Posted by Sam on Apr 14, 2008 at 12:00 AM UTC - 5 hrs
If I am healthy, my body may come to rely on being so and forget what to do when I am sick. Therefore, it is better to be sick than to be healthy.
Since I spent my morning reading reddit and typing comments there instead of writing today's blog post, I'll let you in on this discussion that's going on over there: Larry O'Brien's article 30K application lines + 110K testing lines: Evidence of...? was posted to this thread on reddit, and the FUD started to fly. (If you're interested in the subject, there's also a thread about programmers not getting it, or not wanting to.)
It started with Larry quoting himself on praising extreme programming, and mentioning 110 thousand lines of test code to 30 thousand lines of application code, with the application having been developed in Python. Alan Holub took that as an indictment of dynamic languages, with Larry quoting him as saying:
I want to take exception to the notion that Python is adequate for a real programming project. The fact that 30K lines of code took 110K lines of tests is a real indictment of the language. My guess is that a significant portion of those tests are addressing potential errors that the compiler would have found in C# or Java. Moreover, all of those unnecessary tests take a lot of time to write, time that could have been spent working on the application.
In fact, many people were shocked at the amount of tests compared to code, and that's what the discussion (at least the part I was interested in) centered around. Four times as much test code as application logic is too much. It would shackle you, instilling fear in your heart and soul. No changes would ever be made with that kind of viscosity. Furthermore, tests can provide a false sense of security, a blankie, if you will.

You've got to be kidding. Having a test that will tell you when you broke existing functionality is pressure to avoid changes? To me, that's liberating!
Contrast that with not having a test to tell you when something broke. Does it even make sense to say having tests pressures you to avoid changes? Only if you fear having a program that works over having one that you think works.
Let me try a different approach. Take the following simple program:
if (someCondition is true)
do something
else
something else
if (anotherCondition is true)
do another thing
There are four execution paths: One where both someCondition and anotherCondition are true, one where they are both false, and one each where one is true and the other isn't.
In other words, we have six lines of code and at least four tests we should write to cover all the cases. If each test is just a single line, we still need to write the method names and end lines, so that would give us three lines per test - for a total of twelve lines of test code.
The test code size is already double the number of lines in our application code for this simple, six line program with four execution paths.
How many execution paths are in a 30 thousand line program?
Seeing as the number of execution paths in code is more likely to grow exponentially than linearly with each new line that gets written, 110 thousand lines of test code isn't actually all that much.
Further, the solution to the blankie problem is not "have fewer tests," it is to recognize that passing the tests is a necessary - not sufficient - condition of working software.
Following the blankie argument to its logical conclusion - that fewer tests mean you write better code because you are more careful - we should have no tests.
In fact part of the reason we want the tests is that we can make changes to the code with less fear of unknowingly breaking existing functionality or introducing defects in the software.
In the end, if someone is using the tests as a tool to do wrong, there is something wrong with the person, not the test. They will find another way to do wrong, even if we remove the tests from their arsenal.
Hey! Why don't you make your life easier and subscribe to the full post
or short blurb RSS feed? I'm so confident you'll love my smelly pasta plate
wisdom that I'm offering a no-strings-attached, lifetime money back guarantee!
Posted by Sam on Mar 17, 2008 at 12:00 AM UTC - 5 hrs
Suppose you want to write an algorithm that, when given a set of data points, will find an appropriate number
of clusters within the data. In other words, you want to find the k for input to the
k-means algorithm without having any
a priori knowledge about the data. (Here is my own
failed attempt at finding the k in k-means.)
def test_find_k_for_k_means_given_data_points()
data_points = [1,2,3,9,10,11,20,21,22]
k = find_k_for_k_means(data_points)
assert(k==3, "find_k_for_k_means found the wrong k.")
end
The test above is a reasonable specification for what the algorithm should do. But take it further: can you actually
design the algorithm by writing unit tests and making them pass?
I've previously expressed my doubt that TDD makes an effective approach to algorithm design.
More recently, I alluded to a some optimism towards the same idea.
Then, in a comment to the same post, Dat Chu asked about using unit tests in algorithm design, also referencing
something that Ben Nadel had said about asserting in code-comments
how the state of the algorithm should look at certain points.
That all led to this post, and me wanting to lay my thoughts out a little further.
In the general case, I agree with Dat that it would be better to have the executable tests/specs.
But, what Ben has described sounds like a stronger version of what Steve McConnell called
the pseudocode programming process
in Code Complete 2, which can be useful in working your way through an algorithm.
Taking it to the next step, with executable asserts - the "Iterative Approach To Algorithm Design" post
came out of a case similar to the one described at the top. Imagine you're coming up with something
completely new to you (in fact, in our case, we think it is new to anyone), and you know what you want
the results to be, but you're not quite sure how to transform the input to get them.
What
good does it do me to have that test if I don't know how to make it pass?
The unit test is useful for testing the entire unit (algorithm), but not as helpful for
testing the bits in between.
Now, you could potentially break the algorithm into pieces - but if you're working through it for the
first time, it's unlikely you'll see those breaking points up front.
When you do see them, you can write a test if you like. However, if it's not really a complete unit,
then you'll probably end up throwing the test away.
Because of that, and the inability to notice the units until
after you've created them, I like the simple assert statements as opposed to
the tests, at least in this case.
When we tried solving Sudoku using
TDD during a couple of meetings of the UH Code Dojo, we introduced a lot of methods I felt were artificially there, just to be able to test them.
We also created an object where one might not have existed had we known a way to solve Sudoku through
code to begin with.
Now, we could easily clean up the interface when we're done, but I don't really feel a compulsion to practice
TDD when working on algorithms like I've outlined above. I will write several tests for them to make sure
they work, but (at least today) I prefer to work through them without the hassle of writing tests for the
subatomic particles that make up the unit.
Posted by Sam on Mar 26, 2009 at 12:00 AM UTC - 5 hrs
This is the seventh in a
series of answers to
100 Interview Questions for Software Developers.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
This week's answers are about testing.
More...
- Do you know what a regression test is? How do you verify that new changes have not broken existing features?
You answered the second part of the question with the first: you run regression tests to ensure that
new changes have not broken existing features. For me, regression tests come in the form of already written tests,
especially unit tests that I've let turn into integration tests. However, you could write a regression test
before making a new change, and it would work as well.
The point is that you want to have some tests in place so that when you inevitably make changes, you can ensure
they didn't cascade throughout the system introducing bugs.
- How can you implement unit testing when there are dependencies between a business layer and a data layer?
Generally I'd let that unit test become an integration test. But if the time to run the tests was becoming
too long, I'd build a mock object that represented the data layer without hitting the database or file
system, and that would be expected to decrease the running time significantly.
- Which tools are essential to you for testing the quality of your code?
I don't know if anything is essential. If you've got asserts or throws, you
can always implement testing yourself, and a good eye for bad code helps as well. That said, to reduce
psychological barriers
to testing, it would be nice to have tools already made for this purpose.
Luckily, we have such tool available: unit testing frameworks and static code analysis tools in your language of choice.
- What types of problems have you encountered most often in your products after deployment?
Most recently I've encountered very specific integration errors, and written about some ideas on
fixing the polysystemic testing nightmare.
- Do you know what code coverage is? What types of code coverage are there?
Generally I'd thought it refers to the percentage of code covered by tests. I don't know what
the second question here refers to, as I thought it referred exclusively to testing.
- Do you know the difference between functional testing and exploratory testing? How would you test a web site?
I have to admit that before being asked this question, I wouldn't have thought about it. My guess is that
functional testing refers to testing the expected functionality of an application, whereas exploratory
testing involves testing without knowing any specific expectations.
As far as testing a web site, I'll have plenty of unit tests, some acceptance tests, perhaps some in
Selenium or a similar offering, as well as load testing. These aren't specific to web apps, however, except
for load testing in most cases.
I'm very interested in feedback here, given my misunderstanding of the question. If you can offer it, let me
thank you in advance.
- What is the difference between a test suite, a test case and a test plan? How would you organize testing?
A test suite is made up of test cases. I'm not sure what a test plan is, aside from the obvious which the
name would suggest. As far as organizing testing: I tend to organize my unit tests by class, with the method
they test in the same order they exist within that class.
- What kind of tests would you include for a smoke test of an ecommerce web site?
Again, here's another where I didn't know the terminology, so having to ask would result in demerits, but
knowing the answer of "what is a smoke test?" allows us to properly answer the question:
In software testing, a smoke test is a collection of written tests that are performed on a system prior to being accepted for further testing.

In that case, I'd click around (or more likely, write an application that could be run many times that does the same thing,
or use that application to write Selenium tests) looking for problems. I'd fill out some forms, and leave others blank.
Ideally, it would all be random, so as to find problems with the specs as often as possible without actually
testing all the specs, since the point seems to be to give us a quick way to reject the release without
doing full testing.
- What can you do reduce the chance that a customer finds things that he doesn't like during acceptance testing?
The best thing to do is to use incremental and iterative development that keeps the customer in the
loop providing feedback before you get down to acceptance testing. Have effective tests in place that
cover his requirements and ensure you hit those tests. When you come across something you know
won't pass muster, address it even though it might not be a formal requirement.
There are undoubtedly underhanded ways to achieve that goal as well, but I'm not in the habit of going
that direction, so I won't address them here.
- Can you tell me something that you have learned about testing and quality assurance in the last year?
Again I'm going to reference my polysystemic testing nightmare,
because it taught me that testing is extremely hard when you don't have the right tools at your disposal, and that
sometimes, you've got to create them on your own.
As far as reading goes, I'd start with literature on TDD, as it's
the most important yet underused as far as I'm concerned.
What advice would you give?
Posted by Sam on Feb 11, 2009 at 12:00 AM UTC - 5 hrs
What's with this nonsense about unit testing?
Giving You Context
Joel Spolsky and Jeff Atwood raised some controversy when discussing quality and unit testing on their Stack Overflow podcast (or, a transcript of the relevant part).
Joel started off that part of the conversation:
But, I feel like if a team really did have 100% code coverage of their unit tests, there'd be a couple of problems. One, they would have spent an awful lot of time writing unit tests, and they wouldn't necessarily be able to pay for that time in improved quality. I mean, they'd have some improved quality, and they'd have the ability to change things in their code with the confidence that they don't break anything, but that's it.
But the real problem with unit tests as I've discovered is that the type of changes that you tend to make as code evolves tend to break a constant percentage of your unit tests. Sometimes you will make a change to your code that, somehow, breaks 10% of your unit tests. Intentionally. Because you've changed the design of something... you've moved a menu, and now everything that relied on that menu being there... the menu is now elsewhere. And so all those tests now break. And you have to be able to go in and recreate those tests to reflect the new reality of the code.
So the end result is that, as your project gets bigger and bigger, if you really have a lot of unit tests, the amount of investment you'll have to make in maintaining those unit tests, keeping them up-to-date and keeping them passing, starts to become disproportional to the amount of benefit that you get out of them.
More...
Apparently, that was enough for others to come out of the shadows and discuss frankly why they don't see value in unit tests.
Joel was talking about people who suggest having 100% code coverage, but he said a couple of things about unit testing in general, namely the second and third paragraphs I quoted above: that changes to code may cause a ripple effect where you need to update up to 10% of your tests, and that "as your project gets bigger ... [effort maintaining your tests] starts to become disproportional to the amount of benefit that you get out of them."
One poster at Hacker News mentioned that it's possible for your tests to have 100% code coverage without really testing anything, so they can be a false sense of security (don't trust them!).
Bill Moorier said,
The metric I, and others I know, have used to judge unit testing is: does it find bugs? The answer has been no. For the majority of the code I write, it certainly doesn't find enough bugs to make it worth the investment of time.
He followed up by saying that user reports, automated monitoring systems, and logging do a much better job at finding bugs than unit tests do.
I don't really care if you write unit tests for your software (unless I also have to work on it or (sometimes) use it in some capacity). I don't write unit tests for everything. I don't practice TDD all the time. If you're new to it I'd recommend that you do it though -- until you have enough experience to determine which tests will bring you the value you want. (If you're not good at it, and haven't tried it on certain types of tests, how else would you know?)
 The Points
The Points
All of that was there to provide you context for this simple, short blog post:
- If changing your code means broken tests cascading through the system to the tune of 10%, you haven't written unit tests, have you?
(Further, the sorts of changes that would
needlessly break so many unit-cum-integration tests would be rare, unless you've somehow happened or tried very hard to design a tightly coupled spaghetti monster while writing unit tests too.)
-
I've not yet met a project where the unit tests are the maintenance nightmare. More often, it's the project itself, and it probably doesn't have unit tests to maintain. The larger the code base, with large numbers of dependencies and high coupling, the more resistant it is to change - with or without unit tests. The unit tests are there in part to give you confidence that your changes haven't broken the system when you do make a change.
If you're making changes where you expect the interface and/or behavior to change, I just don't see where the maintenance nightmare comes from regarding tests. In fact, you can run them and find out what else in your code base needs to change as a result of your modifications.
In short, these scenarios don't happen enough such that they would make testing worthless.
-
You may indeed write a bunch of tests that don't do anything to test your code, but why would you? You'd
have to try pretty hard to get 100% code coverage with your tests while succesfully testing nothing.
Perhaps some percentage of your tests under normal development will provide a false sense of security. But without any tests whatsoever, what sense of security will you have?
-
If you measure the value of unit testing by the number of bugs it finds (with more being better), you're looking at it completely wrong. That's like measuring the value of a prophylactic by the number of diseases you
get after using it. The value is in the number of bugs that never made it into production. As a 2008 study from
Microsoft finds [PDF], at least with TDD, that number can be astonishingly high.
-
As for user reports, automated monitoring systems, and logging doing a better job at finding bugs than unit testing: I agree. It's just that I'd prefer my shipped software to have fewer bugs for them to find, and I certainly don't look at my users as tests for my software quality once it's in production.
What are your thoughts?
Posted by Sam on Feb 18, 2008 at 06:43 AM UTC - 5 hrs
Last week, hgs asked,
I find it interesting that lots of people write about how to produce clean code,
how to do good design, taking care about language choice, interfaces, etc, but few people
write about the cases where there isn't time... So, I need to know what are the forces that tell you
to use a jolly good bodge?
I suspect we don't hear much about it because these other problems are often caused by that excuse.
And, in the long run, taking on that technical debt will likely cause you to go so slow that that's the
more interesting problem. In other words, by ignoring the need for good code, you are jumping into
a downward spiral where you are giving yourself even less time (or, making it take so long to do anything
that you may as well have less time).
More...
I think the solution is to start under-promising and over-delivering, as opposed to how most of us do it
now: giving lowball estimates because we think that's what they want to hear. But why lie to them?
If you're using iterative and incremental development, then if you've over-promised one iteration, you
are supposed to dial down your estimates for what you can accomplish in subsequent iterations, until
you finally get good at estimating. And estimates should include what it takes to do it right.
That's the party-line answer to the question. In short: it's never OK to write sloppy code, and
you should take precautions against ever putting yourself in a situation where those
viscous forces pull you in that direction.
The party-line answer is the best answer, but it doesn't fully address the question, and I'm not
always interested in party-line answers anyway. The viscosity (when it's easier
to do the wrong thing that the right thing) is the force behind the bodge. I don't like it, but I
recognize that there are going to be times you run into it and can't resist.
In those cases where you've already painted yourself into a corner, what then? That's the interesting
question here. How do you know the best
places to hack crapcode together and ignore those things that may take a little longer in the short run, but
whose value shows up in the long run?
