Posted by Sam on Aug 02, 2013 at 05:41 AM UTC - 5 hrs
For the last 8 weeks or so, I've been out of the habit of getting up from my office chair regularly. I made a comment about it on twitter and @jwo, thought it was important enough to take a break too.
More...
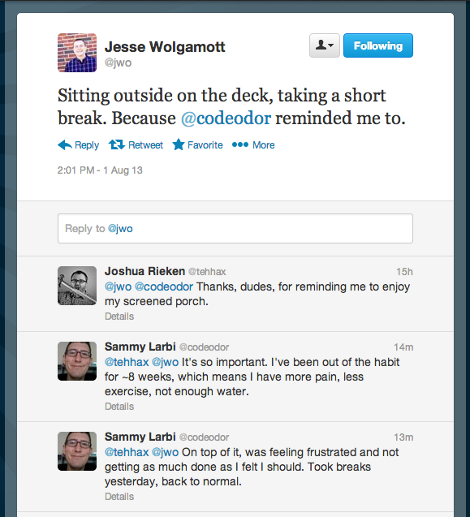 Sitting a lot is bad for your health
Sitting a lot is bad for your health (even if you exercise), and as a programmer, I sit a lot. I haven't ever really felt a problem from it until recently, when I got out of the habit of taking regular breaks. In my case that was leading to back pain, mental frustration, and not getting enough water. So yesterday I started using Dejal Timeout as a way to force myself to get up, stretch, and walk around a bit. (It fades in, dims your screen, and makes it hard to work when it's time for a break).
The results? 5000 more steps for the day (~50% increase), much more water, no back pain this morning, and yesterday I got done WAY more than I have in the past two months. I am not thinking those outstanding results will continue forever (and I realize my story doesn't suffice for proving causality), but I expect I'll remain better off than before. I set it to take a 5 minute break after every 55 minutes.
Final note: You can configure that software to not show the "skip this break" button. I recommend this. If you make it easy to skip, I think you'll end up skipping. I did keep the postpone buttons though, and used them a couple of times.
What tips do you have to help manage and maintain your health?
Hey! Why don't you make your life easier and subscribe to the full post
or short blurb RSS feed? I'm so confident you'll love my smelly pasta plate
wisdom that I'm offering a no-strings-attached, lifetime money back guarantee!
Last modified on Aug 02, 2013 at 05:41 AM UTC - 5 hrs
Posted by Sam on Jun 16, 2008 at 12:00 AM UTC - 5 hrs
Is there a perfect way to teach programming to would-be programmers? Let's ask the Magic 8-Ball.

Outlook not so good.
Does that mean we shouldn't teach them? Of course not. Does it mean we shouldn't look for better methods of teaching them? Emphatically I say again, "of course not!"
And what of the learner? Should beginners seek to increase their level of skill?
Only if they want to become a level 20 Spaghetti Code Slingmancer (can you imagine the mess?). Or, that's how some make it seem.
 Photo from Ken Stein found via Spaghetti cables @ Geek2Live
Photo from Ken Stein found via Spaghetti cables @ Geek2Live
All it means to me is that we shouldn't let our paranoia about the wrong ways of learning stop us from doing so. For instance, take this passage about the pitfalls of reading source code:
Source code is devoid of context. It's simply a miscellaneous block of instructions, often riddled with a fair bit of implicit assumptions about preconditions, postconditions, and where that code will fit in to the grand scheme of the original author's project. Lacking that information, one can't be sure that the code even does what the author wanted it to do! An experienced developer may be able to apply his insight and knowledge to the code and divine some utility from it ("code scavenging" is waxing in popularity and legitimacy, after all), but a beginner can't do that.
Josh also mentions that source code often lacks rationale behind bad code or what might be considered stupid decisions, and that copy and paste is no way to learn.
They're all valid points, but the conclusion is wrong.
Which one of us learned the craft without having read source code as a beginner? Even the author admits that he was taught that way:
Self-learning is what drives the desire to turn to source code as an educational conduit. I have no particular problem with self-learning -- I was entirely self-taught for almost three quarters of what would have been my high school career. But there are well-known dangers to that path, most notably the challenge of selecting appropriate sources of knowledge for a discipline when you are rather ill-informed about that selfsame discipline. The process must be undertaken with care. Pure source code offers no advantages and so many pitfalls that it is simply never a good choice.
