Posted by Sam on Mar 03, 2013 at 10:14 AM UTC - 5 hrs
Someone from our last houston.rb meetup asked me about contributing to open source software, so I wrote an email that talks about the little things I do. I thought others might find it helpful, so I'm also posting the email here. It is below:
It occurred to me I totally ignored your question about open source, so apologies for that,
and here I go attempting to rectify it.
Any time I'm using an open source project I haven't used before
(or using a new-to-me feature of it), I am reading the docs about it as I
implement whatever it is I'm using it for. If I find something unclear, or
something unaddressed, I fork the project, improve the docs to mention it,
and send a pull request.
Examples: How to use init.d services with rvm,
apartment code sample
Any time I am using an open source project and have need of functionality that could
conceivably be provided by the project, if it's general enough I think it would be of use to
others, I'll implement it in that project instead of mine, and send a pull request. Depending
on the project, I might ask them if they'd be interested first.
Examples: Rails table migration generator,
Spree refactoring for reuse
Now, I don't tend to contribute a lot to any one project. If you're more interested in that,
I would guess you ought to do something similar, but focus it all in that one or two projects
that really excite you. Go through the issue tracker, see if you can reproduce and fix the bugs
people are reporting (or leave a comment telling them how to fix there problem if it's not really
a bug), etc.
For example, Steve Klabnik wrote up a how-to contribute to Rails,
which talks a little more on the human side of things, as opposed to just
the project contribution guidelines.
I think his blog post can be generalized to other projects as well, so it's worth a read to get an idea of how to go about interacting with bigger open source projects when you want to contribute.
Lots of projects will mention their own contribution guidelines though, so make sure you read them and follow them!
Hope that helps,
Sam
Hey! Why don't you make your life easier and subscribe to the full post
or short blurb RSS feed? I'm so confident you'll love my smelly pasta plate
wisdom that I'm offering a no-strings-attached, lifetime money back guarantee!
Posted by Sam on Feb 27, 2008 at 12:00 AM UTC - 5 hrs
(or your favorite regex engine)
I have a feeling this post is going to go over like a ton of bricks.
The subject of regular languages, context free languages, and just formal language theory in general
caught my eye today with a question about prime numbers. This was one of my favorite classes as
an undergraduate,
so I thought I'd join in the discussion.
If you can provide a regular expression such that it actually matches the string
representation of only prime (or only non-prime) integers, that would be pretty sweet.
A proof that such a thing could not be created would be equally impressive.
(Sam also linked to a blog post
that linked to another
that constructed a regular expression to decide if the number of 1s in a string of 1s is
not prime, or /^1?$|^(11+?)\1+$/.)
Indeed, even determining if 1* is not prime (the regular expression above) can be shown
not to be a regular language. Using the pumping
lemma for regular languages:
Let the language L = { 1i, i is a number greater than 0 and is not prime }
Assume L is a regular language. Then, by the pumping lemma, there exists
a number p >= 1 such that every string w in L of length p or greater can
be decomposed into substrings w=xyz, where |y| (length of y) > 0, |xy| <= p,
and for all i >= 0, xyiz is also in L.
Choose a string, w from L whose length is greater than p.
Since there are infinitely many prime numbers, we can find one greater than any p.
Therefore, we can choose an i in w=xyiz such that repeating it some number
of times will be a prime. We arrive at a contradiction, and
note that because w cannot be pumped, L is not a regular language.
Another commenter mentioned that "Regular expressions these days can match any
context-free language through the use of sub-expressions." Clearly, since our language L
is not regular, but it is matched by a regex, we can see that today's regexes are more
powerful than regular languages would allow them to be. But, is our regex even restricted
enough to be a CFL?
A similar proof using the pumping lemma for CFLs
would show that our language L is more powerful than even a CFL. (Don't let me slide here if
that's not the case.)
Still, that doesn't tell us anything useful for the problem at hand - only that the regexen of (at least) Perl and Ruby
are more powerful than CFLs. But how much more? If we want to prove that a regular expression
(in the practical sense of the word)
cannot take a string representation of a number, (e.g., "13" or "256") and determine if
it is not prime (or prime), then we need to know how powerful regex are.
But I don't know where to start on that front. Any ideas?
Alternatively, if we want to prove that it can be done, we need only demonstrate so by
coming up with the regex to do it. I'm not convinced it's possible, but I'm not convinced it's
not possible either. Ideally, I'd like to find the formal definition of how powerful regex are,
and prove at least that we don't know if the language is in that class or not. (The
pumping lemmas, for example, are necessary but not sufficient to prove membership of L
amongst the respective class of languages.)
Comments are appreciated. I'm sort of stuck at the moment, so I wanted to bounce these
ideas out there to see if someone might bounce one back.
Posted by Sam on Mar 05, 2008 at 12:00 AM UTC - 5 hrs
One cool and sunny winter day, a beautiful young woman named Kate Libby (a.k.a "Acid Burn") was
writing some mean code. That code was part of a new system that would integrate
aspects of the Organization's SharePoint site with its Active Directory and
various databases. (Kate had since grown out of her hackerish ways.)
It was early in the morning when the piece of code had finally passed all the tests and was ready to deploy - just about two hours into the day. At this rate, Kate would be at the
pub by noon for a couple of pints, and then off to play a game of pickup Football in the early afternoon down at the park by her office.
Kate hit the deploy button and started packing her things, getting ready to leave. Just a quick
verification on the live site and off she'd be.
"Oh jeez, what's wrong now?" Kate asked herself. "Why can't anything just work?"
All the unit tests had passed. All the integration tests had passed. All the acceptance
tests had passed. All the tests-by-hand had passed. What was the difference between
the test site and the live one?
The error messages were largely useless. The last time Kate was getting useless error messages,
there was an issue with differences in credentials to AD, SharePoint, the database server, or any combination of them. Kate proceeded
under that assumption - it had a relatively high degree of being correct.
Twelve hours into three rewrites (trying different strategies to do the same thing) and several
hundred WTFs later, it finally hit her:
"OMFG," yelled Kate.
She noticed that it worked in Firefox, but not in Internet Explorer. After another round of WTFs and some time spent wondering why the different browsers caused a server error, and then some time wondering why SharePoint should error out on its own browser, she realized:
The issue wasn't with
her code at all - it never had been.
The form was supposed to be a normal form - nothing to do with ASP.NET at all. But ASP didn't
care - it wanted to see EnableEventValidation in the @Page directive
to let you submit your own form - but only through Internet Explorer.
Kate's story is a tragedy: the essential complexity of the problem took her a couple of hours, while the accidental complexity ate up twelve. It cost her a couple of pints and some
good fun on the field.
Luckily, you can avoid twelve hours of useless re-work if you just learn the lesson from Kate Libby's
horrific tale: isolate errors before you fix them. Otherwise, you might spend a
ridiculous amount of time "fixing" the parts that already work.
Posted by Sam on Mar 10, 2008 at 12:00 AM UTC - 5 hrs
In the past, I've asked a couple of times
about how you design algorithms. Of course, I'm not talking about algorithms with obvious solutions
or those which are already well-known.
Lately, I've been working on a project that I can't share too much about, where we're exploring what is, to my knowledge, mostly virgin territory. One thing I have learned that I can share, is something about algorithm design.
