or variables scope to make up for
variables named the same in different scopes within the CFC. Then, it attaches those methods to
the struct and you now have a struct which behaves like
an object. It won't work if you have any code outside of methods, however. Also, another problem may
arise if you have something like this.variables.
Since I'm not entirely sure that made any sense, I'll share the code now:
More...
<cfcomponent name="pseudo_Object">
<cfset variables.varscope = "">
<cfset variables.obj_index = 0>
<cfset this.objects = arrayNew(1)>
<cffunction name="po_init" access="public" output="false">
<cfargument name="varscope" required="true">
<cfset variables.varscope = arguments.varscope>
<cfreturn this>
</cffunction>
<cffunction name="populateObject" output="true" access="public">
<cfargument name="relative_path_to_cfc" required="true">
<cfargument name="object" required="true" hint = "Struct returned from prepareObject()">
<cfset var local = structNew()>
<cfset local.objName = getTheNameOfTheVariableThatContainsMe(arguments.object.pseudo_id)>
<cfset local.newfile = arguments.object.pseudo_id & ".cfm">
<cffile action="read" file="#expandpath(arguments.relative_path_to_cfc)#" variable="local.theCfc">
<cfset local.theCfc = replacenocase(local.theCfc, "variables.", "#local.objName#.variables.", "all")>
<cfset local.theCfc = replacenocase(local.theCfc, "this.", "#local.objName#.", "all")>
<cffile action="write" file="#getdirectoryfrompath(getcurrenttemplatepath())##local.newfile#" output="#local.theCfc#">
<cfinclude template="#local.newfile#">
<cfloop collection="#variables#" item="local.key">
<cfif isCustomFunction(variables[local.key]) and not listfindnocase("po_init,getObject,prepareObject,getTheNameOfTheVariableThatContainsMe",local.key)>
<cfset this.objects[variables.obj_index][local.key] = variables[local.key]>
<cfset structdelete(variables, local.key)>
</cfif>
</cfloop>
<cffile action="delete" file="#getdirectoryfrompath(getcurrenttemplatepath())##local.newfile#">
<cfreturn this.objects[variables.obj_index]>
</cffunction>
<cffunction name="prepareObject" returntype="struct" access="public">
<cfset variables.obj_index = variables.obj_index + 1>
<cfset this.objects[variables.obj_index] = structNew()>
<cfset this.objects[variables.obj_index].pseudo_id = createUUID()>
<cfreturn this.objects[variables.obj_index]>
</cffunction>
<cffunction name="getTheNameOfTheVariableThatContainsMe" output="false" access="private">
<cfargument name="keyToFind">
<cfset var local = structNew()>
<cfset local.result = "">
<cfset local.scopes = arrayNew(1)>
<cfset local.scopes[1] = variables.varscope>
<cfset local.scopeNames[1] = "variables">
<cfset local.scopes[2] = session>
<cfset local.scopeNames[2] = "session">
<cfset local.scopes[3] = application>
<cfset local.scopeNames[3] = "application">
<cfloop from="1" to="#arrayLen(local.scopes)#" index="local.i">
<cfloop list="#structkeylist(local.scopes[local.i])#" index="local.name">
<cfif isStruct(local.scopes[local.i][local.name]) and
structKeyExists(local.scopes[local.i][local.name],"pseudo_id") and
local.scopes[local.i][local.name].pseudo_id eq arguments.keyToFind>
<cfset local.result=local.scopeNames[local.i] & "." & local.name>
<cfbreak>
</cfif>
</cfloop>
</cfloop>
<cfreturn local.result>
</cffunction>
</cfcomponent>
And so we have something to test with, I've made this simple test.cfc:
<cfcomponent name="test">
<cffunction name="init">
<cfreturn this>
</cffunction>
<cffunction name="setVar1">
<cfargument name="value">
<cfset variables.var1 = arguments.value>
</cffunction>
<cffunction name="getVar1">
<cfreturn variables.var1>
</cffunction>
<cffunction name="setThisVar1">
<cfargument name="value">
<cfset this.var1 = arguments.value>
</cffunction>
<cffunction name="getThisVar1">
<cfreturn this.var1>
</cffunction>
</cfcomponent>
And finally, here we see how to create a pseudo-object of test.cfc:
<!--- test_pseudo_object.cfm ---->
<cfset pseudoObjCreator = createobject("component", "pseudo_object").po_init(variables)>
<cfset session.pseudoObj = pseudoObjCreator.prepareObject()>
<cfset session.pseudoObj = pseudoObjCreator.populateObject("test.cfc", session.pseudoObj)>
<cfset session.pseudoObj.setVar1("five")>
<cfset session.pseudoObj.setThisVar1("this var 1")>
<cfset pseudoObj2 = pseudoObjCreator.prepareObject()>
<cfset pseudoObj2 = pseudoObjCreator.populateObject("test.cfc", pseudoObj2)>
<cfset pseudoObj2.setVar1("six")>
<cfoutput>
#session.pseudoObj.getVar1()#<br/>
#session.pseudoObj.getThisVar1()#<br/>
#pseudoObj2.getVar1()#
</cfoutput>
Now, it was fun to play around with this stuff, but I realize it's probably useless (I mean, I didn't do
any benchmark testing to see if it was faster than object creation, since I had to read and
write to the file system). Further, I'm not at all happy with the design. My main concern is that the
semantics are exposed: a user of this code needs to know they have to call the methods in the order shown
in test_pseudo_object.cfm to have it work. That could be fixed however, if I required that the name of one
of the variables (and its scope) be passed into the CFC via the init() method. Then,
it would return the struct, all in one go. In fact, if I were to ever start using this, I would reimplement
it in that fashion, and it wouldn't be very hard.
Anyway, what do you think of this useless ...
Last modified on Jan 24, 2007 at 08:23 AM UTC - 5 hrs
Posted by Sam on Jan 23, 2007 at 05:13 PM UTC - 5 hrs
Since building the comments functionality in this blog, I've had probably around 40 spams as comments. I got hit hard the other day with 34. I get emails of all the "possible comment spam." Anyway, Jake Munson's CFFormProtect has correctly identified all of them, and there have been no false positives. I'm not even using the Akismet feature yet.
Anyway, I'm going to try to post nothing else about this, because as he mentions, it can easily be bypassed if they know too much about it. So, the less advertising the better, but I just wanted to make sure I gave him credit for this great idea.
Update: Well over the 1000 mark, and CFFormProtect has caught all of them ... with no false positives. So when I say "seems to be working" I should have called it "is working quite well." I've got this on several of our clients' sites as well, and it is working just as well for them too. Great job on this one Jake...
Last modified on Apr 13, 2007 at 06:01 AM UTC - 5 hrs
Posted by Sam on Jan 15, 2007 at 10:23 AM UTC - 5 hrs
Do you find yourself writing more classes in other languages than in Coldfusion? I do.
For instance, I certainly develop more classes in Java than Coldfusion.
Is it due to the fact that I've developed bad habits in CF and haven't yet broken out of them
(i.e., I'm just unable to spot needs for new classes) or is it because CF is so much more high-level
than Java? A third option may be that the performance issues with instantiating
CFCs contribute to me not wanting
to break out?
More...
I think part of it may be due to bad habits and not having the ability to notice a spot where I need
another class. But, I have no evidence of this, since I haven't been able to notice it =).
I do have evidence of the other two options however: CF being so much more high-level than Java is fairly
self-evident: Where I'll often use a façade to interact with a database in Java, in Coldfusion it would
be pretty useless - since there is no need to instantiate a connection, prepare a statement, prepare a
record set, and then close/destroy them all when you don't need them any more. The other,
about the performance hits, I know sometimes stops me from creating more classes. For instance,
I recently used a mixin to achieve some code reuse with a utility method that didn't belong to any of
the classes that used it. Clearly it broke the "is-a" relationship rule, but I didn't
want to incur the cost of instantiating an object just to use
a single, simple method (the application was already seeming to perform slow).
Of course, this is not a zero-sum game. It is certainly due in part to all three. I'd like to think
it is mostly due to the expressiveness of Coldfusion, but I'll always have to wonder about the bad habits.
In Ruby, I've developed a couple of "significant" applications, but those didn't approach
the size of the one's I've done in Coldfusion or Java. It's hard to say for sure, but I'd guess that I'm
writing much fewer classes in Ruby than I would in Java. Again, this is mostly due to Ruby's expressiveness.
In any case, have you noticed yourself writing fewer classes in CF than in other languages? Have you
thought about it? Come to any conclusions?
Last modified on Jan 15, 2007 at 10:23 AM UTC - 5 hrs
Posted by Sam on Jan 15, 2007 at 09:35 AM UTC - 5 hrs
(and functions with arguments can take more than the defined amount)
This may be well known, but I haven't seen a lot (or anything) on it. Of course, as always,
I may just be missing something.
In any case, the other day as I was looking over some old code,
I (re)discovered this marvelous fact. Now, you may be wondering why on Earth I'd want
to use arguments in a function where none were defined. But, I have at least one case
where I think it's valuable: suppose you are following the
Active Record Pattern, or really
writing any ORM. Basically, you want to
abstract the query process. Now, that's certainly a noble goal. But, what happens when
you want to provide a filter? For instance, you might have a function find_by_id(),
a which finds a record based on the id you pass in. That's easy enough.