This is a common method of teaching - "do as I say, not as I do." It's how we teach beginners anything, because their simple minds cannot grasp all the possible combinations of choices which lead to the actual Right Way to do something. It's a fine way to teach.
But I'd wager that for all X in S = {good programmers}, X started out as a beginner reading source code from other people. And X probably stumbled through the same growing pains we all stumble through, and wrote the same crapcode we all do.
Of course, there are many more bad programmers than good, so lets not make another wrong conclusion - that any method of learning will invariably produce good programmers.
Instead, let's acknowledge that programming is difficult as compared to many other pursuits, and that there's not going to be a perfect way to learn. Let's acknowledge that those who will become good programmers will do so with encouragement and constant learning. Instead of telling them how they should learn, let them learn in the ways that interest them, and let's guide them with the more beneficial ways when they are open to it.
Let's remember that learning is good, encourage it, and direct it when we can. But let people make mistakes.
Learning in the wrong manner will produce good programmers, bad programmers, and mediocre ones.
Independent, orthogonal, and irrelevant are all words that come to mind. The worst it will do is temporarily delay someone from reaching their desired level of skill.
I would be knowledgeable having read programming books with no practical experience. But I wouldn't have any understanding. Making mistakes is fundamental to understanding. Without doing so, we create a bunch of angry monkeys, all of whom "know" that taking the banana is "wrong," but none of whom know why.
What do you think?
Posted by Sam on Jun 30, 2011 at 04:40 PM UTC - 5 hrs
I was introduced to the concept of making estimates in story points instead of hours back in the Software Development Practices course when I was in grad school at UH (taught by professors Venkat and Jaspal Subhlok).
I became a fan of the practice, so when I started writing todoxy to manage my todo list, it was an easy decision to not assign units to the estimates part of the app. I didn't really think about it for a while, but recently
a todoxy user asked me
What units does the "Estimate" field accept?
More...
My response was
The estimate field is purposefully unit-less. That's because the estimate field gets used in determining how much you can get done in a week, so you could think of it in hours, minutes, days, socks, difficulty, rainbows, or whatever -- just as long as in the same list you always think of it in the same terms.
A while back, Jeff Sutherland (one of the inventors of the Scrum development process) pointed out some of the reasons why story points are better than hours. It boiled down to four reasons:
- We are bad at estimating hours, but more consistent with points
- Hours tell us nothing since the best developer on the team may be multiple times faster than the worst
- It takes less time to estimate in points than hours
- "The management metric for project delivery needs to be a unit of production [because] production is the precondition to revenue ... [and] hours are expense and should be reduced or eliminated whenever possible"
But I noticed another benefit in my personal habits. Not only does it free us of the shackles of thinking in time and the poor estimates that come as a result, it corrects itself when you make mistakes.
I recognized this when I saw myself giving higher estimates for work I didn't really want to do. Like a contractor multiplying by a pain-in-the-ass factor for her worst customer, I was consistently going to fib(x+1) in my estimates for a project I wasn't enjoying.
But it doesn't matter. My velocity on that list has a higher number than on my other list, so if anything I hurt myself by committing to more work on it weekly for any items that weren't inflated.
What do you think about estimating projects in leprechauns?
Posted by Sam on Mar 28, 2008 at 12:00 AM UTC - 5 hrs
When I work in Windows, I don't get as much done as when I'm in MacOS X.
It's not because MacOS is inherently better than Windows productivity-wise. It's because
my calendar and time-boxing mechanism resides on MacOS. So when I've got an entire day of
work to do in Windows, I don't have anything telling me "it's time to switch tasks."
Why is that a problem? That's the focus of this week's chapter in MJWTI. (Last week, I took a mini-vacation / early bachelor party to go fishing at Lake Calcasieu in Southwest Louisiana, so I didn't get around to posting then in the Save Your Job series.)
The "Eight-Hour Burn" is another of the chapters in Chad's book that really stuck with me after I first read it.
The premise is that instead of working overtime, you should limit each day's work to an 8 hour period of intense activity. In doing so, you'll get more done than you otherwise would. Our
brains don't function at as high a level as possible when we're tired. And when we're working
on our fifth 60-hour week, we're probably tired.
We may love to brag about how productive we are with our all-nighters [paraphrasing Chad], but the reality is we can't be effective working too many hours over a long period of time.