The easy answer is the obvious one: cut corners in the code that is least likely to need to change or
be touched again. That's because (assuming your hack works) if we don't have to look at the code again,
who really cares that it was a nasty hack? The question whose answer is not so easy or
obvious is "what does such a place in the code look like?"
By the definition above, it would be the lower levels of your code. But if you do that, and inject a bug, then
many other parts of your application would be affected. So maybe that's not the right place to do it.
Instead, it would be better to do it in the higher levels, on which very little (if any) other code
depends. That way, you limit the effects of it. More importantly, if there are no outgoing dependencies
on it, it is easier to change than if other code were highly dependent on it. [ 1]
Maybe the crapcode can be isolated: if a class is already aweful, can you derive a new class from it and
make any new additions with higher quality? If a class is of high quality and you need to hack something together,
can you make a child class and put the hack there? [ 2]
Uncle Bob recently discussed when unit and acceptance
testing may safely be done away with. He put those numbers around 10 and a few thousand lines of code,
respectively.
In the end, there is no easy answer that I can find where I would definitively say, "that's the place for a bodging."
But I suspect there are some patterns we can look for, and I tried to identify a couple of those above.
Do you have any candidates you'd like to share?
Notes:
[1] A passing thought for which I have no answers:
The problem with even identifying those places is that by hacking together solutions, you are more likely
to inject defects into the code, which makes it more likely you'll need to touch it again.
[2] I use inheritance here because the new classes should be
able to be used without violating LSP.
However, you may very well be able to make those changes by favoring composition.
If you can, I'd advocate doing so.
Posted by Sam on Feb 11, 2008 at 05:56 AM UTC - 5 hrs
When I posted about why it's important to test everything first, Marc Esher
from MXUnit asked:
What do you find hard about TDD? When you're developing and you see yourself
not writing tests but jamming out code, what causes those moments for you?
And have you really, in all honesty, ever reaped significant benefits either in
productivity or quality from unit testing? Because there's a pretty large contingent
of folks who don't get much mileage out of TDD, and I can see where they're coming from.
My TDD Stumbling Blocks
I'll address the first bit in one word: viscosity. When it's easier to do the wrong thing
than the right thing, that's when I "see myself not writing tests but jamming out code."
But what causes the viscosity for me? Several things, really:
More...
-
When I'm working with a new framework or technology and I don't know how to test it: I'm trying
to avoid this now by learning languages by unit testing.
However, it's still tough. I started writing tests in C# .NET recently, but moving things to
ASP.NET has made me stumble a bit. That's mostly because I didn't take the time to understand
how it all worked before I started using it, and now I'm in the process of rewriting that code before it becomes too
entrenched.
- UIs: I still don't understand how to test them effectively. I like Selenium for the web,
but most tests I write with it are brittle. Because of that, I write them flippantly. It's a
vicious cycle too: without learning what works, I won't get better at identifying strategies to
remove the viscosity, so I won't write the tests.
- Finally, and most of all: legacy code bases, with no tests and poor design. It's so much easier to hack a fix than it
is to refactor to something testable. I've yet to read Michael Feathers' Working Effectively
With Legacy Code, so that may help when I finally do. (You can find a twelve page PDF article
@ the Object Mentor Resources Website.)
At the minimum, it should help motivate me to follow the elephant more often.
That last one is a killer for me. When I'm working on new projects, it's incredibly easy to write
tests as I develop. So much so that I don't bother thinking about not doing it. Unfortunately, most
of my work is not in new code bases.
I should also note that I often don't bother unit testing one-off throwaway scripts, but there
are times when I do.
On top of that, my unit tests rarely stay unit-sized. I generally just
let them turn into integration tests (stubbing objects as I need them when they are still
unit-sized). The only time I bother with mocks are if the integration piece is taking too long
to run tests.
For example, I might let the tests hit a testing database for a while, but as the tests get unbearable
to run, I'll write a different class to use that just returns some pre-done queries, or runs
all the logic except for save().
What about rewards?
In Code Complete 2, Steve McConnell talks about why it's important to measure experiments when
tuning your code:
Experience doesn't help much with optimization either. A person's experience might have
come from an old machine, language, or compiler - when any of those things changes, all
bets are off. You can never be sure about the effect of an optimization until you
measure the effect. (McConnell, 603)
I bring that up because I think of TDD (and any other practice we might do while
developing) as an optimization, and to be sure about it's effects, I'd have to measure it.
I haven't measured myself with TDD and without, so you can take what follows as anecdotal
evidence only. (Just because I say that, don't think you can try TDD for a couple of days
and decide it's slowing you down so it doesn't bring any benefit - it takes a while to
realize many of the benefits.)
So what rewards have I noticed? Like the problems I've had, there are a few:
-
Better design: My design without TDD has been a train wreck (much of that due to my
past ignorance of design principles), but has (still) improved as a result of TDD.
After all, TDD is a design activity. When writing a test, or determining what test to write next, you
are actively involved in thinking about how you want your code to behave, and how you want to
be able to reuse it.
As a byproduct of writing the tests, you get a very modular design - it becomes harder to do
the wrong thing (bad design), and easier to keep methods short and cohesive.
-
Less fear: Do you have any code that you just hate to touch because of the horror it sends
down your spine? I do. I've had code that is so complex and wrapped up within itself that I've
literally counseled not changing it for fear of it breaking and not being able to fix it. My
bet is that you've probably seen similar code.
The improved design TDD leads to helps that to some extent obviously. But there may be times
when even though you've got a test for something, it's still ugly code that could break easily.
The upside though, is you don't need to fear it breaking. In fact, if you think about it,
the fear isn't so much that you'll break the code - you fear you won't know you've broken it.
With good tests, you know when you've broken something and you can fix it before you deploy.
-
Time savings: It does take some time to write tests, but not as much as you might think.
As far as thinking about what you want your code to do, and how you want to reuse it, my
belief is that you are doing those things anyway. If not, you probably should be, and your
code likely looks much the same as some of that which I have to deal with
(for a description, see the title of this weblog).
It saves time as an executable specification - I don't have to trace through a big code base
to find out what a method does or how it's supposed to do it. I just look up the unit tests
and see it within a few clean lines.
Most of your tests will be 5-7 lines long, and you might have five tests per method. Even
if you just test the expected path through the code, ignoring exceptions and negative tests,
you'll be a lot better off and you'll only be writing one or two tests per method.
How long does that take? Maybe five minutes per test? (Which would put you at one minute per line!)
Maybe you won't achieve that velocity as you're learning the style of development, but certainly you could
be there (or better) after a month or two.
And you're testing anyway, right? I mean, you don't write code and check it in to development
without at least running it, do you? So, if you're programming from the bottom up, you've
already written a test runner of some sort to verify the results. What would it cost to
put that code into a test? Perhaps a minute or three, I would guess.
And now when you need to change that code, how long does it take you to login to the application,
find the page you need to run, fill out the form, and wait for a response to see if you were right?
If you're storing the result in the session, do you need to log out and go through the same process,
just to verify a simple calculation?
How much time would it save if you had written automated tests? Let's say it takes you two
minutes on average to verify a change each time you make one. If it took you half-an-hour
of thinking and writing five tests, then within 15 changes you've hit even and the rest is gravy.
How many times do you change the same piece of code? Once a year? Oh, but we didn't include all the
changes that occur during initial development. What if you got it wrong the first
time you made the fix? Certainly a piece of code changes 15 times even before you've got it
working in many cases.
Overall, I believe it does save time, but again, I haven't measured it. It's just all those little
things you do that take a few seconds at a time - you don't notice them. Instead, you think
of them as little tasks to get you from one place to another. That's what TDD is like: but
you don't see it that way if you haven't been using it for a while. You see it as an
extra task - one thing added to do. Instead, it replaces a lot of tasks.
And wouldn't it be better if you could push a button and verify results?
That's been my experience with troubles and benefits. What's yours been like? If you haven't
tried it, or are new, I'm happy to entertain questions below (or privately if you prefer) as
well.
Posted by Sam on Jan 30, 2008 at 07:34 AM UTC - 5 hrs
Because when you don't, how do you know your change to the code had any effect?
When a customer calls with a trouble ticket, do you just fix the problem, or do you
reproduce it first (a red test), make the fix, and test again (a green test, if you fixed the
problem)?
Likewise, if you write automated tests, but don't run them first to ensure
they fail, it defeats the purpose of having the test. Most of the time you won't
run into problems, but when you do, it's not fun trying to solve them. Who would
think to look at a test that's passing?
The solution, of course, is to forget about testing altogether. Then we won't be lulled into
a false sense of security. Right?
Last modified on Jan 30, 2008 at 07:35 AM UTC - 5 hrs
Posted by Sam on Jan 14, 2008 at 06:42 AM UTC - 5 hrs
This is a story about my journey as a programmer, the major highs and lows I've had along the way, and
how this post came to be. It's not about how ecstasy made me a better programmer, so I apologize if that's why you came.
In any case, we'll start at the end, jump to
the beginning, and move along back to today. It's long, but I hope the read is as rewarding as the write.
A while back,
Reg Braithwaite
challenged programing bloggers with three posts he'd love to read (and one that he wouldn't). I loved
the idea so much that I've been thinking about all my experiences as a programmer off and on for the
last several months, trying to find the links between what I learned from certain languages that made
me a better programmer in others, and how they made me better overall. That's how this post came to be.
More...
The experiences discussed herein were valuable in their own right, but the challenge itself is rewarding
as well. How often do we pause to reflect on what we've learned, and more importantly, how it has changed
us? Because of that, I recommend you perform the exercise as well.
I freely admit that some of this isn't necessarily caused by my experiences with the language alone - but
instead shaped by the languages and my experiences surrounding the times.
One last bit of administrata: Some of these memories are over a decade old, and therefore may bleed together
and/or be unfactual. Please forgive the minor errors due to memory loss.
How QBASIC Made Me A Programmer
As I've said before, from the time I was very young, I had an interest in making games.
I was enamored with my Atari 2600, and then later the NES.
I also enjoyed a playground game with Donald Duck
and Spelunker.
Before I was 10, I had a notepad with designs for my as-yet-unreleased blockbuster of a side-scrolling game that would run on
my very own Super Sanola game console (I had the shell designed, not the electronics).
It was that intense interest in how to make a game that led me to inspect some of the source code Microsoft
provided with QBASIC. After learning PRINT, INPUT,
IF..THEN, and GOTO (and of course SomeLabel: to go to)
I was ready to take a shot at my first text-based adventure game.
The game wasn't all that big - consisting of a few rooms, the NEWS
directions, swinging of a sword against a few monsters, and keeping track of treasure and stats for everything -
but it was a complete mess.
The experience with QBASIC taught me that, for any given program of sufficient complexity, you really only
need three to four language constructs:
- Input
- Output
- Conditional statements
- Control structures
Even the control structures may not be necessary there. Why? Suppose you know a set of operations will
be performed an unknown but arbitrary amount of times. Suppose also that it will
be performed less than X number of times, where X is a known quantity smaller than infinity. Then you
can simply write out X number of conditionals to cover all the cases. Not efficient, but not a requirement
either.
Unfortunately, that experience and its lesson stuck with me for a while. (Hence, the title of this weblog.)
Side Note: The number of language constructs I mentioned that are necessary is not from a scientific
source - just from the top of my head at the time I wrote it. If I'm wrong on the amount (be it too high or too low), I always appreciate corrections in the comments.
What ANSI Art taught me about programming
When I started making ANSI art, I was unaware
of TheDraw. Instead, I opened up those .ans files I
enjoyed looking at so much in MS-DOS Editor to
see how it was done. A bunch of escape codes and blocks
came together to produce a thing of visual beauty.

Since all I knew about were the escape codes and the blocks (alt-177, 178, 219-223 mostly), naturally
I used the MS-DOS Editor to create my own art. The limitations of the medium were
strangling, but that was what made it fun.
And I'm sure you can imagine the pain - worse than programming in an assembly language (at least for relatively
small programs).
Nevertheless, the experience taught me some valuable lessons:
- Even though we value people over tools, don't underestimate
the value of a good tool. In fact, when attempting anything new to you, see if there's a tool that can
help you. Back then, I was on local BBSs, and not
the 1337 ones when I first started out. Now, the Internet is ubiquitous. We don't have an excuse anymore.
-
I can now navigate through really bad code (and code that is limited by the language)
a bit easier than I might otherwise have been able to do. I might have to do some experimenting to see what the symbols mean,
but I imagine everyone would.
And to be fair, I'm sure years of personally producing such crapcode also has
something to do with my navigation abilities.
-
Perhaps most importantly, it taught me the value of working in small chunks and
taking baby steps.
When you can't see the result of what you're doing, you've got to constantly check the results
of the latest change, and most software systems are like that. Moreover, when you encounter
something unexpected, an effective approach is to isolate the problem by isolating the
code. In doing so, you can reproduce the problem and problem area, making the fix much
easier.
The Middle Years (included for completeness' sake)
The middle years included exposure to Turbo Pascal,
MASM, C, and C++, and some small experiences in other places as well. Although I learned many lessons,
there are far too many to list here, and most are so small as to not be significant on their own.
Therefore, they are uninteresting for the purposes of this post.
However, there were two lessons I learned from this time (but not during) that are significant:
-
Learn to compile your own $&*@%# programs
(or, learn to fish instead of asking for them).
-
Stop being an arrogant know-it-all prick and admit you know nothing.
As you can tell, I was quite the cowboy coding young buck. I've tried to change that in recent years.
How ColdFusion made me a better programmer when I use Java
Although I've written a ton of bad code in ColdFusion, I've also written a couple of good lines
here and there. I came into ColdFusion with the experiences I've related above this, and my early times
with it definitely illustrate that fact. I cared nothing for small files, knew nothing of abstraction,
and horrendous god-files were created as a result.
If you're a fan of Italian food, looking through my code would make your mouth water.
DRY principle?
Forget about it. I still thought code reuse meant copy and paste.
Still, ColdFusion taught me one important aspect that got me started on the path to
Object Oriented Enlightenment:
Database access shouldn't require several lines of boilerplate code to execute one line of SQL.
Because of my experience with ColdFusion, I wrote my first reusable class in Java that took the boilerplating away, let me instantiate a single object,
and use it for queries.
How Java taught me to write better programs in Ruby, C#, CF and others
It was around the time I started using Java quite a bit that I discovered Uncle Bob's Principles of OOD,
so much of the improvement here is only indirectly related to Java.
Sure, I had heard about object oriented programming, but either I shrugged it off ("who needs that?") or
didn't "get" it (or more likely, a combination of both).
Whatever it was, it took a couple of years of revisiting my own crapcode in ColdFusion and Java as a "professional"
to tip me over the edge. I had to find a better way: Grad school here I come!
The better way was to find a new career. I was going to enter as a Political Scientist
and drop programming altogether. I had seemingly lost all passion for the subject.
Fortunately for me now, the political science department wasn't accepting Spring entrance, so I decide to
at least get started in computer science. Even more luckily, that first semester
Venkat introduced me to the solution to many my problems,
and got me excited about programming again.
I was using Java fairly heavily during all this time, so learning the principles behind OO in depth and
in Java allowed me to extrapolate that for use in other languages.
I focused on principles, not recipes.
On top of it all, Java taught me about unit testing with
JUnit. Now, the first thing I look for when evaluating a language
is a unit testing framework.