It seems obvious to me now, and may be to you, but before recently, I had never thought about it: you can use an iterative approach in designing new algorithms. In the past, I had thought the opposite - since as a unit, the algorithm would rarely have the ability to be broken into chunks for testing purposes, how could we break it into chunks for iteration purposes?
But with the latest one we've been working on, we were able to take an iterative approach in it's design.
The process went something like this:
Decide what it is you need to accomplish - not necessarily how to accomplish it.
Based on that, find the parameters to the algorithm that will vary in each invocation.
Fix the parameters, and run through the algorithm. This will be it's simplest version.
Go ahead and write it if you want - but be aware it will likely change dramatically between now and when you are finished.
For each parameter p, vary it and go through the algorithm keeping the rest of the
parameters fixed.
When you've got that working, now you can start varying combinations of parameters.
Always observe what your algorithm is outputting versus expected output, and
fix it when it's wrong.
Finally, allow all the parameters to vary as they would in working conditions.
Clean it up, keeping its essence.
A final bit of advice: don't force looping when the code won't go there. The code
I was working on could have had any number of nested loops, and I spent a long time trying to find the relationships behind the parameters and their depth in the loop structure, in an
attempt to find a way to fix the number of loops (so we don't have to change the code each time
we need another loop in the nest). It was quickly becoming a hard-to-understand mess.
Instead, take a few minutes to step back and look at it from a distance. Do you really need to be looping? In my case, not as much as I thought. Use recursion when the code wants to be recursive. (If you still really want to avoid recursion, you'll probably need to simulate it with your own stack - but why do all the extra work?)
That iterative approach to algorithm design worked for me. It turned what at first seemed like a daunting, complicated algorithm into just several lines of elegant, understandable code.
Do you have an approach to designing algorithms whose solutions you don't know (and to be clear - can't find via search)?
Posted by Sam on Apr 09, 2008 at 12:00 AM UTC - 5 hrs
Something's been bothering me lately. It's nothing, really. ?, ?, null, nil, or whatever you want to call it. I think we've got it backwards in many cases. Many languages like to throw errors when you try to use nothing as if it were something else - even if it's nothing fancy.
I think a better default behavior would be to do nothing - at most log an error somewhere, or allow us a setting - just stop acting as if the world came to an end because I *gasp* tried to use null as if it were a normal value.
In fact, just because it's nothing, doesn't mean it can't be something. It is something - a concept at the minimum. And there's nothing stopping us from having an object that represents the concept of nothing.
Exceptions should be thrown when something exceptional happens. Maybe encountering a null value was at some time, exceptional. But in today's world of databases, form fields, and integrated disparate systems, you don't know where your data is at or where it's coming from - and encountering null is the rule, not the exception.
Expecting me to write paranoid code and add a check for null to avoid every branch of code where it might occur is ludicrous. There's no reason some sensible default behavior can't be chosen for null, and if I really need something exceptional to happen, I can check for it.
Really, aren't you sick of writing code like this:
string default = "";
if(form["field"] != null and boolFromDBSaysSetIt != null
and boolFromDBSaysSetIt)
default = form["field"];
when you could be writing code like this:
if(boolFromDBSaysSetIt)
default = form["field"];
I think this is especially horrid for conditional checks. When I write if(someCase) it's really just shorthand for if(someCase eq true). So why, when
someCase is null or not a boolean should it cause an error? It's not
true, so move on - don't throw an error.
Someone tell me I'm wrong. It feels like I should be wrong. But it feels worse to have the default path always be the one of most resistance.
Posted by Sam on Apr 28, 2008 at 12:00 AM UTC - 5 hrs
When I was younger I was "an arrogant know-it-all prick" at one point in the "middle years" of my programming experience, as many of you know from the stories I often relate on this weblog.
The phrase "middle years" doesn't give us a frame of reference for my age though. For instance, if I were 50 years old right now, my "middle years" of programming may have been when I was in my thirties. That's not the case, and I want to give you that frame of reference: I'm 28 at the time of this writing. The middle years as I talked about them would have referred to my late teens to early twenties. Maybe even up to the the middle of my twenties.
By most standards, that's young.
And I know a thing or two about being set in your ways. We can all see the laugh I have at myself with the title here being "MySecretLife as a SpaghettiCoder" and some of the stories I've told as well.
In fact, let me add to the wealth of stodginess, idiocy, and all around opposite-of-good-developerness here:
I once said I preferred Windows to Linux. While that's not a completely shocking statement, the reason behind it was: I said I preferred Windows because 14 year olds work on Linux. Not because of any experience I'd had with it, but because of my fear of learning it.
Because of my prior experience being unwilling to learn, I was quite interested when I read this:
When you are young, you don't have that sense of self to protect. You're driven by a need to find out who you are, to turn the pages of your biography and see how the story turns out. If people around you are doing something you don't understand, you assume the problem is your inexperience and you go to work trying to understand it.
But when you are old, when you know who you are, everything is different. When people around you are doing something you don't understand, you have no trouble at all explaining why they are assholes mistaken.
. . .
If you want a new idea, you have to silence your inner critic. Your sense of right and wrong, of smart and stupid works by comparing new ideas to what you already know. Your sense of what would be a good fit for you works by comparing new things to who you already are. To learn and grow, you must let go of you, you must be young again, you must accept that you don't understand and seek to understand rather than explaining why it doesn't make any sense.
In a couple of paragraphs, Reg sums up almost precisely some of what I've been thinking and writing about for the last several months. He's so close, but misses a fundamental point: the old and young parts are incidental.
My hypothesis is that the level of learning and idea absorption you can attain has little to do with age. Instead, it is influenced more by your perceived level of experience. Normally, age is highly correlated to experience - but it doesn't have to be. In my case, when I was younger I thought I knew everything. Now that I've aged, I came to the realization I know very little.
My conclusion is not that different from Reg's, and this is not some scientific experimental contest, so let me explain why I feel the difference is worth noting: If we blame our reluctance to try new things on age, we are dooming ourselves to think of it as some unchangeable, deterministic process. By thinking of it in terms of perception of experience, we admit to being able to control it with more ease. (My belief is that we have control over what and how we perceive things.)
In other words, we lose our ability to blame anyone but ourselves. That's a powerful motivator sometimes.
Thoughts? Disagreements? Please be kind enough to let me know.
Posted by Sam on May 28, 2008 at 12:00 AM UTC - 5 hrs
In the field of bioinformatics, one way to measure similarities between two (or more) sequences of
DNA is to perform sequence alignment:
"a way of arranging the primary sequences of DNA, RNA, or protein to identify regions of similarity that may
be a consequence of functional, structural, or evolutionary relationships between the sequences."
Think of it this way: you've got two random strands of DNA - how do you know where one starts and one begins?
How do you know if they come from the same organism? A closely related pair? You might use sequence alignment
to see how the two strands might line up in relation to each other - subsequences may indicate similar
functionality, or conservation through evolution.
In "normal" programming terms, you've got a couple of strings and want to find out how you might align them so they they look
as much like one another as possible.
There are plenty of ways to achieve that goal. Since we haven't done much programming on here lately,
I thought it would be nice to focus on two very similar algorithms that do so:
Needleman-Wunsch and
Smith-Waterman.
The first @substitution_matrix is fairly simplistic - give one point for each match, and ignore any mismatches or gaps introduced.