And it's more than just our brains being tired that should prevent us from working too long. It's the fact that when we know we've got so much extra time to do something, we end up goofing off anyway:
Think about day 4 of the last 70-hour week you worked. No doubt, you were putting in a valiant effort. But, by day 4, you start to get lax with your time. It's 10:30 AM, and I know I'm going to be here for hours after everyone else goes home. I think I'll check out the latest technology news for a while. When you have too much time to work, your work time reduces significantly in value. If you have 70 hours available, each hour is less precious to you than when you have 40 hours available.
That's why I'm in trouble when I work in Windows all day. I do work 12-16 hours most days between job, school, and personal activity (like this blog). I get burnt out every few weeks and have to take a couple of days off, but when I'm in MacOS X, at least my working days are very productive: I've got each task time-boxed and any time I spend reading blogs or news or just getting lost on the web is always scheduled.
When I'm in Windows with nothing to remind me but myself, I drift off quite a bit more easily. After all, it's only 6:30 in the morning. I've still got eight hours to get everything done (I'm leaving early to go check the progress on the house I'm having built).
The good news is that I've got an item on my longer-term to-do list to remedy the situation. Hopefully after reading this chapter again, I'll be more motivated to get it done. The bad
news is, since it means working in Windows all day to get it done, I'll probably be off
doing my best to read all of Wikipedia instead.
Anyway, how much do you work? Do you have any tricks for staying fresh and motivated?
Last modified on Mar 26, 2011 at 01:10 AM UTC - 5 hrs
Posted by Sam on Mar 31, 2008 at 12:00 AM UTC - 5 hrs
An interesting discussion going on over at programming reddit got me thinking about what features I'd like my ideal job to have.
Aside from " an easy, overpaid job that will get bring me fame and fortune," here's what would make up my list:
-
Interesting Work:
You can only write so many CRUD applications before the tedium drives you insane, and you think to yourself, "there's got to be a better way." Even if you don't find a framework to assist you, you'll end up writing your own and copying ideas from the others. And even that only stays interesting until you've relieved yourself of the burden of repetition.
Having interesting work is so important to me that I would contemplate a large reduction in income at the chance to have it (assuming my budget stays in tact or can be reworked to continue having a comfortable-enough lifestyle, and I can still put money away for retirement). Of course,the more interesting the work is, the more of an income reduction I could stand.
Fortunately, interesting work often means harder work, so many times you needn't trade down in salary - or if you do, it may only be temporary.
The opportunity to present at conferences and publish papers amplifies this attribute.
-
Competent Coworkers: One thing I can't stand is incompetence. I don't expect everyone to be an expert, and I don't expect them to know about all the frameworks and languages and tricks of the trade.
I do expect programmers to have basic problem solving skills, and the ability to learn how to fish.
-
Sane Management: Don't make me delighted to have a broken watch. I shouldn't have to turn back the dial on it to meet deadlines. Or put more strongly, management/customers shouldn't be given the latitude to control all three sides of the iron triangle of software development.
Scope, Schedule, and Resources. Choose two. We, the development team, get to control the third.
-
Trust: One comment in the reddit discussion mentioned root access to my workstation and it made me think of trust. If you cannot trust me to administer my own computer, how can you trust me not to subvert the software I'm writing?
Additionally, I need you to trust my opinion. When I recommend some course of action, I need to know that you have a good technical reason for refusing it, or a good business reason. I want an argument as to why I am wrong, or why my advice is ignored. If you've got me consistently using a hammer to drive marshmallows through a bag of corn chips, I'm not likely to stay content.
I don't mind if you verify. In fact, I'd like that very much. It'll help keep me honest and vigilant.
-
Personal Time: I like the idea of Google's 20% time. I have other projects I'd like to work on, and I'd like the chance to do that on the job. One thing I'd like to see though, is that the 20% time is enforced: every Friday you're supposed to work on a project other than your current project. It'd be nice to know I'm not looked down upon by management as selfish because I chose to work on my project instead of theirs.
I wouldn't mind seeing something in writing about having a share of the profits it generates. I don't want to be working on this at home and have to worry about who owns the IP. And part of that should allow me to work on open source projects where the company won't retain any rights on the code I produce.
-
Telecommuting: Some days I'll have errands to run, and I dislike doing them. I really dislike doing them on the weekends or in the evenings after work. I'd like to be able to work from home on these days, do my errands, and work late to make up for it. It saves the drive time on those days to help ensure I can get everything done.