What Ruby taught me that the others didn't
My experience with Ruby over the last year or so has been invaluable. In particular, there are four
lessons I've taken (or am in the process of taking):
-
The importance of code as data, or higher-order functions, or first-order functions, or blocks or
closures: After learning how to appropriately use
yield, I really miss it when I'm
using a language where it's lacking.
-
There is value in viewing programming as the construction of lanugages, and DSLs are useful
tools to have in your toolbox.
-
Metaprogramming is OK. Before Ruby, I used metaprogramming very sparingly. Part of that is because
I didn't understand it, and the other part is I didn't take the time to understand it because I
had heard how slow it can make your programs.
Needless to say, after seeing it in action in Ruby, I started using those features more extensively
everywhere else. After seeing Rails, I very rarely write queries in ColdFusion - instead, I've
got a component that takes care of it for me.
-
Because of my interests in Java and Ruby, I've recently started browsing JRuby's source code
and issue tracker.
I'm not yet able to put into words what I'm learning, but that time will come with
some more experience. In any case, I can't imagine that I'll learn nothing from the likes of
Charlie Nutter, Ola Bini,
Thomas Enebo, and others. Can you?
What's next?
Missing from my experience has been a functional language. Sure, I had a tiny bit of Lisp in college, but
not enough to say I got anything out of it. So this year, I'm going to do something useful and not useful
in Erlang. Perhaps next I'll go for Lisp. We'll see where time takes me after that.
That's been my journey. What's yours been like?
Now that I've written that post, I have a request for a post I'd like to see:
What have you learned from a non-programming-related discipline that's made you a better programmer?
Last modified on Jan 16, 2008 at 07:09 AM UTC - 5 hrs
Posted by Sam on Dec 10, 2007 at 11:46 AM UTC - 5 hrs
Here's some pseudocode that got added to a production system that might just be the very definition of a simple change:
-
Add a link from one page to cancel_order.cfm?orderID=12345
-
In that new page, add the following two queries:
- update orders set canceled = 1, canceledOn=getDate() where orderID=#url.orderID#
- delete from orderItems
Now, upload those changes to the production server, and run it real quick to be sure it does what you meant it to do.
Then you say to yourself, "Wait, why is the page taking several seconds to load?"
"Holy $%^@," you think aloud, "I just deleted every item from every order in the system!"
It's easy enough for you to recover the data from the backups. It isn't quite as easy to recover from the heart attack.
Steve McConnell (among others) says that the easiest changes are the most important ones to test, as you aren't thinking quite as hard about it when you make them.
Are there any unbelievers left out there?
Last modified on Dec 10, 2007 at 11:46 AM UTC - 5 hrs
Posted by Sam on Oct 04, 2007 at 04:00 PM UTC - 5 hrs
A couple of weeks ago the UH Code Dojo embarked on the
fantastic voyage that is writing a program to solve Sudoku puzzles, in Ruby. This week, we
continued that journey.
Though we still haven't completed the problem (we'll be meeting again tenatively on October 15, 2007 to
do that), we did construct what we think is a viable plan for getting there, and began to implement some
of it.
The idea was based around this algorithm (or something close to it):
More...
while (!puzzle.solved)
{
find the most constrained row, column, or submatrix
for each open square in the most constrained space,
find intersection of valid numbers to fill the square
starting with the most constrained,
begin filling in open squares with available numbers
}
With that in mind, we started again with TDD.
I'm not going to explain the rationale behind each peice of code, since the idea was presented above.
However, please feel free to ask any questions if you are confused, or even if you'd just like
to challenge our ideas.
Here are the tests we added:
def test_find_most_constrained_row_column_or_submatrix
assert_equal "4 c", @solver.get_most_constrained
end
def test_get_available_numbers
most_constrained = @solver.get_most_constrained
assert_equal [3,4,5], @solver.get_available_numbers(most_constrained).sort
end
def test_get_first_empty_cell_from_most_constrained
most_constrained = @solver.get_most_constrained
indices = @solver.get_first_empty_cell(most_constrained)
assert_equal [2,4], indices
end
def test_get_first_empty_cell_in_submatrix
indices = @solver.get_first_empty_cell("0 m")
assert_equal [0,2], indices
end
And here is the code to make the tests pass:
def get_most_constrained
min_open = 10
min_index = 0
@board.each_index do |i|
this_open = @board[i].length - @board[i].reject{|x| x==0}.length
min_open, min_index = this_open, i.to_s + " r" if this_open < min_open
end
#min_row = @board[min_index.split(" ")]
@board.transpose.each_index do |i|
this_open = @board.transpose[i].length - @board.transpose[i].reject{|x| x==0}.length
min_open, min_index = this_open, i.to_s + " c" if this_open < min_open
end
(0..8).each do |index|
flat_subm = @board.get_submatrix_by_index(index).flatten
this_open = flat_subm.length - flat_subm.reject{|x| x==0}.length
min_open, min_index = this_open, index.to_s + " m" if this_open < min_open
end
return min_index
end
def get_available_numbers(most_constrained)
index, flag = most_constrained.split(" ")[0].to_i,most_constrained.split(" ")[1]
avail = [1,2,3,4,5,6,7,8,9] - @board[index] if flag == "r"
avail = [1,2,3,4,5,6,7,8,9] - @board.transpose[index] if flag == "c"
avail = [1,2,3,4,5,6,7,8,9] - @board.get_submatrix_by_index(index).flatten if flag == "m"
return avail
end
def get_first_empty_cell(most_constrained)
index, flag = most_constrained.split(" ")[0].to_i,most_constrained.split(" ")[1]
result = index, @board[index].index(0) if flag == "r"
result = @board.transpose[index].index(0), index if flag == "c"
result = index%3*3,index*3+@board.get_submatrix_by_index(index).flatten.index(0) if flag == "m"
return result
end
Obviously we need to clean out that commented-out line, and
I feel kind of uncomfortable with the small amount of tests we have compared to code. That unease was
compounded when we noticed a call to get_submatrix instead of get_submatrix_by_index.
Everything passed because we were only testing the first most constrained column. Of course, it will
get tested eventually when we have test_solve, but it was good that the pair-room-programming
caught the defect.
I'm also not entirely convinced I like passing around the index of the most constrained whatever along
with a flag denoting what type it is. I really think we can come up with a better way to do that, so
I'm hoping that will change before we rely too much on it, and it becomes impossible to change without
cascading.
Finally, we also set up a repository for this and all of our future code. It's not yet open to the public
as of this writing (though I expect that
to change soon). In any case, if you'd like to get the full source code to this, you can find our Google Code
site
at http://code.google.com/p/uhcodedojo/.
If you'd like to aid me in my quest to be an idea vacuum (cleaner!), or just have a question, please feel
free to contribute with a comment.
Last modified on Oct 04, 2007 at 04:12 PM UTC - 5 hrs
Posted by Sam on Sep 19, 2007 at 01:37 PM UTC - 5 hrs
A couple of days ago the UH Code Dojo met once again (we took the summer off). I had come in wanting to
figure out five different ways to implement binary search.
The first two - iteratively and recursively - are easy to come up with. But what about three
other implementations? I felt it would be a good exercise in creative thinking, and pehaps it
would teach us new ways to look at problems. I still want to do that at some point, but
the group decided it might be more fun to tackle to problem of solving any Sudoku board,
and that was fine with me.
Remembering the trouble
Ron Jeffries had in
trying to
TDD a solution
to Sudoku, I was a bit
weary of following that path, thinking instead we might try
Peter Norvig's approach. (Note: I haven't looked
at Norvig's solution yet, so don't spoil it for me!)
More...
Instead, we agreed that certainly there are some aspects that are testable, although
the actual search algorithm that finds solutions is likely to be a unit in itself, and therefore
isn't likely to be testable outside of presenting it a board and testing that its outputted solution
is a known solution to the test board.
On that note, our first test was:
require 'test/unit'
require 'sudokusolver'
class TestSudoku < Test::Unit::TestCase
def setup
@board = [[5, 3, 0, 0, 7, 0, 0, 0, 0],
[6, 0, 0, 1, 9, 5, 0, 0, 0],
[0, 9, 8, 0, 0, 0, 0, 6, 0],
[8, 0, 0, 0, 6, 0, 0, 0, 3],
[4, 0, 0, 8, 0, 3, 0, 0, 1],
[7, 0, 0, 0, 2, 0, 0, 0, 6],
[0, 6, 0, 0, 0, 0, 2, 8, 0],
[0, 0, 0, 4 ,1 ,9 ,0, 0, 5],
[0, 0, 0, 0, 8, 0, 0, 7, 9]]
@solution =[[5, 3, 4, 6, 7, 8, 9, 1, 2],
[6, 7, 2, 1, 9, 5, 3, 4, 8],
[1, 9, 8, 3, 4, 2, 5, 6, 7],
[8, 5, 9, 7, 6, 1, 4, 2, 3],
[4, 2, 6, 8, 5, 3, 7, 9, 1],
[7, 1, 3, 9, 2, 4, 8, 5, 6],
[9, 6, 1, 5, 3, 7, 2, 8, 4],
[2, 8, 7, 4 ,1 ,9 ,6, 3, 5],
[3, 4, 5, 2, 8, 6, 1, 7, 9]]
@solver = SudokuSolver.new
end
def test_solve
our_solution = @solver.solve(@board)
assert_equal(@solution, our_solution)
end
end
We promptly commented out the test though, since we'd never get it to pass until we were done. That
doesn't sound very helpful at this point. Instead, we started writing tests for testing the validity
of rows, columns, and blocks (blocks are what we called the 3x3 submatrices in a Sudoku board).
Our idea was that a row, column, or block is in a valid state
if it contains no duplicates of the digits 1 through 9. Zeroes (open cells) are acceptable in
a valid board. Obviously, they are not acceptable in a solved board.
To get there, we realized we needed to make initialize take the initial game board
as an argument (so you'll need to change that in the TestSudokuSolver#setup method and
SudokuSolver#solve, if you created it), and then we added the following tests (iteratively!):
def test_valid_row
assert @solver.valid_row?(0)
end
def test_valid_allrows
(0..8).each do |row|
assert @solver.valid_row?(row)
end
end
The implementation wasn't difficult, of course. We just need to reject all zeroes from the row, then run
uniq! on the resulting array. Since uniq! returns nil if each
element in the array is unique, and nil evaluates to false, we have:
class SudokuSolver
def initialize(board)
@board = board
end
def valid_row?(row_num)
@board[row_num].reject{|x| x==0}.uniq! == nil
end
end
At this point, we moved on to the columns. The test is essentially the same as for rows:
def test_valid_column
assert @solver.valid_column?(0)
end
def test_valid_allcolumns
(0..8).each do |column|
assert @solver.valid_column?(column)
end
end
The test failed, so we had to make it pass. Basically, this method is also the same for columns as it was
for rows. We just need to call Array#transpose# on the board, and follow along. The
valid_column? one-liner was @board.transpose[col_num].reject{|x| x==0}.uniq! == nil.
We added that first, made sure the test passed, and then refactored SudokuSolver
to remove the duplication:
class SudokuSolver
def initialize(board)
@board = board
end
def valid_row?(row_num)
valid?(@board[row_num])
end
def valid_column?(col_num)
valid?(@board.transpose[col_num])
end
def valid?(array)
array.reject{|x| x==0}.uniq! == nil
end
end
All the tests were green, so we moved on to testing blocks. We first tried slicing in two dimensions, but
that didn't work: @board[0..2][0..2]. We were also surprised Ruby didn't have something
like an Array#extract_submatrix method, which assumes it it passed an array of arrays (hey,
it had a transpose method). Instead, we created our own. I came up with some nasty, convoluted code,
which I thought was rather neat until I rewrote it today.
Ordinarily, I'd love to show it as a fine example of how much prettier it could have become. However, due
to a temporary lapse into idiocy on my part: we were editing in 2 editors, and I accidentally saved the
earlier version after the working version instead of telling it not to save. Because of that,
I'm having to re-implement this.
Now that that sorry excuse is out of the way, here is our test for, and implementation of extract_submatrix:
def test_extract_submatrix
assert_equal [[1,2,3],[4,5,6],[7,8,9]].extract_submatrix(1..2,1..2) , [[5,6],[8,9]]
end
class Array
def extract_submatrix(row_range, col_range)
self[row_range].transpose[col_range].transpose
end
end
Unfortunately, that's where we ran out of time, so we didn't even get to the interesting problems Sudoku
could present. On the other hand, we did agree to meet again two weeks from that meeting (instead of a month),
so we'll continue to explore again on that day.
Thoughts? (Especially about idiomatic Ruby for Array#extract_submatrix)
Update: Changed the misspelled title from SudokoSolver to SudokuSolver.
Update 2: SudokuSolver Part 2 is now available.
Last modified on Oct 04, 2007 at 04:05 PM UTC - 5 hrs
Posted by Sam on Sep 10, 2007 at 12:48 PM UTC - 5 hrs
If you don't care about the background behind this, the reasons why you might want to use
rules based programming, or a bit of theory, you can skip straight the Drools tutorial.
Background
One of the concepts I love to think about (and do) is raising the level of abstraction in a system.
The more often you are telling the computer what, and not how, the better.
Of course, somewhere someone is doing imperative programming (telling it how), but I like to
try to hide much of that somewhere and focus more on declarative programming (telling it what). Many
times, that's the result of abstraction in general and DSLs
and rules-based programming more specifically.
More...
As a side note, let me say that this is not necessarily a zero-sum game. In one aspect you may be declaratively
programming while in another you are doing so imperatively. Example:
function constructARecord()
{
this.name=readFileLineNumber(fileName, 1);
this.phone=readFileLineNumber(fileName, 2);
this.address=readFileLineNumber(fileName, 3);
}
You are telling it how to construct a record, but you are not telling it how to read the file. Instead,
you are just telling it to read the file.
Anyway, enough of that diversion. I hope I've convinced you.
When I finished writing the (half-working) partial order planner in Ruby,
I mentioned I might like "to take actions as functions, which receive preconditions as their parameters,
and whose output are effects" (let me give a special thanks to Hugh Sasse for his help and ideas in trying to use TSort for it while I'm
on the subject).
Doing so may have worked well when generalizing the solution to a rules engine instead of just a planner (they are conceptually
quite similar). That's
often intrigued me from both a business application and game programming standpoint.
The good news is (as you probably already know), this has already been done for us. That was the
subject of Venkat's talk that I attended at No Fluff Just Stuff at the end of June 2007.
Why use rules-based programming?
After a quick introduction, Venkat jumped right into why you might want to use a rules engine.
The most prominent reasons all revolve around the benefits provided by separating concerns:
When business rules change almost daily, changes to source code can be costly. Separation of knowledge
from implementation reduces this cost by having no requirement to change the source code.
Additionally, instead of providing long chains of if...else statements, using a rule engine
allows you the benefits of declarative programming.
A bit of theory
The three most important aspects for specifying the system are facts, patterns, and the rules themselves.
It's hard to describe in a couple of sentences, but your intuition should serve you well - I don't think
you need to know all of the theory to understand a rule-based system.
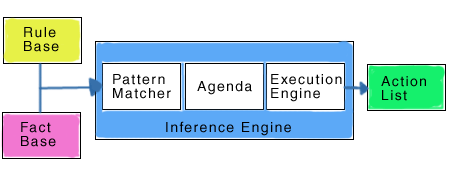
Rules Engine based on Venkat's notes
Facts are just bits of information that can be used to make decisions. Patterns are similar, but can
contain variables that allow them to be expanded into other patterns or facts. Finally, rules have
predicates/premises that if met by the facts will fire the rule which allows the action to be
performed (or conclusion to be made).