In @substitution_matrix2
what score should be given if "s" is aligned with "a"? (One.) What if "d" is aligned with another "d"? (Six.)
The substitution matrix is simply a table telling you how to score particular characters when they are in the same position in two
different strings.
After you've determined a scoring scheme, the algorithm starts scoring each pairwise alignment, adding to or
subtracting from the overall score to determine which alignment should be returned. It uses
dynamic programming, storing calculations
in a table to avoid re-computation, which allows it to reverse course after creating the table to find and return
the best alignment.
It feels strange to implement this
as a class, but I did it to make it clear how trivially easy it is to derive Smith-Waterman (SW) from Needleman-Wunsch (NW). One design that jumps out at me would be to have a SequenceAligner where you can choose which algorithm as a method to run - then SW could use a NW algorithm where min_score is passed as a parameter to the method. Perhaps you can think of something even better.
Anyway, here's the Ruby class that implements the Needleman-Wunsch algorithm.
classNeedlemanWunsch@min_score=nildefinitialize(a,b,substitution_matrix,gap_penalty)@a=a@b=b# convert to array if a/b were strings@a=a.split("")ifa.class==String@b=b.split("")ifb.class==String@sm=substitution_matrix@gp=gap_penaltyenddefget_best_alignmentconstruct_score_matrixreturnextract_best_alignment_from_score_matrixenddefconstruct_score_matrixreturnif@score_matrix!=nil#return if we've already calculated itinitialize_score_matrixtraverse_score_matrixdo|i,j|ifi==0&&j==0@score_matrix[0][0]=0elsifi==0#if this is a gap penalty square@score_matrix[0][j]=j*@gpelsifj==0#if this is a gap penalty square @score_matrix[i][0]=i*@gpelseup=@score_matrix[i-1][j]+@gpleft=@score_matrix[i][j-1]+@gp#@a and @b are off by 1 because we added cells for gaps in the matrixdiag=@score_matrix[i-1][j-1]+s(@a[i-1],@b[j-1])max,how=diag,"D"max,how=up,"U"ifup>maxmax,how=left,"L"ifleft>max@score_matrix[i][j]=max@score_matrix[i][j]=@min_scoreif@min_score!=nilandmax<@min_score@traceback_matrix[i][j]=howendendenddefextract_best_alignment_from_score_matrixi=@score_matrix.length-1j=@score_matrix[0].length-1left=Array.newtop=Array.newwhilei>0&&j>0if@traceback_matrix[i][j]=="D"left.push(@a[i-1])top.push(@b[j-1])i-=1j-=1elsif@traceback_matrix[i][j]=="L"left.push"-"top.push@b[j-1]j-=1elsif@traceback_matrix[i][j]=="U"left.push@a[i-1]top.push"-"i-=1elseputs"something strange happened"#this shouldn't happenendendreturnleft.join.upcase.reverse,top.join.upcase.reverseenddefprint_score_visualizationconstruct_score_matrixprint_as_table(@score_matrix)enddefprint_traceback_matrixconstruct_score_matrixprint_as_table(@traceback_matrix)enddefprint_as_table(the_matrix)putsputs"a="+@a.to_sputs"b="+@b.to_sputsprint" "@b.each_index{|elem|print" "+@b[elem].to_s}puts""traverse_score_matrixdo|i,j|ifj==0andi>0print@a[i-1]elsifj==0print" "endprint" "+the_matrix[i][j].to_sputs""ifj==the_matrix[i].length-1endenddeftraverse_score_matrix@score_matrix.each_indexdo|i|@score_matrix[i].each_indexdo|j|yield(i,j)endendenddefinitialize_score_matrix@score_matrix=Array.new(@a.length+1)@traceback_matrix=Array.new(@a.length+1)@score_matrix.each_indexdo|i|@score_matrix[i]=Array.new(@b.length+1)@traceback_matrix[i]=Array.new(@b.length+1)@traceback_matrix[0].each_index{|j|@traceback_matrix[0][j]="L"ifj!=0}end@traceback_matrix.each_index{|k|@traceback_matrix[k][0]="U"ifk!=0}@traceback_matrix[0][0]="f"enddefs(a,b)#check the score for bases a. b being alignedforiin0..(@sm.length-1)breakifa.downcase==@sm[i][0].downcaseendforjin0..(@sm.length-1)breakifb.downcase==@sm[0][j].downcaseendreturn@sm[i][j]endend
Needleman-Wunsch follows that path, and finds the best global alignment possible. Smith-Waterman truncates
all negative scores to 0, with the idea being that as the alignment score gets smaller, the local alignment
has come to an end. Thus, it's best to view it as a matrix, perhaps with some coloring to help you visualize
the local alignments.
All we really need to get Smith-Waterman from our implementation of Needleman-Wunsch above is this:
However, it would be nice to be able to get a visualization matrix. This matrix should be able to use windows
of pairs instead of
each and every pair, since there can be thousands or millions or billions of base pairs we're aligning. Let's add a couple of methods to that
effect:
#modify array class to include extract_submatrix methodclassArraydefextract_submatrix(row_range,col_range)self[row_range].transpose[col_range].transposeendendrequire'needleman-wunsch'classSmithWaterman<NeedlemanWunschdefinitialize(a,b,substitution_matrix,gap_penalty)@min_score=0super(a,b,substitution_matrix,gap_penalty)enddefprint_score_visualization(window_size=nil)returnsuper()ifwindow_size==nilconstruct_score_matrix#score_matrix base indexessi=1#windowed_matrix indexeswi=0windowed_matrix=initialize_windowed_matrix(window_size)#compute the windowswhile(si<@score_matrix.length)sj=1wj=0imax=si+window_size-1imax=@score_matrix.length-1ifimax>=@score_matrix.lengthwhile(sj<@score_matrix[0].length)jmax=sj+window_size-1jmax=@score_matrix[0].length-1ifjmax>=@score_matrix[0].lengthcurrent_window=@score_matrix.extract_submatrix(si..imax,sj..jmax)current_window_score=0current_window.flatten.each{|elem|current_window_score+=elem}beginwindowed_matrix[wi][wj]=current_window_scorerescueendwj+=1sj+=window_sizeendwi+=1si+=window_sizeend#find max score of windowed_matrixmax_score=0windowed_matrix.flatten.each{|elem|max_score=elemifelem>max_score}max_score+=1#so the max normalized score will be 9 and line up properly #normalize the windowed matrix to have scores 0-9 relative to percent of max_scorewindowed_matrix.each_indexdo|i|windowed_matrix[i].each_indexdo|j|beginnormalized_score=windowed_matrix[i][j].to_f/max_score*10windowed_matrix[i][j]=normalized_score.to_irescueendendend#print the windowed matrixwindowed_matrix.each_indexdo|i|windowed_matrix[i].each_indexdo|j|printwindowed_matrix[i][j].to_sendputsendenddefinitialize_windowed_matrix(window_size)windowed_matrix=Array.new(((@a.length+1).to_f)/window_size)windowed_matrix.each_indexdo|i|windowed_matrix[i]=Array.new(((@b.length+1).to_f)/window_size)endreturnwindowed_matrixendend
And now we'll try it out. First, we take two sequences and perform a DNA dotplot analysis on them:
Then, we can take our own visualization, do a search and replace to colorize the results by score, and have a look:
Lo and behold, they look quite similar!