You might even provide methods to find_by_other_columns_even_in_combinations().
More...
But surely you can't provide every combination! That's where you'd want to
provide a filter argument. Here it comes again: another but! You don't want
to simply provide filter="where column1=#form.column1#" - you want to parameterize
the query for the developer. Now, one way to do that would be to parse the
filter argument and reconstruct it using your cfqueryparams in all the right
places. But, an easier way would be to something like this:
find_records("where age=? and (name=? or name=?)", 9, "blockhead", "charlie brown")
Note: I would probably move the "where" into the abstraction, and just let the programmer provide the clause,
but for illustration purposes, I left it in there.
For illustration purposes, my function only does this:
<cfcomponent>
<cffunction name="find_records" output="true">
<cfargument name="filter">
<cfloop collection="#arguments#" item="key">
#key# = #arguments[key]#<br/>
</cfloop>
</cffunction>
</cfcomponent>
But it would be easy enough to modify it to do something useful. Right now, if you run it, you see
all the arguments are available in the arguments structure. The first one comes under the key
"filter", and the rest come under numeric keys, in the order they were passed (of course, looping over it won't
show you that order, but the number of the key represents the position in which it was passed. Now, you can
parameterize the arguments, first checking more restrictive and moving to less restrictive parameters
(for instance, you'd want to check isDate(), isNumeric(), and fall back on string).
You could name the arguments too, but I haven't found that useful for this example, since they will have their
names as keys in the arguments structure, and I know of no good way to figure out the order
in which they were passed.
Finally, I haven't yet implemented this in cfrails, so I don't know how feasible basing parameterization on
the CF type is, but I'll try to remember to post it when
I do implement it. In any case, I'd be willing to bet there are other uses for this - it's just
that this is the most important one on my mind recently.
Update: It did occur to me as I was writing this post that you could accomplish the same thing by using an array as a
defined argument, with the added benefit of keeping your interface well defined. In all honesty, I would prefer to do it
that way if you could define an array inline like: [9, "blockhead", "charlie brown"]. But the way you define arrays in
Coldfusion really makes for too much code in what I'd like to accomplish with this, so in this case I'd provide a hint in the
function to let a developer know it expects you to pass those arguments. This way, I get cleaner syntax and a decent solution to the
interface problem.
Last modified on Jan 15, 2007 at 12:09 PM UTC - 5 hrs
Posted by Sam on Jan 09, 2007 at 04:44 PM UTC - 5 hrs
For those that don't know, cfrails is supposed to be a very light framework for obtaining MVC architecture with little to no effort (aside from putting custom methods where they belong). It works such that any changes to your database tables are reflected immediately throughout the application.
For instance, if you change the order of the columns, the order of those fields in the form is changed.
If you change the name of a column or it's data type, the labels for those form fields are changed, and
the validations for that column are also changed, along with the format in which it
is displayed (for example, a money field displays with the local currency,
datetime in the local format, and so forth).
I've also been developing a sort-of DSL for it,
so configuration can be performed quite easily programmatically (not just through the database), and you can follow DRY to the extreme. Further, some of this includes (and will include) custom data types (right now, there are only a couple of custom data types based on default data types).
More...
In a nutshell, the goal is to have such highly customizable "scaffolding" that there really is no scaffolding - all the code is synthesized - or generated "on the fly." Of course, this only gets you so far. For the stuff that really makes your application unique, you'll still have to code that. But you can compose views from others and such, so it's not like related tables have to stay unrelated, but I do want to stress that right now there is no relationship stuff implemented in the ORM.
I've skipped a few "mini-versions" from 0.1.3 to 0.2.0 because there were so many changes that I haven't documented one-by-one. That's just sloppiness on my part. Basically, I started by following Ruby on Rails' example, and taking my own experience about what I find myself doing over and over again. That part is done, except that the ORM needs to be able to auto-load and lazy-load relationships at the programmer's whim. In any case, once I got enough functionality to start using it on my project, I've been developing them in parallel. The problem is, I've fallen back on poor practices, so the code isn't as nice as it could be.
In particular, there aren't any new automated tests after the first couple of releases, which isn't as bad as it might otherwise be, since a lot of the core code was tested in them. But on that note, I haven't run the existing tests in a while, so they may be broken.
Further, since I've been thinking in Ruby and coding in Coldfusion, you'll see a mix of camelCase and under_score notations. My original goal was to provide both for all the public methods, and I still plan to do that (because, since I can't rely on case from all databases for the column names -- or so I think -- I use the under_score notation to tell where to put spaces when displaying the column names). But right now, there is a mix. Finally, the DSL needs a lot more thought put behind it - Right now it is a mix-and-match of variables.setting variables and set_something() methods. Right now it is really ugly, but when I take the time to get some updated documentation up and actually package it as a zip, I should have it cleaned up. In fact, I shouldn't have released this yet, but I was just starting to feel I needed to do something, since so much had be done on it and I hadn't put anything out in quite some time. Besides that, I'm quite excited to be using it - it's been a pain to build, but it's already saved me more time than had I not done anything like it.
In the end, I guess what I'm trying to say is: 1) Don't look at it to learn from. There may be
some good points, but there are bad points too, and 2) Don't rely too heavily on the interfaces.
While I don't anticipate changing them (only adding to them, and not forcing you to set
variables.property), this is still less than version 1, so I reserve the right
to change the interfaces until then. =)
Other than that, I would love to hear any feedback if you happen to be using it, or need help because the documentation is out of date, or if you tried to use it but couldn't get it to work. You can contact me here. You can find
cfrails at http://cfrails.riaforge.org/ .
Last modified on Jan 09, 2007 at 04:45 PM UTC - 5 hrs
Posted by Sam on Jan 08, 2007 at 11:55 AM UTC - 5 hrs
Today I was working on some code where an error message could follow one of three basic formats:
[Column Name] is required to be a/n [data type]
[Column Name] is a required field.
[Column Name] must be a/n valid [data type]
The trouble was that [Column Name] isn't known (only the entire message), and doesn't come in the case (as in upper/lower) that I want it displayed. Therefore, I wanted to use rereplace() to end with something like:
<span style='text-transform: capitalize;'>#columnName#</span> [rest of message].
Of course, this isn't very hard. You just need to use a backreference to substitute the old match into the replacement substring:
rereplace(err, "((is[ a]*required)|(must be))" ,"</span>\1","one").
The \1 is the backreference. But, the part that
I had forgotten is that you need parenthesis around the matched text that you are referencing. Therefore, all I needed was the outer parentheses.
I know this is actually quite simple, and mostly useless for most people, but I hadn't used it in a while, and forgot how to do it. So, I thought I'd post a little reminder for myself, and anyone else who might need it.
Last modified on Jan 08, 2007 at 12:00 PM UTC - 5 hrs
Posted by Sam on Jan 06, 2007 at 09:25 AM UTC - 5 hrs
Thankfully for me (and anyone who is interested in using his closures package), Sean Corfield reponded to my Beauty of Closures post and set me straight on a couple of issues.
First, he confirmed that there was indeed a bug when attempting to use a mapping to use the closures, and that in fact, it wasn't a CF 6.1 issue only.
Next, he dove right into the code. So, for easy reference, here is my original code:
More...
<!--- container.cfc --->
<cfcomponent>
<cfscript>
variables._arr = arrayNew(1);
variables._curIndex = 0;
// adds an element to the container
function add(value)
{
_curIndex = _curIndex + 1;
_arr[_curIndex]=value;
}
// iterates over the container, letting a closure
// specify what to do at each iteration
function each(closure)
{
closure.name("run");
for (i=1; i lte _curIndex; i=i+1)
{
closure = closure.bind(value=_arr[i]);
closure.run();
}
}
</cfscript>
</cfcomponent>
His each() method is only slightly different from mine, but significantly so:
// iterates over the container, letting a closure
// specify what to do at each iteration
function each(closure)
{
for (i=1; i lte _curIndex; i=i+1)
{
closure.call(_arr[i]);
}
}
He mentions that I "[name] the method and then repeatedly [bind] the value variable. That doesn't actually do what he thinks." He's right. I was using it incorrectly, and I thought that it was sort of odd to do it like that. In particular, I didn't like having to name the closure. This syntax is much cleaner, and easier to understand. And the best part follows: I had mentioned that, "from my understanding of closures, you should be able to modify 'outer' variables within them. Thus, to be a 'true' closure, outputting beenhere above should show true" in reference to this code:
<!--- closure_test.cfm --->
<cfscript>
cf = createObject("component","org.corfield.closure.ClosureFactory");
container = createObject("component","container");
container.add(10);
container.add(20);
container.add(30);
beenhere = false;
c = cf.new("<cfset value = value + 3><cfoutput>#value#</cfoutput><cfset beenhere = true>");
container.each(c);
c = cf.new("<br/><cfoutput>This container has the value #value# in it</cfoutput>");
container.each(c);
</cfscript>
<cfoutput>
#beenhere# <!--- outputs false --->
</cfoutput>
Sean shows that in fact, had I used bind() as it was intended, outputting beenhere would have shown true, as expected. Basically, you can use bind(outer=variables) on the closure to get access to it. Then, in the code for the closure, you could use outer.beenhere = true and of course, the value is changed as you would expect. That is close to what I was thinking of when I said my idea would muck up the syntax, but I was thinking of passing it when creating the object. I actually like this a little better, as it is much cleaner than what I envisioned, and it is easier to see what's going on. It would be nice of course, if there was a way to do it without the programmer worrying about it, but I don't think that is possible with CF, since it uses the the same name for (from what I can tell) are two different scopes.