(Another side note: See JSR 94 for a Java spec for Rules Engines
or this google query for some theory.
Norvig's and Russell's Artificial Intelligence: A Modern Approach
also has good explanations, and is a good introduction to AI in general (though being a textbook, it's pricey at > $90 US)).
(Yet another side note: the computational complexity of this pattern matching can be enormous, but the
Rete Algorithm will help, so don't
prematurely optimize your rules.)
Drools
Now that we know a bit of the theory behind rules-based systems, let's get into the practical to show
how easy it can be (and aid in removing fear of new technology to become a generalist).
First, you can get Drools 2.5 at Codehaus or
version 3, 4 or better from JBoss.
At the time of writing, the original Drools lets you use XML with Java or Groovy, Python, or Drools' own
DSL to implement rules, while the JBoss version (I believe) is (still) limited to Java or the DSL.
Since I avoid XML like the plague (well, not that bad),
I'll go the DSL route.
First, you'll need to download Drools and unzip it to a place you keep external Java libraries.
I'm working with Drools 4.0.1. After that, I created a new Java project in Eclipse and added a new user
library for Drools, then added that to my build path (I used all of the Drools JARs in the library).
(And don't forget JUnit if you don't have it come up automatically!)
Errors you might need to fix
For reference for anyone who might run across the problems I did, I'm going to include a few of the
errors I came into contact with and how I resolved them. I was starting with a pre-done example, but
I will show the process used to create it after trudging through the errors. Feel free to
skip this section if you're not having problems.
After trying the minimal additions to the build path I mentioned above, I was seeing an error
that javax.rules was not being recognized. I added
jsr94-1.1.jar to my Drools library (this is included under /lib in the Drools download) and it was
finally able to compile.
When running the unit tests, however, I still got this error:
org.drools.RuntimeDroolsException: Unable to load dialect 'org.drools.rule.builder.dialect.java.JavaDialectConfiguration:java'
At that point I just decided to add all the dependencies in /lib to my Drools library and the error
went away. Obviously you don't need Ant, but I wasn't quite in the mood to go hunting for the minimum
of what I needed. You might feel differently, however.
Now that the dialect was able to be loaded, I got another error:
org.drools.rule.InvalidRulePackage: Rule Compilation error : [Rule name=Some Rule Name, agendaGroup=MAIN, salience=-1, no-loop=false]
com/codeodor/Rule_Some_Rule_Name_0.java (8:349) : Cannot invoke intValue() on the primitive type int
As you might expect, this was happening simply because the rule was receiving an int and was
trying to call a method from Integer on it.
After all that, my pre-made example ran correctly, and being comfortable that I had Drools working,
I was ready to try my own.
An Example: Getting a Home Loan
From where I sit, the process of determining how and when to give a home loan is complex and can change
quite often. You need to consider an applicant's credit score, income, and down payment, among
other things. Therefore, I think it is a good candidate for use with Drools.
To keep the tutorial simple
(and short), our loan determinizer will only consider credit score and down payment in regards to the
cost of the house.
First we'll define the HomeBuyer class. I don't feel the need for tests, because as you'll
see, it does next to nothing.
package com.codeodor;
public class HomeBuyer {
int _creditScore;
int _downPayment;
String _name;
public HomeBuyer(String buyerName, int creditScore, int downPayment) {
_name = buyerName;
_creditScore = creditScore;
_downPayment = downPayment;
}
public String getName() {
return _name;
}
public int getCreditScore(){
return _creditScore;
}
public int getDownPayment(){
return _downPayment;
}
}
Next, we'll need a class that sets up and runs the rules. I'm not feeling
the need to test this directly either, because it is 99% boilerplate and all of the code
gets tested when we test the rules anyway. Here is our LoanDeterminizer:
package com.codeodor;
import org.drools.jsr94.rules.RuleServiceProviderImpl;
import javax.rules.RuleServiceProviderManager;
import javax.rules.RuleServiceProvider;
import javax.rules.StatelessRuleSession;
import javax.rules.RuleRuntime;
import javax.rules.admin.RuleAdministrator;
import javax.rules.admin.LocalRuleExecutionSetProvider;
import javax.rules.admin.RuleExecutionSet;
import java.io.InputStream;
import java.util.ArrayList;
public class LoanDeterminizer {
// the meat of our class
private boolean _okToGiveLoan;
private HomeBuyer _homeBuyer;
private int _costOfHome;
public boolean giveLoan(HomeBuyer h, int costOfHome) {
_okToGiveLoan = true;
_homeBuyer = h;
_costOfHome = costOfHome;
ArrayList<Object> objectList = new ArrayList<Object>();
objectList.add(h);
objectList.add(costOfHome);
objectList.add(this);
return _okToGiveLoan;
}
public HomeBuyer getHomeBuyer() { return _homeBuyer; }
public int getCostOfHome() { return _costOfHome; }
public boolean getOkToGiveLoan() { return _okToGiveLoan; }
public double getPercentDown() { return(double)(_homeBuyer.getDownPayment()/_costOfHome); }
// semi boiler plate (values or names change based on name)
private final String RULE_URI = "LoanRules.drl"; // this is the file name our Rules are contained in
public LoanDeterminizer() throws Exception // the constructor name obviously changes based on class name
{
prepare();
}
// complete boiler plate code from Venkat's presentation examples follows
// I imagine some of this changes based on how you want to use Drools
private final String RULE_SERVICE_PROVIDER = "http://drools.org/";
private StatelessRuleSession _statelessRuleSession;
private RuleAdministrator _ruleAdministrator;
private boolean _clean = false;
protected void finalize() throws Throwable
{
if (!_clean) { cleanUp(); }
}
private void prepare() throws Exception
{
RuleServiceProviderManager.registerRuleServiceProvider(
RULE_SERVICE_PROVIDER, RuleServiceProviderImpl.class );
RuleServiceProvider ruleServiceProvider =
RuleServiceProviderManager.getRuleServiceProvider(RULE_SERVICE_PROVIDER);
_ruleAdministrator = ruleServiceProvider.getRuleAdministrator( );
LocalRuleExecutionSetProvider ruleSetProvider =
_ruleAdministrator.getLocalRuleExecutionSetProvider(null);
InputStream rules = Exchange.class.getResourceAsStream(RULE_URI);
RuleExecutionSet ruleExecutionSet =
ruleSetProvider.createRuleExecutionSet(rules, null);
_ruleAdministrator.registerRuleExecutionSet(RULE_URI, ruleExecutionSet, null);
RuleRuntime ruleRuntime = ruleServiceProvider.getRuleRuntime();
_statelessRuleSession =
(StatelessRuleSession) ruleRuntime.createRuleSession(
RULE_URI, null, RuleRuntime.STATELESS_SESSION_TYPE );
}
public void cleanUp() throws Exception
{
_clean = true;
_statelessRuleSession.release( );
_ruleAdministrator.deregisterRuleExecutionSet(RULE_URI, null);
}
}
I told you there was a lot of boilerplate code there. I won't explain it all because:
- It doesn't interest me
- I don't yet know as much as I should about it
I fully grant that reason number one may be partially or completely dependent on the second one.
In any case, now we can finally write our rules. I'll be starting with a test:
package com.codeodor;
import junit.framework.TestCase;
public class TestRules extends TestCase {
public void test_poor_credit_rating_gets_no_loan() throws Exception
{
LoanDeterminizer ld = new LoanDeterminizer();
HomeBuyer h = new HomeBuyer("Ima Inalotadebt and Idun Payet", 100, 20000);
boolean result = ld.giveLoan(h, 150000);
assertFalse(result);
ld.cleanUp();
}
}
And our test fails, which is what we wanted. We didn't yet create our rule file, LoanRules.drl, so
let's do that now.
package com.codeodor
rule "Poor credit score never gets a loan"
salience 2
when
buyer : HomeBuyer(creditScore < 400)
loan_determinizer : LoanDeterminizer(homeBuyer == buyer)
then
System.out.println(buyer.getName() + " has too low a credit rating to get the loan.");
loan_determinizer.setOkToGiveLoan(false);
end
The string following "rule" is the rule's name. Salience is one of the ways Drools performs conflict resolution.
Finally, the first two lines tell it that buyer is a variable of type HomeBuyer with a credit score of less than 400
and loan_determinizer is the LoanDeterminizer passed in with the object list
where the homeBuyer is what we've called buyer in our rule. If either of
those conditions fails to match, this rule is skipped.
Hopefully that
makes some sense to you. If not, let me know in the comments and I'll try again.
And now back to
our regularly scheduled test:
running it again still results in a red bar. This time, the problem is:
org.drools.rule.InvalidRulePackage: Rule Compilation error : [Rule name=Poor credit score never gets a loan, agendaGroup=MAIN, salience=2, no-loop=false]
com/codeodor/Rule_Poor_credit_score_never_gets_a_loan_0.java (7:538) : The method setOkToGiveLoan(boolean) is undefined for the type LoanDeterminizer
The key part here is "the method setOkToGiveLoan(boolean) is undefined for the type LoanDeterminizer."
Oops, we forgot that one. So let's add it to LoanDeterminizer:
public void setOkToGiveLoan(boolean value) { _okToGiveLoan = value; }
Now running the test results in yet another red bar! It turns out I forgot something pretty big (and basic) in
LoanDeterminizer.giveLoan(): I didn't tell it to execute the rules. Therefore, the default
case of "true" was the result since the rules were not executed.
Asking it to execute the rules is as
easy as this one-liner, which passes it some working data:
_statelessRuleSession.executeRules(objectList);
For reference, the entire working giveLoan method is below:
public boolean giveLoan(HomeBuyer h, int costOfHome) throws Exception {
_okToGiveLoan = true;
_homeBuyer = h;
_costOfHome = costOfHome;
ArrayList<Object> objectList = new ArrayList<Object>();
objectList.add(h);
objectList.add(costOfHome);
objectList.add(this);
_statelessRuleSession.executeRules(objectList);
// here you might have some code to process
// the loan if _okToGiveLoan is true
return _okToGiveLoan;
}
Now our test bar is green and we can add more tests and rules. Thankfully, we're done with programming
in Java (except for our unit tests, which I don't mind all that much).
To wrap-up the tutorial I want to focus on two more cases: Good credit score always gets the loan and
medium credit score with small down payment does not get the loan. I wrote the tests and rules
iteratively, but I'm going to combine them here for organization's sake seeing as I already demonstrated
the iterative approach.
public void test_good_credit_rating_gets_the_loan() throws Exception {
LoanDeterminizer ld = new LoanDeterminizer();
HomeBuyer h = new HomeBuyer("Warren Buffet", 800, 0);
boolean result = ld.giveLoan(h, 100000000);
assertTrue(result);
// maybe some more asserts if you performed processing in LoanDeterminizer.giveLoan()
ld.cleanUp();
}
public void test_mid_credit_rating_gets_no_loan_with_small_downpayment() throws Exception {
LoanDeterminizer ld = new LoanDeterminizer();
HomeBuyer h = new HomeBuyer("Joe Middleclass", 500, 5000);
boolean result = ld.giveLoan(h, 150000);
assertFalse(result);
ld.cleanUp();
}
And the associated rules added to LoanRules.drl:
rule "High credit score always gets a loan"
salience 1
when
buyer : HomeBuyer(creditScore >= 700)
loan_determinizer : LoanDeterminizer(homeBuyer == buyer)
then
System.out.println(buyer.getName() + " has a credit rating to get the loan no matter the down payment.");
loan_determinizer.setOkToGiveLoan(true);
end
rule "Middle credit score fails to get a loan with small down payment"
salience 0
when
buyer : HomeBuyer(creditScore >= 400 && creditScore < 700)
loan_determinizer : LoanDeterminizer(homeBuyer == buyer && percentDown < 0.20)
then
System.out.println(buyer.getName() + " has a credit rating to get the loan but not enough down payment.");
loan_determinizer.setOkToGiveLoan(false);
end
As you can see, there is a little bit of magic going on behind the scenes (as you'll also find in Groovy) where
here in the DSL, you can call loan_determinizer.percentDown and it will call getPercentDown
for you.
All three of our tests are running green and the console outputs what we expected:
Ima Inalotadebt and Idun Payet has too low a credit rating to get the loan.
Warren Buffet has a credit rating to get the loan no matter the down payment.
Joe Middleclass has a credit rating to get the loan but not enough down payment.
As always, questions, comments, and criticism are welcome. Leave your thoughts below. (I know it was
the length of a book, so I don't expect many.)
For more on using Drools, see the Drools 4 docs.
Finally, as with my write-ups on
Scott Davis's Groovy presentation,
his keynote,
Stuart Halloway's JavaScript for Ajax Programmers,
and Neal Ford's 10 ways to improve your code,
I have to give Venkat most of the credit for the good stuff here.
I'm just reporting from my notes, his slides,
and my memory, so any mistakes you find are probably mine. If they aren't, they likely should have been.
Last modified on Sep 10, 2007 at 05:46 PM UTC - 5 hrs
Posted by Sam on Jul 27, 2007 at 03:43 PM UTC - 5 hrs
We could all stand to be better at what we do - especially those of us who write software. Although
many of these ideas were not news to me, and may not be for you either, you'd be surprised at how
you start to slack off and what a memory refresh will do for you.
Here are (briefly)
10 ways to improve your code from the
NFJS
session I attended with Neal Ford.
Which do you follow?
More...
-
Know the fundamentals
It was no surprise that Neal led off with the DRY
principle. Being one from the school of thought that "code reuse" meant "copy-and-pastable with few changes," I
feel this is the most important principle to follow when coding.
Neal uses it in the original sense:
Refuse to repeat yourself not just in your code, but all throughout the system.
To quote (If I remember correctly, The Pragmatic Programmer): "Every piece of knowledge must have a single, unambiguous, authoritative representation within a system."
I can't think of anything that wouldn't be improved by following that advice.
Continuous integration and version control are important fundamentals as well. Continuous integration means you
know the code base at least compiles, and you can have it run your unit tests as well. The codebase is verified as always working
(at least to the specs as you wrote them - you might have gotten them wrong, of course).
Using version control means you don't have to be afraid of deleting that commented out code that you'll probably never use again but
you keep around anyway "just in case." That keeps your code clean.
Finally, Neal suggests we should use static analysis tools such as FindBugs
and PMD that inspect our code, look for bad patterns, and suggest fixes and
places to trim. Those two are for Java. Do you know of similar applications for other platforms? (Leave a comment please!)
-
Analyze code odors and remove them if they stink
Inheritance is a smell. It doesn't always have to smell bad, but at least you should take the time
to determine if what you really need is composition.
Likewise, the existence of helper or utility classes often indicates a "poor design." As
Neal notes, "if you've gotten the abstraction correct, why do you need 'helpers'?" Try to put
them in "intelligent domain object[s]" instead.
Static methods are an indication you are thinking procedurally, and they are "virtually impossible to test."
Seeing the procedural mindset is easy, I think, but why are they hard to test?
Finally, avoid singletons. I know Singleton is everyone's favorite design
pattern because it's so easy to conceptualize, but as Neal mentions:
- They're really just a poor excuse for global variables.
- They violate SRP (link is to a PDF file)
by mixing business logic with policing you from using too many
- They make themselves hard to test
- It's very hard to build a real singleton, as you have to ensure you are using a unified class loader.
- More that I won't get into here...