I understand the algorithms are a bit complex and particularly well explained, so I invite questions about
them in particular. As always, comments and (constructive) criticisms are encouraged as well.
Posted by Sam on Jun 04, 2008 at 12:00 AM UTC - 5 hrs
If you get too smart, you start to think a lot. And when you think a lot, your mind explores the depths of some scary places. If you're not careful, your head could explode.
So to combat the effects of increasing intelligence due to reading books like The Mythical Man Month and Code Complete, I'm careful about maintaining a subscription to digg/programming in my feed reader. Incidentally, this tactic is also useful in preemptive head explosion. However, this second type of explosion is usually caused by asininity, as opposed to the combinatorial explosion due to choices you gain from reading something useful.
Ohloh, a company that ranks the nation's top open source coders, is opening its service to let other developers to track and rank their own teams. [Strong emphasis is mine.]
It's the latest move by Ohloh, a Bellevue, WA company that already distributes its coder profiles and related data to about 5,000 open source sites. The Ohloh profiles can serve as advertising for these sites, because the profiles show how active their open source development projects are.
Here's how it works. Ohloh ranks individual coders by tracking their activity. Ohloh can do this because open source projects publish their code, along with a record of updates each coder makes. Ohloh exploits this publicly available information and analyzes which coders are the most active in making key contributions to the most important open source projects. It assigns them a "KudoRank" to each coder between 1 (poor) through 10 (best).
Teams now have access to Ohcount - "a source code line counter" that "identifies source code files in most common programming languages, and prepares total counts of code and comments."
Unfortunately, since Ohcount helps power the normal Ohloh website, I'd bet it can track commits and lines of code by committer.
As is well known to many people, if you want something done, measure it. In this case, presumably you want more lines of code.
And what makes measuring lines of code per developer (and saying more == better) completely stupid is that program size is code's worst enemy. You'll end up doing the opposite of what you intended.
Still, Ohloh has some interesting stats for you to look at. And you know you want to be ranked #1.
Posted by Sam on Jun 16, 2008 at 12:00 AM UTC - 5 hrs
Is there a perfect way to teach programming to would-be programmers? Let's ask the Magic 8-Ball.
Outlook not so good.
Does that mean we shouldn't teach them? Of course not. Does it mean we shouldn't look for better methods of teaching them? Emphatically I say again, "of course not!"
And what of the learner? Should beginners seek to increase their level of skill?
Only if they want to become a level 20 Spaghetti Code Slingmancer (can you imagine the mess?). Or, that's how some make it seem.
All it means to me is that we shouldn't let our paranoia about the wrong ways of learning stop us from doing so. For instance, take this passage about the pitfalls of reading source code:
Source code is devoid of context. It's simply a miscellaneous block of instructions, often riddled with a fair bit of implicit assumptions about preconditions, postconditions, and where that code will fit in to the grand scheme of the original author's project. Lacking that information, one can't be sure that the code even does what the author wanted it to do! An experienced developer may be able to apply his insight and knowledge to the code and divine some utility from it ("code scavenging" is waxing in popularity and legitimacy, after all), but a beginner can't do that.
Josh also mentions that source code often lacks rationale behind bad code or what might be considered stupid decisions, and that copy and paste is no way to learn.
They're all valid points, but the conclusion is wrong.
Which one of us learned the craft without having read source code as a beginner? Even the author admits that he was taught that way:
Self-learning is what drives the desire to turn to source code as an educational conduit. I have no particular problem with self-learning -- I was entirely self-taught for almost three quarters of what would have been my high school career. But there are well-known dangers to that path, most notably the challenge of selecting appropriate sources of knowledge for a discipline when you are rather ill-informed about that selfsame discipline. The process must be undertaken with care. Pure source code offers no advantages and so many pitfalls that it is simply never a good choice.
This is a common method of teaching - "do as I say, not as I do." It's how we teach beginners anything, because their simple minds cannot grasp all the possible combinations of choices which lead to the actual Right Way to do something. It's a fine way to teach.
But I'd wager that for all X in S = {good programmers}, X started out as a beginner reading source code from other people. And X probably stumbled through the same growing pains we all stumble through, and wrote the same crapcode we all do.
Of course, there are many more bad programmers than good, so lets not make another wrong conclusion - that any method of learning will invariably produce good programmers.
Instead, let's acknowledge that programming is difficult as compared to many other pursuits, and that there's not going to be a perfect way to learn. Let's acknowledge that those who will become good programmers will do so with encouragement and constant learning. Instead of telling them how they should learn, let them learn in the ways that interest them, and let's guide them with the more beneficial ways when they are open to it.
Let's remember that learning is good, encourage it, and direct it when we can. But let people make mistakes.
Learning in the wrong manner will produce good programmers, bad programmers, and mediocre ones.
Independent, orthogonal, and irrelevant are all words that come to mind. The worst it will do is temporarily delay someone from reaching their desired level of skill.
I would be knowledgeable having read programming books with no practical experience. But I wouldn't have any understanding. Making mistakes is fundamental to understanding. Without doing so, we create a bunch of angry monkeys, all of whom "know" that taking the banana is "wrong," but none of whom know why.
Indeed, that code is hard to understand, and comments would clear it up. And I'm not trying to pick on Peter (the code is certainly not something I'd be unlikely to write), but there are other ways to clear up the intent, which the clues of str, pat, * and ? indicate may have something to do with regular expressions. (I'll ignore the question of re-implementing the wheel for now.)
For example, even though pat, str, idx, ch, and arr are often programmer shorthand for pattern, string, index, character, and array respectively, I'd probably spell them out. In particular, str and array are often used to indicate data types, and for this example, the data type is not of secondary importance. Instead, because of the primary importance of the data type, I'd opt to spell them out.
Another way to increase the clarity of the code is to wrap this code in an appropriately named function. It appears as if it was extracted from one as there is a return statement, so including a descriptive function name is not unreasonable, and would do wonders for understandability.
But the most important ways in which the code could be improved have to do with the magic strings and boolean expressions. We might ask several questions (and I did, in a follow-up comment to Peter's):
Why are we stopping when patArr[patIdxEnd] EQ '*' OR strIdxStart GT strIdxEnd?
Why are we returning false when ch=="?" and ch!=strArr[strIdxEnd]?
What is the significance of * and ?
In regular expression syntax, a subexpression followed by * tells the engine to find zero or more occurrences of the subexpression. So, we might put it in a variable named zeroOrMore, and set currentPatternToken = patArr[patIdxEnd]. We might also set outOfBounds = strIdxStart GT strIdxEnd, which would mean we continue looping when currentPatternToken NEQ zeroOrMore AND NOT outOfBounds.
Similarly, you could name '?' by putting it in a variable that explains its significance.
And finally, it would be helpful to further condense the continue/stop conditions into variable names descriptive of their purpose.
In the end, regular expression engines may indeed be one of those few applications that are complex enough to warrant using comments to explain what's going on. But if I was already aware of what this piece of code's intent was, I could also have easily cleared it up using the code itself. Of course it is near impossible to do after the fact, but I think I've shown how it might be done if one had that knowledge before-hand.
Posted by Sam on Jul 09, 2008 at 12:00 AM UTC - 5 hrs
Your boss gave you three weeks to work on a project, along with his expectations about what should be done during that time.