There are some other nice-to-have's that didn't quite make the list above for me. For example, it would be nice to be able to travel on occasion. It would also be nice to have conferences, books, and extended learning in general paid for by the company. I'd like to see a personal budget for buying tools I need, along with quality tools to start with.
But if you can meet some agreeable combination of the six qualities above, I'll gladly provide these things myself. If you won't let me use my own equipment, and you provide me with crap, we may not have a deal.
That's my list. What's on yours?
Posted by Sam on Aug 03, 2010 at 12:46 PM UTC - 5 hrs
Rails Rumble has nothing on this.
Of course, you could just click the edit button in your database management studio of choice and achieve the same functionality.
SELECT DISTINCT 'script/generate scaffold ' + t.name + ' ' + column_names
FROM sys.tables t
CROSS APPLY (
SELECT c.name +
case when max_length > 255 then ':text' else ':string' end + ' '
FROM sys.columns c
WHERE c.object_id = t.object_id
ORDER BY c.column_id
FOR XML PATH('') ) dummy_identifier ( column_names )
A similar discovery was made in the 1930's. One important difference to note is that, since my program does not simulate the input on it's output program, I am able to achieve speeds that are logarithmically faster than what Turing could accomplish.
Posted by Sam on Mar 05, 2010 at 10:14 PM UTC - 5 hrs
You might think that "tech support" is a solved problem. You're probably right. Someone has solved it
and written down The General Procedures For Troubleshooting and How To Give Good Tech Support.
However, surprisingly enough, not everyone has learned these lessons.
And if the manual exists, I can't seem to find it so I can RTFthing.
The titles of the two unheard of holy books I mentioned above might seem at first glance to be
different tales. After all, troubleshooting is a broad topic applicable to any kind of
problem-solving from chemistry to mechanical engineering to computer and biological science.
Tech support is the lowliest of Lowly Worms for top-of-the-food-chain programmers.
More...
 (And don't ask me how sad it makes me feel that my favorite book as a kid has only a 240px image online. I need to find my copy and scan it.)
(And don't ask me how sad it makes me feel that my favorite book as a kid has only a 240px image online. I need to find my copy and scan it.)
But just like its more enlightened brethren, tech support consists of troubleshooting. In fact, it should be
the first line of defense to keep your coders coding and off the phone. Who wants them to man the phones?
Certainly not the programmers. Certainly not management. Tech support is a cost center, not a customer
service opportunity.
That's a lie of course. It's a bajillion times more likely that you'll sell to an existing customer than someone else1.
So why do we see such poor customer service? Especially in our own industry?
Perhaps when you have a virtual monopoly over a market like most cable companies or utilities in a given locale,
you can afford to have poor customer service. The cable sphere seems to be opening up, what with satellite TV and internet
and now AT&T and Verizon offering television and decent-to-good internet packages.
Even still, AT&T's UVerse has its own problems, I've heard,
and (at least personally) I've not witnessed the kind of customer service that competition promises with regards to cable TV and internet access.
Is tech support really that bad? Maybe it's not. There are some folks
that have decent starting advice. Even if it's not How To, at least Some Ways is better than no ways.
The fact is we tend to treat support like a second class citizen. It's a position we want to fill with a minimum-wage worker (or less, if we
can outsource it) who has no expertise, no clue, and doesn't care to learn the
product since he can get a job in the fast food industry at about the same rate. And with no stress!
It makes it worse that we don't even want to take the time to train him, since it would take away from the productive code-writing time to do so.
The person we want to treat as an ape or worse always seems expendable. We treat them so. Should they be?

I say no. Not only am I a big fan of dogfooding,
I feel like Fog Creek's
giving customer service people a career path nowadays
matches a lot of my ANSI artist peers' experiences
from back in the day. Smart people start in support, and they can move themselves up in the organization to play more "key roles."
Bill puts on a headset, sits down, and answers the phone. "Hello, this is Microsoft Product Support, William speaking. How can I help you?"
Bill talks with the customer, collects the details of the problem, searches in the product support Knowledge Base, sifts through the search results, finds the solution, and patiently walks the customer through fixing the problem.
The customer is thrilled that William was able to fix the problem so quickly, and with such a pleasant attitude. Bill wraps up the call. "And thank you for using Microsoft products."
At no point did Bill identify himself as anything other than William. The customer had no idea that the product support engineer who took the call was none other than Bill Gates.
Like Bill.
I don't think it needs to be a full-time thing, but it certainly helps if programmers are their own support team.