-
Kill Sacred Cows
Neal started off saying that "sacred cows make the tastiest hamburger" and told the story of the angry monkeys:
A few monkeys were put in a room with a stepladder and a banana that could only be reached if the
monkeys used the stepladder. However, when a monkey would climb upon the stepladder, all the
monkeys would be doused with water. Then new monkeys were introduced and when they
tried to use the stepladder, the other monkeys would get angry and beat him up. Eventually,
the room contained none who had been doused with water, but the monkeys who had been beat up for
using the stepladder were still refusing to allow new monkeys to get the banana.
That is the light in which you may often view sacred cows in software development. In particular,
Neal points out that
- StickingToCamelCaseForSentenceLongTestNamesIsRidiculous so_it_is_ok_to_use_underscores
in languages_that_standardized_on_camel_case for your test names.
-
Using getters and setters does not equate to encapsulation. One of my favorite sayings,
and a reference to why
they are evil is appropriate.
-
Avoidance of multiple returns in a method is antiquated because it comes from a time
when we weren't using tiny, cohesive methods. I still like to avoid them, but will
use them when it makes the code more readable.
-
Polluting interface names with "I", as in ISomeInterface should be avoided.
It is contrary to what interfaces are about. Instead, you should decorate the concrete
class name.
-
Your objects should be Good Citizens. Never let them exist in an invalid state.
-
Use Test Driven Development
TDD provides "explicit dependency management" because you must think about dependencies
as you code. It provides instant feedback and encourages you to implement the simplest
thing that works.
You can take it further by analyzing your dependencies with JDepend.
And don't forget about YAGNI. Quoting
Neal,
Speculative development saves time if
• You have nothing better to work on right now
• You guarantee that it won't take longer to fix later
Is that ever going to be true?
-
Use reflection when you can (and when it makes sense)
It's not slow, and it can be extremely useful!
-
Colour Your World
Nick Drew, a ThoughtWorker in the UK came up with a system of coloring the code you write
by classifying it as to who will use the feature: only a specific business customer,
only a particular market, many markets, or unchangeable infrastructure. Based on
the color and amount of it, you can decide what value or cost your code has.
It's a very interesting system, so I recommend seeing a more detailed overview in
Neal's handout (PDF).
You can find it on pages 21-22.
-
Use a DSL style of coding
It lets you "[Build] better abstraction layers, using language instead of trees" while
"utilizing" current building blocks. As he pointed out, "every complicated human endeavor
has its own DSL. [If you can] make the code closer to the DSL of the business [then] it is
better abstracted."
I'll add that it's easier to spot logical errors as well.
A funny quote from Neal: "It's almost as if in Java we're talking to a severely retarded person."
Regarding that, he recommended looking at EasyMock as a good
example of fluent interfaces, and that having setters return void in a waste.
Instead, we should return this so that calls can be chained together (and if
you are using fluent-interface type names, you could construct sentences in your DSL that way).
Neal also noted a distinction between an API and DSL: API has an explicit context that must
be repeated with each call. However, a DSL uses an implicit context.
-
SLAP tells us to keep
all lines of code in a method at the same level of abstraction.
Steve McConnell's Code Complete 2
tells us about this as well, but I don't recall if it had the clever acronym.
-
And finally, Think about Antiobjects.
Quoting Neal, "Antiobjects are the inverse of what we perceive to be the computational objects."
So instead of solving the really hard "foreground" problem, have a look at the "background"
problem (the inverse) to see if it is easier to solve.
As an example, he used PacMan:
Rather than constructing a solution for the "shortest route around the maze," the game has
a "notion of a PacMan 'scent'" for each tile." That way, the ghosts follow the strongest scent.
As with my write-ups on
Scott Davis's Groovy: Greasing the Wheels of Java,
and Stuart Halloway's JavaScript for Ajax Programmers,
Neal gets all the credit for the good stuff here. I'm just reporting from my notes, his mindmap,
and my memory, so any mistakes you find are probably mine. If they aren't, they probably should
have been.
So which strategies have you used? Will you start using any of the above?
Posted by Sam on Jun 19, 2007 at 11:12 AM UTC - 5 hrs
If you aren't one of the lucky few who get to attend the Google Test Automation Conference, there's still good news for us: They'll be posting the presentations to YouTube Google Channel.
Last modified on Jun 19, 2007 at 11:13 AM UTC - 5 hrs
Posted by Sam on Jun 18, 2007 at 07:03 PM UTC - 5 hrs
Last Saturday, I had the fortune of attending the JUnit Workshop put on by Agile Houston. It was great getting to meet and work with some of the developers in the Houston Area. We started a couple of hours late because of a mixup at the hotel, but it was a good chance to chat with the other developers.
I signed up for a story to implement forums for JUnit.org, which would be used to post hard to test code and receive tests for them. The twist was that we wanted to compile the code and run the unit tests that others posted in response against the code, providing pass/fail and code coverage statistics (that sounds a lot harder than it really is). The other set of stories I signed up for was related to articles, news, (something else related to those that I can't recall), and RSS feeds for each of them.
More...
There were other stories too, but I don't know how they all fared, so I'll just report on the ones I was involved in. I was on a team that started with four developers (and ended with 4, with one person leaving and another coming in), and we decided to start with the articles, news, RSS, etc, as that seemed simple.
We started talking about perhaps implementing something in Python (or perhaps Jython, either with Django), Ruby/ JRuby on Rails, or Groovy and Grails. Even though it was for JUnit, many of us weren't too keen on using the weekend to code in Java like we would during the week (plus, how would we ever get anything done?).
Then someone mentioned something about using Zope (which I had never heard of) and Python. At that point, I installed Python and Zope - and so began a long day of installing programs on my laptop.
The problem was compounded by the fact that a few months back my memory went bad in the laptop and I had to reinstall everything (I originally thought the problem was with Windows, and attempts to repair the installation didn't work). Well, I waited until last week to install anything, so I only showed up prepared for Java and Ruby development.
In any case, it was decided somewhere that a PHP solution would be preferable, since there is a lot of good open source content management systems to choose from, as well as just about any other application we might need (such as the forums). Somewhere around this time we realized the articles could be implemented by the team doing the CMS, and we could move on to
the forums. Ideally, we'd want to use a pre-made solution and modify it to our needs, but in the beginning we just wanted a proof of concept. The four of us all started getting development environment set up - just testing that our Java compiled and unit tests could work. I got to use annotations and JUnit 4 for the first time right here, so that was mildly exciting. =)
But, because there were only two of us who had development environments ready to go, and I was one of them, I got stuck working on the front end. That's not too terribly exciting, but it was fine since I was getting to work with others, and someone had to do it (it isn't like I disliked it, but I would have preferred to work on the back end).
Before we dipped all the way into installing a PHP forum and modifying it, we thought it would be a good idea to implement a simple forum in a JSP to post code to the back end, which would compile it and run tests against it.
That turned out to be a bad move. I had to install Apache, Apache Tomcat, Eclipse Web Platform Tools, and a seemingly endless list of dependencies. To make everything better, the WPT package (or one of the dependencies) was missing a file, and I could only find questions about it searching the internet - no answers. Luckily, I made my problems known and finally one of the other developers found the file on his machine and we transferred it over. Now, four hours into the day, I had a form with a textarea in it. See why web development with Java rocks? =) (Just kidding of course - it's not that bad.)
After that I moved on to try to modify the phpBB for our needs. I installed PHP, MySQL, and phpBB with phpBB telling me the version of MySQL was incompatible with my installation of PHP. But it wasn't! Then I installed PostgreSQL and tried it - to no avail. Finally, it was time for me to leave, and having accomplished nothing, I felt pretty useless.
I haven't heard an update on what the rest of the team accomplished yet, but when I turned on my computer today and tried to install phpBB - it just worked - no questions asked. So what happened? It didn't tell me I'd need to restart the computer, but that's the only thing that changed. In my frustration, I didn't think to do it "just in case." How funny!
Anyway, if you've stayed with me through what must be a boring story for most people, I may as well give you a bit of juicy news: Uncle Bob is supposed to be visiting us at Agile Houston in a short while. I don't know if anything is official yet, but it sure will/would be cool!
Posted by Sam on Jun 14, 2007 at 08:13 PM UTC - 5 hrs
Just a friendly reminder that Agile Houston is hosting a JUnit website improvement workshop on Saturday, June 16, 2007. The workshop starts at 9 AM and continues all day.
It's at the Courtyard Marriott. We'll be TDDing improvements to the JUnit.org website and I should be there from about 9 AM to 3 PM. See you there!
Posted by Sam on Jun 14, 2007 at 08:07 PM UTC - 5 hrs
I recently found the Google Testing Blog and they have a series called "Testing on the Toilet," which are quick one-page write-ups on automated testing issues.
The latest issue of TotT covers Extracting Methods to Simplify Testing.
One of the interesting things for me is that they mention
The first hint that this method could use refactoring is the abundance of comments. Extracting sections of code into well-named methods reduces the original method's complexity. When complexity is reduced, comments often become unnecessary.
This isn't the first place this has come up, and it's not new either (to those in the know). In fact, not too long ago, I pondered something similar when I asked if you can name a block of code, is that a valid indicator that it should be a method?
Anyway, I think the Google Testing Blog is a good place to go to learn about testing.
(and oh yeah- Google is holding a test automation conference in New York towards the end of summer. It's free, but you'll have to justify why you should be one of the 150 people accepted to attend.)
Posted by Sam on Jun 11, 2007 at 09:52 AM UTC - 5 hrs
Want to get a report of a certain session? I'll be attending No Fluff Just Stuff in Austin, Texas at the end of June. So, look at all that's available, and let me know what you'd like to see.
I haven't yet decided my schedule, and it's going to be tough to do so. I'm sure to attend some Groovy and JRuby sessions, but I don't know which ones. In any case, I want to try to leave at least a couple of sessions open for requests, so feel free to let me know in the comments what you'd like to see. (No guarantees though!). Here's what I'm toying with so far (apologies in advance for not linking to the talks or the speakers' blogs, there are far too many of them =)):
More...
First set of sessions: No clue. Leaning toward session 1, Groovy: Greasing the Wheels of Java by Scott Davis.
Second set: 7 (Groovy and Java: The Integration Story by Scott Davis), 8 (Java 6 Features, what's in it for you? by Venkat Subramaniam), 9 (Power Regular Expressions in Java by Neal Ford), or 11 (Agile Release Estimating, Planning and Tracking by Pete Behrens). But, no idea really.
Third set: 13 (Real World Grails by Scott Davis), 15 (10 Ways to Improve Your Code by Neal Ford), or 17 (Agile Pattern: The Product Increment by Pete Behrens). I'm also considering doing the JavaScript Exposed: There's a Real Programming Language in There! talks in the 2nd and 3rd sets by Glenn
Vanderburg.
Fourth set: Almost certainly I'll be attending session 20, Drooling with Groovy and Rules by Venkat Subramaniam, which will focus on declarative rules-based programming in Groovy, although Debugging and Testing the Web Tier by Neal Ford (session 22) and Java Performance Myths by Brian Goetz (session 24) are also of interest to me.
Fifth set: Again, almost certainly I'll go to Session 27, Building DSLs in Static and Dynamic Languages by Neal Ford.
Sixth set: No clue - I'm interested in all of them.
Seventh set: Session 37, Advanced View Techniques With Grails by Jeff Brown and Session 39, Advanced Hibernate by Scott Leberknight, and Session 42, Mocking Web Services by Scott Davis all stick out at me.
Eighth set: Session 47, Pragmatic Extreme Programming by Neal Ford, Session 46, What's New in Java 6 by Jason Hunter, Session 45, RAD JSF with Seam, Facelets, and Ajax4jsf, Part One by David Geary, or Session 44, Enterprise Applications with Spring: Part 1 by Ramnivas Laddad all seem nice.
Ninth set: Session 50, Enterprise Applications with Spring: Part 2 by Ramnivas Laddad or Session 51, RAD JSF with Seam, Facelets, and Ajax4jsf, Part Two by David Geary are appealing, which probably means the eight set will be the part 1 of either of these talks.
Tenth set: Session 59, Productive Programmer: Acceleration, Focus, and Indirection by Neal Ford is looking to be my choice, though the sessions on Reflection, Spring/Hibernate Integration Patterns, Idioms, and Pitfalls, and NetKernel (which "turns the wisdom" of "XML is like lye. It is very useful, but humans shouldn't touch it," "on its head" all interest me.
Final set: Most probably I'll go to Session #65: Productive Programmer: Automation and Canonicality by Neal Ford.
As you can see, there's tons to choose from - and that's just my narrowed down version. So much so, I wonder how many people will leave the symposium more disappointed about what they missed than satisfied with what they saw =).
Anyway, let me know what you'd like to see. Even if its not something from the list I made, I'll consider it, especially if there seems to be enough interest in it.
Last modified on Jun 11, 2007 at 09:58 AM UTC - 5 hrs
Posted by Sam on Jun 11, 2007 at 07:50 AM UTC - 5 hrs
Don't forget to (learn how to) unit test it using XMLUnit.
Posted by Sam on May 29, 2007 at 07:14 AM UTC - 5 hrs
Often when we make a change to some code, if it is not properly designed, the result is that cascading changes need to be done throughout the application because bugs will ripple through the system. That's one of the ideas behind why we want to have low coupling between classes. We also have unit testing to combat the effects of this, but let's just suppose we haven't written any, and haven't used JUnit Factory to create regression tests.
Given that there is a lot of code out there that isn't quite perfect, wouldn't it be nice to have a tool that could analyze changes and where they would affect other code? I can imagine how such a tool might work, but I haven't heard of one before now (that I recall, anyway).
So the point of it all: I heard something about BMC and IBM teaming up on such a tool (my understanding is that BMC started it, and IBM later joined the project). I'm assuming it'd be in Java, but does anyone have information on this? Can anyone confirm or deny the story I heard?
Last modified on May 29, 2007 at 07:15 AM UTC - 5 hrs
Posted by Sam on May 27, 2007 at 11:15 AM UTC - 5 hrs
Hot off the presses: On Saturday, June 16, 2007 from 9:00 AM (and lasting all day) Agile Houston is hosting a JUnit workshop.
Attendees will be pairing and TDDing improvements to JUnit.org, including: (quoting Agile Houston's announcement)
More...
* A forum that lets developers post hard-to-test code, and "test case" responses that show coverage and test results.
* A JUnit roadmap that shows changes to upcoming versions, like the Hamcrest style API changes in JUnit 4.4
* Updated graphics, layout, and content.
I'm guessing the updated graphics won't be test-driven, but who knows what's possible these days?!
This sounds like a lot of fun so I'm tentatively planning on making it out, and I hope to see you people there! You just need to "bring your laptop" and show up "ready to sling some code." And Ben Rady said you'll want to get there early if you want some place to sit!
Last modified on Jun 03, 2007 at 12:14 PM UTC - 5 hrs
Posted by Sam on Apr 07, 2007 at 04:29 PM UTC - 5 hrs
Have any of you Java guys or gals seen or tried JUnit Factory from Agitar? It generates functional unit tests for each method in a given class. A good description of how this can be used (since it can't detect how you expect the code should work, only how it does work) is provided in the FAQ:
More...
What do these so-called tests actually test? Don't they just check that the code is doing what it's doing?
You are absolutely right. The tests that JUnit Factory generates are best described as characterization tests. These are tests that characterize the actual behavior of the code. They record and test not what the code is supposed to do, but what it actually does. The term characterization tests was introduced by Michael Feathers in his book Working Effectively With Legacy Code – a great book by the way.