You started the job a week before this assignment, and now is your chance to prove you're not incompetent.
You're a busy programmer, and you know it will only take a couple of days to finish anyway, so you put it on the back-burner for a couple of weeks.
Today is the day before you're supposed to present your work. You've spent the last three days dealing with technical problems related to the project. There's no time to ask anyone for help and expect a reply.
Tonight is going to be hell night.
And you still won't get it done.
What can you do to recover? Embrace failure. Here's how I recently constructed (an anonymized) email along those lines:
Take responsibility. Don't put the blame on things that are out of your control. It's a poor excuse, it sounds lame, and it affords you no respect. Instead, take responsibility, even if it's not totally your fault. If you can't think of an honest way to blame yourself, I'd go so far as to make something up.
I've been having some technical troubles getting the support application to work with the project.
To compound that problem, instead of starting immediately and spreading my work across several days, I combined all my work this week into the last three days, so when I ran into the technical problems, I had very little time to react.
After trying to make the support application run on various platforms, I finally asked a teammate about it, where I learned that I needed to use a specific computer, where I did not have access.
As such, I don't think I can meet your expectations about how much of the project should be done by tomorrow.
State how you expect to avoid the mistake in the future. Admitting your mistake is not good enough. You need to explain what you learned from the experience, and how that lesson will keep you from making a similar mistake in the future.
I just wanted to say that I take responsibility for this mistake and in the future, I will start sooner, which will give me an opportunity to receive the feedback I need when problems arise. I've learned that I cannot act as a one man team and I by starting sooner I can utilize my teammates' expertise.
Explain your plan to rectify the situation. If you don't have a plan for fixing your mistake, you'll leave the affected people wondering when they can expect progress, or if they can trust you to make progress at all. Be specific with what you intend to do and when you will have it done, and any help you'll need.
I already sent an email request to technical support requesting access to the specific computer, and await a response.
In the mean time, here's how I expect to fix my mistake:
a) I need to run the support program on data I already have. It will analyze the data and return it in a format I can use in the next process. I can have this completed as soon as I have access to the machine, plus the time it takes to run.
b) I need to learn how to assemble another source of data from its parts. I have an article in-hand that explains the process and I am told we have another support program that will be available next week. I do have the option to write my own "quick and dirty" assembler, and I will look into that, but I do not yet know the scope.
c) I need to use another one of our tools on the two sets of data to get be able to analyze them. Assuming I am mostly over the technical problems, I wouldn't expect this to cause any more significant delay.
d) Finally, I'm unsure of how to finish the last part of the project (which is not expected for this release). If possible, I'd like to get feedback on how to proceed at the next meeting with our group.
After that, close the email with a reiteration that it was your fault, you learned from it, you won't let it happen again, and that it will be resolved soon.
Since I rarely make mistakes, I'm certainly no expert at how to handle them. Therefore, I pose the question to you all, the experts:
How would you handle big mistakes? What strategies have worked (or failed) for you in the past?
Posted by Sam on Jul 11, 2008 at 12:00 AM UTC - 5 hrs
Don't be afraid to make connections with other programmers, even if you might consider them a "rockstar." Those connections can make you a much better software developer.
That's the point Chad Fowler makes in this week's chapter of MJWTI.
After relating the concept to the music scene (with which at one time I was also familiar), Chad (not surprisingly) sums up the matter in a few well-chosen words:
The most serious barrier between us mortals and the people we admire is our own fear. Associating with smart, well-connected people who can teach you things or help find you work is possible the best way to improve yourself, but a lot of us are afraid to try. Being part of a tight-knit professional community is how musicians, artists, and other craftspeople have stayed strong and evolved their respective artforms for years. The gurus are the supernodes in the social and professional network. All it takes to make the connection is a little less humility.
One of the reasons I started blogging was to make connections with other programmers. I enjoy it. Before I started reaching out to my fellow code-enthusiasts, I sucked. I still suck (don't we all?), but I suck progressively less each day. Part of the reason I'm on the road to Notsuckington can be attributed to the connections I've made with all of you.
Some of you taught me better design. To argue better. To write clearly, in code and prose. The value of being a wishy-washy flip-flopper.
Some of you helped me find flaws in my own work. Some helped correct them. The list could literally continue much further. However, in the interest of not publicly proclaiming myself a leech, I'll stop there.
Boo! Are you scared? Am I a zombie who wants to feed on your brain?
Ok, so I am a zombie who wants to feed on your brain. Luckily, it's not a zero-sum proposition. You can retain your thoughts, knowledge, and memories while also sharing them with me.
Feel free to drop me a line any time. You might be able to teach me something, even if you're asking a question. I might be able to teach you something too. I won't be offended at you contacting me if you won't be offended if I don't always have the time to respond.
Let's travel to Notsuckington together.
Have you any stories of how connections with other programmers have made you better? Please, share them with the rest of us! (You can leave the names out, if you want.)
I think that's sound advice. But is there ever a time when you ought to use cryptic one-letter variable names and strange symbols in your code?
If we're admonished to write code so that it's easier to be read, then I think, yes, depending on your intended audience, there are times when it's OK.
For example, if you work in a science lab and are implementing a math theorem, everyone on the team knows how to read and probably prefers the concise notation. Would that not be a good time to break the no-single-letter-variable-name rule?
In the article, he talks about dealing with an account_balance where you iterate over
the transactions of the account and sum up their amounts to arrive at a final balance.
A special case arrives when he points out you're dealing with a transaction.type
whose value is "pending". You clearly don't want to include this in the account_balance because when the transaction processor introduces a new
transaction of "authorized" for the same purchase, your overall balance will be incorrect.
A lot of the code I see (and used to write) looks like Avdi's example:
def account_balance
cached_transactions.reduce(starting_balance)do|balance, transaction| if transaction.type == "pending"
balance else
balance + transaction.amount end end end
It cannot be stressed enough how important the advice is to go from code like that to introducing a new object. In my experience, many cases are solved by simply introducing an OpenStruct.new(attributes: "you need", to: "support"), but Avdi advocates going further than that, and introducing a new object entirely.
I'm a fan of that, but typically I'll wait until YAGNI is satisfied, like when I need a method call with parameters.
Doing that is a huge win. As Avdi points out, it
solves the immediate problem of a special type of transaction, without duplicating logic for
that special case all throughout the codebase
But for me, the second benefit he mentions is the biggest, and I hope he'll revisit its importance over and over again:
But not only that, it is exemplary: it sets a good example for code that follows. When, inevitably, another special case transaction type turns up, whoever is tasked with dealing with it will see this class and be guided towards representing the new case as a distinct type of object.
I really enjoy the style of what I've read so far as a narrative, and if the article is any indication, this will be better than Objects on Rails (which I loved). One bit of feedback though: I'd like to see a "Key Takeaway" at the end of every section, so it can double as a quick reference book when I need to remind myself of its lessons.
Posted by Sam on Jun 18, 2008 at 12:00 AM UTC - 5 hrs
Just two years ago, I was beyond skeptical towards the forces telling me that comments are
worse-than-useless, self-injuring blocks of unexecutable text in a program. I thought the idea was downright ludicrous. But as I've made an effort towards reaching this nirvana called "self-documenting code," I've noticed it's far more than a pipe dream.
