Posted by Sam on Mar 13, 2013 at 08:45 AM UTC - 5 hrs
I recently made a proof-of-concept to get MS Word to edit documents in a Rails app and save them back to the server, using Devise for authentication. It wasn't straightforward, so I thought I'd mention the steps I took to get it done.
I used Rails 3.2.12 with rack_dav providing the WebDAV functionality.
There's also dav4rack which was based on rack_dav, and adds a few features.
I started with rack_dav, and had all of the kinks worked out except for the authentication, when I noticed dav4rack included authentication. So I switched to dav4rack, but I had some trouble with it, so I switched back to rack_dav because I feared I'd get into another day-or-two-long yak shaving session.
You might check it out though, and see if it works just as well.
Anyway, here's the basis of what I did.
1. Add the gem to my Gemfile (and run bundle install):
gem 'rack_dav'
2. Mount it in my routes.rb, wrapped with basic authentication:
webdav = RackDAV::Handler.new(:root => 'private/docs/', :resource_class => LockableFileResource)
webdav_with_auth = Rack::Auth::Basic.new(webdav) do |username, password|
user = User.find_for_authentication(:email => username)
user && user.valid_password?(password)
end
mount webdav_with_auth, at: "/webdav_docs"
3. Create my lockable file resource, which doesn't really do any locking (since this was just a PoC), so you probably want to fix that:
More...
class AuthenticableFileResource < RackDAV::FileResource
def lock(locktoken, timeout, lockscope=nil, locktype=nil, owner=nil)
puts "token: #{locktoken}"
puts "timeout: #{timeout}"
puts "scope: #{lockscope}"
puts "type: #{locktype}"
puts "owner: #{owner}"
@@owner ||= owner
@@locktype ||= 'exclusive'
@@lockscope ||= 'all day'
return [60, @@lockscope, @@locktype, @@owner]
end
def unlock(a)
@@owner = nil
@@locktype = nil
@@lockscope = nil
return true
end
end
4. Tell the browser to instruct Word to open the file: For users on the web, we don't want the default rendering of the WebDAV root, because we'd like these docs to be editable in Word, which means you have to tell Word to open it. While you could add this to your own resource collection, I just created an action to list the links to the files with the code to open it in Word. Here's the basis of what you need in the view:
<script>
function officelink(link) {
try {
new ActiveXObject("SharePoint.OpenDocuments.4").EditDocument(link.href);
return false;
}
catch(e) {
try {
document.getElementById("winFirefoxPlugin").EditDocument(link.href);
return false;
}
catch(e2) {
return true;
}
}
}
</script>
<a href="/webdav_docs/inetfilter.doc" onclick="return officelink(this)">inetfilter.doc
<object id="winFirefoxPlugin" type="application/x-sharepoint" width="0" height="0" style="visibility: hidden;"></object>
Users who have Office 2010 installed on their system will also have those 2 plugins installed on their system, so we try to use them and return false (preventing the browser from following the link) if they have it. For those who don't, the JS provides a way to just download the file. See OpenDocuments Control API and FFWinPlugin Plug-in API for more info about what you can do with those plugins.
5. Tell Rails not to parse params for our mounted rack_dav app. For whatever reason, Word will try to save the file back to the server, PUTting it with the mime type application/xml, but it doesn't wrap in XML. I don't suppose it's supposed to, but it would be nice if it played well with Rails. Unfortunately, Rails understandably barfs when you tell it to parse parameters from XML and didn't send any XML. So, I had to create a patch and stuck it in an initializer. All we do is figure out if the request is for where we mounted rack_dav: if so, let rack_dav handle it without parsing the params. If not, just parse the params as normal:
module ActionDispatch
class ParamsParser
old_call = instance_method(:call)
define_method(:call) do |env|
if env["PATH_INFO"] =~ /\/webdav_docs\//
@app.call(env)
else
old_call.bind(self).(env)
end
end
end
end
There may be some security problems with this if rack_dav parses request parameters like Rails did before they put out their security updates in January and February 2013. I plan to review the rack_dav code to make sure it doesn't expose the same problems Rails had before I put this in production, and I'd recommend you do the same before you do.
6. Tell Devise not to authenticate OPTIONS or PROPFIND requests. This is needed if you redirect your root url to a protected controller/action, because when Word makes requests using these methods, you'll get redirected and asked for authentication on a web page, which totally breaks the whole concept. This is probably in your application_controller.rb, unless you moved it. So if you moved it, you'll need to make the change there.
class ApplicationController < ActionController::Base
protect_from_forgery :unless=>:options_request?
before_filter :authenticate_user!, :unless=>:options_request?
def options_request?
request.method == "OPTIONS" || request.method == "PROPFIND"
end
end
That's all. Feel free to ask any questions if something is unclear or not working for you!
Hey! Why don't you make your life easier and subscribe to the full post
or short blurb RSS feed? I'm so confident you'll love my smelly pasta plate
wisdom that I'm offering a no-strings-attached, lifetime money back guarantee!
Last modified on Mar 13, 2013 at 08:54 AM UTC - 5 hrs
Posted by Sam on Feb 20, 2013 at 09:42 AM UTC - 5 hrs
Last week at the Houston Ruby User Group I made a presentation called "The Website's Slow" Tips and Tools for Identifying Performance Bottlenecks.

That link is to the slides and notes on each slide mentioning a little about what I said.
Basically I went through a couple of different classes of performance issues you're likely to see on the server side of things, what tools you might use to make finding the issue easier, how you can interpret some of the data, and even a suggestion here or there about what to do to resolve common issues I've seen.
Let me know what you think! (Or, if you have any questions, feel free to ask!)
Last modified on Feb 20, 2013 at 09:48 AM UTC - 5 hrs
Posted by Sam on Feb 27, 2012 at 07:45 AM UTC - 5 hrs
Here's a 35 minute recording of the presentation which I gave to houstonrb on February 21, 2012. It is a practice run I did before the live presentation, so you won't get the discussion, but hopefully you'll find it useful anyway.
How to avoid becoming a formerly-employed Rails developer standing in line at the OOP Kitchen from Sammy Larbi on Vimeo.
You can find the slides here: Slides for the Rails OOP presentation
There is also reference to a project whose purpose is to eventually be a full-scale demonstration of the techniques: Project for the Rails OOP presentation
Let me know what you think in the comments below.
Updated to use HTML5 player at Vimeo.
Last modified on Mar 01, 2012 at 06:10 AM UTC - 5 hrs
Posted by Sam on Feb 01, 2012 at 05:41 AM UTC - 5 hrs
You know when you see code like this:
class CompulsionsController < ApplicationController
# ... standard actions above here
def update
if params[:obsessions].include?(ObsessionsTypes[:murdering_small_animals])
handle_sociopathic_obsessions
redirect_to socio_path and return
elsif params[:obsessions]
handle_normal_obsessions
redirect_to standard_obsessions_path and return
end
# normal update for compulsions
@compulsion = Compulsions.find(params[:id])
if(@compulsion.update_attributes(params[:compulsion]))
# ... remainder of the standard actions below here
end
and the phrase "WTF were they thinking?" runs through your mind?
More...
I have a theory about that little "pass a flag in the url to skip over the real action and perform a different one"
trick I see so often (and have been guilty of using myself).
It's because you've got this omniscient file that knows everything about where to route requests
that's not part of your editing routine, so finding and opening it breaks your train of thought.
It's a pain to open routes.rb when you suddenly realize you need a new route.
That got me thinking:
Should controllers route themselves? Would it make more sense for a controller to tell the router
how each of it's actions should be reached?
In the second edition of Code Complete (that's an affiliate link), Steve McConnell writes about using
the Principle of Proximity (page 352) as a way to think about organizing code.
Keep related actions together.
From that point of view, it
certainly would be easier to follow along when you're questioning "how do I get to this action?"
Further, I think it would help solve the "pass a flag to an action to perform a different one" problem I illustrated in the code snippet above.
It was on my mind over the weekend, so I put together this little
experiment to see what controllers routing themselves in Rails would look like.
In that repository is a one-controller Rails project which specifies routes to itself using a gem you'll find in
vendor/gems/route.
One major drawback to doing routing in this style has to do with nested routes: should a controller that's
part of a nested route know who it's parents are? Should a higher-in-the-nest controller know about its child
routes? And if you choose one or the other, how would you specify it? What if there are conflicting routes -- who wins out?