Like Bruce Johnson who posted that linked message, I work on a small team and can vouch: it's downright embarrassing to have to support
our customers. I'm glad to do it, but when it happens, more than likely I've got to take blame for the problem I'm dealing with.
You know how hard I try to make sure my code works as expected before I deploy it?
"OMG I'm sorry, that's my fault, I'll fix it for you right away." Can you get better support than that?
I'm not so sure I'd have tried that hard without the customer experience pushing me.
I think I've made my first point: that customer support is customer service is important to the health of your business.
While I agree that tech support in the common use of the term is useful to shield your programmers from
inane requests, I also recognize the value in having programmers take those calls from time-to-time.
Given that, I do in fact have some do's and do-not's with regards to support. The list here deals mostly with
how to be a good support technician for your team, as opposed to the customer. Still, the customer is
central to the theory.
Although it does not make an exhaustive list, here are four contributions to The General Procedures For Troubleshooting:
-
After listening to the problem description, the first thing to do is recognize whether or not you can
solve the problem while the customer is on the phone, or if anyone can. If you can, then do it. If you think
only someone else can do it, and work for an organization that has multiple levels of live-support, then escalate it.
If you don't think solving the problem is possible without escalating it to a level of support that won't get
to it immediately, thank the customer for reporting the issue, let them know the problem is being worked on,
and boogie on to step 2.
- As support, the first thing you need to do before escalating the issue is confirm there is an issue, and do it with a test account, not the user's.
It's ridiculous to ask for the user's
credentials. Don't do it. If someone were to ask you, "What is your username and password?" what would you think?
The average user isn't going to know your query is tantamount stupidity, but if you get someone who is slightly
security-conscious, you're going to lose a customer. Hopefully, he's not a representative of your
whale.
If anyone found out that you're in the habit of asking users for their passwords, they can easily call anyone
who uses your software and get in by just asking. Further, since many people use the same password for everything
or many things, that person would also have access to your customers' other sensitive information, wherever it resides.
You can point the blame at your stupid customer for using the same password everywhere they go all you want. You're being
just as stupid by opening the door for that type of attack. Further, you should always try to recreate and fix the problem
with as little inconvenience to the user as possible. That means doing it with test accounts as opposed to asking the
user for theirs, or changing their information.
Keep things simple for the user. Don't jump immediately to using their time to make things easier on the support team.
Doing that is lazy at best, sloppy most of the time, and could result in disaster at worst.
- After confirming the existence of the problem, provide the steps of how to reproduce it. Give some screen shots.
If it's a web app, provide links. Don't constantly send and email and ask the higher levels about it. Doing so once or twice is
one thing, but doing it for every request is a time-waster. Just send the email and the next level will get to it
when they can. If they don't get to it within the acceptable time-frame for your organization, send a reminder.
Include the boss if you need to. But don't do that prematurely (and that's another subject altogether).
-
Don't jump to conclusions about the source of the problem.
Although Abby Fichtner wasn't speaking
directly to support ...
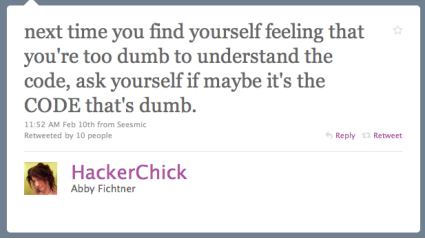
... This is the opposite of my general approach. The parallel here is code : customer :: you : dumb2.
I've learned (even if through a bit of self-torture) that I should always look at the code first, if for no other reason than I don't
want to be foolishly blaming others when I'm to blame. In the case of support, I've always hated the term "User Error,"
and that's what the tweet reminds me of.
By framing it as an external problem, we miss an opportunity to teach the user how to use the product, or a chance to
improve the product to make sure they can't use it "incorrectly."
What are your thoughts about tech support? What can you contribute to The General Procedures For Troubleshooting?
Notes:
1) I know this statistic, it's even intuitive, but I can't seem to find it online for free.
Here's some apparently made-up stats to satisfy you.
Go back to what you were reading.
2) "word1 : word2 :: word3 : word4" is SAT (and elsewhere) notation for
the analogy "word1 is to word2 as word3 is to word4." See freesat1prep.com
for a few examples.
Some links in this post are affiliate links. This message brought to you by the Federal Trade Commission.
Last modified on Mar 24, 2010 at 10:57 AM UTC - 5 hrs
Posted by Sam on Jan 27, 2009 at 12:00 AM UTC - 5 hrs
Being a programmer, when I see something repetitive that I can automate, I normally opt to do so.