The first thing you have to do is throw out this notion of gratuitously commenting for the sake of commenting that they teach you in school. There's no reason every line needs to be commented with some text that simply reiterates what the line does.
After that, we can examine some seemingly rational excuses people often use to comment their code:
The code is not readable without comments. Or, when someone (possibly myself) revisits the code, the comments will make it clear as to what the code does. The code makes it clear what the code does. In almost all cases, you can choose better variable names and keep all code in a method at the same level of abstraction to make is easy to read without comments.
We want to keep track of who changed what and when it was changed. Version control does this quite well (along with a ton of other benefits), and it only takes a few minutes to set up. Besides, does this ever work? (And how would you know?)
I wanted to keep a commented-out section of code there in case I need it again. Again, version control systems will keep the code in a prior revision for you - just go back and find it if you ever need it again. Unless you're commenting out the code temporarily to verify some behavior (or debug), I don't buy into this either. If it stays commented out, just remove it.
The code too complex to understand without comments. I used to think this case was a lot more common than it really is. But truthfully, it is extremely rare. Your code is probably just bad, and hard to understand. Re-write it so that's no longer the case.
Markers to easily find sections of code. I'll admit that sometimes I still do this. But I'm not proud of it. What's keeping us from making our files, classes, and functions more cohesive (and thus, likely to be smaller)? IDEs normally provide easy navigation to classes and methods, so there's really no need to scan for comments to identify an area you want to work in. Just keep the logical sections of your code small and cohesive, and you won't need these clutterful comments.
Natural language is easier to read than code. But it's not as precise. Besides, you're a programmer, you ought not have trouble reading programs. If you do, it's likely you haven't made it simple enough, and what you really think is that the code is too complex to understand without comments.
There are only four situations I can think of at the moment where I need to comment code:
In the styles of Javadoc, RubyDoc, et cetera for documenting APIs others will use.
In the off chance it really is that complex: For example, on a bioinformatics DNA search function that took 5 weeks to formulate and write out. That's how rare it is to have something complex enough to warrant comments.
TODOs, which should be the exception, not the rule
Explaining why the most obvious code wasn't written. (Design decisions)
In what other ways can you reduce clutter comments in your code? Or, if you prefer, feel free to tell me how I'm wrong. I often am, and I have a feeling this is one of those situations.
What are some other reasons you comment your code?
Posted by Sam on Feb 27, 2012 at 07:45 AM UTC - 5 hrs
Here's a 35 minute recording of the presentation which I gave to houstonrb on February 21, 2012. It is a practice run I did before the live presentation, so you won't get the discussion, but hopefully you'll find it useful anyway.
There is also reference to a project whose purpose is to eventually be a full-scale demonstration of the techniques: Project for the Rails OOP presentation
Posted by Sam on Feb 01, 2012 at 05:41 AM UTC - 5 hrs
You know when you see code like this:
class CompulsionsController < ApplicationController # ... standard actions above here defupdate if params[:obsessions].include?(ObsessionsTypes[:murdering_small_animals])
handle_sociopathic_obsessions redirect_to socio_path andreturn elsif params[:obsessions]
handle_normal_obsessions redirect_to standard_obsessions_path andreturn end
# normal update for compulsions @compulsion = Compulsions.find(params[:id])
if(@compulsion.update_attributes(params[:compulsion])) # ... remainder of the standard actions below here end
and the phrase "WTF were they thinking?" runs through your mind?
More...
I have a theory about that little "pass a flag in the url to skip over the real action and perform a different one"
trick I see so often (and have been guilty of using myself).
It's because you've got this omniscient file that knows everything about where to route requests
that's not part of your editing routine, so finding and opening it breaks your train of thought.
It's a pain to open routes.rb when you suddenly realize you need a new route.
That got me thinking:
Should controllers route themselves? Would it make more sense for a controller to tell the router
how each of it's actions should be reached?
In the second edition of Code Complete (that's an affiliate link), Steve McConnell writes about using
the Principle of Proximity (page 352) as a way to think about organizing code.
Keep related actions together.
From that point of view, it
certainly would be easier to follow along when you're questioning "how do I get to this action?"
Further, I think it would help solve the "pass a flag to an action to perform a different one" problem I illustrated in the code snippet above.
It was on my mind over the weekend, so I put together this little
experiment to see what controllers routing themselves in Rails would look like.
In that repository is a one-controller Rails project which specifies routes to itself using a gem you'll find in
vendor/gems/route.
One major drawback to doing routing in this style has to do with nested routes: should a controller that's
part of a nested route know who it's parents are? Should a higher-in-the-nest controller know about its child
routes? And if you choose one or the other, how would you specify it? What if there are conflicting routes -- who wins out?
It leads to a lot of questions for which I have no immediate answers.
Anyway, what do you think? Would this help solve the problem of recycled routes? Is that even a problem?
What are the drawbacks of such an approach? Do you see any merits?
The next one makes your object unable to decide what it is, turning it into a FickleTeenager. If he has to check more than once,
the typecaser is going to have a tough time with a kid who can't make up his mind.
Posted by Sam on Oct 24, 2011 at 08:41 AM UTC - 5 hrs
With a name like each_cons, I thought you were going to iterate through all the
permutations of how I could construct a list
you operated upon. For example, I thought
[1,2,3,4].each_consdo|x|# I did not notice the required argument puts x.inspect end
Posted by Sam on Oct 17, 2011 at 03:20 PM UTC - 5 hrs
It's a small step, but emcee-3PO can now identify the
staves in an image of sheet music for my single test case of "My Darling Clementine." I need to include
hundreds more test cases, and I plan to when I implement code to make the tests mark the sheet music
with what emcee3po detected so I can visually inspect the accuracy.
Do a y-projection on the image.
A projection just reduces the number of dimensions in an image. In this case, we just take
the number of dark-colored pixels in a row of the image. It's similar in theory to
3D projection, but instead of projecting
three dimensions onto a plane, we're projecting a plane onto a line.
I used a threshold of 50% to determine if a pixel was dark enough to include in the projection.
So, if R+G+B < (FF+FF+FF) / 2, I count the pixel as dark.
Find the local maxima.
We want to find the places where the number of dark pixels in a row is highest - those will indicate the horizontal
lines on the staff. To do that, we find all the places where the number of pixels stops growing and starts getting smaller -- or where the
slope changes from positive to negative. To ignore noise, we set a threshold as Fujinaga suggests at
the average of each row, so we don't include anything less than that in our collection of local maxima.
Find the tightest groups of 5.
We want to find all the places where 5 local maxima are the smallest distance apart, which should indicate
the 5 lines in a staff. This part is accomplished by examining each 5-element window in the array of
local maxima, and finding the one with the smallest distance between its points. Then you can remove
all the windows that include any of those points, and continue until there are no more windows.
Expand those indexes to collect the places where the notes fall outside the staff lines.
I don't remember Fujinaga mentioning this in the paper I linked to above, but I'm thinking it must be in there.
Essentially, since the local maxima get us only what's in between the 5 lines of the staff, we need
to expand it a bit so we can get the notes that don't fall directly between the 5 lines. Right now,
I've used 1/4 of the average of the rows in the projection, but I think it will need to be
an even smaller threshold because I'm still not reliably getting all of the notes.