It leads to a lot of questions for which I have no immediate answers.
Anyway, what do you think? Would this help solve the problem of recycled routes? Is that even a problem?
What are the drawbacks of such an approach? Do you see any merits?
Last modified on Feb 01, 2012 at 05:44 AM UTC - 5 hrs
Posted by Sam on Oct 12, 2011 at 01:58 PM UTC - 5 hrs
plupload-rails3 is now available as a gem, and it now works on Rails 3.1.
Automated tests are still virtually non-existent, which was a result of me not having a good idea for a strategy on how to test it in any useful manner. But after briefly bouncing ideas off of Jesse Wolgamott last night at the HRUG meeting, I think that will improve.
If you have an issue or improvement, don't be afraid to let me know.
PS: I'd like to give a little thank you to David Radcliffe, who prompted me to make these changes.
Posted by Sam on Sep 02, 2011 at 02:18 PM UTC - 5 hrs
Frequent changes and deprecations to technology you rely upon cause dependencies to break
if you want to upgrade. In many cases, you'll find yourself hacking through someone else's code
to try to fix it, because a new version has yet to be release (and probably never will). That can be
a chore.
I get embarrassed when something I've recommended falls prey to this cycle. Backwards compatibility
is one way to deal with the issue, but in the Rails world, few seem worried about it. It doesn't bother
me that code and interface quality is a high priority, but it does cause extra work.
There's a trick you can use to help isolate the pain, decrease the work involved in keeping your app up to date,
and improve your code in general. You've probably heard of it, but you might not be using it to help you
out in this area: encapsulation.
More...
What I'm about to describe talks heavily about Ruby on Rails, but that's only because it was the focus
of what got me thinking about this. I think it really applies in general.
Problem
Rails changes frequently. Some people think it
changes too frequently. I'll leave it for you to decide whether or not that's the case.
One consequence of change is that plugins and gems designed to work with Rails break. Perhaps as a result
of frequent changes (in Rails or just the whims of the community about which project in a similar area does
the job best), the authors of those packages become disillusioned and abandon the project. They could
just be lacking time, of course.
Now you get to fix their code (which doesn't have to be a bad thing, if you contribute it back and someone
else is sparred the trouble), use a new project that does the same thing, roll your own, or sit on an old
version of Rails that time forgot, and everyone else forgot how to use.
Don't you get at least a little embarrassed that you have to recommend large changes to your
customer or product owner or manager as a result of upgrading to the latest version of a technology you
recommended using?
It reminds me of a quote from Harry Browne I heard as part of his year 2000 United States
Presidential election campaign:
Government is good at only one thing. It knows how to break your legs, hand you a crutch, and say,
"See if it weren't for the government, you couldn't walk."

I'm likening programmers to the government of that quote, except we don't pretend to
give the crutch away. We tell them "you can't walk without our crutch, so pay up." We sell people
on a technology which they build their business around, and then tell them they have to choose between
keeping a substandard version of it, or spending a lot of money to upgrade all the components.
(Understand that I'm talking about how it feels overall as a result of what happens in the community of
programmers, not a particular instance of particular decisions by any particular well-defined group of programmers.)
I just got done migrating a Rails 2.3 app to Rails 3.1 that was heavily dependent on several plugins and gems.
After writing a ton of missing tests, I made the switch and ran them. As expected, there were loads of errors.
More than half of them were due to the application's own code, but those failures were fixed with very little
effort. By far the most excruciating and time consuming task (even longer than writing all of the tests) was
spent getting the plugins to work (or in some cases, using new plugins and changing the application to use them
instead).
I acknowledge that I'm doing something wrong, because surely not everyone has this problem.
So tell me, how can I improve my experience?
A Solution?
Something I'd like to see more of in this area is to encapsulate your plugin usage. Rather than
include NoneSuch,
why don't you take the time to wrap it in your own code? In doing so, I see a couple of benefits:
-
You document which features you're using by only writing methods for those in use. That means
you have something specific to test against in your app, and something specific to run those
tests agains when you trade one dependency for another. It also means you know exactly what you
need to implement when you swap dependencies.
-
You ensure a consistent interface for your app to use, as opposed to having to change it when you
swap out which plugin you're using. Also, all your changes to that interface are localized, instead
of spread throughout your source code.
That means you can change one external dependency for another with greater ease, which means you'll be a
lot less likely to get off in the weeds trying to make something fundamentally unworkable work.
Thoughts?
Posted by Sam on Jul 26, 2011 at 01:51 PM UTC - 5 hrs
I'm working on a website analytics tool, and in pursuit of that goal, I wanted to POST some data from a series of websites to the one that's doing the tracking. If you've tried to do that before, you've run afoul of the same origin policy, as I did, so you'll need to specify how your application handles Cross-Origin Resource Sharing.
I won't go into all the details about why that is the case - for that you can read the Wikipedia links above. Instead, I'm going to show a short example of how I handled this in my Rails 3 app.
First, you need to specify a route that will handle an HTTP OPTIONS method request.
# config/routes.rb
resources :web_hits, :only=>[:create]
match '/web_hits', :controller => 'web_hits', :action => 'options', :constraints => {:method => 'OPTIONS'}
More...
Since this controller only handles incoming requests to create a web hit resource, I've only specified the POST method on the it (which will run the create method in the controller). However, before the browser will send the POST to the tracking website, it first sends an OPTIONS request to see if it can do the POST. The second line specifies the route for that: it will go to my web_hits_controller and use the action options.
Next, we'll look at the controller.
# controllers/web_hits_controller.rb
class WebHitsController < ApplicationController
def create
if access_allowed?
set_access_control_headers
head :created
else
head :forbidden
end
end
def options
if access_allowed?
set_access_control_headers
head :ok
else
head :forbidden
end
end
private
def set_access_control_headers
headers['Access-Control-Allow-Origin'] = request.env['HTTP_ORIGIN']
headers['Access-Control-Allow-Methods'] = 'POST, GET, OPTIONS'
headers['Access-Control-Max-Age'] = '1000'
headers['Access-Control-Allow-Headers'] = '*,x-requested-with'
end
def access_allowed?
allowed_sites = [request.env['HTTP_ORIGIN']] #you might query the DB or something, this is just an example
return allowed_sites.include?(request.env['HTTP_ORIGIN'])
end
end
The key above is checking whether or not the request should be allowed. Here I've set access_allowed? to always return true, but you could have some checks in there that inspect the request to determine if you want to allow it or not. If you do, set the headers and respond appropriately. Since I don't need to really return a response, I'm only returning the headers indicating success or access denied, but you could just as easily turn those head method calls into renders if you need to render some content.
A good resource that helped me figure this out was Cross-Origin Resource Sharing for JSON and RAILS. He didn't go into detail on restricting access nor routing though, so I felt like this would be a good addendum.
Posted by Sam on Jun 22, 2011 at 06:42 AM UTC - 5 hrs
Yesterday I got sick of typing rake test and rake db:migrate and being told
You have already activated rake 0.9.2, but your Gemfile requires rake 0.8.7. Consider using bundle exec.
I know you should always run bundle exec, but my unconscious memory has not caught up with my conscious one on that aspect, so I always forget to run rake under bundle exec.
So I wondered aloud on twitter if I could just alias rake to bundle exec rake, but confine that setting to specific directories (with bash being my shell).
Turns out, it is possible with the help of another tool that
Calvin Spealman pointed me towards: capn.
More...
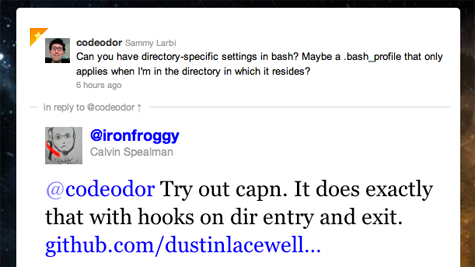
To successfully run the commands I've listed below, you need to have python and homebrew already installed. If you already have libyaml installed or have another way of getting it, there's no need for homebrew.
The section beginning with the line that starts out with echo and ending with -unalias rake"... creates the capn config file. It's just YAML, so if you'd rather create it with a text editor, you can surely do so. See the capn project for details on the config possibilities.
Either way, you'll want to change the paths I've used to the places you want to do the aliasing.