How are these characterization tests useful?
Characterization tests are change detectors and are particularly useful when working with legacy code. In Working With Legacy Code (you should really get this book), Michael Feathers defines legacy code as code without tests. When modifying legacy code you are working without a safety net. You make specific changes but you don't know if those changes have some unwanted or unexpected side effects. A good set of characterization tests can serve as a safety net because these tests will show you when you have changed some existing behavior. Of course, only you – the developer - can decide if the change is what you had intended or not. In many cases, the tests will show that your changes have some intended effects and some unintended side-effects.
Can I use the generated tests in some other ways?
Sure. Since the test generator does not know how you meant your code to be used, it tries all sorts of things and uses a wide range of valid and invalid inputs – including things that you did not plan for or anticipate. By reading the generated tests you will often discover behavior that you did not want or expect. Seeing a generated test method called testFooThrowsArrayIndexOfBoundException for example, lets you know that method foo() throws an AIOOBException. Is this exception something that you expected? If the answer is yes, then fine, you now have a test for that. If the answer is no, you can fix your code accordingly.
I tried a simple MathFunctions class in the online demo:
public class MathFunctions {
public int add(int x, int y){
return x+y;
}
public int subtract(int x, int y){
return x-y;
}
public int multiply(int x, int y){
return x*y;
}
public int divide(int x, int y){
return x/y;
}
}
and it responded with the following tests (pardon the lack of formatting - I'm just lazy at the moment):
/**
* Generated by Agitar build: Agitator Version 1.0.4.000276 (Build date: Mar 27, 2007) [1.0.4.000276]
* JDK Version: 1.5.0_09
*
* Generated on Apr 7, 2007 2:19:39 PM
* Time to generate: 00:03.788 seconds
*
*/
import com.agitar.lib.junit.AgitarTestCase;
public class MathFunctionsAgitarTest extends AgitarTestCase {
static Class TARGET_CLASS = MathFunctions.class;
public void testConstructor() throws Throwable {
new MathFunctions();
assertTrue("Test completed without Exception", true);
}
public void testAdd() throws Throwable {
int result = new MathFunctions().add(100, 1000);
assertEquals("result", 1100, result);
}
public void testAdd1() throws Throwable {
int result = new MathFunctions().add(0, 0);
assertEquals("result", 0, result);
}
public void testDivide() throws Throwable {
int result = new MathFunctions().divide(0, 100);
assertEquals("result", 0, result);
}
public void testDivide1() throws Throwable {
int result = new MathFunctions().divide(100, -1);
assertEquals("result", -100, result);
}
public void testMultiply() throws Throwable {
int result = new MathFunctions().multiply(100, 0);
assertEquals("result", 0, result);
}
public void testMultiply1() throws Throwable {
int result = new MathFunctions().multiply(100, 1000);
assertEquals("result", 100000, result);
}
public void testSubtract() throws Throwable {
int result = new MathFunctions().subtract(2, 2);
assertEquals("result", 0, result);
}
public void testSubtract1() throws Throwable {
int result = new MathFunctions().subtract(100, 1000);
assertEquals("result", -900, result);
}
public void testDivideThrowsArithmeticException() throws Throwable {
try {
new MathFunctions().divide(100, 0);
fail("Expected ArithmeticException to be thrown");
} catch (ArithmeticException ex) {
assertEquals("ex.getClass()", ArithmeticException.class, ex.getClass());
assertThrownBy(MathFunctions.class, ex);
}
}
}
It looks pretty promising.
Last modified on Apr 07, 2007 at 04:30 PM UTC - 5 hrs
Posted by Sam on Mar 12, 2007 at 08:43 AM UTC - 5 hrs
Yesterday I was working on a little Java program that, when given a table, a "possible" candidate key (which could be composite), and some non-key columns would check to see if the table was in 1st, 2nd, or 3rd normal form(s). One constraint is that this program needs to be procedural in style (or rather, all of my code must reside in the file that contains the main() function).
I started out with the pseudocode programming process in psvm. My listing started to look like:
More...
// validate the input args[]
// extract the table, "possible" candidate key, and non-keys
// validate that there are no duplicate columns in the "possible" candidate key and the non-keys
// validate the table exists
// validate the columns exist for the "possible" candidate key and the non-keys
...
// and so on
At that point, I decided to go ahead and start coding. Now, I wasn't using TDD, since I have no clue how I might go about doing so other than to first code in different classes, and then migrate everything over to main(). In that case, I figured there may very well be more bugs after migrating, rather than less. So, I just started coding.
Once I got down to having to hit the database table to verify it and the columns existed, I got stuck. I didn't know if I needed to test against an actual DBMS using JDBC or if I needed to check against a .CSV file, for example. I stayed stuck and thinking for a while, until I started thinking in objects (or more generally, and importantly, abstract data types). At that point I realized that whatever I did, I'd have to store it some how, and in doing so, I could "fake it" and implement that part later. All I needed was the interface, essentially.
Now, this is a technique you'll often use in OOP and especially if you're following test driven development, but given the nature of the constraints, I didn't think about it immediately.
The point is that even if you aren't programming with objects or using TDD, you can still think about abstraction, and use it to continue coding even when the detailed implementation-level requirements aren't fully specified. I'm not sure this is something I would have thought about when programming purely procedurally, so hopefully it will help someone out, as it certainly did for me.
Thoughts anybody?
Posted by Sam on Mar 06, 2007 at 12:13 PM UTC - 5 hrs
Our second meeting of the UH Code Dojo was just as fun as the first. This time, we decided to switch languages from Java to Ruby. And although we started quite slowly (we came unprepared and undecided on a problem and a language), we pretty much finished the anagram problem.
Now, I mentioned it was slow at first - because we were trying to decide on a problem. I'm guessing we spent about 30-45 minutes just looking over Ruby Quiz and then moving on to Pragmatic Dave's Code Kata. We learned from our experience though, and resolved to determine before-hand what we would do in the future. In any case, we finally decided on anagrams as our problem, and one of us mentioned something to the effect of "I don't know about you all, but I use Java too much at work." Of course, there's not much you can say to an argument like that - Ruby it was!
Since we found ourselves violating YAGNI at the first meeting, we decided to do a little more discussion of the problem before we started coding. One of the initial paths we explored was looping over each letter and generating every possible combination of letters, from 1 to n (n being the length of the input). We then realized that would need a variable number of nested loops, so we moved on to recursion. After that, we explored trying to use yield in conjunction with recursion, in an isolated environment. I don't recall the reasoning behind it, but whatever it was, we were starting to discover that when we passed that fork on the road a few minutes back, we took the path that led to the cannibals. (As a side note, if you're unfamiliar: yield sits in a function, which takes a closure as an argument, and runs the code in the closure -- I think that's a simple way of putting it, anyway).
After smelling the human-stew awaiting us, we backtracked a little and started looking for another idea. Enter idea number two: I'm not sure how to describe it in words, so I'll just show the code now and try to explain it afterwards:
char_count = Array.new(26).fill(0)
dictionary = ['blah', 'lab', 'timmy', 'in', 'hal', 'rude', 'open']
word = "BlAhrina".downcase
word.each_byte { |x| char_count[x - ?a] += 1 }
dictionary.each do |entry|
char_count2 = char_count.clone
innocent = true
entry.each_byte do |letter|
index = letter - ?a
if char_count2[index] > 0
char_count2[index] -= 1
else
innocent = false
break
end
end
puts entry if innocent
end
That's it: quite simple. First we initialize an array with a cell corresponding to each letter of the alphabet. Each cell holds a number, which represents the number of times that letter is used in out input, called word. These cells are set by using the line word.each_byte {...}.
Then for each entry in the dictionary, we do something similar: loop through each letter. If the total count for each letter goes to 0, we have a match (and in our case, simply print it to the standard output device). It's really a simple, elegant solution, and I think we're all glad we didn't go down the painful path of recursion. It would be fairly trivial to add a file which contained a real dictionary, and loop over that instead of each word in our array, but we didn't have one handy (nor did we happen to notice that Dave had provided one). And it would have been just an extra step on top of that to find all the anagrams in the dictionary.
I know this is just a silly little problem that you're not likely to encounter in real life, but it shows how even the simplest of problems can be tough without some thought, and I found it to be great practice. In particular, one problem we had was with trying to use TDD. Although we spent some time looking for tests we could write, and ways to test, and we even wrote an empty test thinking about what to put in there - none of us seemed to find anything to test. Now that we see the solution, it's fairly easy to figure out how to test it, but trying to drive the design with the test was proving fruitless for us. Dave alluded to this on the Kata page:
Apart from having some fun with words, this kata should make you think somewhat about algorithms. The simplest algorithms to find all the anagram combinations may take inordinate amounts of time to do the job. Working though alternatives should help bring the time down by orders of magnitude. To give you a possible point of comparison, I hacked a solution together in 25 lines of Ruby. It runs on the word list from my web site in 1.5s on a 1GHz PPC. It’s also an interesting exercise in testing: can you write unit tests to verify that your code is working correctly before setting it to work on the full dictionary.
I didn't read that before we had started (in fact, it wasn't until we had finished that anyone noticed it), but as you can tell, this exercise performed as promised. Our solution was under 25 lines, and while we didn't test it on his word list, I think our results would have been comparable (in fact, I wouldn't be surprised if we had the same basic solution he did).
Thoughts anybody?
Last modified on Mar 06, 2007 at 12:15 PM UTC - 5 hrs
Posted by Sam on Feb 27, 2007 at 10:57 AM UTC - 5 hrs
A while back, I posted a short screencast on how to use Selenium to automate testing for your web application. Since familiarizing myself with it, I've intermittently thought about using it as part of my TDD cycle. However, I always felt like it would be to much trouble to be worth it.
However, Dan Bunea thought differently, and has posted a tutorial on his experience using Selenium with TDD to InfoQ. It's aimed at the .NET developer, but may be worth a read if you are into that stuff, as I am.
Posted by Sam on Feb 01, 2007 at 03:02 PM UTC - 5 hrs
On Monday (Jan. 29, 2007) we had our first meeting of the UH Code Dojo,
and it was a lot of fun. Before we started, I was scared that I'd be standing
there programming all by myself, with no input from the other members. But,
my fear was immediately laid to rest. Not only did everyone participate a lot,
one of the members, Matt (I didn't catch his last name), even took over the
typing duties after about 45 minutes. That turned out to be a good thing -
since I still can't type worth a crap on my laptop, and he was much faster than me.
Now, it had only been a couple of months since I last used Java - but it still amazes me
how little time off you need to forget simple things, like "import" for "require." I found
myself having several silly syntax errors for things as small as forgetting the
semicolon at the end of the lines.
Overall, we started with 7 people, and had 5 for most of the meeting. We finished with
four because one person had tons of homework to do. It seemed like those five of us
who stayed were genuinely enjoying ourselves.
In any case, we decided to stick with the original plan of developing a tic-tac-toe game.
You would think that a bunch of computer scientists could develop the whole
game in the two hours we were there. But, you'd have been wrong.
I came away from the meeting learning two main points, which I think illustrate the main
reasons we didn't complete the game:
- YAGNI is your friend
- Writing your tests first, and really checking them is very worthwhile
More...
Both points are things most of us already know, but things you sometimes lose sight
of when working like that all the time, or without paying attention. But, I was
paying attention on Monday, so let me explain how I came to identify those points.
We started by trying to identify a class we could test. This was harder than it looked. We
initially decided on Game. There was a lot of discussion on making it an
abstract class, or an interface, or should we just make it support only tic-tac-toe? After
everyone was convinced that we should first make it concrete, because we would not be
able to test it otherwise, we started trying to figure out what we could test.
So, we wrote a test_hookup() method to check that JUnit was in
place and working.
In the end, we also decided that we would probably want to try to
make it abstract after we tested the functionality, so we could support multiple games.
I think that decision proved to be a bad one - because none of us could figure
out a single peice of functionality that a Game should have.
For me, I think this was due mostly to the fact that I was trying to think of
general functionality, so I only came up
with run(), basically the equivalent of play().
After thinking for a couple of minutes about things we could test, we decided we should
go with something more tangible for us - the Board class. Once we did that,
we never had a problem with what to test next. But, we still ran into problems with
YAGNI. We were arguing about what type of object we should use, so I just said "let's use
Object, then anything will fit and we can be more general when we get
back to Game." This led to trouble later, when we had to have checks for
null all the time. So, we changed it to a string whose value could be "x", "o", or "".
That made life, and the code, a lot simpler.
Those are the two main places where ignoring the YAGNI prinicple hurt us. There are also
a couple of places where not writing our tests first hurt us.
The most obvious one is that we were just looking for a green bar. Because of that, we
actually were running the wrong tests, and some of ours hadn't worked in the first
place. We were running the test from the Game class, not the Board.
It wasn't too hard to fix the ones that were broken though.
Other than that, we spent
a lot of time trying to figure out if an algorithm to determine a winner would work (in
our heads). If we had just written the test first, we could have run it and seen
for sure if the algorithm was going to work correctly.
Overall, the only other thing I would have changed about how we developed would have been to
decide on several tests in advance, so we would have plenty to choose from,
rather than thinking of a test, then immediately implementing it.
For reference, I've posted our code below.
// Board.java
public class Board {
private String[][] _board;
private boolean current_player;
public Board(int row, int col)
{
_board = new String[row][col];
current_player = true;
for (int i = 0 ; i < row ; i++)
{
for (int j = 0 ; j < col ; j++)
{
_board[i][j] = "";
}
}
}
public boolean isEmpty()
{
for (int i=0; i<_board.length; i++)
{
for(int j=0; j<_board[i].length; j++)
{
if (!_board[i][j].equals("")) return false;
}
}
return true;
}
public void setMarkerAtPosition(int row, int col)
{
if (current_player)
_board[row][col] = "x";
else
_board[row][col] = "o";
current_player = !current_player;
}
protected Object getMarkerAtPosition(int row, int col)
{
return _board[row][col];
}
protected boolean isGameOver()
{
return false;
}
public boolean isRowWinner(int row)
{
for (int j = 0 ; j < _board[0].length - 1 ; j++)
{
if (!_board[row][j].equals(_board[row][j + 1]))
{
return false;
}
}
return true;
}
public boolean isColWinner(int col)
{
for (int i = 0 ; i < _board.length -1 ; i++)
{
if (!_board[i][col].equals(_board[i][col]))
{
return false;
}
}
return true;
}
public boolean isDiagWinner()
{
boolean diag_winner1 = true, diag_winner2 = true;
for (int i = 0 ; i < _board.length -1 ; i++)
{
if (!_board[i][i].equals(_board[i+1][i+1]))
{
diag_winner1=false;
}
if (!_board[i][_board[0].length-1-i].equals(
_board[i+1][_board[0].length-1-(i+1)]))
{
diag_winner2=false;
}
}
return diag_winner1||diag_winner2;
}
}
// TestBoard.java
import junit.framework.TestCase;
public class TestBoard extends TestCase {
private Board _b;
public void setUp()
{
_b= new Board(3,3);
}
public void testBoard()
{
assertTrue(_b != null);
assertTrue(_b.isEmpty());
}
public void testSetMarkerAtPosition()
{
_b.setMarkerAtPosition(0, 0);
//assertEquals(_b.getMarkerAtPosition(0,0),"x");
}
public void testIsGameOver()
{
assertFalse(_b.isGameOver());
for (int i = 0 ; i < 3 ; i++)
{
for (int j = 0 ; j < 3 ; j++)
{
_b.setMarkerAtPosition(i,j);
}
}
//assertTrue(_b.isGameOver());
}
public void testIsRowWinner()
{
_b.setMarkerAtPosition(0,0);
_b.setMarkerAtPosition(1,0);
_b.setMarkerAtPosition(0,1);
_b.setMarkerAtPosition(1,1);
_b.setMarkerAtPosition(0,2);
assertTrue(_b.isRowWinner(0));
}
public void testIsColWinner()
{
_b.setMarkerAtPosition(0,0);
_b.setMarkerAtPosition(0,1);
_b.setMarkerAtPosition(1,0);
_b.setMarkerAtPosition(1,1);
_b.setMarkerAtPosition(2,0);
assertTrue(_b.isColWinner(0));
}
public void testIsDiagWinner1()
{
_b.setMarkerAtPosition(0,0);
_b.setMarkerAtPosition(0,1);
_b.setMarkerAtPosition(1,1);
_b.setMarkerAtPosition(0,2);
_b.setMarkerAtPosition(2,2);
assertTrue(_b.isDiagWinner());
}
public void testIsDiagWinner2()
{
_b.setMarkerAtPosition(0,2);
_b.setMarkerAtPosition(0,1);
_b.setMarkerAtPosition(1,1);
_b.setMarkerAtPosition(0,0);
_b.setMarkerAtPosition(2,0);
assertTrue(_b.isDiagWinner());
}
}
As you can see, the board object really didn't do what its name implies. That should have
been game, I think. Also, the three check for winner functions are only temporarily
public - we planned on combining them to check for a winner in just one public function.