Anyway, thanks again to Sean for cleaning up my mess.
Last modified on Jan 06, 2007 at 09:31 AM UTC - 5 hrs
Posted by Sam on Dec 18, 2006 at 08:50 AM UTC - 5 hrs
There are plenty of uses for closures, but two of the most useful ones I've found
(in general) are when you really want/need to encapsulate something, and when you want to implement
the Template Method pattern.
Actually, implementing the Template Method pattern using closures may be misusing it, or
I may be mischaracterizing it. It's more of like a "generalized" template
method (particularly since we're not following the pattern, but implementing the intent).
I still don't understand all of the Gang of Four patterns, so have mercy on me if I've
gotten it wrong. =) More on all this below.
So as I get ideas from other languages, I always wonder "how can I use that idea in language X."
For instance, I like the way Coldfusion handles queries as a data structure - so I tried to
implement something similar in Java (which, I will eventually get around to posting).
I encountered closures for the first time in Lisp a few years ago in an Artificial Intelligence
course, I'm sure. But it wasn't until more recently in my experience with
Ruby that I started to understand them. Naturally, I thought "could this be done in Coldfusion?"
More...
Luckily for us,
Sean Corfield made a Closures for CF
package available a couple of months ago (as far as I can tell).
A couple of days ago, I gave it a whirl.
The first thing I have to say is that I had to move the CFCs into the same
directory as my closure_test.cfm file because it wasn't able to find the
temporary templates it was generating. Sean let me know it was because of a pre CF 7.0 bug in
expandPath(), which explains why I had trouble with that function in cfrails. Anyway,
I've posted a "fix" for 6.0/6.1 to the comments on his blog, which basically just
replaces expandPath(".") when it is creating a temp file to
use getDirectoryFromPath(getCurrentTemplatePath()).
After that, it did take a while to understand what was going on, but once I figured it out,
it was pretty cool. So here's my first class of using closures, and what I did in Coldfusion
to implement it: really "encapsulating" something.
Encapsulation is a word you see thrown around quite often. But you don't achieve it by
putting getters and setters everywhere - particularly if you are passing back complex data
structures from a get() method (without first making duplicates, of course).
The idea behind it, as far as I've been able to understand, is to hide implementation
details from code which doesn't need to know it. Not only does this make the client
code need to be less complex, it certainly lowers your coupling as well. However,
if you have a Container (for instance), how can you encapsulate it?
If you return an array representation, you've just let the client code know too much.
If you don't let the client code know too much, how will it ever iterate over the
contents of your Container?
Certainly an Iterator comes to mind. You could provide that if you wanted to,
complete with next(), previous() and anything else you might need.
But you could also use a closure to allow you to encapsulate iteration over the Container,
while still allowing you the freedom to do what you wanted within the loop. Here's my CF code:
<!--- container.cfc --->
<cfcomponent>
<cfscript>
variables._arr = arrayNew(1);
variables._curIndex = 0;
// adds an element to the container
function add(value)
{
_curIndex = _curIndex + 1;
_arr[_curIndex]=value;
}
// iterates over the container, letting a closure
// specify what to do at each iteration
function each(closure)
{
closure.name("run");
for (i=1; i lte _curIndex; i=i+1)
{
closure = closure.bind(value=_arr[i]);
closure.run();
}
}
</cfscript>
</cfcomponent>
And here's the resulting code that uses Container.each(), and passes a closure to it:
<!--- closure_test.cfm --->
<cfscript>
cf = createObject("component","org.corfield.closure.ClosureFactory");
container = createObject("component","container");
container.add(10);
container.add(20);
container.add(30);
beenhere = false;
c = cf.new("<cfset value = value + 3><cfoutput>#value#</cfoutput><cfset beenhere = true>");
container.each(c);
c = cf.new("<br/><cfoutput>This container has the value #value# in it</cfoutput>");
container.each(c);
</cfscript>
<cfoutput>
#beenhere# <!--- outputs false --->
</cfoutput>
Now, from my understanding of closures, you should be able to modify "outer" variables within them. Thus,
to be a "true" closure, outputting beenhere above should show true. This
would be relatively easy to do by sending the appropriate scopes to the closure,
but the only ways I can think of to do that would muck up the syntax. Other than that, it is not code
that makes me comfortable, so to speak. The closure_test needs to know that it is expected
to use value as the name of the variable. There may very well be a simple way around this that
doesn't screw up the syntax, but I have yet to spend enough research in figuring it out. In fact, in
Ruby you'd use |value| do_something_with(value), so it's probably as simple as that, or providing
an extra parameter (as I saw in one of Sean's examples). Perhaps I will
when I run across a need for it (and I'm sure I will be using this in the future).
And now for comparison purposes, I've included the Ruby version that does the same thing:
class Container
def initialize
@arr = []
@curIndex=-1
end
def add(value)
@curIndex = @curIndex+1
@arr[@curIndex] = value
end
def each
cnt = 0
(@curIndex+1).times do
yield @arr[cnt]
cnt += 1
end
end
end
#trial run
container = Container.new
container.add 15
container.add 25
container.add 35
beenhere = false
container.each{|v| v+=1; beenhere=true}
puts beenhere #displays true
This isn't normally how you'd code in Ruby, but I tried to keep the look approximately the same.
In particular, the each() method is already implemented for arrays in Ruby, so there
would certainly be no need to rewrite it.
As you can see, the syntax is a bit cleaner in Ruby than in the CF version. It's so easy to do,
one doesn't need to think about using closures - you just do it when it comes naturally. Even with
all that, I think Sean reached his goal of proving himself wrong (he said
"I was having a discussion about closures with someone recently and
I said they wouldn't make sense for ColdFusion because the syntax would be too ugly.
On Friday evening, I decided to try to prove myself wrong"). I think it might be possible to
improve it a little, but I don't think it would ever become as "pretty" as Ruby's style (unless, of
course, it was built into the language). Because of that, and the effort involved in creating them,
I don't think it will ever become a natural solution we turn to in CF (although, if I started using them
enough, it would eventually become a natural solution). In any case, he certainly did an awesome job,
made the syntax much cleaner than I would have thought possible, and gave us a new tool to solve problems with.
In closing, I'd like to talk a bit about the "other" use for closures I've found, what I called a generalized
Template Method pattern above. Really, this is just a general case of the way encapsulation was furthered
with the each method above. Basically, you are defining the skeleton of an algorithm, and allowing
someone else to define its behavior. I mentioned that it's not really the template method pattern,
since we aren't confining it to subclasses, and we aren't actually following the pattern - we're just implementing
its intent, in a more general way. So basically, you might think of it as a delayed evaluate for letting
some other code customize the behavior of your code that expects a closure. I don't know if I've made
any sense, but I sure hope so (and if not, let me know what I might clarify!).
Finally I'd like to thank Sean for providing this tool to us, and ask everyone, "what uses
have you found for closures, if any?"
Update: Thanks to Brian Rinaldi, Sean Corfield found this post and addressed the problems I encountered. It turns out I was just doing it wrong, so to see it done right, visit his blog. I also responded to a few of the issues raised here.
Last modified on Jan 06, 2007 at 09:33 AM UTC - 5 hrs
Posted by Sam on Dec 12, 2006 at 09:29 AM UTC - 5 hrs
OK, maybe its not the stupidist ever, but its almost on par with that error I get from time to time that tells me I need a primary key passed to cfupdate when I've got a primary key passed in, and to top it off it works sometimes (the cfupdate one). This one has to do with lists.
I love lists and list processing in Coldfusion. I use them for everything. But one thing I can't stand (which is something I feel I ought to be able to do), is when I get an exception because the list is too short (or sometimes too long). In this case, I was trying to delete an element from the list, but the element didn't exist. So, I got an "Invalid list index 0" error.
Maybe I'm too used to Ruby and its ability to index arrays with say, -1 to get the last element. But I don't feel its asking too much to have
<cfset listdeleteat(local.hotellist,listcontainsnocase(local.hotellist,"other"))>
not bomb if listcontainsnocase returns 0.
How do you feel? How often do you use lists? All the time like me?
Last modified on Dec 12, 2006 at 09:32 AM UTC - 5 hrs
Posted by Sam on Dec 08, 2006 at 03:12 PM UTC - 5 hrs
This morning, Ed Griffiths asked on the CFCDev mailing list if it was "possible to interrogate some method or metadata associated with [an object] in order to find out what variable name it has been stored within."