From the terminal, run the following commands:
curl -O http://python-distribute.org/distribute_setup.py
sudo python distribute_setup.py
sudo easy_install pip
sudo brew install libyaml
sudo easy_install -U pyyaml
sudo pip install capn
echo "
settings:
default_type: path
hooks:
- path: ~/workspace #change this to the path where you want to alias rake
type: tree # if you don't want the whole tree under the path above, remove this line
enter:
- echo aliasing rake to 'bundle exec rake'
- alias rake='bundle exec rake'
exit:
- echo unaliasing rake from 'bundle exec rake'
- unalias rake" > ~/.capnhooks
source capn # put this line in your .bash_profile if you want capn to work when you enter the shell
# to deactivate the hooks, use: unhook
Enjoy the silence now that you don't have to hear the whining.
Posted by Sam on Jun 07, 2011 at 06:10 AM UTC - 5 hrs
You can split an input on a specific string to get the same field to autocomplete multiple times. One example where you might want to do this is in the case of tags: You have a field that should contain multiple tags, and you want to do an autocomplete after every comma + space (', ').
It's not documented in the rails3-jquery-autocomplete README, but all you need to do is use the 'data-delimiter' attribute like this:
<%= f.label :category_tags %>
<%= f.autocomplete_field :category_tags, autocomplete_category_tag_title_library_assets_path, 'data-delimiter'=>', ' %>
Hopefully this helps you save a little time by allowing you to skip reading the implementation to find this detail.
Last modified on Jun 07, 2011 at 06:12 AM UTC - 5 hrs
Posted by Sam on May 31, 2011 at 08:18 AM UTC - 5 hrs
Here is the beginning of a Rails 3 plugin for plupload
Plupload lets you upload multiple files at a time and even allows drag and drop from the local file system into the browser (with Firefox and Safari).
This plugin tries to make its integration with Rails 3 very simple.
To install (from inside your project's directory):
More...
rails plugin install git://github.com/codeodor/plupload-rails3.git
To use:
<%= plupload(model, method, options={:plupload_container=>'uploader'} %>
<div id="uploader" name="uploader" style="width: 100%;"></div>
More info is available on the readme file.
If it's missing a feature you'd like to see, please open an issue or fork it and add it yourself (and send me a pull request).
Last modified on May 31, 2011 at 08:21 AM UTC - 5 hrs
Posted by Sam on Apr 13, 2011 at 02:18 PM UTC - 5 hrs
What's a better name for this function, and how do you better accomplish the same task?
Gist at github: remote_function_with_container_and_id_from_javascript.rb
Posted by Sam on Aug 03, 2010 at 12:46 PM UTC - 5 hrs
Rails Rumble has nothing on this.
Of course, you could just click the edit button in your database management studio of choice and achieve the same functionality.
SELECT DISTINCT 'script/generate scaffold ' + t.name + ' ' + column_names
FROM sys.tables t
CROSS APPLY (
SELECT c.name +
case when max_length > 255 then ':text' else ':string' end + ' '
FROM sys.columns c
WHERE c.object_id = t.object_id
ORDER BY c.column_id
FOR XML PATH('') ) dummy_identifier ( column_names )
A similar discovery was made in the 1930's. One important difference to note is that, since my program does not simulate the input on it's output program, I am able to achieve speeds that are logarithmically faster than what Turing could accomplish.
Posted by Sam on Jan 03, 2010 at 03:09 AM UTC - 5 hrs
I've spent some time recently building a tool that makes my life a bit easier.
I've browsed plenty of Rails log analyzers that
help me find performance bottlenecks and potential improvements. But what I really need is a faster way to filter my logs to
trace user sessions for support purposes. Maybe it's just me, but I've got apps where users report problems
that make no sense, where their data gets lost, and who can't tell me what they did. Add to that
the fact that I've got the same app running on dozens of different sites, and you can see
why performance analyzers aren't what I'm looking for to solve my problem.
Because of that, I need a solution that lets me filter down and search parameters to figure out
what a particular user was doing on a certain date. Hence, Ties.
More...
Why the name?
 Source
Source
The logs rails are fastened to are called ties. There's already railties,
" the glue that binds Action Pack and Active Record together to the complete web framework named Rails".
There's also the non-North-American "railway sleeper," which is already taken for log analysis.
Ties is a word that describes the rail/log aspect, isn't quite taken, and fits the clothing aspect since it's written using
Shoes.
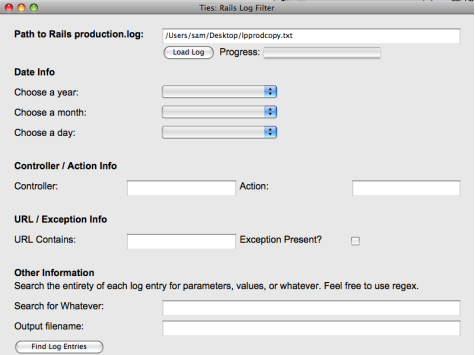 What can Ties do?
What can Ties do?
Enter the path to a Ruby on Rails production log file, click the "Load Log" button and it reads in the file.
Then, choose from the years, months, and days of requests in that file. Tell Ties which controller, action, and URL you are interested in.
Finally, decide if you only want to see the log entries which contain an exception, enter a regular expression
to search the params, plus the output filename and click a button to filter the log entries you care to see.
Ties takes a many-megabyte Rails production log file and outputs only the entries you're interested in.
The Ties git repository can be found at the github project page. The
Ties executable downloads for Windows, MacOS, and Linux are there as well.
What's missing in the initial release?
-
Keyboard Shortcuts: Shoes leaves it to the programmer to
implement keyboard shortcuts, so while familiar
actions like Copy (ctrl-C) and Paste (ctrl-V) are available
via the mouse, I have yet to implement them on the keyboard.
-
Error Handling: It's minimal. If you enter a non-existent file,
or non-Rails-production file, who knows what will happen?
-
Crazy web-of-a-graph: My intent is to build the data model
such that you can search most items in approximately O(1) time. Right now,
you drill down to the day in constantish time, and after that
it becomes linear search.
-
Testing on all platforms and Rails versions: I proudly certify
this version (0.1) WOMM.

Source
That means I've only tested it on Mac OS 10.5.8 (Leopard), using straight log files from Rails 2.2 on Ruby 1.8.6 and 1.8.7.
That being said, Shoes is supposed to work on Windows and Linux as well, and I've not noticed any major differences
in the log files between Rails versions, so you might find it works great for you too. If not, I encourage you to
let me know and I'll fix it up quick for you. (Please have
a sample log file available if possible.)
Thoughts?
Posted by Sam on Dec 22, 2008 at 12:00 AM UTC - 5 hrs
This post might be better titled, "How (and how not) to help yourself when
Google doesn't have the answer: A whirlwind tour through Rails' source" if only I wasn't
too lazy to change the max length of the database field for titles to my blog entries.
Google sometimes seems as if it has the sum of all human knowledge within the confines of its search index.
It might even be the case that it does. Even if you prefer to think that's true,
there may come a time when humanity does not yet have the knowledge you are seeking.
How often is that going to happen? Surely someone has run up against the problems I'm
going to have, right? That hasn't been the case for me the last couple of months.
I may be the only developer writing Rails apps on MacOSX to be deployed to the world on Windows
where SQL Server 2008 is the backend to a Sharepoint install used by internal staff to drive the data. I'm
not so presumptious to think I'm a beautiful and unique snowflake, but I wasn't finding any answers.
More...
Before I started this trek, I made a commitment to leave after an hour if I found my attention
drifting toward something else. I never started checking email, reading blogs, or obsessively reloading
twitter to see my tweeps latest tweets, so I thought I was in the clear.
However, even though I felt like I was focused, the fact that I had been sitting at the computer for so
long contributed to poor decision making. The first of these was to keep searching Google even though
every search was coming up useless. I always followed the path of least resistance - even
if it wasn't going to get me to the goal quicker than an alternative path. If it was less challenging,
it was for me.
After a while, I ran out of mentally casual paths and resigned myself to tracing through
the source code (it is open source, after all, and this is one of the benefits everyone claims but
so few practice). It was what I knew I should have been doing as I started out, and I had wasted
several hours trying to tip-toe around it for the sake of my poor, tired brain.

Now that I was sure I had the right data type being returned, I needed to narrow down where the problem was
occuring. I knew SQLServerAdapter was using DBI to connect to the database, so I figured I'd use a
quick irb session to test DBI itself. The test came back negative - DBI was getting the correct
data. I also ran a quick test in the Rails app, reaching through ActiveRecord::Base to use the connection
manually. That worked, as expected.