Other than that, we also need some negative tests, and obviously to complete the game.
Finally, thanks to everyone who showed up for making
it an enjoyable experience! I can't wait for the next one!
Last modified on Feb 12, 2007 at 10:12 AM UTC - 5 hrs
Posted by Sam on Jan 11, 2007 at 12:58 PM UTC - 5 hrs
I don't want to turn this into a mouthpiece for the code dojo at University of Houston, but I'm pretty excited about it since we've set the date of our first meeting. We're planning on doing it January 29, 2007 at 7:00 PM. Check the website for more details (such as the room). We have yet to decide on the first problem to solve / topic, but we will have that done by the end of next week. After that, I probably won't post much here about it, or I'll try not to anyway (I realize folks in China, for instance, could probably care less about it).
Last modified on Jan 11, 2007 at 01:04 PM UTC - 5 hrs
Posted by Sam on Jan 09, 2007 at 04:44 PM UTC - 5 hrs
For those that don't know, cfrails is supposed to be a very light framework for obtaining MVC architecture with little to no effort (aside from putting custom methods where they belong). It works such that any changes to your database tables are reflected immediately throughout the application.
For instance, if you change the order of the columns, the order of those fields in the form is changed.
If you change the name of a column or it's data type, the labels for those form fields are changed, and
the validations for that column are also changed, along with the format in which it
is displayed (for example, a money field displays with the local currency,
datetime in the local format, and so forth).
I've also been developing a sort-of DSL for it,
so configuration can be performed quite easily programmatically (not just through the database), and you can follow DRY to the extreme. Further, some of this includes (and will include) custom data types (right now, there are only a couple of custom data types based on default data types).
More...
In a nutshell, the goal is to have such highly customizable "scaffolding" that there really is no scaffolding - all the code is synthesized - or generated "on the fly." Of course, this only gets you so far. For the stuff that really makes your application unique, you'll still have to code that. But you can compose views from others and such, so it's not like related tables have to stay unrelated, but I do want to stress that right now there is no relationship stuff implemented in the ORM.
I've skipped a few "mini-versions" from 0.1.3 to 0.2.0 because there were so many changes that I haven't documented one-by-one. That's just sloppiness on my part. Basically, I started by following Ruby on Rails' example, and taking my own experience about what I find myself doing over and over again. That part is done, except that the ORM needs to be able to auto-load and lazy-load relationships at the programmer's whim. In any case, once I got enough functionality to start using it on my project, I've been developing them in parallel. The problem is, I've fallen back on poor practices, so the code isn't as nice as it could be.
In particular, there aren't any new automated tests after the first couple of releases, which isn't as bad as it might otherwise be, since a lot of the core code was tested in them. But on that note, I haven't run the existing tests in a while, so they may be broken.
Further, since I've been thinking in Ruby and coding in Coldfusion, you'll see a mix of camelCase and under_score notations. My original goal was to provide both for all the public methods, and I still plan to do that (because, since I can't rely on case from all databases for the column names -- or so I think -- I use the under_score notation to tell where to put spaces when displaying the column names). But right now, there is a mix. Finally, the DSL needs a lot more thought put behind it - Right now it is a mix-and-match of variables.setting variables and set_something() methods. Right now it is really ugly, but when I take the time to get some updated documentation up and actually package it as a zip, I should have it cleaned up. In fact, I shouldn't have released this yet, but I was just starting to feel I needed to do something, since so much had be done on it and I hadn't put anything out in quite some time. Besides that, I'm quite excited to be using it - it's been a pain to build, but it's already saved me more time than had I not done anything like it.
In the end, I guess what I'm trying to say is: 1) Don't look at it to learn from. There may be
some good points, but there are bad points too, and 2) Don't rely too heavily on the interfaces.
While I don't anticipate changing them (only adding to them, and not forcing you to set
variables.property), this is still less than version 1, so I reserve the right
to change the interfaces until then. =)
Other than that, I would love to hear any feedback if you happen to be using it, or need help because the documentation is out of date, or if you tried to use it but couldn't get it to work. You can contact me here. You can find
cfrails at http://cfrails.riaforge.org/ .
Last modified on Jan 09, 2007 at 04:45 PM UTC - 5 hrs
Posted by Sam on Dec 18, 2006 at 09:24 AM UTC - 5 hrs
The last couple of weeks I've been soliciting teammates and friends of mine to help on starting a code dojo at the University of Houston. Well, we got the go-ahead yesterday from the CougarCS organization, so now we're just trying to plan when we'll have our first meeting. If you go to UH or live around Houston (I don't think we'll be checking IDs or anything), I'd encourage you to come to one of our meetings. You can find more information at CodeDojo.org. Right now, as I said, we don't have a meeting schedule or anything, but you can follow the link to our google group and stay informed that way (of course we will be posting it on the webpage as well).
If you don't live in Houston, but want to start a dojo of your own, we also plan to provide a place for others to post information. We don't have the infrastructure set up yet, but if you contact me, I'll be glad to let you know when we do. Of course, you won't have to have our cheesy logo up there =).
Last modified on Dec 18, 2006 at 09:31 AM UTC - 5 hrs
Posted by Sam on Dec 03, 2006 at 01:38 PM UTC - 5 hrs
A couple of days ago I wrote about wanting to do a nice test runner interface to my unit (and integration) tests in Coldfusion. Well, it seems that just a couple of days before that, Laura Arguello (possibly in collaboration with her partner, Nahuel Foronda) released cfcUnit Runner on RIA Forge.
Up until now, I've been using CFUnit, about which she says "I believe it could also used to run CFUnit tests, but CFUnit will need to implement a service façade that Flex can use."
I'm going to get cfcUnit and download cfcUnit runner and try it out sometime soon. It looks really sweet. Then, if I can automatically run tests marked as slow or choose to skip all those marked as such, Laura (and Nahuel?) will have saved me a bunch of time and provided for all of us exactly the system I was thinking I wanted!
Update:
Robert Blackburn, creator of CFUnit, said in the comments at Laura and Nahuel's blog that he is indeed working on something similar for CFUnit, and would be willing to implement the service façade Laura mentioned. Awesome!
Last modified on Dec 03, 2006 at 01:46 PM UTC - 5 hrs
Posted by Sam on Nov 29, 2006 at 01:30 PM UTC - 5 hrs
As I'm finishing up a Ruby on Rails project today, I've been reflecting on some of the issues we had, and what caused them. One glaring one is our lack of automated tests - in the unit (what Rails calls unit, anyway) test and functional test categories.
The "unit" tests - I'm not too concerned about, overall. These tests run against our models, and since most of them simply inherit from ActiveRecord::Base (ActiveRecord is an ORM for Ruby), with some relationships and validation thrown in (both of which taken care of by ActiveRecord). In the few cases we have some real code to test, we've (for the most part) tested it.
What concerns me are the functional tests (these test our controllers). Of course, Rails generates test code for the scaffolds (if you use them), so we started with a nice, passing, suite of tests. But the speed of development in Rails combined with the lack of a convenient way to run tests and the time it takes to run them has caused us to allow our coverage to degrade, pretty severely. It contributed to very few automated tests being written, compared with what we may have done in a Java project, for example.
Of course, there were some tests written, but not near as many as we'd normally like to have. When a small change takes just a couple of seconds to do and and (say, for instance) 30 seconds to run the test, it becomes too easy to just say, "forget it, I'm moving on to the next item on the list." It definitely takes a lot of discipline to maintain high coverage (I don't have any metrics for this project, but trust me, its nowhere near acceptable).
Well that got me thinking about Coldfusion. I notice myself lacking in tests there as well. I'd traditionally write more in Coldfusion that what we did on this Rails project, but almost certainly I'd write less than in an equivalent Java project. And it's not just less because there is less code in a CF or Rails project than in Java - I'm talking more about the percent of code covered by the tests, rather than the raw number. It's because there is no convenient way to run them, and run them quickly.
For Rails development, I'm using RadRails (an Eclipse plugin), so at least I can run the tests within the IDE. But, there is no easy way to run all the tests. I take that back, there is, but for some reason, it always hangs on me at 66%, and refuses to show me any results. I can also use rake (a Ruby make, in a nutshell) to run all the tests via the console, but it becomes very difficult to see which tests are failing and what the message was with any more than a few tests. Couple this with the execution time, and I've left testing for programming the application.
In Coldfusion, it takes quite a while to run the tests period. This is due partly to the limitations of performance in creating CFCs, but also to the fact I'm testing a lot of queries. But at least I can run them pretty conveniently, although it could be a lot better. Now, I've got some ideas to let you run one set of tests, or even one test at a time, and to separate slow tests from fast ones, and choose which ones you want to run. So, look out in the future for this test runner when I'm done with it (it's not going to be super-sweet, but I expect it could save some much-needed time). And then the next thing to go on my mile-long to-do list will be writing a desktop CF server and integrate the unit testing with CFEclipse... (yeah, right - that's going on the bottom of the list).
Last modified on Nov 29, 2006 at 01:35 PM UTC - 5 hrs
Posted by Sam on Nov 14, 2006 at 12:22 PM UTC - 5 hrs
Selenium is an incredibly easy tool you can use to set up automated tests for your web applications. However, if you're like me, you might wince at the thought of having to learn yet another technology - and put it off for the time being due to the "curve" associated with learning it.
To combat that feeling, I created a screencast - starting from download and going through creating an automated test suite. In about 6 minutes, you can have some automated tests for your application to run in just about any browser. The time it saves in manually re-testing is well worth the minor investment you make in getting automated tests. So, check it out.
More...
To get started you can download this this zipped AVI (about 20 MB).
Selenium Core and Selenium IDE can be found at openqa.org.
Last modified on Nov 14, 2006 at 12:27 PM UTC - 5 hrs
Posted by Sam on Nov 09, 2006 at 11:31 AM UTC - 5 hrs
Recently on the Test Driven Development Yahoo Group, James Carr initiated a discussion on TDD Anti-Patterns for a paper he's writing to submit for consideration to be published in IEEE's Software Magazine TDD Special Issue.
It's certainly been an interesting discussion, and he catalogued several of the anti-patterns on his blog.
I think it's a good idea to have names for these smells, since I've noticed a couple of them in my own tests - and it helps remind me to fix them. In particular, I didn't like a few tests in cfrails, which seemed only to test that "such and such works," without asserting anything really. This falls under The Secret Catcher:
A test that at first glance appears to be doing no testing due to the absence of assertions, but as they say, “the devil’s in the details.” The test is really relying on an exception to be thrown when a mishap occurs, and is expecting the testing framework to capture the exception and report it to the user as a failure.
I don't recall if I fixed them yet or not, but you can be sure I'll be paying more attention to my tests now!
Posted by Sam on Oct 18, 2006 at 11:12 AM UTC - 5 hrs
Well, I guess I lied when I said xorBlog wouldn't be developed until I had caught up on my writing. I still haven't gotten caught up, but this morning I couldn't stand it any more - I had to have a way to categorize posts. Now, I didn't TDD these, and I didn't even put them in the right place. True to the name of the blog, I interspersed code where it was needed. I feel absolutely dirty, but I just couldn't spare the time at the moment to do it right, and I could no longer endure not having any categories. So, I took about 15 minutes, coded up a rudimentary category system, violated DRY in 2 places, and put a few comments like "this needs to be refactored into a CFC" throughout the code (as it needed).
At least I have some categories now (its not as gratifying a feeling as I thought it would be, however). I plan on refactoring this as soon as I have a chance. I'll write about it as well - it might make for some more interesting reading in the TDDing xorBlog series of posts.
Last modified on Oct 18, 2006 at 11:14 AM UTC - 5 hrs
Posted by Sam on Sep 26, 2006 at 07:40 AM UTC - 5 hrs
Given a class LeapYear with method isleap? and a data file consisting of year, isleap(true/false) pairs, we want to generate individual tests for each line of data. Using Ruby, this is quite simple to do. One way is to read the file, and build a string of the code, then write that to a file and then load it. That would certainly work, but using define_method is a bit more interesting. Here is the code my partner Clay Smith and I came up with:
require 'test/unit'
require 'leapyear'
class LeapYearTest < Test::Unit::TestCase
def setup
@ly = LeapYear.new
end
def LeapYearTest.generate_tests
filename = "testdata.dat"
file = File.new(filename, "r") #reading the file
file.each_line do |line| #iterate over each line of the file
year, is_leap = line.split; #since a space separates the year from if it is a leap year or not, we split the line along a space
code = lambda { assert_equal(is_leap.downcase=="true", @ly.isleap?(year.to_i)) } #create some code
define_method("test_isleap_" + year, code) #define the method, and pass in the code
end
file.close
end
end
LeapYearTest.generate_tests
One thing to note, that I initially had trouble with, was the to_i. At first, it never occurred to me that I should be using it, since with Coldfusion a string which is a number can have operations performed on it as if it were a number. In Ruby, I needed the to_i, as isleap? was always returning false with the String version of year.
A more interesting item to note is that in the line where we define the method, if you were to attach a block like this:
define_method("test_isleap_"+year) { assert_equal(is_leap.downcase=="true", @ly.isleap?(year.to_i)) }
Then the solution will not work. It creates the correct methods, but when it evaluates them, it appears as though it will use the last value of year, rather than the value at the time of creation.
Last modified on Sep 26, 2006 at 07:42 AM UTC - 5 hrs
Posted by Sam on Sep 08, 2006 at 08:16 AM UTC - 5 hrs
Since school has been back in, I've been much busier than (seemingly) ever. I haven't had the opportunity to do some of the things I've wanted (such as writing more in TDDing xorBlog), but I wanted to share my Wizard, which you can teach to learn spells. I should also note that this is the product of work with my partner, Clayton Smith.