I first pointed out that Per Djurner (contributor to CF on Wheels) and myself were chatting over IM about something similar - but with functions. His solution, which I thought was "awesomely creative" (to quote myself on the CFCDev list), was basically to do this: Throw an exception and catch it. Find the line number you are looking for, read the line number, and figure out the variable name (or in this case, function).
Of course, we both hope to find a better solution. Anyway, back to Ed's problem. From my understanding of his question, he just wanted to know the name of a variable who was holding a reference to a CFC. Responses ranged from things like "why would you want to do that?" to "there is probably a way," to "it's not possible because it may have many references" (these aren't true quotes, but paraphrases really). Even Hal Helms chimed in (and I am a fan of his, albeit just recently).
More...
After I posted a function which I thought solves the problem, Teddy Payne mentioned "this looks academic," as in he couldn't find a use for it. I have to agree with Teddy, in that I can't find a use for it either. But, when some one has a tough problem that I can't see immediately how to find an answer to, I like to find an answer. That compulsion gets stronger as the number of "this can't be done" replies increases. =) (I said).
For Per, the problem is more than academic (and this doesn't quite solve it -- I'll investigate that tomorrow). We were discussing ways to dynamically decide what a function should do based on its name.
I started out searching through all the Java stuff to find a solution. When I didn't find one, I thought, why not just search through each scope and compare if the memory address is the same? Well, that didn't work well, but the function below did. I got the idea to insert a UUID key into the CFC and compare the variables in the scope to this from looking through Paul Kenney's cfcUnit (brilliant Paul!).
In any case, if you ever have the need, here's how you can find all the references to an object, but you need to provide the scope to search. This was done because I didn't take the time to figure out if there was a way to reference the "global" variables scope from within a CFC. Now, of course you may want to make it return a list of all the names, or to search all the scopes available, but you get the idea from this.
<cffunction name="getTheNameOfTheVariableThatContainsMe" output="true">
<cfargument name="variablesScope" required="true">
<cfset this.testkey = createUUID()>
<cfloop list="#structkeylist(variablesScope)#" index="name">
<cfif isStruct(variablesScope[name]) and structKeyExists(variablesScope[name],"testKey") and variablesScope[name].testKey eq this.testKey>
#name#,
</cfif>
</cfloop>
<cfset structDelete(this,"testKey")>
</cffunction>
Last modified on Dec 08, 2006 at 04:53 PM UTC - 5 hrs
Posted by Sam on Dec 08, 2006 at 08:47 AM UTC - 5 hrs
Two of the 3 projects I'm working on right now will be built using cfrails for at least some of the development. The third has such a strange architecture that I've never worked with before as to make it hard to see how I might integrate cfrails with it (it's already in version 1, and we've picked it up for version 2 and 3). With the other two, I've already integrated it, and it's quite simple to do.
Therefore, I thought I'd provide some insight in case someone else needed to do it. Both applications are already well established, but we're basically building new subapplications for them, and I've already integrated it for use with single-table manager mini-apps.
Basically, instead of using the provided index.cfm, which routes all the requests, we've already got index.cfms which are used. Now, two options are available here: either use the cfrails index.cfm, and "include" the old one where it says to include the default page, or just change the name of the cfrails index.cfm entirely.
To avoid any potential trouble, I just changed the name. So, now I have cfrails.cfm, where any links that point to actions that cfrails takes care of should go to. So, instead of having index.cfm/controller/action, you'll have cfrails.cfm/controller/action.
More...
Since these applications are already well established, I didn't bother creating any layouts - so the page titles aren't exactly representative of each page, but it helped in that I could just wrap cfrails with the current template, and I was done.
Except, for one last issue: clicking on links back to the "old" part of the application meant that cfrails was looking for actions called "thispage.cfm," and didn't know how to handle it. So, in the newly (re)named cfrails.cfm, I just needed a simple check (after the action was extracted from the URL):
<cfif findnocase(".cfm", action)>
<cflocation url="../../#action#">
</cfif>
It's not something anyone couldn't have figured out, for sure. But, I was just amazed at how easy it was, because this was never a design consideration. I was building it for use on a completely fresh application.
Last modified on Dec 08, 2006 at 08:52 AM UTC - 5 hrs
Posted by Sam on Dec 08, 2006 at 08:20 AM UTC - 5 hrs
After my first couple of trial runs, I was a bit disappointed with the performance of cfrails. It was taking several seconds for simple pages to load, which is completely unacceptable. Of course with everything dynamically synthesized for you, you expect a performance hit, because CF isn't all that fast itself, but several seconds is way too long to wait.
After the disappointment, I tried running it on our production box, and while you could still notice it was a bit slow, it wasn't unacceptable. But, if possible, I want to improve the performance (and I have quite a few ideas on how to acheive that).
So, that brings me to the good news: After about a 3-4 month hiatus on doing anything in Coldfusion (except for the occassional maintenance, for not more than an hour at a time), I'm finally working in a few CF projects again (3, to be exact). Working in CF again cascades the good news to cfrails - our development machine sucks.
More...
Now, I've known this for quite some time - it's still the same box we were running CF 4.5 on. I think it may have had a couple of upgrades since then, but it's certainly not more than 528 MB RAM with a 1 GHz processor. In any case, I was doing some work this morning in a non-cfrails utilizing project, and it is equally slow (whereas a few months ago, when I was developing heavily on it, it was "normal"). That means it's likely cfrails performance isn't as bad as I thought it was, though I won't stick my neck out and say it performs well.
The further good news is that since I'm working in CF again, I'm wanting to use cfrails for the new work - and that means I'll be adding features to it a lot more often than I was in the last 3 months. Which means that sooner rather than later, it will become useful for someone besides me!
Anyway, we've got a new development box that's been in the works for a little while, with all the latest stuff. And since the current one is forcing me to wait longer for pages to load than the time I spend coding (literally), I'm taking a break from coding until we get it up - which will hopefully be soon.
Finally, if you're one of the few people who have downloaded and used cfrails, I'd like to hear from you if you've had performance issues. So let me know through the contact form until I get some comments up and running.
Last modified on Dec 08, 2006 at 08:32 AM UTC - 5 hrs
Posted by Sam on Dec 04, 2006 at 08:31 AM UTC - 5 hrs
Just finished writing a survey on some of relatively current literature on k-means, focusing on introducing it, some practical applications of it, some difficulties in it, and how to find k, the number of clusters. I'm still new to the area, so don't expect much groundbreaking to be done.
The second half focuses on my own experiment, trying to find k using two similar, but slightly different techniques. I failed, but if you'd like to go over it and either laugh at me, or perhaps figure out what I've done wrong, you are free to. =)
Obviously, this isn't going to interest many people, so I didn't take time to mark it up - it's just available as a DOC (I had planned on having a PDF version, but my PDF writer has taken a crap on me). If you don't have Word or Open Office, and would like to read it, contact me and I'll try to get the PDF for you in some way or another.
Anyway, the DOC is here if you want to read it. It's over 3600 words, so beware!
I'm interested to know if anyone has built any machine learning libraries or done anything with machine learning in Coldfusion? My immediate thought is "no way!" because I don't think Coldfusion has the performance for it. But, I wouldn't know, since I haven't tried it. Have you? What's been your experience? Drop me a line if you care to.
Posted by Sam on Dec 03, 2006 at 01:38 PM UTC - 5 hrs
A couple of days ago I wrote about wanting to do a nice test runner interface to my unit (and integration) tests in Coldfusion. Well, it seems that just a couple of days before that, Laura Arguello (possibly in collaboration with her partner, Nahuel Foronda) released cfcUnit Runner on RIA Forge.
Up until now, I've been using CFUnit, about which she says "I believe it could also used to run CFUnit tests, but CFUnit will need to implement a service façade that Flex can use."
I'm going to get cfcUnit and download cfcUnit runner and try it out sometime soon. It looks really sweet. Then, if I can automatically run tests marked as slow or choose to skip all those marked as such, Laura (and Nahuel?) will have saved me a bunch of time and provided for all of us exactly the system I was thinking I wanted!
Update:
Robert Blackburn, creator of CFUnit, said in the comments at Laura and Nahuel's blog that he is indeed working on something similar for CFUnit, and would be willing to implement the service façade Laura mentioned. Awesome!
Last modified on Dec 03, 2006 at 01:46 PM UTC - 5 hrs
Posted by Sam on Nov 30, 2006 at 12:55 PM UTC - 5 hrs
There's been an ongoing discussion in the Coldfusion community for quite some time
now regarding the use of XML for configuration files to your applications.
More recently, Peter Bell has written quite a few posts about it in
The Benefits of XML Config Files (and why I don't use them),
Configuration Files vs. Scripts,
and most recently, Should you use XML for you configuration files?
He references Hal Helms,
Joe Rinehart
(and thanks Jim Collins who wrote (or co-wrote?)
config.cfc for these),
and Martin Fowler.
This post was sort of "sparked" by Jim's release of config.cfc, then my ensuing question about "when and why" I would want to use it (and no, I didn't mean it to sound that provocative), and then Peter's response to which this post title is addressed as "regarding."
I'm a little late to the party, but I thought I'd chime in nevertheless.
More...