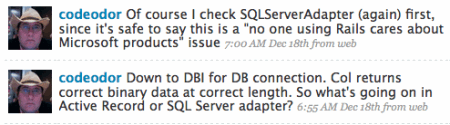
I had thought, and now confirmed, that the best place to look would be SQLServerAdapter.
If it were a Rails problem, certainly someone would have run into it by now. So it made sense the problem would be in the interface
between Rails and Microsoft.
Why? Because if Rails is a Ghetto,
Rails with Microsoft products is a fucking concentration camp.
Excuse the profanity. I don't often use it here, so you know I must mean it when I do.
As I began to browse the source, I was first drawn to this innocent looking code from rails-sqlserver on github:
class << self
def string_to_binary(value)
"0x#{value.unpack("H*")[0]}"
end
def binary_to_string(value)
value =~ /[^[:xdigit:]]/ ? value : [value].pack('H*')
end
end
But it wasn't obvious how it was being used elsewhere. I even tried using the reverse operations in my objects - to no avail.
And after searching in the source file, it certainly wasn't being called inside of SQLServerAdapter.
So I went on a quest for the answer inside /opt/local/lib/ruby/gems/1.8/gems/activerecord-2.1.1/
.
For quite some time I went back and forth inserting and removing debugging code between Active Record and
SQLServerAdapter. select(sql, name=nil) is a protected method defined in the abstract connection
adapter in Active Record. SQLServerAdapter implements it privately, and it was both getting and returning
the correct data.
After ActiveRecord calls object.instance_variable_set("@attributes", record) when instantiating our object,
object.attributes[binary].size becomes less than record["binary"].size. That was
the problem. I thought for sure instance_variable_set was a monkeypatched method on Object,
and that all I needed to do was issue a monkeyfix and all would be well.
Only I was wrong. It's there by default in Ruby, and Rails wasn't monkeypatching it (that I can tell).
All the sudden things started looking bleak. By this time I knew how I could fix it as a hack. I even
had a nice little monkeypatch for my objects that I could issue and
have it feel less hacky to be used. I had given up.
But for some reason I picked it back up after an hour and found that ActiveRecord was actually calling
that string to binary method in SQL Server Adapter. It allows them to register calls that should happen before
defining the read and write methods on the object. Excellent!
I opened up SQLServerAdapater, there it was: a different binary_to_string method
that totally explained it. The pair in this version were encoding and decoding the data to/from base 64.
That would work fine, if my data was going through the encoding part. But it wasn't - it was coming straight
from Sharepoint.
There's a comment in the code about some arbitrary 7k limit on data size from SQL Server
being the reason for encoding as base 64 before inserting the data. I don't know about
inserting, but retrieving works fine without it. If I could think of a way to distinguish,
I'd submit a patch for the patchwork. Ideally, I'd rather find a way around the restriction, if it
actually exists.
The original code I was looking at was on github. It (not surprisingly) differed from the code in use on
my machine. Another side effect of the 16 hour monitor stare.
It's called the 8 hour burn for a reason.
The only things burning after 16 hours are your brain from all the stimulants and your
wife, wondering WTF you're really doing because there's no way you're working from before
she wakes up until after she goes to bed.
What's the point?
There's two, if you ask me:
-
You have the source code. Look through it. You have no other choice when no one has had your problem,
and you might
benefit by doing so even if someone already has.
-
Even when you think you're focused working late, and resolve to leave when you lose the focus, you're
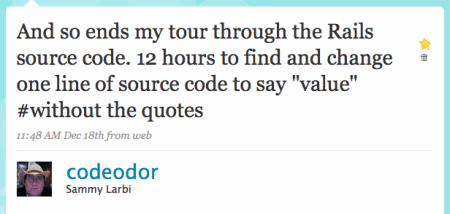
still going to make stupid decisions that you won't notice until the morning. I turned
a 5 hour journey into a 12 hour marathon. Sleep, FTW.
Oh, and Rails on Windows is a concentration camp.
Posted by Sam on Apr 14, 2009 at 12:00 AM UTC - 5 hrs
Code in Views and Code in the Wrong Place are two of the top 20 Rails development No-No's that came up in Chad Fowler's straw poll on Twitter about poor practices in Ruby on Rails.

Domain code in controllers and views isn't a problem that's limited to Rails, of course. It's a problem everywhere, and one you generally need to remain vigilant about. Rails doesn't make it easy by making it easy - it's much too easy to do the wrong thing.
You've got the view open and think, "I need to get a list of Widgets."
More...
<% widgets = Widget.find(:all, :conditions=>["owner=?",session[:user_id]]) %>
That was easy, and it's even easier in controllers where you don't have the hassle of angled brackets and percent signs. Worse yet, since you've got what you need right there, it's easy to add more logic around it. Before you know it, your views and controllers are cluttered with a bunch of crap that shouldn't be there.
I fall into the trap more often than I'd like to admit. And I know it's wrong. What of those who haven't a clue?
To combat this syndrome, I created a Rails plugin called FindFail that makes ActiveRecord::Base#find private.
FindFail results in less business logic in your views and controllers because it forces you to open a model and add a
method. Since you're already in the right place, you may as well stay there. It makes it hard to do the wrong thing, and contributes to making it easier to do the right thing.
It preys on your laziness that way.

It's only one line of useful code, but it can help keep the rest of your code clean.
Posted by Sam on Jan 14, 2008 at 06:42 AM UTC - 5 hrs
This is a story about my journey as a programmer, the major highs and lows I've had along the way, and
how this post came to be. It's not about how ecstasy made me a better programmer, so I apologize if that's why you came.
In any case, we'll start at the end, jump to
the beginning, and move along back to today. It's long, but I hope the read is as rewarding as the write.
A while back,
Reg Braithwaite
challenged programing bloggers with three posts he'd love to read (and one that he wouldn't). I loved
the idea so much that I've been thinking about all my experiences as a programmer off and on for the
last several months, trying to find the links between what I learned from certain languages that made
me a better programmer in others, and how they made me better overall. That's how this post came to be.
More...
The experiences discussed herein were valuable in their own right, but the challenge itself is rewarding
as well. How often do we pause to reflect on what we've learned, and more importantly, how it has changed
us? Because of that, I recommend you perform the exercise as well.
I freely admit that some of this isn't necessarily caused by my experiences with the language alone - but
instead shaped by the languages and my experiences surrounding the times.
One last bit of administrata: Some of these memories are over a decade old, and therefore may bleed together
and/or be unfactual. Please forgive the minor errors due to memory loss.
How QBASIC Made Me A Programmer
As I've said before, from the time I was very young, I had an interest in making games.
I was enamored with my Atari 2600, and then later the NES.
I also enjoyed a playground game with Donald Duck
and Spelunker.
Before I was 10, I had a notepad with designs for my as-yet-unreleased blockbuster of a side-scrolling game that would run on
my very own Super Sanola game console (I had the shell designed, not the electronics).
It was that intense interest in how to make a game that led me to inspect some of the source code Microsoft
provided with QBASIC. After learning PRINT, INPUT,
IF..THEN, and GOTO (and of course SomeLabel: to go to)
I was ready to take a shot at my first text-based adventure game.
The game wasn't all that big - consisting of a few rooms, the NEWS
directions, swinging of a sword against a few monsters, and keeping track of treasure and stats for everything -
but it was a complete mess.
The experience with QBASIC taught me that, for any given program of sufficient complexity, you really only
need three to four language constructs:
- Input
- Output
- Conditional statements
- Control structures
Even the control structures may not be necessary there. Why? Suppose you know a set of operations will
be performed an unknown but arbitrary amount of times. Suppose also that it will
be performed less than X number of times, where X is a known quantity smaller than infinity. Then you
can simply write out X number of conditionals to cover all the cases. Not efficient, but not a requirement
either.
Unfortunately, that experience and its lesson stuck with me for a while. (Hence, the title of this weblog.)
Side Note: The number of language constructs I mentioned that are necessary is not from a scientific
source - just from the top of my head at the time I wrote it. If I'm wrong on the amount (be it too high or too low), I always appreciate corrections in the comments.