We know that one way to save your job is by
automating, but another is to know when not to automate. It sounds obvious, but when you get
into the habit of rooting out all duplication of effort, you can lose sight of the fact that sometimes, it costs more
to automate something than to do it by hand.
More...
I came across such a situation the other day.
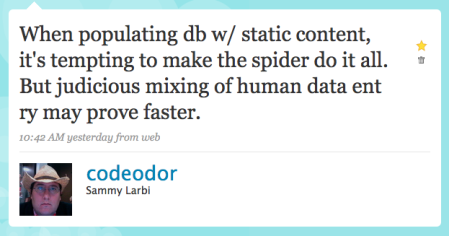 .
In this case I was working with static content on a website that wanted to go dynamic. It wasn't just a case of
writing a spider to follow all the links and dump all the HTML into a database - there was some structure to the
data, and the database would need reflect it.
In this case, there was a hierarchy of data. For simplicity's sake, let's say there were three levels to the tree:
departments, sections, and products. At the top we have very few departments. In the middle, there are several
sections per department. And there are many products in each section.
Each level of the hierarchy is different - so you'll need at least three spider/parser/scrapers. Within each level,
most of the content is fairly uniform, but there are some special cases to consider. We can also assume each
level requires roughly the same amount of effort in writing an automaton to process it's data.
It's natural to start at the top (for me, anyway -- you are free to differ), since you can use that spider to
collect not only the content for each department, but the links to the section pages as well. Then you'll
write the version for the sections which collect the content there and the links to the products. Finally, you get
to the bulk of the data which is contained in the products. (And don't forget the special cases in each level!)
But that's the wrong way to proceed.
You ought to start at the bottom, where you get the most return on your investment first. (Or at least skip the top
level.) Spidering each level to collect links to the lower levels is exceedingly easy. It's the parsing and special
cases in the rest of the content that makes each level a challenge.
Since there are so few cases at the top level, you can input that data by hand quicker than you can write the automation
device. It may not be fun, but it saves a few hours of you (and your customer's) time.


Carry on now, nothing to see here.
Posted by Sam on Mar 24, 2009 at 12:00 AM UTC - 5 hrs
Every day, psychological barriers are erected around us, and depending on what task they are a stumbling block for,
they can be helpful or a hindrance.
Ramit Sethi wrote a guest post on personal finance blog Get Rich Slowly about passive barriers that got me
thinking about passive barriers in software development, or perhaps just any easily destroyed (or erected barrier) that
prevents you from doing something useful (or stupid). One example he uses that comes up a lot in my own work
references email:
More...
I get emails like this all the time:
"Hey Ramit, what do you think of that article I sent last week? Any suggested changes?"
My reaction? "Ugh, what is he talking about? Oh yeah, that article on savings accounts ... I have to dig that up
and reply to him. Where is that? I'll search for it later. Marks email as unread"
Note: You can yell at me for not just taking the 30 seconds to find his email right then, but that's exactly
the point: By not including the article in this followup email, he triggered a passive barrier of me
needing to think about what he was talking about, search for it, and then decide what to reply to.
The lack of the attached article is the passive barrier, and our most common response to barriers is to
do nothing.
(Bold emphasis is mine).
If I can't immediately answer an email, it gets put on hold until I have time to go through and do the research
that I need to do to give a proper reply. Sometimes, that means your email never gets answered because eventually
I look down at the receipt date and say to myself "I guess it'd be stupid to respond now." But I digress.
In everyday software development, there are a number of barriers that can help us:
-
Minimizing or closing the browser. When a compilation is expected to take up to a minute, or a test suite
will run for too long, or a query takes forever, there's not much work that can be done, so I might
fire up the feed reader, email, or twitter to pass the time away. The problem here is that you'll often spend
far longer on your excursion than it takes for your process to complete. If you waste just 5 minutes each time,
you've accomplished nothing - you're just skimming and certainly not getting anything out of it, and you could
have been back working on what you were trying to accomplish. In these situations, I have my email, feed reader,
and twitter minimized, and that significantly reduces the urge to open them up and start a side quest.
If you wanted to get more to the active side of barriers, you might just add the line
to your hosts file. That turns a passive barrier to time waste into a downright pain.