We were given the assignment as a few unit tests:
require 'wizard'
require 'test/unit'
class WizardTest < Test::Unit::TestCase
def setup
@wiz = Wizard.new
end
def test_teach_one_spell
got_here = false
@wiz.learn('telepathy') { puts "I see what you're thinking"; got_here = true}
@wiz.telepathy
assert(got_here)
end
def test_teach_another_spell
got_here = false
spell_code = lambda { puts "no more clouds"; got_here = true}
@wiz.learn('stop_rain', &spell_code)
@wiz.stop_rain
assert(got_here)
end
def test_teach_a_couple_of_spells
got_here1 = false
got_here2 = false
@wiz.learn('get_what_you_want') { |want| puts want; got_here1 = true }
@wiz.learn('sleep') { puts 'zzzzzzzzzzzz'; got_here2 = true}
@wiz.get_what_you_want("I'll get an 'A'")
@wiz.sleep
assert(got_here1 && got_here2)
end
def test_unknown_spell
@wiz.learn('rain') { puts '...thundering...' }
assert_raise(RuntimeError, "Unknown Spell") {@wiz.raln }
end
end
We simply had to make the tests pass:
class Wizard
def initialize()
@spells=Hash.new
end
def learn(spell, &code)
@spells[spell]=code
end
def method_missing(method_id, *args)
begin
@spells["#{method_id}"].call(args)
rescue
raise("Unknown Spell")
end
end
end
Basically, all that happens is that when you create a Wizard, the initialize() method is called, and it creates a Hash to store spells in. Then you have a method, learn(), which takes as a parameter a block of code and stores that code in the Hash. Then when someone calls a method that doesn't exist for an object, Ruby automatically calls the method_missing() method. In this method, all I do is try to call the code stored in the hash under the name of the method they tried to call. If that doesn't work, I raise an exception with the message "Unknown Spell." Quite simple to do something so complex. I can't even imagine how I'd do something like that in a more "traditional" language (though, I can't say that I've tried either).
Can you imagine how cool it would be to say, have one programmer who wrote this Wizard into a game, and other programmers who just litter places in the game (in SpellBooks, consisting of Spells of course) with code that names the spell and specifies what it does? Without even needing to know anything about each other! Instantly extending what a Wizard can do, without even having to so much as think about changing Wizard - it's a beautiful world, indeed.
Last modified on Sep 26, 2006 at 08:19 AM UTC - 5 hrs
Posted by Sam on Aug 31, 2006 at 10:45 AM UTC - 5 hrs
Oh my! I almost forgot the most important part in 'Beginning Ruby' - how to test your code!
require 'test/unit'
class MyTest < Test::Unit::TestCase
def test_hookup
assert(2==2)
end
end
Running that in SciTE gives the following output:
Loaded suite rubyunittest
Started
.
Finished in 0.0 seconds.
1 tests, 1 assertions, 0 failures, 0 errors
On the other hand, if you change one of those twos in the assert() to a three, it shows this:
Loaded suite rubyunittest
Started
F
Finished in 0.079 seconds.
1) Failure:
test_hookup(MyTest) [rubyunittest.rb:4]:
<false> is not true.
1 tests, 1 assertions, 1 failures, 0 errors
The Ruby plugin for Eclipse gives a nice little GUI, however, where you can see the green bar (assuming
your code passes all the tests). I also have a classmate who is writing a Ruby unit testing framework based on NUnit for his thesis, so it is supposed to be the bollocks. I'll let you all know more when I know more.
Last modified on Aug 31, 2006 at 10:50 AM UTC - 5 hrs
Posted by Sam on Aug 29, 2006 at 09:27 AM UTC - 5 hrs
Now that we can insert posts, it is possible to update, select, delete, and search for them. To me, any
one of these would be a valid place to go next. However, since I want to keep the database as unchanged
as possible, I'll start with test_deletePost(). This way, as posts are inserted for
testing, we can easily delete them.
Here is the code I wrote in xorblog/cfcs/tests/test_PostEntity:
<cffunction name="test_deletePost" access="public" returnType="void" output="false">
<cfset var local = structNew()>
<cfset local.newID=_thePostEntity.insertPost(name="blah", meat="blah", originalDate="1/1/1900", author="yoda")>
<cfset local.wasDeleted = _thePostEntity.deletePost(local.newID)>
<cfset assertTrue(condition=local.wasDeleted, message="The post was not deleted.")>
<cfquery name="local.post" datasource="#_datasource#">
select id from post where id = <cfqueryparam cfsqltype="cf_sql_integer" value="#local.newID#">
</cfquery>
<cfset assertEquals(actual = local.post.recordcount, expected = 0)>
</cffunction>
And the corresponding code for deletePost():
<cffunction name="deletePost" output="false" returntype="boolean" access="public">
<cfargument name="id" required="true" type="numeric">
<cfset var local = structNew()>
<cfset local.result = false>
<cftry>
<cfquery name="local.del" datasource="#_datasource#">
delete from post where id = <cfqueryparam cfsqltype="cf_sql_integer" value="#id#">
</cfquery>
<cfset local.result=true>
<cfcatch>
</cfcatch>
</cftry>
<cfreturn local.result>
</cffunction>
Originally, I just left the test as asserting that local.wasDeleted was true. However, writing just
enough of deletePost() in xorblog/cfcs/tests/PostEntity to get the test to pass resulted in the
simple line <cfreturn true>. Since that would always pass, I also added a check that
the inserted post no longer existed.
Now that we have some duplicate code, its definitely time to do some refactoring. More on that next time.
(To be continued...)
Posted by Sam on Aug 28, 2006 at 11:46 AM UTC - 5 hrs
We left off after writing the test for the insertPost() method. Now, we're going to make
that test pass by writing the code for it. First you'll need to create PostEntity.cfc in the xorblog/cfcs/src
directory, and make sure to surround it in the proper <cfcomponent> tags.
What follows is that code:
<cffunction name="insertPost" output="false" returntype="numeric" access="public">
<cfargument name="name" required="true" type="string">
<cfargument name="meat" required="true" type="string">
<cfargument name="originalDate" required="true" type="date">
<cfargument name="author" required="true" type="string">
<cfset var local = structNew()>
<cftransaction>
<cfquery name="local.ins" datasource="#variables._datasource#">
insert into post
(name, meat, originalDate, lastModifiedDate, author)
values
(<cfqueryparam cfsqltype="cf_sql_varchar" value="#arguments.name#">,
<cfqueryparam cfsqltype="cf_sql_longvarchar" value="#arguments.meat#">,
<cfqueryparam cfsqltype="cf_sql_timestamp" value="#arguments.originalDate#">,
<cfqueryparam cfsqltype="cf_sql_timestamp" value="#arguments.originalDate#">,
<cfqueryparam cfsqltype="cf_sql_varchar" value="#arguments.author#">,
</cfquery>
<cfquery name="local.result" datasource="#_datasource#">
select max(id) as newID from post
where originalDate=<cfqueryparam cfsqltype="cf_sql_timestamp" value="#arguments.originalDate#">
and name=<cfqueryparam cfsqltype="cf_sql_varchar" value="#arguments.name#">
</cfquery>
</cftransaction>
<cfif local.result.recordcount is 0>
<cfthrow message="The new post was not properly inserted.">
</cfif>
<cfreturn local.result.newID>
</cffunction>
There isn't really anything special here, unless you are new to Coldfusion. If that's the case, you'll
want to take note of the <cfqueryparam> tag - using it is considered a "best practice" by
most (if not all) experienced Coldfusion developers.
The other item of note is that if you were to run this code by itself,
it still wouldn't work, since we haven't defined variables._datasource. Many developers
would do this in a function called init() that they call each time they create an object. I've
done it as well.
I suppose if you were rigorously following the
YAGNI principle, you might wait until creating the next
method that would use that variable before defining it. I certainly like YAGNI, but my
OCD is not so bad that I won't occasionally allow
my ESP to tell me that I'm going to use something,
even if I don't yet need it. With that said, I try only do it in the most obvious of cases, such as this one.
Now that we've written the code for insertPost(), its time to run the test again. Doing so,
I see that I have two test that run green (this one, and our test_hookup() from earlier.
We've gone red-green, so now it's time to refactor. Unfortunately, I don't see any places to do that
yet, but I think they'll reveal themselves next time when we write
our second test and second method in PostEntity. (To be continued...)
Last modified on Aug 28, 2006 at 11:52 AM UTC - 5 hrs
Posted by Sam on Aug 25, 2006 at 12:34 PM UTC - 5 hrs
So we decided that blog software centers around posts and that for any other feature
to be useful, we'd need them first. Therefore, we'll start with a model component for our posts,
and we'll call it PostEntity. Before I create that file though, I'm going to go back
into my test_PostEntity.cfc file and write a test or two for some functionality that
PostEntity should provide.
Thinking of things we should be able to do regarding the storage of posts, it's easy to identify
at least insert(), update(), and delete(). However,
since you can't update or delete a post that doesn't exist, I figured I'd start with adding a post.
I came up with the following test:
<cffunction name="test_insertPost" access="public" returntype="void" output="false">
<cfset var local = structNew()>
<cfset local.nameOfPost = "My Test Post" & left(createUUID(),8)>
<cfset local.meatOfPost = "The meat of the post is that this is a test." & left(createUUID(),8)>
<cfset local.dateOfPost = now()>
<cfset local.author = "Sam #createUUID()#">
<cfset local.newID=_thePostEntity.insertPost(name=local.nameOfPost, meat=local.meatOfPost, originalDate=local.dateOfPost, lastModifiedDate=local.dateOfPost, author=local.author)>
<cfquery name="local.post" datasource="#variables._datasource#">
select name, meat, originalDate, author
from post
where id = <cfqueryparam cfsqltype="cf_sql_integer" value="#local.newID#">
</cfquery>
<cfset assertEquals(actual=local.post.name, expected=local.nameOfPost)>
<cfset assertEquals(actual=local.post.meat, expected=local.meatOfPost)>
<cfset assertEquals(actual=local.post.author, expected=local.author)>
<!--- dateCompare isn't working correctly, so we are testing each datepart --->
<cfset assertEquals(actual=month(local.post.originalDate), expected=month(local.dateOfPost))>
<cfset assertEquals(actual=day(local.post.originalDate), expected=day(local.dateOfPost))>
<cfset assertEquals(actual=year(local.post.originalDate), expected=year(local.dateOfPost))>
<cfset assertEquals(actual=hour(local.post.originalDate), expected=hour(local.dateOfPost))>
<cfset assertEquals(actual=minute(local.post.originalDate), expected=minute(local.dateOfPost))>
<cfset assertEquals(actual=second(local.post.originalDate), expected=second(local.dateOfPost))>
<!--- clean up --->
<cfquery datasource="#_datasource#">
delete from post where id = #local.newID#
</cfquery>
</cffunction>
You'll notice I used a UUID as part of the data. There's no real point to it, I suppose. I just wanted to have
different data each time, and thought this would be a good way to achieve that.
You should also be uncomfortable about the comment saying dateCompare isn't working - I am anyway. It doesn't
always fail, but occasionally it does, and for reasons I can't figure out, CFUnit isn't reporting why. For
now, so I can move on, I'm assuming it is a bug in CFUnit. Since I can test each date part that is
important to me individually and be sure the dates are the same if they all match, I don't feel
too bad.
Another thing to note is the use of the var local. By default, any variables created
are available everywhere, so to keep them local to a function, you need to use the var keyword.
I like to just create a struct called local and put all the local variables
in there - it just makes things easier.
Finally, some people might not like the length of that test. Right now, I don't either, but we'll see
what we can do about that later. Others may also object to using more than one assertion per test. I don't
mind it so much in this case since we really are only testing one thing. If you like, you could also
create a struct out of each and write a UDF like
structCompare() and do the assertion that way. I haven't tested this one personally, but
there is one available at cflib.
In either case, I don't see much difference, other than one way I have to write more code than I need.
Now I run the test file we created and find that, as expected, the test still fails. Besides the fact that
we don't even have a PostEntity.cfc, we haven't yet instantiated an object of that type, nor have
we defined _datasource and the like. Let's do that in the setUp() method.
<cffunction name="setUp" access="public" returntype="void" output="false">
<cfset variables._datasource="xorblog">
<cfset variables.pathToXorblog = "domains.xorblog">
<cfset variables._thePostEntity = createObject("component", "#variables.pathToXorblog#cfcs.src.PostEntity").init(datasource=_datasource)>
</cffunction>
Now our tests still fail, because we have no code or database. So create the datasource and
database with columns as needed:
id (int, primary key, autonumber)
name (nvarchar 50)
meat (ntext)
originalDate (datetime)
lastModifiedDate (datetime)
author (nvarchar 50)
Next time, we'll start coding and get our first green test. (To be continued...)
Last modified on Aug 29, 2006 at 08:38 AM UTC - 5 hrs
Posted by Sam on Aug 20, 2006 at 10:38 AM UTC - 5 hrs
Since I wanted to start this blog, I thought it would be good practice to write the software that runs it
using test-driven development. I've used a bit of TDD recently for additions to existing applications, but
I've not yet started writing an application using it from beginning to end. I'm getting sick of
eating Italian microwaveable dinners when I have to maintain code. This is my chance to eat something else.
So, without further ado, we'll jump right in.
The first thing I did of course, was to create my directory structure. For the time being, we have:
xorblog/cfcs/src
and
xorblog/cfcs/tests
I like to keep the tests separate from the source. I don't have a reason behind it, other than it helps
keep me a bit organized.
Next, I thought about what a blog needs. We want to deliver items that have the highest business value first,
and move on to things that are lower on the value scale later. In doing this, we get a working application
sooner rather than later, and hence the blog can be used at the earliest possible moment in its development.
With that in mind, we probably shouldn't start with things like Comments or functionality
that lets us get included in places like Technorati. Since
you need content to make anything else useful, I thought I'd start with that. Indeed, the Post is
the core part of a blog. Therefore, the first thing I did was create test_PostEntity.cfc under
xorblog/cfcs/tests.
Now, I'm using CFUnit for my tests, and this assumes you already have it set up. If you need help on
that, you can visit CFUnit on SourceForge.
The first thing I do in test_PostEntity.cfc is write test_hookup(),
to make sure everything is working:
<cfcomponent extends="net.sourceforge.cfunit.framework.TestCase" output="false" name="test_PostEntity">
<cffunction name="test_hookup" access="public" returntype="void" output="false">
<cfset assertEquals(expected=4, actual=2+2)>
</cffunction>
</cfcomponent>
Next, we need a way to see the status of and run our tests. For this we have test_runner.cfm, which
for the most part just copies what you'll find at the CFUnit site linked above:
<cfset testClasses = ArrayNew(1)>
<cfset ArrayAppend(testClasses, "domains.xorblog.cfcs.tests.test_PostEntity")>
<!--- Add as many test classes as you would like to the array --->
<cfset suite = CreateObject("component", "globalcomponents.net.sourceforge.cfunit.framework.TestSuite").init( testClasses )>
<cfoutput>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>Unit Tests for xorBlog</title>
</head>
<body>
<h1>xorBlog Unit Tests</h1>
<cfscript>
createobject("component", "globalcomponents.net.sourceforge.cfunit.framework.TestRunner").run(suite,'');
</cfscript>
</body>
</html>
</cfoutput>
Finally, we run that page in a browser to make sure the test runs green - and it does.
Now that we have our test environment set up, we can start writing tests for our PostEntity
that doesn't yet exist. (To be continued...)
Last modified on Aug 20, 2006 at 10:49 AM UTC - 5 hrs
|
Me

|