What ANSI Art taught me about programming
When I started making ANSI art, I was unaware
of TheDraw. Instead, I opened up those .ans files I
enjoyed looking at so much in MS-DOS Editor to
see how it was done. A bunch of escape codes and blocks
came together to produce a thing of visual beauty.

Since all I knew about were the escape codes and the blocks (alt-177, 178, 219-223 mostly), naturally
I used the MS-DOS Editor to create my own art. The limitations of the medium were
strangling, but that was what made it fun.
And I'm sure you can imagine the pain - worse than programming in an assembly language (at least for relatively
small programs).
Nevertheless, the experience taught me some valuable lessons:
- Even though we value people over tools, don't underestimate
the value of a good tool. In fact, when attempting anything new to you, see if there's a tool that can
help you. Back then, I was on local BBSs, and not
the 1337 ones when I first started out. Now, the Internet is ubiquitous. We don't have an excuse anymore.
-
I can now navigate through really bad code (and code that is limited by the language)
a bit easier than I might otherwise have been able to do. I might have to do some experimenting to see what the symbols mean,
but I imagine everyone would.
And to be fair, I'm sure years of personally producing such crapcode also has
something to do with my navigation abilities.
-
Perhaps most importantly, it taught me the value of working in small chunks and
taking baby steps.
When you can't see the result of what you're doing, you've got to constantly check the results
of the latest change, and most software systems are like that. Moreover, when you encounter
something unexpected, an effective approach is to isolate the problem by isolating the
code. In doing so, you can reproduce the problem and problem area, making the fix much
easier.
The Middle Years (included for completeness' sake)
The middle years included exposure to Turbo Pascal,
MASM, C, and C++, and some small experiences in other places as well. Although I learned many lessons,
there are far too many to list here, and most are so small as to not be significant on their own.
Therefore, they are uninteresting for the purposes of this post.
However, there were two lessons I learned from this time (but not during) that are significant:
-
Learn to compile your own $&*@%# programs
(or, learn to fish instead of asking for them).
-
Stop being an arrogant know-it-all prick and admit you know nothing.
As you can tell, I was quite the cowboy coding young buck. I've tried to change that in recent years.
How ColdFusion made me a better programmer when I use Java
Although I've written a ton of bad code in ColdFusion, I've also written a couple of good lines
here and there. I came into ColdFusion with the experiences I've related above this, and my early times
with it definitely illustrate that fact. I cared nothing for small files, knew nothing of abstraction,
and horrendous god-files were created as a result.
If you're a fan of Italian food, looking through my code would make your mouth water.
DRY principle?
Forget about it. I still thought code reuse meant copy and paste.
Still, ColdFusion taught me one important aspect that got me started on the path to
Object Oriented Enlightenment:
Database access shouldn't require several lines of boilerplate code to execute one line of SQL.
Because of my experience with ColdFusion, I wrote my first reusable class in Java that took the boilerplating away, let me instantiate a single object,
and use it for queries.
How Java taught me to write better programs in Ruby, C#, CF and others
It was around the time I started using Java quite a bit that I discovered Uncle Bob's Principles of OOD,
so much of the improvement here is only indirectly related to Java.
Sure, I had heard about object oriented programming, but either I shrugged it off ("who needs that?") or
didn't "get" it (or more likely, a combination of both).
Whatever it was, it took a couple of years of revisiting my own crapcode in ColdFusion and Java as a "professional"
to tip me over the edge. I had to find a better way: Grad school here I come!
The better way was to find a new career. I was going to enter as a Political Scientist
and drop programming altogether. I had seemingly lost all passion for the subject.
Fortunately for me now, the political science department wasn't accepting Spring entrance, so I decide to
at least get started in computer science. Even more luckily, that first semester
Venkat introduced me to the solution to many my problems,
and got me excited about programming again.
I was using Java fairly heavily during all this time, so learning the principles behind OO in depth and
in Java allowed me to extrapolate that for use in other languages.
I focused on principles, not recipes.
On top of it all, Java taught me about unit testing with
JUnit. Now, the first thing I look for when evaluating a language
is a unit testing framework.
What Ruby taught me that the others didn't
My experience with Ruby over the last year or so has been invaluable. In particular, there are four
lessons I've taken (or am in the process of taking):
-
The importance of code as data, or higher-order functions, or first-order functions, or blocks or
closures: After learning how to appropriately use
yield, I really miss it when I'm
using a language where it's lacking.
-
There is value in viewing programming as the construction of lanugages, and DSLs are useful
tools to have in your toolbox.
-
Metaprogramming is OK. Before Ruby, I used metaprogramming very sparingly. Part of that is because
I didn't understand it, and the other part is I didn't take the time to understand it because I
had heard how slow it can make your programs.
Needless to say, after seeing it in action in Ruby, I started using those features more extensively
everywhere else. After seeing Rails, I very rarely write queries in ColdFusion - instead, I've
got a component that takes care of it for me.
-
Because of my interests in Java and Ruby, I've recently started browsing JRuby's source code
and issue tracker.
I'm not yet able to put into words what I'm learning, but that time will come with
some more experience. In any case, I can't imagine that I'll learn nothing from the likes of
Charlie Nutter, Ola Bini,
Thomas Enebo, and others. Can you?
What's next?
Missing from my experience has been a functional language. Sure, I had a tiny bit of Lisp in college, but
not enough to say I got anything out of it. So this year, I'm going to do something useful and not useful
in Erlang. Perhaps next I'll go for Lisp. We'll see where time takes me after that.
That's been my journey. What's yours been like?
Now that I've written that post, I have a request for a post I'd like to see:
What have you learned from a non-programming-related discipline that's made you a better programmer?
Last modified on Jan 16, 2008 at 07:09 AM UTC - 5 hrs
Posted by Sam on Jun 25, 2007 at 05:58 PM UTC - 5 hrs
Last night John Lam posted about Steve Yegge's port of Rails to JavaScript (Running on Rhino, "JavaScript for Java" on the JVM," not in the browser).
Sounds interesting.
Update: Steve responds and explains how it's not much to get hyped up about.
Last modified on Jun 27, 2007 at 06:21 AM UTC - 5 hrs
Posted by Sam on Jun 18, 2007 at 02:50 PM UTC - 5 hrs
This one refers to the 40+ minute presentation by Obie Fernandez on Agile DSL Development in Ruby. (Is InfoQ not one of the greatest resources ever?)
You should really view the video for better details, but I'll give a little rundown of the talk here.
Obie starts out talking about how you should design the language first with the domain expert, constantly refining it until it is good - and only then should you worry about implementing it (this is about the same procedure you'd follow if you were building an expert system as well). That's where most of the Agility comes into play.
More...
Later, he moves on to describe four different types of design for your DSL. This was something I hadn't really thought about before, therefore it was the most interesting for me. Here are the four types:
- Instantiation: The DSL consists simply of methods on an object. This is not much different from normal programming. He says it is "DSLish," perhaps the way Blaine Buxton looks at it.
- Class Macros: DSL as methods on some ancestor class, and subclasses can then use those methods to tweak the behavior of themselves and their subclasses. This follows a declarative style of programming, and is the type of DSL followed by Ruby on Rails (and cfrails) if I understand him correctly.
- Top-level methods: Your application defines the DSL as a set of top-level methods, and then invokes
load with the path to your DSL script. When those methods are called in the configuration file, they modify some central (typically global) data, which your application uses to determine how it should execute. This is like scripting, and (again) if I understood correctly, this is the style my (almost working correctly) Partial Order Planner uses.
- Sandboxing (aka Contexts): Similar to the Instantiation style, but with more magic. Your DSL is defined as methods of some object, but that object is really just a "sandbox." Interaction with the object's methods modifies some state in the sandbox, which is then queried by the application. This is useful for processing user-maintained scripts kept in a database, and you can vary the behavior by changing the execution context.
Note: These are "almost" quotes from the slides/talk (with a couple of comments by myself), but I didn't want to keep rewinding and such, so they aren't exact. Therefore, I'm giving him credit for the good stuff, but I stake a claim on any mistakes made.
The talk uses Ruby as the implementation language for the example internal DSLs, but I think the four types mentioned above can be generalized. At the least, they are possible in ColdFusion - but with Java, I'm not so sure. In particular, I think you'd need mixin ability for the Top-level methods style of DSL.
Next, Obie catalogs some of the features of Ruby you see used quite often in crafting DSLs: Symbols (because they have less noise than strings), Blocks (for delayed evaluation of code), Modules (for cleaner separation of code), Splats (for parameter arrays), the different types of eval (for dynamic evaluation), and define_method and alias_method.