-
Having a test suite with continuous integration and code analysis tools running. At various points in a day you might be tempted to
check in code that breaks the build or introduces a bug. This is especially true at the end of the day.
However, if you have a test suite that runs on every commit, you're much more likely to run it to avoid the embarrassment of checking
in bad code. If you've got static analysis tools that also report on potentially poor code, you're less
likely to write it.
-
Annoyance Driven Development. This isn't one that I know how to turn on or off, but I think it would be
a great feature to have in IDEs or text editors: it gets slow when your methods or classes or files get too big.
This would be a great preventative tool, if it exists. I guess it falls back to using test suites and
code analysis to provide instant feedback that annoys you into doing the right thing.
-
Working with others, or having others review your code. Most of us pay more attention to quality
when we know others will be looking at the code we write. Imagine how much more of your code you'd be
proud to show off if you just knew that someone would be looking at it later.

Just as well, there are also barriers that hinder us:
-
Interruptions. This one is obvious, but so pervasive it should be mentioned. IM,
telephone calls, email, coworkers stopping by to chat or ask questions - they all prevent us from working
from time to time. The easy answer is to close these things, and that's what I do. They all represent
passive barriers to getting work done, and you can easily turn that around to be a passive barrier
against wasting time (see above). Pair programming is an effective technique that erects its own
barrier to these time wasters.
If you're really looking for something to help you focus, I'd have a look at The Pomodoro Technique,
which divides your work into tomato time units of 25 minutes each, which really helps you focus on work. It's
agile for time management. (The Pomodoro Technique PDF book is available for free.)
-
Rotting Design: Rigidity, Fragility, Immobility, and Viscosity. Bob Martin discusses these
in his (PDF) article on Design Principles and Design Patterns. Quoting him for the
descriptions, I'll leave it to you to read for the full story:
Rigidity is the tendency for software to be difficult to change, even in
simple ways. Every change causes a cascade of subsequent changes in dependent
modules. What begins as a simple two day change to one module grows into a multi-
week marathon of change in module after module as the engineers chase the thread of
the change through the application.
...
Closely related to rigidity is fragility. Fragility is the tendency of the
software to break in many places every time it is changed. Often the breakage occurs
in areas that have no conceptual relationship with the area that was changed. Such
errors fill the hearts of managers with foreboding. Every time they authorize a fix,
they fear that the software will break in some unexpected way.
...
Immobility is the inability to reuse software from other projects or
from parts of the same project. It often happens that one engineer will discover that he
needs a module that is similar to one that another engineer wrote. However, it also
often happens that the module in question has too much baggage that it depends upon.
After much work, the engineers discover that the work and risk required to separate
the desirable parts of the software from the undesirable parts are too great to tolerate.
And so the software is simply rewritten instead of reused.
...
Viscosity comes in two forms: viscosity of the design, and viscosity of
the environment. When faced with a change, engineers usually find more than one
way to make the change. Some of the ways preserve the design, others do not (i.e.
they are hacks.) When the design preserving methods are harder to employ than the
hacks, then the viscosity of the design is high. It is easy to do the wrong thing, but
hard to do the right thing.
The point is that poor software design makes an effective barrier to progress. There are only two ways
I know to tear down this wall: avoid the rot, and make a conscious decision to fix it when you
know there's a problem. There are plenty of ways to avoid the rot, but books are devoted to them, so
I'll leave it alone except to say a lot of the agile literature will point you in the right direction.
-
Unit Tests. I struggled with the idea of putting this on here or not. If you're an expert, you already know this.
If you're a novice or lazy, you'll use it as an excuse to avoid unit testing. The point remains: unit testing
can be a barrier to producing software, if you are exploring new spaces and having trouble determining
test cases for it. I'll let the Godfather of TDD, Kent Beck, explain:
... I still didn't have any software. As with any speculative idea, the chances that this
one will actually work out are slim, but without having anything running, the chances are zero. In six
or eight hours of solid programming time, I can still make significant progress. If I'd just written
some stuff and verified it by hand, I would probably have the final answer to whether my idea is
actually worth money by now. Instead, all I have is a complicated test that doesn't
work, a pile of frustration, eight fewer hours in my life, and the motivation to write another essay.
These are just a few examples, so I'm interested in hearing from you.
What barriers have you noticed that positively affect your programming? Negatively?