First, I want to start off with my position that "there are no best practices, only better practices" (to quote my professor Venkat). And to paraphrase Peter, a lot of people who know a lot more than I do use XML configurations. On the other hand, a lot of people who know a lot more than me don't use them.
Second, I'd like to point out that I found it mildly funny (not in a bad way) in reading some of the reference documents that some of us consider XML to be human readable. I don't think you'd find that statement anywhere except the Coldfusion community.
Finally, now that I've got the mile-long introduction out of the way, let's continue.
In Hal Helms' article, he is touting the benefits of configuration files in general. He makes a convincing argument, and has motivated me to be a better job of extracting things I never thought would should be configurable, unless I was building something that needed to be internationalized. He compared the INI file to those of the XML variety, and mentions that "some configuration information is more complex and is a poor fit for the simple nature of the INI file. In such cases, XML can be the ideal solution." I think it would be hard to have a problem with that statement, especially given the context of the article.
Joe Rinehart also only touches on the topic - he says that XML "provides the easiest way for us to partition off our configuration into logical 'chunks,'" and doesn't go into detail beyond that (for explaining why XML is a Good Thing.
But, Peter goes into a lot more detail about the benefits of XML. In particular, he mentions (Peter, if you feel I've reproduced too much of your article here, let me know and I'll trim it down)
Validation
As long as you have a DTD/Schema for your XML, you can validate XML against the DTD/Schema to confirm that it meets the specificed requirements. This can be extremely useful in pre-checking your data before getting a ColdFusion error because your configuration data was not well formed. Better yet, you don’t need to write any of the validation code – just the DTD/schema.
Manipulation
With XSLT you can transform XML files from one structure to another and you can even query the data using XPath. There are lots of great tools for working with XML files and again, they’re just there. You don’t need to write them.
Editing
There are plenty of good free plug ins for Eclipse and stand alone editors (XMLBuddy seems
to be a popular Eclipse plug in). People are mostly used to editing in XML and there are
good tools with highlighting and that will validate against a DTD/Schema in editor.
Consistency
As in Steve Krug's "Don't Make me think", framework design choices should bear in mind that
many people spend most of their time using something other than your framework. I may not use
MG often, but apart from learning the vocabulary of the DSLs, there is no real learning curve
in terms of how to create an XML config file for Reactor, CS or MG. Same for Mach-II and
anything else that uses XML configuration files. It is usually better to do things the
way people expect so they have less to learn.
Like Peter, I find XML to have a low signal to noise ratio (in "Benefits of XML Config Files...",
though he said "high," if he'll allow me to put words in his mouth, I think he meant low).
I should also put a bit of a disclaimer here: I've spent the last three months working on a Java project, so
I'm sick of XML configuration. And in general, I've only rarely used XML configuration files with Colfusion,
and even then in fairly distant past. In that regard, let me profess some ignorance, especially regarding
DTDs. Lately, I've been preferring programmatic configs (written directly in
CFML/script). However, I've also not been needing much in the way of configuration, so that may help blind me
to the benefits of XML.
In any case, let me get into some reasons as to why, comparing that with the perceived benefits of XML.
Validation:
As opposed to validating my XML file with a DTD/Schema, I validate my code with unit tests. These can similarly
be provided to other programmers to validate their configurations. Now, I don't know how in depth validation
can go, but it seems to me I'll be writing some validation in CF even if I use XML, and if it wasn't well
formed, or did not meet my expectations, the unit tests would catch that. Another thing frequently mentioned
is that it would be better to catch any errors in the spot the error occurred. I agree with this, but
if you are validating your programmatic config file (with unit tests or otherwise), it is easy enough to
throw an exception in that one spot, rather than letting the error propagate through your code.
Manipulation: I don't suppose I can use a converter to change my programmatic config file, but I'm
not sure I see a reason to either. If I chose to, I could query the data with SQL using a query of query,
as opposed to XPath.
Editing: I feel it is as simple to edit CFML as it is XML, so I don't see a benefit here, except the
highlighting he mentions. But, if we're writing CFML, it is easy enough to check for syntax errors, and if
you're using a decent editor, it will also highlight syntax errors for you. I realize it won't highlight
"syntactic" errors by missing out on something you need in the config, but I don't value that highly, since
I cannot remember a time I wrote a config file from scratch, unless I was creating the application (and in
that case, the XML highlighting is unlikely to help you).
Consistency:
As he mentions, there is little to learn in how to configure different apps when they use similar XML. But,
assuming the person configuring the XML file is also the programmer, the part you have to learn is precisely
the part you need to learn in a programmatic configuration file! You don't need to relearn how to do
<cfset name = value>, you need to learn what valid names and values are. In the case
that the person configuring the application is not a programmer, I'd almost certainly have provided a GUI
frontend to the config file, or likely stored it in a database in the first place.
Finally, Peter mentioned that although just a few variables don't need XML, you might need it when
configuring 200 beans for ColdSpring or LightWire (both dependecy injection frameworks). I have a hard time
seeing that something which is weighty for a small project could be anything less than unwieldy for a larger
one. Especially in this example, if I was using something that required an XML configuration file, I would
undoubtedly store the information for all those beans in a database, and write a script that would write
my XML file for me.
Overall, I like what Martin Fowler said the best:
"I often think that people are over-eager to define configuration files. Often a programming language
makes a straightforward and powerful configuration mechanism... My advice here is to always provide
a way to do all configuration easily with a programmatic interface, and then treat a separate
configuration file as an optional feature."
So having said all that, if and when I find a good case for using an XML configuration file, I'll gladly do so,
and so should you. Nor should we discount XML - as Peter said and I agree, a lot of really smart people
use it. But at the moment, I don't see a need for the excess clutter in my life - CFML provides
enough of that for me =).
Last modified on Nov 30, 2006 at 04:58 PM UTC - 5 hrs
Posted by Sam on Nov 29, 2006 at 01:30 PM UTC - 5 hrs
As I'm finishing up a Ruby on Rails project today, I've been reflecting on some of the issues we had, and what caused them. One glaring one is our lack of automated tests - in the unit (what Rails calls unit, anyway) test and functional test categories.
The "unit" tests - I'm not too concerned about, overall. These tests run against our models, and since most of them simply inherit from ActiveRecord::Base (ActiveRecord is an ORM for Ruby), with some relationships and validation thrown in (both of which taken care of by ActiveRecord). In the few cases we have some real code to test, we've (for the most part) tested it.
What concerns me are the functional tests (these test our controllers). Of course, Rails generates test code for the scaffolds (if you use them), so we started with a nice, passing, suite of tests. But the speed of development in Rails combined with the lack of a convenient way to run tests and the time it takes to run them has caused us to allow our coverage to degrade, pretty severely. It contributed to very few automated tests being written, compared with what we may have done in a Java project, for example.
Of course, there were some tests written, but not near as many as we'd normally like to have. When a small change takes just a couple of seconds to do and and (say, for instance) 30 seconds to run the test, it becomes too easy to just say, "forget it, I'm moving on to the next item on the list." It definitely takes a lot of discipline to maintain high coverage (I don't have any metrics for this project, but trust me, its nowhere near acceptable).
Well that got me thinking about Coldfusion. I notice myself lacking in tests there as well. I'd traditionally write more in Coldfusion that what we did on this Rails project, but almost certainly I'd write less than in an equivalent Java project. And it's not just less because there is less code in a CF or Rails project than in Java - I'm talking more about the percent of code covered by the tests, rather than the raw number. It's because there is no convenient way to run them, and run them quickly.
For Rails development, I'm using RadRails (an Eclipse plugin), so at least I can run the tests within the IDE. But, there is no easy way to run all the tests. I take that back, there is, but for some reason, it always hangs on me at 66%, and refuses to show me any results. I can also use rake (a Ruby make, in a nutshell) to run all the tests via the console, but it becomes very difficult to see which tests are failing and what the message was with any more than a few tests. Couple this with the execution time, and I've left testing for programming the application.
In Coldfusion, it takes quite a while to run the tests period. This is due partly to the limitations of performance in creating CFCs, but also to the fact I'm testing a lot of queries. But at least I can run them pretty conveniently, although it could be a lot better. Now, I've got some ideas to let you run one set of tests, or even one test at a time, and to separate slow tests from fast ones, and choose which ones you want to run. So, look out in the future for this test runner when I'm done with it (it's not going to be super-sweet, but I expect it could save some much-needed time). And then the next thing to go on my mile-long to-do list will be writing a desktop CF server and integrate the unit testing with CFEclipse... (yeah, right - that's going on the bottom of the list).
Last modified on Nov 29, 2006 at 01:35 PM UTC - 5 hrs
Posted by Sam on Nov 22, 2006 at 07:53 AM UTC - 5 hrs
A common problem I've been having and seeing lately is dealing with components that should read files in locations they don't know about. For instance, you have component Model in cfrails, which should read a configuration file in the project that is using it. I didn't want to have to create a mapping for every project, and I didn't want to have to figure out the ../../../../etc between the two directories to pass the value in to Model. So, here's a function which takes care of the mapping for you. If you needed, it would be trivially easy to add a new parameter for base template, if you didn't want to use the actual base template as your basis for inclusion.