Up next: reading the notes on the staves. That's going to be cool.
Posted by Sam on Sep 02, 2011 at 02:18 PM UTC - 5 hrs
Frequent changes and deprecations to technology you rely upon cause dependencies to break
if you want to upgrade. In many cases, you'll find yourself hacking through someone else's code
to try to fix it, because a new version has yet to be release (and probably never will). That can be
a chore.
I get embarrassed when something I've recommended falls prey to this cycle. Backwards compatibility
is one way to deal with the issue, but in the Rails world, few seem worried about it. It doesn't bother
me that code and interface quality is a high priority, but it does cause extra work.
There's a trick you can use to help isolate the pain, decrease the work involved in keeping your app up to date,
and improve your code in general. You've probably heard of it, but you might not be using it to help you
out in this area: encapsulation.
What I'm about to describe talks heavily about Ruby on Rails, but that's only because it was the focus
of what got me thinking about this. I think it really applies in general.
Problem
Rails changes frequently. Some people think it
changes too frequently. I'll leave it for you to decide whether or not that's the case.
One consequence of change is that plugins and gems designed to work with Rails break. Perhaps as a result
of frequent changes (in Rails or just the whims of the community about which project in a similar area does
the job best), the authors of those packages become disillusioned and abandon the project. They could
just be lacking time, of course.
Now you get to fix their code (which doesn't have to be a bad thing, if you contribute it back and someone
else is sparred the trouble), use a new project that does the same thing, roll your own, or sit on an old
version of Rails that time forgot, and everyone else forgot how to use.
Don't you get at least a little embarrassed that you have to recommend large changes to your
customer or product owner or manager as a result of upgrading to the latest version of a technology you
recommended using?
It reminds me of a quote from Harry Browne I heard as part of his year 2000 United States
Presidential election campaign:
Government is good at only one thing. It knows how to break your legs, hand you a crutch, and say,
"See if it weren't for the government, you couldn't walk."
I'm likening programmers to the government of that quote, except we don't pretend to
give the crutch away. We tell them "you can't walk without our crutch, so pay up." We sell people
on a technology which they build their business around, and then tell them they have to choose between
keeping a substandard version of it, or spending a lot of money to upgrade all the components.
(Understand that I'm talking about how it feels overall as a result of what happens in the community of
programmers, not a particular instance of particular decisions by any particular well-defined group of programmers.)
I just got done migrating a Rails 2.3 app to Rails 3.1 that was heavily dependent on several plugins and gems.
After writing a ton of missing tests, I made the switch and ran them. As expected, there were loads of errors.
More than half of them were due to the application's own code, but those failures were fixed with very little
effort. By far the most excruciating and time consuming task (even longer than writing all of the tests) was
spent getting the plugins to work (or in some cases, using new plugins and changing the application to use them
instead).
I acknowledge that I'm doing something wrong, because surely not everyone has this problem.
So tell me, how can I improve my experience?
A Solution?
Something I'd like to see more of in this area is to encapsulate your plugin usage. Rather than
include NoneSuch,
why don't you take the time to wrap it in your own code? In doing so, I see a couple of benefits:
You document which features you're using by only writing methods for those in use. That means
you have something specific to test against in your app, and something specific to run those
tests agains when you trade one dependency for another. It also means you know exactly what you
need to implement when you swap dependencies.
You ensure a consistent interface for your app to use, as opposed to having to change it when you
swap out which plugin you're using. Also, all your changes to that interface are localized, instead
of spread throughout your source code.
That means you can change one external dependency for another with greater ease, which means you'll be a
lot less likely to get off in the weeds trying to make something fundamentally unworkable work.
Posted by Sam on Aug 01, 2011 at 08:12 AM UTC - 5 hrs
When you first introduce someone to source control, things often go smoothly until the first time they have to merge conflicting changes. Then they wonder,
What's the point of this? I thought it was supposed to be easy but it's a PITA.
Two responses on how to combat this immediately come to mind.
The first thing that can help in this situation is to ensure they aren't having to merge useless files. I'm thinking of files here like the CSS generated from SASS: they change frequently but the changes don't affect them one way or the other. (In this case, because the CSS will be regenerated). Another example is a user-specific project settings file.
Two strategies to avoid useless merging are to ignore files (do not have the repository track them) and to automatically use one version of a file or another. Each has it's place.
In the case of a file that needn't be in the repository to begin with -- things like Thumbs.db or .DS_Store -- you should obviously ignore them. In the cases where files should be in the repository, but where you know which version you want all the time, you should consider telling it to always choose one file over another.
If you're using git, .gitignore will help you ignore files, while .gitattributes will help you choose one file over another without specifying it every time. I only wanted to make you aware of this, and Pro Git explains it better than I could, so I'll let you read about how to do it over there.
Thanks to Markus Prinz who helped me find .gitattributes when I didn't know the term I was looking for.
So what's the second thing that helps a newcomer to source control overcome their hatred of merging conflicting changes?
Remind them the alternative is to consistently have their own work overwritten.
Posted by Sam on Jun 30, 2011 at 04:40 PM UTC - 5 hrs
I was introduced to the concept of making estimates in story points instead of hours back in the Software Development Practices course when I was in grad school at UH (taught by professors Venkat and Jaspal Subhlok).
I became a fan of the practice, so when I started writing todoxy to manage my todo list, it was an easy decision to not assign units to the estimates part of the app. I didn't really think about it for a while, but recently
a todoxy user asked me
The estimate field is purposefully unit-less. That's because the estimate field gets used in determining how much you can get done in a week, so you could think of it in hours, minutes, days, socks, difficulty, rainbows, or whatever -- just as long as in the same list you always think of it in the same terms.
We are bad at estimating hours, but more consistent with points
Hours tell us nothing since the best developer on the team may be multiple times faster than the worst
It takes less time to estimate in points than hours
"The management metric for project delivery needs to be a unit of production [because] production is the precondition to revenue ... [and] hours are expense and should be reduced or eliminated whenever possible"
But I noticed another benefit in my personal habits. Not only does it free us of the shackles of thinking in time and the poor estimates that come as a result, it corrects itself when you make mistakes.
I recognized this when I saw myself giving higher estimates for work I didn't really want to do. Like a contractor multiplying by a pain-in-the-ass factor for her worst customer, I was consistently going to fib(x+1) in my estimates for a project I wasn't enjoying.
But it doesn't matter. My velocity on that list has a higher number than on my other list, so if anything I hurt myself by committing to more work on it weekly for any items that weren't inflated.
What do you think about estimating projects in leprechauns?
Posted by Sam on Jun 22, 2011 at 06:42 AM UTC - 5 hrs
Yesterday I got sick of typing rake test and rake db:migrate and being told
You have already activated rake 0.9.2, but your Gemfile requires rake 0.8.7. Consider using bundle exec.
I know you should always run bundle exec, but my unconscious memory has not caught up with my conscious one on that aspect, so I always forget to run rake under bundle exec.
So I wondered aloud on twitter if I could just alias rake to bundle exec rake, but confine that setting to specific directories (with bash being my shell).
Turns out, it is possible with the help of another tool that
Calvin Spealman pointed me towards: capn.
To successfully run the commands I've listed below, you need to have python and homebrew already installed. If you already have libyaml installed or have another way of getting it, there's no need for homebrew.