Posted by Sam on Sep 07, 2009 at 12:00 AM UTC - 5 hrs
Logging Good Ideas Without Interrupting Your Flow Recently I decided I'd start using a wiki to manage knowledge and ideas, adding
research and thoughts as I flushed them out over time. I'd like to see
how the things I think about are interrelated, and I think using a wiki is going
to help me on that front.
One problem I've had with the traditional to-do list, emails, calendars, and wikis
was that when you open the whole thing up, you can pretty easily get distracted
from what you were doing by all of the information that floods your brain: all the emails in your inbox (especially the bold ones), the rest of the to-do list, tomorrow's events, and -- well everyone knows the time-sink a wiki can be.
More...
Fighting it yourself requires a lot of discipline, so so as a backup in combat, I thought I'd figure out how to
automate some simple actions through Quicksilver.
More specifically, this post might be entitled "Automating MediaWiki additions with Ruby and Quicksilver."
I intend to do similar things for the other applications I mentioned above, but this one is specific
to MediaWiki
(For those who are unaware, MediaWiki runs the Wikimedia properties, including Wikipedia).
Automating this stuff turns out to be surprisingly simple. My original idea was to have a section
on the Main_Page of my wiki called "Free Floaters" that would be a simple list of one-line ideas
to be flushed out later. However, I ran into some trouble trying to edit it, so I ended up
just giving it its own page. (Therefore, if you know how it might be accomplished, let me know in a
comment!)
All you need to do is drop the following Ruby script
(edited to your requirements -- I've annotated the lines you'll need to change) in
~/Library/Application Support/Quicksilver/Actions in your MacOS install.
Wiki.rb (placed in ~/Library/Application Support/Quicksilver/Actions -- be sure to chmod -x Wiki.rb)
#!/opt/local/bin/ruby # change to your ruby path - run "which ruby" from command line to find it
require 'net/http'
require 'yaml'
require 'cgi'
def urlify(hash)
result = ""
hash.keys.each do |k|
result += k + "=" + hash[k]
result += "&" if k != hash.keys[-1]
end
return result
end
url = URI.parse('http://example.com/wiki/api.php') # change to your wiki url
params = {
'action' => 'login',
'lgname' => 'your_username', # change to your wiki username
'lgpassword' => 'your_password', # change to your wiki password
'format' => 'yaml'
}
browser = Net::HTTP.new(url.host, url.port)
sign_in = browser.post(url.path, urlify(params))
cookie = sign_in.response['set-cookie']
headers = { 'Cookie' => cookie }
params = {
'action' => 'query',
'prop' => 'info',
'intoken' => 'edit',
'titles' => 'Page_Title_To_Edit', # change to the page you want to edit
'format' => 'yaml'
}
edit_token = browser.post(url.path, urlify(params), headers)
edit_token = YAML::parse(edit_token.body)['query']['pages'][0]['edittoken'].value
params = {
'action' => 'edit',
'title' => 'Page_Title_To_Edit', # change to the page you want to edit
'token' => CGI::escape(edit_token),
'minor' => 'true',
'appendtext' => "%0A*" + ARGV.join(" "), #This adds a new list item, feel free to modify the markup to your liking
'format' => 'yaml'
}
addition = browser.post(url.path, urlify(params), headers)
Then restart Quicksilver. From the command line:
$ killall Quicksilver
$ open /Applications/Quicksilver.app
Now, when you open Quicksilver, type "." to enter text, tab to the action and type "wiki" (or the file name if
you decide to change it), then hit enter to run it. Quicksilver passed what you typed to the script arguments,
and the script sends it up to your wiki.
Any thoughts? What would you change? What else in this vein would you like to see?
Posted by Sam on Sep 15, 2009 at 12:00 AM UTC - 5 hrs
 More...
More...


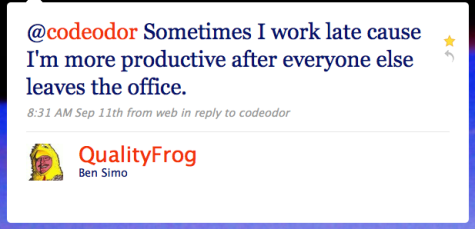
Good point, @QualityFrog. I hadn't thought of it because
I come in early instead, for the same reason.
I'd really like to see a "Send Sometime In The Next 24 Hours" button in Gmail, but failing that, I'll
just create a place for myself to store emails in a database until an hourly scheduled job
sends them via Gmail at getdate() + rand()*23.
Last modified on Oct 20, 2009 at 07:58 AM UTC - 5 hrs
|
Me

|