It doesn't have any associated automated tests, mainly because I can't figure out how I'd test something like this. So, I tested it manually in 3 different directory structures, and it works fine for me. If you ever find a need for this, and encounter problems, I'd like to know about it - especially the directory structures your using so I can replicate and fix it.
So, without further ado, here's the code:
More...
<cffunction name="includeRelativeToBaseTemplate" description="Given the current template's path, includes a file relative to the base template path" output="true" access="private">
<!---
why ?
Because sometimes, even though the "current template path" is known from getCurrentTemplatePath,
cfinclude appears to use it's _actual_ current template. For example, you have
A.cfc in dir1, and B.cfc, which extends A.cfc, but it resides in another directory. But, you
want to cfinclude a file within A.cfc relative to the file that instantiated B.cfc. Well, I didn't
find it very simple, so I created this function. =)
--->
<cfargument name="currentTemplate" hint="The template which should be relative to.">
<cfargument name="relativePath" hint="The relative path to the include, from the base template.">
<cfset var local=structNew()>
<cfset local.baseTemplate = getBaseTemplatePath()>
<cfset local.curTemplate = arguments.currentTemplate>
<cfset local.relative=arguments.relativePath>
<!--- in case of unix, convert slashes --->
<cfset local.baseTemplate = replace(local.baseTemplate,"\","/","all")>
<cfset local.curTemplate = replace(local.curTemplate,"\","/","all")>
<cfloop from="1" to="#max(listlen(local.baseTemplate,'/'),listlen(local.curTemplate,'/'))#" index="local.i">
<cfset local.baseDir=listGetAt(local.baseTemplate,local.i,"/")>
<cfset local.curDir=listGetAt(local.curTemplate,local.i,"/")>
<cfif local.baseDir neq local.curDir>
<cfbreak>
</cfif>
</cfloop>
<cfset local.goBackTimes=listlen(local.curTemplate,'/')-local.i>
<cfset local.dotDotSlash = repeatString("../", local.goBackTimes)>
<cfset local.newPath=listDeleteAt(local.baseTemplate,listLen(local.baseTemplate,"/"),"/")>
<cfloop from="1" to="#local.i-1#" index="local.k">
<cfset local.newPath = listDeleteAt(local.newPath,1,"/")>
</cfloop>
<cfif listlen(local.baseTemplate,'/') lt listlen(local.curTemplate,'/')>
<cfset local.dotDotSlashesInRelative = listvaluecount(local.relative,"..","/")>
<cfloop from="1" to="#local.dotDotSlashesInRelative#" index="local.k">
<cfset local.newPath = listDeleteAt(local.newPath,listLen(local.newPath,"/"),"/")>
</cfloop>
<cfset local.relative = replace(local.relative,"../","","all")>
</cfif>
<cfset local.newPath = local.dotDotSlash & local.newPath & "/" & local.relative>
<!---if fileExists(expandPath(local.newPath)) - cf using different relative path than current? --->
<cftry>
<cfinclude template="#local.newPath#">
<cfset result = true>
<cfcatch>
<cfset result = false>
</cfcatch>
</cftry>
<cfreturn result>
</cffunction>
Last modified on Nov 22, 2006 at 07:59 AM UTC - 5 hrs
Posted by Sam on Nov 19, 2006 at 04:45 PM UTC - 5 hrs
Today I discovered Peter Bell's blog, Application Generation, and it's an absolute gem. It looks like he's working on and interested in a lot of the same stuff I am. What his blog covers is all in the title - application generation, and has a particular bent towards Coldfusion in many posts. However, it's also good general, and I'd reccommend it even for non-CF developers.
Posted by Sam on Nov 04, 2006 at 07:29 PM UTC - 5 hrs
So, the last couple of weeks I've been hard at work with school stuff, and also we've started a new (well, massively adding on to an existing one) project at work (and now another new one, as of last Wednesday). Because I seem to be so incredibly busy, and the projects need to be done "yesterday" (don't they all?), I built myself a little helper application that should increase my velocity by a ton - no more repetitive busy-work (well, it is greatly reduced anyway).
I've quite unimaginatively called it cfrails, since it was inspired by Ruby on Rails, and you can find it's project page at RIA Forge.
But first, you might want to read Getting Started with cfrails, so you can see how easily 0 lines of real code can create an interface to your database (the only lines are a couple of setup things, and cfcomponent creation).
I'd like to know what you think, so please leave a comment.
Last modified on Nov 04, 2006 at 07:30 PM UTC - 5 hrs
Posted by Sam on Oct 26, 2006 at 05:20 PM UTC - 5 hrs
(or scopes as structs, as it were)
So, what would you expect the output of this to be, and why?
<cfset url.test = 1>
<cfset tempurl = structcopy(url)>
<cfset structdelete(tempurl, "test")>
<cfoutput>
#structkeyexists(url,"test")#
</cfoutput>
I thought it should be "YES", but in fact it is "NO." I'm sure I'm overlooking something - or else I'm stating something everyone already knows. I've posted to the CFCDev list - perhaps someone there can help me understand.
I'm using Macromedia's CFMX 6.1, for reference. I don't know how this behaves in 7.
More...
Update: Sean Corfield wrote about this behavior back in 2004. It's quite a bit annoying, since CF says it is a struct, and treats it like one in just about every way you can imagine, except for this. I'm getting the same behavior using the duplicate() function as well. Guess I'll have to copy it manually.
Update 2: Actually, I said in the last post I was getting the same behavior using duplicate(), but I was wrong.
I wasn't doing the exact same thing, but I was doing something I would still expect to work. Here it is:
<cfset form.test = 1>
<cfset tempform = duplicate(form)>
<cfset structdelete(form, "test")>
<cfset form=duplicate(tempform)>
<cfoutput>
In Form: #structkeyexists(form,"test")#<br/>
In Temp Form: #structkeyexists(tempform,"test")#
</cfoutput>
Still strange.
Update 3: I didn't think about it until this morning (November 1, 2006), but this is a gross violation of LSP ( Read Uncle Bob's PDF on LSP). Now, I know the underlying Java classes are different, as Sean Corfield pointed out in the post I linked to above, but to me, if you return a true value from isStruct(form), then that tells me it ought to behave in every way like a structure.
Last modified on Nov 01, 2006 at 08:14 AM UTC - 5 hrs
Posted by Sam on Oct 26, 2006 at 11:42 AM UTC - 5 hrs
Barry Beattie wrote recently on the CFCDev mailing list a question asking, "if it were Java/JSP, would you bother generating great sections of HTML within the java classes instead of leaving it to the JSP to take care of?"
It got me thinking again about my own use of HTML in CFCs.
At first, I thought it was a valid point - of course I would never consider using HTML in a Java class. But, the more I thought about it, the fuzzier the line got. As it turns out, I could go either way on the CFC/tag issue, depending on the specific case.
More...
In Java/JSP, no, I would almost never write the HTML in a class. I may have some small bits in a UI class from time to time, but never more than a single tag or perhaps two. But, it is not for any other reason than writing HTML like the following is completely unreadable and impossible to follow, and more importantly easy to screw up:
String somehtml = "<html>";
somehtml += "<head><title>" + titleOfThisPage + "</title>";
somehtml += "<meta ...></head>";
...
Can you imagine doing an entire page like that? Or even just a table with more than a couple of columns? It's unwieldy.
With CFC's however, you can still keep the HTML in its readable form. In some cases, I prefer to use CFCs to accomplish the goal of reuse, while in others, I prefer to use includes. I find myself preferring CFCs in particular, in cases where there may be slight customizations to a basic display, based on individual client preferences. I can inherit (or aggregate, if it makes more sense) from the base display (cut up into logical chunks) and reuse those parts which make sense, and only rewrite the custom bits. It lets me keep duplicate code to the absolute minimum - something I'm very fond of these days. The inheritance in particular has the extra benefit of allowing me to keep client code unchanged, as long as I've followed Liskov Substitution Principle.
Last modified on Oct 26, 2006 at 11:44 AM UTC - 5 hrs
Posted by Sam on Oct 18, 2006 at 11:12 AM UTC - 5 hrs
Well, I guess I lied when I said xorBlog wouldn't be developed until I had caught up on my writing. I still haven't gotten caught up, but this morning I couldn't stand it any more - I had to have a way to categorize posts. Now, I didn't TDD these, and I didn't even put them in the right place. True to the name of the blog, I interspersed code where it was needed. I feel absolutely dirty, but I just couldn't spare the time at the moment to do it right, and I could no longer endure not having any categories. So, I took about 15 minutes, coded up a rudimentary category system, violated DRY in 2 places, and put a few comments like "this needs to be refactored into a CFC" throughout the code (as it needed).
At least I have some categories now (its not as gratifying a feeling as I thought it would be, however). I plan on refactoring this as soon as I have a chance. I'll write about it as well - it might make for some more interesting reading in the TDDing xorBlog series of posts.
Last modified on Oct 18, 2006 at 11:14 AM UTC - 5 hrs
Posted by Sam on Oct 03, 2006 at 11:26 AM UTC - 5 hrs
It appears that way, with Coldfusion 6.1. I stumbled across this today, so I thought I'd share what I observed.