Finally, he winds up the presentation with a bit about BNL. I liked this part because I found Jay Fields' blog and his series of articles about BNL.
As always, comments, questions, and thoughts are appreciated. Flames - not so much.
Posted by Sam on Jun 15, 2007 at 09:18 PM UTC - 5 hrs
Sean Corfield responded in some depth to " Is Rails easy?", and explained what I wish I could have when I said (awkwardly, rereading it now) "I think my cat probably couldn't [code a Rails app]."
Sean makes it quite clear (as did Venkat's original post) that it isn't that using a framework, technology, or tool in general is easy or hard (although, you can certainly do things to make it easier or harder to use). In many cases, what it does for you is easy to begin with - in the case of Rails, it is stuff you do all the time that amounts to time-wasting, repetitive, boring busy-work. Rather, the right way to look at them is that they are tools that make you more productive, and it takes a while to learn to use them.
If you go into them thinking they are easy, you're likely to be disappointed and drop a tool that can really save you time before you learn to use it. And that could be tragic, if you value your time.
Posted by Sam on Jun 15, 2007 at 12:23 PM UTC - 5 hrs
This morning I was reading an announcement for another Rails-based conference (Not RailsConf, and I didn't think to save the email, so I'm not sure what I could link to here), and I thought to myself, "Self, isn't Rails supposed to be easy? How is there possibly enough to talk about that justifies having so much conference exposure?"
If it takes that long to explain it, surely it isn't easy.
Well, Rails is pretty simple - as someone noted on Ruby-Talk the other day, it doesn't take long to see that the magic of Rails is just its excellent use of Ruby, and even its strongest points aren't particularly hard if you see that it can be done (which I admit, is probably true about most things).
But as Venkat (co-author of Practices of an Agile Developer, among other books) pointed out today (completely by coincidence), it's not so simple that the brainless can do it. As he noted, in his move from C++ to Java he became more productive, but no one "would say that Java makes an ignorant programmer more productive." In fact, he asks, " Can your cat code my Rails app?"
I think my cat probably couldn't do it. But, can yours? =)
Posted by Sam on May 19, 2007 at 01:25 PM UTC - 5 hrs
Peter Bell's presentation on LightWire
generated some comments I found very interesting and thought provoking.
(Perhaps Peter is not simply into application generation, but comment generation as well.)
The one I find most interesting is brought up by several people whose opinions I value -
Joe Rinehart, Sean Corfield,
Jared Rypka-Hauer, and others during and after the presentation.
That is: what is the distinction between code and data, and specifically, is XML code or data
(assuming there is a difference)?
More...
The first item where I see a distinction that needs to be made is on, "what do we mean when we are talking about
XML?" I see two types - XML the paradigm where you use tags to describe data, and the XML you write - as in,
the concrete tags you put into a file (like, "see that XML?"). We're talking about XML you've written, not
the abstract notion of XML.
The second idea: what is code? What is data? Sean Corfield offers what I would consider to be a concice,
and mostly correct definition: "Code executes, non-code (data) does not execute." To make it correct (rather
than partially so), he adds that (especially in Lisp) code can be data, but data is not code. You see this
code-as-data any time you are using closures or passing code around as data. But taking it a bit further -
your source code is always just data to be passed to a compiler or interpreter, which figures out what the
code means, and does what it has been told to do.
So is XML code? Certainly we see it can be: ColdFusion, MXML, and others are languages where your
source code is written (largely) in XML. But what about the broader issue of having a programmatic
configuration file versus a "data-only" config file?
Is the data in the config file executable? It depends on the purpose behind the data. In the case of data
like
<person>
<name>
Bill
</name>
<height>
4'2"
</height>
</person>
I think (assuming there is nothing strange going on) that it is clearly data. Without knowing anything about the
back end, it seems like we're just creating a data structure. But In the case of
DI (and many others uses for config files),
I see it as giving a command to the DI framework to configure a new bean. In essence, as Peter notes,
we've just substituted one concrete syntax for another.
In the case of XML, we're writing (or using)
a parser to send data to an intepreter we've written that figures out what "real" commands to run based on
what the programmer wrote in the configuration file. We've just created a higher level language than we had before
- it is doing the same thing any other non-machine code language does (and you might even argue
about the machine code comment). In the configuration case,
often it is a DSL (in the DI case specifically, used to describe which objects depend on which other
objects and load them for us).
While we don't often have control structures, there is nothing stopping us from implementing them,
and as Peter also notes, just because a language is not
Turing complete), doesn't mean it is not
a programming language. In the end, I see it as code.
Both approaches are known to have their benefits and drawbacks, and choosing one over the other is largely a matter
of personal taste, size and scope of problem, and problem/solution domain. For me, in the worlds of
JIT compiling and interpreted langages, the programmatic way
of doing things tends to win out - especially with large configurations because I prefer to have
the power of control structures to help me do my job (without having to implement them myself).
On the other hand, going the hard-coded XML route is especially popular in the compiled world, if not
for any other reason than you can change configurations without recompiling your application.
I don't make a distinction between the two on terms of XML is data, while programming (or using an in-language DSL)
in your general-purpose language is code. To me, they are both code, and if either is done incorrectly it will
blow-up your program.
Finally, I'm not sure what value we gain from seeing that code is data (and in many cases config data is code),
other than perhaps a new way of looking at problems which might lead us to find better solutions.
But that isn't provided by the distinction itself, just the fact that we saw it.
Comments, thoughts, questions, and requests for clarifications are welcome and appreciated.
Posted by Sam on May 07, 2007 at 09:20 AM UTC - 5 hrs
As I'm getting into little details about the generation cfrails is doing, I had a couple of questions I thought the community could provide some insight on better than my own experiences regarding lists.
One of the great things about generating this stuff is that you can have for free all the bells and whistles that used to take a long time to do. In particular, you can have sorting on columns automatically generated, as well as pagination.
So question 1 is: given that you can have sorting for free, would you rather automatically sort on every column, and specify any columns you did not want to sort on, or would you prefer to not have sorting placed automatically, but just specify which columns to sort on?
And question 2: Given that more and more people are on broadband, is it time to up the 10-record limit on results? I find it annoying to have to reload all the time, and if given the option, I normally up the results/page to 50 or 100. What do you think, would you make the default number of results/page higher (and how high would you take it?), or would you cater to the lowest common denominator?
Posted by Sam on May 01, 2007 at 09:36 AM UTC - 5 hrs
There are a couple of drawbacks (or some incompleteness) to scaffolding being truly useful. The one that seems to be most often cited is that normally (at least in Ruby on Rails, which seems to have popularized it) it looks like crap (it is only scaffolding though). Of course, most who make that complaint also recognize that it is only a starting point from which you should build.
Django has been generating (what I feel is) production-quality "admin" scaffolding since I first heard about it. It looks clean and professional. Compare that to the bare-bones you get by default in Rails, and you're left wondering, "why didn't they do that?" Well, as it happens, it has been done. In particular, there are at least 4 such products for use with Rails: Rails AutoAdmin (which professes to be "heavily inspired by the Django administration system"), ActiveScaffold (which is just entering RC2 status), Hobo, and Streamlined (whose site is down for me at the moment).
More...
My interest lies in the second complaint though - that writing it to a live file (rather than dynamically figuring it out - which I've been calling "synthesis," as opposed to generation) means you can't get the benefits of upgrades to the scaffolding engine (and, it is not following DRY!). But, if you just use the default scaffolding, what happens if it doesn't come out just right (assuming you've even passed the notUgly test in the first place)? Well, thats a big part of what I'm trying to solve with cfrails, by using a DSL that provides tweakability to the scaffolding, without requiring you to write to a file (though, if the tweaks won't work, you are always welcome to go to a file with HTML and the like). The interesting part for me about the RoR plugins above, therefore, is that it appears (I haven't checked them out yet) that at least Hobo contains a DSL, called DRYML, to help along those lines.
I'll be having a closer look at those when free time becomes a bit less scarce. What do you think? Is it the holy grail, or can there be very useful
"scaffolding"?
Last modified on May 01, 2007 at 09:37 AM UTC - 5 hrs
Posted by Sam on Mar 29, 2007 at 02:24 PM UTC - 5 hrs
It had been a while since I visited InfoQ, but the other day I got one of their mailings in my inbox, and tons of it was relevant to my interests (even more so than normal). Rather than having a separate post for all of it, I decided to combine much of it into this post.
First, this post let me know that Thoughtworks has released CruiseControl.rb, which is good news for Ruby users who also want continuous integration. I've yet to use it, but those guys are a great company and it seems like everything they touch turns to gold.
More...
Next, of interest to Java programmers and ORM fans, Google has contributed code to Hibernate that allows people to "keep their data in more than one relational database for whatever reason-too much data or to isolate certain datasets, for instance-without added complexity when building and managing applications."
Then, Bruce Tate, who is probably best known for his books Beyond Java and From Java to Ruby (by me anyway) has a case study on ChangingThePresent.org, his new project that uses Rails. It looks like a good starting point if you are developing a high-traffic Rails site. And, the site does some good charity work - taking only the credit card processing fee from your donation to the causes of your choice.
Finally, Gilad Bracha speaks about dynamic languages on the JVM. Until recently he was the Computational Theologist (is that someone who studies the religion of computation?) at Sun. The talk is just over 30 minutes long, and is at a surprisingly low level - so geeks only! He discusses a few of the challenges with implementation details on getting dynamic languages to run natively in byte-code (as opposed to writing an interpreter in Java which would then interpret the dynamic language). This includes a new instruction for invoking methods - invokedynamic, as well as a discussion on possible implementations of hotswapping - the technique that allows you to modify code at runtime. Very interesting stuff.
For today, I should be done referencing InfoQ, except to give them credit in my next post for turning me on to a couple of good resources for implementing DSLs in Ruby (which is the subject of my next post). I'll post the link in the comments when I'm done with it - I try not to edit these posts anymore since MXNA likes to visit every 30 seconds and thinks the date is the unique identifier of the post... you know, instead of using the XML field called "guid." =) (sorry guys, just poking a little fun - thanks for aggregating me).
Posted by Sam on Feb 27, 2007 at 06:31 AM UTC - 5 hrs
One of the things I've been dreading is getting Rails to work with IIS, although it appears to be getting easier (last time I checked, there was no such "seamless integration"). But eWeek has some good news. They note that core developer on the JRuby project, Charles Nutter
said the JRuby project will announce, possibly as soon as this week, that JRuby supports the popular Ruby on Rails Web development framework. Ruby on Rails is sometimes referred to as RoR or simply Rails.
"We're trying to finish off the last few test cases so we can claim that more than 95 percent of core Rails tests passed across the board," Nutter said.
Moreover, the JRuby team is inviting Rails developers to try out real-world usage of JRuby and help them find any Rails issues the unit tests do not cover, or any remaining failures that are crucial for real applications, Nutter said.
Support for Ruby on Rails is important because "once Rails can run on JVM alongside other Java apps, existing Java shops will have a vector to bringing Rails apps into their organizations. They won't have to toss out the existing investment in servers and software to go with the new kid on the block," Nutter said.
The article also mentions "Microsoft is looking at support for Ruby developers and broader uses of Ruby, including having it run on the CLR."
Both bits of good news for fans of Ruby who want it to play well with Windows and IIS. Not to mention that using JRuby (or NRuby, if it will be called that for .NET) should open up all of those libraries available to Java/.NET developers, which has been considered by some to be one of Ruby's weaker spots.
Posted by Sam on Jan 09, 2007 at 04:44 PM UTC - 5 hrs
For those that don't know, cfrails is supposed to be a very light framework for obtaining MVC architecture with little to no effort (aside from putting custom methods where they belong). It works such that any changes to your database tables are reflected immediately throughout the application.
For instance, if you change the order of the columns, the order of those fields in the form is changed.
If you change the name of a column or it's data type, the labels for those form fields are changed, and
the validations for that column are also changed, along with the format in which it
is displayed (for example, a money field displays with the local currency,
datetime in the local format, and so forth).
I've also been developing a sort-of DSL for it,
so configuration can be performed quite easily programmatically (not just through the database), and you can follow DRY to the extreme. Further, some of this includes (and will include) custom data types (right now, there are only a couple of custom data types based on default data types).
More...
In a nutshell, the goal is to have such highly customizable "scaffolding" that there really is no scaffolding - all the code is synthesized - or generated "on the fly." Of course, this only gets you so far. For the stuff that really makes your application unique, you'll still have to code that. But you can compose views from others and such, so it's not like related tables have to stay unrelated, but I do want to stress that right now there is no relationship stuff implemented in the ORM.
I've skipped a few "mini-versions" from 0.1.3 to 0.2.0 because there were so many changes that I haven't documented one-by-one. That's just sloppiness on my part. Basically, I started by following Ruby on Rails' example, and taking my own experience about what I find myself doing over and over again. That part is done, except that the ORM needs to be able to auto-load and lazy-load relationships at the programmer's whim. In any case, once I got enough functionality to start using it on my project, I've been developing them in parallel. The problem is, I've fallen back on poor practices, so the code isn't as nice as it could be.
In particular, there aren't any new automated tests after the first couple of releases, which isn't as bad as it might otherwise be, since a lot of the core code was tested in them. But on that note, I haven't run the existing tests in a while, so they may be broken.
Further, since I've been thinking in Ruby and coding in Coldfusion, you'll see a mix of camelCase and under_score notations. My original goal was to provide both for all the public methods, and I still plan to do that (because, since I can't rely on case from all databases for the column names -- or so I think -- I use the under_score notation to tell where to put spaces when displaying the column names). But right now, there is a mix. Finally, the DSL needs a lot more thought put behind it - Right now it is a mix-and-match of variables.setting variables and set_something() methods. Right now it is really ugly, but when I take the time to get some updated documentation up and actually package it as a zip, I should have it cleaned up. In fact, I shouldn't have released this yet, but I was just starting to feel I needed to do something, since so much had be done on it and I hadn't put anything out in quite some time. Besides that, I'm quite excited to be using it - it's been a pain to build, but it's already saved me more time than had I not done anything like it.
In the end, I guess what I'm trying to say is: 1) Don't look at it to learn from. There may be
some good points, but there are bad points too, and 2) Don't rely too heavily on the interfaces.
While I don't anticipate changing them (only adding to them, and not forcing you to set
variables.property), this is still less than version 1, so I reserve the right
to change the interfaces until then. =)
Other than that, I would love to hear any feedback if you happen to be using it, or need help because the documentation is out of date, or if you tried to use it but couldn't get it to work. You can contact me here. You can find
cfrails at http://cfrails.riaforge.org/ .
Last modified on Jan 09, 2007 at 04:45 PM UTC - 5 hrs
Posted by Sam on Dec 03, 2006 at 01:15 PM UTC - 5 hrs
Regarding some of the problems we had in automating testing for our rails app, I was reminded of another today: how do we test functionality that requires the user to be logged in?
At first, I tried just setting the required session variables manually, in the setup method. Now, I can't see why that didn't work, and I didn't investigate long enough to find out, because Rachana Parmar, one of our team members, had a brilliant idea: why not just go through the login process? So, she wrote a test helper method that we could call that instantiated the user controller and performed the login action. After that, we had no more problems related to needing to log in to the app to test something.
On another note, I want to explain these short, almost useless postings: Part of the idea here is that I want to learn, and I find that when I write something down, I remember it better. And if I forget, I can always look it up when I know "I've seen this before, but I can't remember how we solved it." So, I find them helpful, and my hope is that someone else will too.
As another aside, for the longest time I didn't write down simple solutions like this and the previous one about upgrading functionality only for users with Javascript enabled, but the idea came to me when I read Venkat Subramaniam's and Andy Hunt's Practices of an Agile Developer. It's chock full of great advice, and even though most of it is obvious common sense (or seems that way), I found that I wasn't really doing a lot of the things it suggests. So, I have to give credit where credit is due.
Posted by Sam on Nov 30, 2006 at 06:27 AM UTC - 5 hrs
There are plenty out there who think it won't/can't cut it. But, Amazon is using it for Unspun. Check out the best programming languages or the home page (which is not working at the time I write this - so are those people right?).
David Heinemeier Hansson (the creator of Rails) on the Rails blog also mentions "a bunch of other announcements for high-profile companies going Ruby on Rails for various new projects" are forthcoming. Judging by the comments on that post, we have to hope it fairs better than the Unspun announcement.