In a nutshell, I've got a security object, which handles all the login related information and rules. Also, it is stored in the session. Of course, you wouldn't want to do that if you were planning on running on clustered servers, because of Coldfusion's cfc serialization session issue (at least in Macromedia/Adobe's variety). But, that is beside the point.
Basically, what happens is:
- If the security object is not defined, create it
- The security object creates a cookie which stores the userID (encrypted)
- later, I check the userID by calling a method on the security object
The cookie is set to expire when the user logs out, or when they close the browser.
So what happens?
In Firefox, when the browser is closed, both the session and the cookie are destroyed, so that when the user returns, everything happens again as I originally expected.
In Internet Explorer, however, when the browser is closed, only the cookie is destroyed. When the user returns before the session would normally time out, they get an error, because the security object still exists and expects the cookie to exist too.
I wonder where the real difference lies?
Last modified on Oct 03, 2006 at 11:27 AM UTC - 5 hrs
Posted by Sam on Sep 13, 2006 at 09:34 AM UTC - 5 hrs
It may be that I'm still so new to Java that I don't know a good way around this, or it may be that I'm so used to the convenience of Coldfusion that I build tools in Java to help it act more like Coldfusion, but I was having some trouble with MVC in Java. I didn't see why something in my View layer should be importing anything from the package java.sql, such as ResultSet.
Moreover, I wanted to open and close my Connection to the database (and the Statement/ PreparedStatement in the Model layer, and doing so would have prevented the ResultSet from being available to the View.
Enter QueryResult. QueryResult simply takes as a parameter a ResultSet and creates a HashMap where each key is a column name, and accessing it gives you an array of the rows' values for that column.
Thus you can get the fifth row of the column email by doing this:
QueryResult qr = new QueryResult(someResultSet);
String emailInRow4 = (String) qr.get("email")[4];
It's not the greatest thing in the world, but it works better than the alternative. I plan to put the code up here for it later, so maybe it could help someone else as well.
Last modified on Sep 13, 2006 at 09:37 AM UTC - 5 hrs
Posted by Sam on Aug 29, 2006 at 09:27 AM UTC - 5 hrs
Now that we can insert posts, it is possible to update, select, delete, and search for them. To me, any
one of these would be a valid place to go next. However, since I want to keep the database as unchanged
as possible, I'll start with test_deletePost(). This way, as posts are inserted for
testing, we can easily delete them.
Here is the code I wrote in xorblog/cfcs/tests/test_PostEntity:
<cffunction name="test_deletePost" access="public" returnType="void" output="false">
<cfset var local = structNew()>
<cfset local.newID=_thePostEntity.insertPost(name="blah", meat="blah", originalDate="1/1/1900", author="yoda")>
<cfset local.wasDeleted = _thePostEntity.deletePost(local.newID)>
<cfset assertTrue(condition=local.wasDeleted, message="The post was not deleted.")>
<cfquery name="local.post" datasource="#_datasource#">
select id from post where id = <cfqueryparam cfsqltype="cf_sql_integer" value="#local.newID#">
</cfquery>
<cfset assertEquals(actual = local.post.recordcount, expected = 0)>
</cffunction>
And the corresponding code for deletePost():
<cffunction name="deletePost" output="false" returntype="boolean" access="public">
<cfargument name="id" required="true" type="numeric">
<cfset var local = structNew()>
<cfset local.result = false>
<cftry>
<cfquery name="local.del" datasource="#_datasource#">
delete from post where id = <cfqueryparam cfsqltype="cf_sql_integer" value="#id#">
</cfquery>
<cfset local.result=true>
<cfcatch>
</cfcatch>
</cftry>
<cfreturn local.result>
</cffunction>
Originally, I just left the test as asserting that local.wasDeleted was true. However, writing just
enough of deletePost() in xorblog/cfcs/tests/PostEntity to get the test to pass resulted in the
simple line <cfreturn true>. Since that would always pass, I also added a check that
the inserted post no longer existed.
Now that we have some duplicate code, its definitely time to do some refactoring. More on that next time.
(To be continued...)
Posted by Sam on Aug 28, 2006 at 11:46 AM UTC - 5 hrs
We left off after writing the test for the insertPost() method. Now, we're going to make
that test pass by writing the code for it. First you'll need to create PostEntity.cfc in the xorblog/cfcs/src
directory, and make sure to surround it in the proper <cfcomponent> tags.
What follows is that code:
<cffunction name="insertPost" output="false" returntype="numeric" access="public">
<cfargument name="name" required="true" type="string">
<cfargument name="meat" required="true" type="string">
<cfargument name="originalDate" required="true" type="date">
<cfargument name="author" required="true" type="string">
<cfset var local = structNew()>
<cftransaction>
<cfquery name="local.ins" datasource="#variables._datasource#">
insert into post
(name, meat, originalDate, lastModifiedDate, author)
values
(<cfqueryparam cfsqltype="cf_sql_varchar" value="#arguments.name#">,
<cfqueryparam cfsqltype="cf_sql_longvarchar" value="#arguments.meat#">,
<cfqueryparam cfsqltype="cf_sql_timestamp" value="#arguments.originalDate#">,
<cfqueryparam cfsqltype="cf_sql_timestamp" value="#arguments.originalDate#">,
<cfqueryparam cfsqltype="cf_sql_varchar" value="#arguments.author#">,
</cfquery>
<cfquery name="local.result" datasource="#_datasource#">
select max(id) as newID from post
where originalDate=<cfqueryparam cfsqltype="cf_sql_timestamp" value="#arguments.originalDate#">
and name=<cfqueryparam cfsqltype="cf_sql_varchar" value="#arguments.name#">
</cfquery>
</cftransaction>
<cfif local.result.recordcount is 0>
<cfthrow message="The new post was not properly inserted.">
</cfif>
<cfreturn local.result.newID>
</cffunction>
There isn't really anything special here, unless you are new to Coldfusion. If that's the case, you'll
want to take note of the <cfqueryparam> tag - using it is considered a "best practice" by
most (if not all) experienced Coldfusion developers.
The other item of note is that if you were to run this code by itself,
it still wouldn't work, since we haven't defined variables._datasource. Many developers
would do this in a function called init() that they call each time they create an object. I've
done it as well.
I suppose if you were rigorously following the
YAGNI principle, you might wait until creating the next
method that would use that variable before defining it. I certainly like YAGNI, but my
OCD is not so bad that I won't occasionally allow
my ESP to tell me that I'm going to use something,
even if I don't yet need it. With that said, I try only do it in the most obvious of cases, such as this one.
Now that we've written the code for insertPost(), its time to run the test again. Doing so,
I see that I have two test that run green (this one, and our test_hookup() from earlier.
We've gone red-green, so now it's time to refactor. Unfortunately, I don't see any places to do that
yet, but I think they'll reveal themselves next time when we write
our second test and second method in PostEntity. (To be continued...)
Last modified on Aug 28, 2006 at 11:52 AM UTC - 5 hrs
Posted by Sam on Aug 25, 2006 at 12:34 PM UTC - 5 hrs
So we decided that blog software centers around posts and that for any other feature
to be useful, we'd need them first. Therefore, we'll start with a model component for our posts,
and we'll call it PostEntity. Before I create that file though, I'm going to go back
into my test_PostEntity.cfc file and write a test or two for some functionality that
PostEntity should provide.
Thinking of things we should be able to do regarding the storage of posts, it's easy to identify
at least insert(), update(), and delete(). However,
since you can't update or delete a post that doesn't exist, I figured I'd start with adding a post.
I came up with the following test:
<cffunction name="test_insertPost" access="public" returntype="void" output="false">
<cfset var local = structNew()>
<cfset local.nameOfPost = "My Test Post" & left(createUUID(),8)>
<cfset local.meatOfPost = "The meat of the post is that this is a test." & left(createUUID(),8)>
<cfset local.dateOfPost = now()>
<cfset local.author = "Sam #createUUID()#">
<cfset local.newID=_thePostEntity.insertPost(name=local.nameOfPost, meat=local.meatOfPost, originalDate=local.dateOfPost, lastModifiedDate=local.dateOfPost, author=local.author)>
<cfquery name="local.post" datasource="#variables._datasource#">
select name, meat, originalDate, author
from post
where id = <cfqueryparam cfsqltype="cf_sql_integer" value="#local.newID#">
</cfquery>
<cfset assertEquals(actual=local.post.name, expected=local.nameOfPost)>
<cfset assertEquals(actual=local.post.meat, expected=local.meatOfPost)>
<cfset assertEquals(actual=local.post.author, expected=local.author)>
<!--- dateCompare isn't working correctly, so we are testing each datepart --->
<cfset assertEquals(actual=month(local.post.originalDate), expected=month(local.dateOfPost))>
<cfset assertEquals(actual=day(local.post.originalDate), expected=day(local.dateOfPost))>
<cfset assertEquals(actual=year(local.post.originalDate), expected=year(local.dateOfPost))>
<cfset assertEquals(actual=hour(local.post.originalDate), expected=hour(local.dateOfPost))>
<cfset assertEquals(actual=minute(local.post.originalDate), expected=minute(local.dateOfPost))>
<cfset assertEquals(actual=second(local.post.originalDate), expected=second(local.dateOfPost))>
<!--- clean up --->
<cfquery datasource="#_datasource#">
delete from post where id = #local.newID#
</cfquery>
</cffunction>
You'll notice I used a UUID as part of the data. There's no real point to it, I suppose. I just wanted to have
different data each time, and thought this would be a good way to achieve that.