Posted by Sam on Nov 29, 2006 at 01:30 PM UTC - 5 hrs
As I'm finishing up a Ruby on Rails project today, I've been reflecting on some of the issues we had, and what caused them. One glaring one is our lack of automated tests - in the unit (what Rails calls unit, anyway) test and functional test categories.
The "unit" tests - I'm not too concerned about, overall. These tests run against our models, and since most of them simply inherit from ActiveRecord::Base (ActiveRecord is an ORM for Ruby), with some relationships and validation thrown in (both of which taken care of by ActiveRecord). In the few cases we have some real code to test, we've (for the most part) tested it.
What concerns me are the functional tests (these test our controllers). Of course, Rails generates test code for the scaffolds (if you use them), so we started with a nice, passing, suite of tests. But the speed of development in Rails combined with the lack of a convenient way to run tests and the time it takes to run them has caused us to allow our coverage to degrade, pretty severely. It contributed to very few automated tests being written, compared with what we may have done in a Java project, for example.
Of course, there were some tests written, but not near as many as we'd normally like to have. When a small change takes just a couple of seconds to do and and (say, for instance) 30 seconds to run the test, it becomes too easy to just say, "forget it, I'm moving on to the next item on the list." It definitely takes a lot of discipline to maintain high coverage (I don't have any metrics for this project, but trust me, its nowhere near acceptable).
Well that got me thinking about Coldfusion. I notice myself lacking in tests there as well. I'd traditionally write more in Coldfusion that what we did on this Rails project, but almost certainly I'd write less than in an equivalent Java project. And it's not just less because there is less code in a CF or Rails project than in Java - I'm talking more about the percent of code covered by the tests, rather than the raw number. It's because there is no convenient way to run them, and run them quickly.
For Rails development, I'm using RadRails (an Eclipse plugin), so at least I can run the tests within the IDE. But, there is no easy way to run all the tests. I take that back, there is, but for some reason, it always hangs on me at 66%, and refuses to show me any results. I can also use rake (a Ruby make, in a nutshell) to run all the tests via the console, but it becomes very difficult to see which tests are failing and what the message was with any more than a few tests. Couple this with the execution time, and I've left testing for programming the application.
In Coldfusion, it takes quite a while to run the tests period. This is due partly to the limitations of performance in creating CFCs, but also to the fact I'm testing a lot of queries. But at least I can run them pretty conveniently, although it could be a lot better. Now, I've got some ideas to let you run one set of tests, or even one test at a time, and to separate slow tests from fast ones, and choose which ones you want to run. So, look out in the future for this test runner when I'm done with it (it's not going to be super-sweet, but I expect it could save some much-needed time). And then the next thing to go on my mile-long to-do list will be writing a desktop CF server and integrate the unit testing with CFEclipse... (yeah, right - that's going on the bottom of the list).
Last modified on Nov 29, 2006 at 01:35 PM UTC - 5 hrs
Posted by Sam on Nov 04, 2006 at 07:29 PM UTC - 5 hrs
So, the last couple of weeks I've been hard at work with school stuff, and also we've started a new (well, massively adding on to an existing one) project at work (and now another new one, as of last Wednesday). Because I seem to be so incredibly busy, and the projects need to be done "yesterday" (don't they all?), I built myself a little helper application that should increase my velocity by a ton - no more repetitive busy-work (well, it is greatly reduced anyway).
I've quite unimaginatively called it cfrails, since it was inspired by Ruby on Rails, and you can find it's project page at RIA Forge.
But first, you might want to read Getting Started with cfrails, so you can see how easily 0 lines of real code can create an interface to your database (the only lines are a couple of setup things, and cfcomponent creation).
I'd like to know what you think, so please leave a comment.
Last modified on Nov 04, 2006 at 07:30 PM UTC - 5 hrs
Posted by Sam on Sep 22, 2006 at 06:47 AM UTC - 5 hrs
I could have sworn I had RadRails and Instant Rails working and was able to develop Ruby on Rails applications several months ago. But, I think I had a funktified setup, as yesterday I couldn't get it to work at all.
So, I went looking for what was wrong, and came across Matt Griffith's screencast about how to get started with Rails (in less than 5 minutes!).
The first thing to do was get InstantRails. I already had it, but I downloaded again just in case I had old versions of everything. Then, I followed his easy directions. I've restated them here, since I'm new to this and easily forget.
- Unzip Instant Rails where you want it to reside. I chose C:\InstantRails
- Start Instant Rails. Click the "OK" button to let it update the configuration file
- If IIS is running (you get port 80 is in use by inetinfo.exe, stop IIS by typing iisreset /stop at the command prompt
- Open a Ruby console window through Instant Rails by clicking The "I" button -> Rails Applications -> Open Ruby Console Window
- You should be in C:\InstantRails\rails_apps. If you are working on a new application, generate it by using the command:
rails <project_name>. Matt called his demo, so the command was "rails demo."
- Move to the project directory, C:\InstantRails\rails_apps\demo
- Generate a controller: ruby script/generate controller <ControllerName>
- Generate a model: ruby script/generate model <ModelName>
- Create a migration by editing the file: C:\InstantRails\rails_apps\demo\db\migrate\001_create_posts.rb (assuming your model was called Post
- In the self.up method in that file, add the columns (one per line). For instance,
t.column :title, :string on the first line, then t.column :body, :text (he is using a blog as an example).
- Open the configuration file for the database. This is found in C:\InstantRails\rails_apps\demo\config\database.yml. Basically, you can find the names of the databases you are going to need to create. We'll be doing demo_development.
- Start Apache to create the database using php administrator interface to MySQL. You can start Apache by clicking on Apache->Start in Instant Rails. Be sure to unblock it if Windows Security asks.
- Click I->Configure->Database (via PhpMyAdmin)
- That will open a browser to the admin page. Just type in the name of the database and submit the form. Ours is called demo_development.
- Stop Apache (in Instant Rails click Apache->Stop)
- Start WEBrick: In C:\InstantRails\rails_apps\demo, type the command: ruby script/server. If Windows asks, unblock it. Take note of the port it will be using.
- Set up the controller to have something. Open C:\InstantRails\rails_apps\demo\app\controllers\blog_controller.rb. In the class, type
scaffold :post
- To create the database, run the migration. In C:\InstantRails\rails_apps\demo type the command: rake db:migrate
- Now you can go to http://localhost:3000 (or whatever port it is using). Here you'll see the "Welcome Aboard" page from Rails.
- To see your application, go to http://localhost:3000/blog. Play around, have fun.
If you are working on an existing application, obviously you can skip several of those steps (like, every one that involves creating a new application).
Now, I'll see about getting RadRails working in the next few days.
Last modified on Sep 26, 2006 at 08:15 AM UTC - 5 hrs
|
Me

|

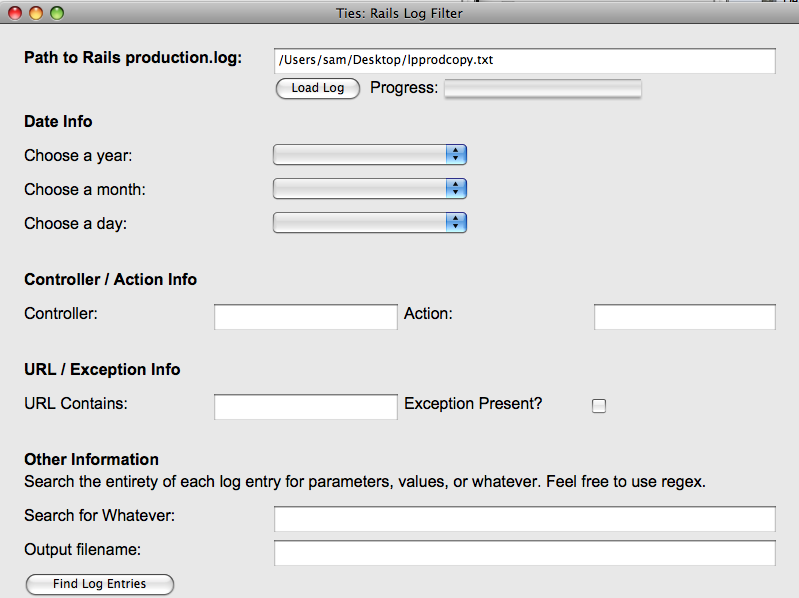
{kind=link}
{kind=link}