You should also be uncomfortable about the comment saying dateCompare isn't working - I am anyway. It doesn't
always fail, but occasionally it does, and for reasons I can't figure out, CFUnit isn't reporting why. For
now, so I can move on, I'm assuming it is a bug in CFUnit. Since I can test each date part that is
important to me individually and be sure the dates are the same if they all match, I don't feel
too bad.
Another thing to note is the use of the var local. By default, any variables created
are available everywhere, so to keep them local to a function, you need to use the var keyword.
I like to just create a struct called local and put all the local variables
in there - it just makes things easier.
Finally, some people might not like the length of that test. Right now, I don't either, but we'll see
what we can do about that later. Others may also object to using more than one assertion per test. I don't
mind it so much in this case since we really are only testing one thing. If you like, you could also
create a struct out of each and write a UDF like
structCompare() and do the assertion that way. I haven't tested this one personally, but
there is one available at cflib.
In either case, I don't see much difference, other than one way I have to write more code than I need.
Now I run the test file we created and find that, as expected, the test still fails. Besides the fact that
we don't even have a PostEntity.cfc, we haven't yet instantiated an object of that type, nor have
we defined _datasource and the like. Let's do that in the setUp() method.
<cffunction name="setUp" access="public" returntype="void" output="false">
<cfset variables._datasource="xorblog">
<cfset variables.pathToXorblog = "domains.xorblog">
<cfset variables._thePostEntity = createObject("component", "#variables.pathToXorblog#cfcs.src.PostEntity").init(datasource=_datasource)>
</cffunction>
Now our tests still fail, because we have no code or database. So create the datasource and
database with columns as needed:
id (int, primary key, autonumber)
name (nvarchar 50)
meat (ntext)
originalDate (datetime)
lastModifiedDate (datetime)
author (nvarchar 50)
Next time, we'll start coding and get our first green test. (To be continued...)
Last modified on Aug 29, 2006 at 08:38 AM UTC - 5 hrs
Posted by Sam on Aug 22, 2006 at 08:54 AM UTC - 5 hrs
I know there is a general disdain for using CFCs to produce the view layer in applications, but I wanted to take the time to explain when I use it: in situations where several customers will be using the same application (hosted on the same server as well).
In my more inept days, long before CFCs were introduced, I just deployed different versions of the same application to the different directories that housed each client's specific version of the application. This was nice because it allowed customization, but of course it became a giant pain having to fix the same bugs in several different places. The same was true if there was an improvement which would benefit everyone.
Eventually, (still before CFCs) I had the idea to just keep a common code base and <cfinclude> the needed files in each client's own directory. I even built the application(s) such that they would <cfinclude> some custom code in spots that required customer-specific computations or outputs. As you might expect, it wasn't long before customers started asking for changes which couldn't be done in the "customer-specific" includes very easily. It became much easier just to write
<cfif customerID is theCustomerRequestingThisChange>
... do something ...
<cfelse>
... do something for everyone else ...
</cfif>
in the middle of the common code rather than do it correctly. Because of the problems with the different versions I mentioned above, I was very reluctant to "branch" clients into differing code bases - so the code became littered with <cfif>'s and got to be a nightmare to maintain.
Finally, along came CFCs. I could have a component and aggregate it into another or inherit from it in another, and only make the changes I needed to those methods which needed it for those clients who needed it. A silver bullet (almost) for all my problems! The werecode was killed!
But, everywhere I look I see everyone telling me not to use HTML in CFCs! So what do you do in the situation where one client's form
has to differ slightly from the common code? For instance, you might have a form that has a name section, a contact information section, an address section (or two), and perhaps more. Suppose one client wants to track some other information specific to them, and they want it placed just below the name section and just above the contact information. Do you rewrite the form for that client? While you would be following "best practices," this can lead to similar situations as described above.
I've been placing the common code in CFCs - and with great results. Each section of the form can be its own function, to be called in a main displayForm() function. Then, if a client needs a new section, I simply have to rewrite displayForm() and write the new part of the form. If they need to change the order of some fields within a section, I only have to rewrite that section. Its really helped me cut down on duplicate code and helped me follow the DRY principle.
What do you do in similar situations?
Last modified on Aug 22, 2006 at 09:06 AM UTC - 5 hrs
Posted by Sam on Aug 20, 2006 at 10:38 AM UTC - 5 hrs
Since I wanted to start this blog, I thought it would be good practice to write the software that runs it
using test-driven development. I've used a bit of TDD recently for additions to existing applications, but
I've not yet started writing an application using it from beginning to end. I'm getting sick of
eating Italian microwaveable dinners when I have to maintain code. This is my chance to eat something else.
So, without further ado, we'll jump right in.
The first thing I did of course, was to create my directory structure. For the time being, we have:
xorblog/cfcs/src
and
xorblog/cfcs/tests
I like to keep the tests separate from the source. I don't have a reason behind it, other than it helps
keep me a bit organized.
Next, I thought about what a blog needs. We want to deliver items that have the highest business value first,
and move on to things that are lower on the value scale later. In doing this, we get a working application
sooner rather than later, and hence the blog can be used at the earliest possible moment in its development.
With that in mind, we probably shouldn't start with things like Comments or functionality
that lets us get included in places like Technorati. Since
you need content to make anything else useful, I thought I'd start with that. Indeed, the Post is
the core part of a blog. Therefore, the first thing I did was create test_PostEntity.cfc under
xorblog/cfcs/tests.
Now, I'm using CFUnit for my tests, and this assumes you already have it set up. If you need help on
that, you can visit CFUnit on SourceForge.
The first thing I do in test_PostEntity.cfc is write test_hookup(),
to make sure everything is working:
<cfcomponent extends="net.sourceforge.cfunit.framework.TestCase" output="false" name="test_PostEntity">
<cffunction name="test_hookup" access="public" returntype="void" output="false">
<cfset assertEquals(expected=4, actual=2+2)>
</cffunction>
</cfcomponent>
Next, we need a way to see the status of and run our tests. For this we have test_runner.cfm, which
for the most part just copies what you'll find at the CFUnit site linked above:
<cfset testClasses = ArrayNew(1)>
<cfset ArrayAppend(testClasses, "domains.xorblog.cfcs.tests.test_PostEntity")>
<!--- Add as many test classes as you would like to the array --->
<cfset suite = CreateObject("component", "globalcomponents.net.sourceforge.cfunit.framework.TestSuite").init( testClasses )>
<cfoutput>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>Unit Tests for xorBlog</title>
</head>
<body>
<h1>xorBlog Unit Tests</h1>
<cfscript>
createobject("component", "globalcomponents.net.sourceforge.cfunit.framework.TestRunner").run(suite,'');
</cfscript>
</body>
</html>
</cfoutput>
Finally, we run that page in a browser to make sure the test runs green - and it does.
Now that we have our test environment set up, we can start writing tests for our PostEntity
that doesn't yet exist. (To be continued...)
Last modified on Aug 20, 2006 at 10:49 AM UTC - 5 hrs
Posted by Sam on Aug 17, 2006 at 01:48 PM UTC - 5 hrs
I'm either an idiot, or a moron. But, I have courage and that's what matters. Let me explain:
Ever since I started messing with inheritance with CFCs in Coldfusion, I have lamented the
"fact" they didn't have a way to override a parent's method while retaining the functionality via
a call to super.methodInQuestion(). I got so sick of it, in fact, I came up
with this brilliant way to re-use code and not repeat myself - I'd have component
Parent with methods foo(arg1, arg2) and theRealFoo(arg1, arg2) where
foo() simply called theRealFoo() with the arguments it had been passed.
Following me so far?
Then in component Child, when I needed to slightly modify the behavior of foo()
and still use its code, I could simply do so by calling theRealFoo() within my
Child version of the method. Sweet!
Of course I had tried using super, but I kept getting this strange error:
|
Error Occurred While Processing Request
|
Cannot invoke method method1 on an object of type coldfusion.runtime.Struct with named arguments.
|
|
Use ordered arguments instead.
|
|
What? I wasn't trying to invoke a method on a struct, was I? I thought this was just one of those random CF errors that get thrown which seem to have nothing to do with the problem, especially since it was right there in big bold letters. I never read the fine print.
Well, since then I had read that it did exist, and I tried again - but got the same error. I came to the conclusion that it became part of the language in version 7.0, since I don't yet have it. And lately I've been reading and writing with the Gurus on the CFCDev mailing list, and I finally decided to ask: Am I a moron or is there no super in CF6.1? Well, as it turns out, I am a moron. I should have read the fine print.
Last modified on Aug 18, 2006 at 07:21 AM UTC - 5 hrs
|
Me

|