The section beginning with the line that starts out with echo and ending with -unalias rake"... creates the capn config file. It's just YAML, so if you'd rather create it with a text editor, you can surely do so. See the capn project for details on the config possibilities.
Either way, you'll want to change the paths I've used to the places you want to do the aliasing.
hooks:
- path: ~/workspace #change this to the path where you want to alias rake
type: tree # if you don't want the whole tree under the path above, remove this line
enter:
- echo aliasing rake to 'bundle exec rake'
- alias rake='bundle exec rake'
exit:
- echo unaliasing rake from 'bundle exec rake'
- unalias rake" > ~/.capnhooks
source capn # put this line in your .bash_profile if you want capn to work when you enter the shell
# to deactivate the hooks, use: unhook
Enjoy the silence now that you don't have to hear the whining.
Posted by Sam on Jun 12, 2011 at 07:22 PM UTC - 5 hrs
I have a job where in any given week I might be working on any one of 30 projects spread across a half dozen product lines. I freelance, sometimes with a single company, but I also work a lot through another company for several different customers. I have my personal projects too, of course, and then there's non-work type things like getting a haircut, building a garden, or changing the air filters around the house.
Problem
My list of things to do is too complex for me to keep in my head. It doesn't fit in a typical list because I might want to see what needs to be done, not just at work, or not just for a client, but also for different customers or projects, or both.
Furthermore, it doesn't quite fit into a project management tool either. I need something more flexible that lets me keep my professional and personal lists in the same place, and that gives me just a list when I need it, or some predictions and statistics and data when those things are appropriate.
Goals
So when I started on this project, I wanted something more than a todo list, but not as involved as a project management suite.
More...
I wanted to manage both my work and personal tasks in one place, without too many fields to fill out, but still having the ability to collect information that could be used for more than just seeing what needs to be done.
I wanted a simple view of items most of the time, but allowing for a more in-depth view when I need it.
I also wanted something that realizes some things have to be done at a certain time, some things can be done in a span of time, and some things just need to get done, regardless of when.
Most importantly, I wanted something that would allow me to divorce the view of tasks from a specific calendar or list, and let me look at what needs to be done in a variety of ways.
Progress
Today, todoxy collects a task in a single field, where you can specify a calendar, supply tags for an item, give it a date/time, and an estimate it can use to tell you when you might expect to be done based on your past performance.
Lists aren't wed to calendars: you create them for a specific calendar if you like, or a set of tags, or a time frame, or any combination of those things.
Rather than try to explain to you how this works in text alone, I figured a video might help: (you'll probably want to watch it in 720p, and bigger than fits here in the blog so you can read the text)
Basically, it shows:
There is a single input interface. Create a calendar by typing a colon (':') after the first thing you type. Create tags by prefixing them with a hash. Estimate items by using est=X where X is a number. Toss in a natural language reference to a date / time, and it will try to guess what you meant.
You can create lists based on tags, and then you can click a link to see a burndown chart that tries to predict when you'll be done based on your estimates and past performance.
Help Wanted
It doesn't do everything I want it to yet, but I've been happily using it for a couple of weeks now, so I figured it would be a great time to get some feedback.
To do that, I need some of you who are interested to sign up and use it. I don't have a lot of slots open because it's hosted on a free account right now, and performance will suck if I let too many people in. But if you think you'd like to try it out and don't mind providing me with some criticism and feedback, I would appreciate it!
As always, comments and criticism are greatly appreciated! I can handle the negative ones, so don't refrain, but make them constructive so I can take some action on them.
Posted by Sam on Apr 02, 2008 at 12:00 AM UTC - 5 hrs
I don't remember what I thought the first time saw the title of this
chapter ("Learn to Love Maintenance")
from My Job Went To India.
I felt sick though. The thought process probably went something like this:
Oh no. You mean I'm going to be stuck here so long I better learn to love it?
I've got it really bad - I have to maintain a bunch of the code I wrote. Mere mortals cannot
comprehend how bad that is. When do I get to toss my refuse off to some other sorry excuse for a programmer?
But Chad Fowler (in the book) turns it around, saying that not much is expected of maintenance programmers.
You just need to fix the occasional bug or add a small feature here or there. It really boils down to this:
[In a greenfield project,] when we don't have the constraints of bad legacy code and lack of funding to deal with, our managers and customers rightfully expect more from us. And, in project work, there is an expected business improvement. If we don't deliver it, we have failed. Since our companies are counting on these business improvements, they will often put tight reigns on what gets created, how, and by when. Suddenly, our creative playground starts to feel more like a military operation - our every move dictated from above.
But in maintenance mode, all we're expected to do is keep the software running smoothly
and for as little money as possible. Nobody expects anything from the maintenance
crew. Typically, if all is going well, customers will stay pretty hands-off with the daily management of the maintainers and their work. Fix bugs, implement small feature requests, and keep it
running. That's all you have to do.
Moreover, after enough code is written, that new project isn't much different than your maintenance work.
It's just missing the benefits.
Consequently, you've got a lot more freedom in maintenance to do as you will. Get creative. Spruce up the UI a little bit.
Since you get to interact with your "customer" more often,
"more people will know who you are, and
you'll have the chance to build a larger base of advocates in your business."
On top of that, being responsible for
the entire application, it's likely that "even without much effort, you will come to understand what
the application actually does." In doing so, you're well on your way to becoming a domain expert.
As I've mentioned before in several of the "Save Your Job" series' posts,
as of this writing, I'm working with a small company. So, not only am I a maintenance programmer, I'm a
greenfield project programmer too. I've been known to wear more than one hat (As I'm sure many of you can
say).
Because of that and the push to drive maintenance costs down - I don't get as many opportunities to get
creative in maintenance as Chad suggests. That's a bit of a downer for me.
But he ends it on a motivational high note in the "Act on it!" section: Pick the most important aspect of
your maintenance work and find a way to measure it. Make it a point to improve your performance in that
area, and measure again. Continuously improve. It's more motivating than having the mindset laid out in
the introduction to this post, and you'll likely
raise a few eyebrows.
Posted by Sam on Mar 17, 2008 at 12:00 AM UTC - 5 hrs
Suppose you want to write an algorithm that, when given a set of data points, will find an appropriate number
of clusters within the data. In other words, you want to find the k for input to the
k-means algorithm without having any
a priori knowledge about the data. (Here is my own
failed attempt at finding the k in k-means.)
def test_find_k_for_k_means_given_data_points()
data_points = [1,2,3,9,10,11,20,21,22]
k = find_k_for_k_means(data_points)
assert(k==3, "find_k_for_k_means found the wrong k.")
end
The test above is a reasonable specification for what the algorithm should do. But take it further: can you actually
design the algorithm by writing unit tests and making them pass?
That all led to this post, and me wanting to lay my thoughts out a little further.
In the general case, I agree with Dat that it would be better to have the executable tests/specs.
But, what Ben has described sounds like a stronger version of what Steve McConnell called
the pseudocode programming process
in Code Complete 2, which can be useful in working your way through an algorithm.
Taking it to the next step, with executable asserts - the "Iterative Approach To Algorithm Design" post
came out of a case similar to the one described at the top. Imagine you're coming up with something
completely new to you (in fact, in our case, we think it is new to anyone), and you know what you want
the results to be, but you're not quite sure how to transform the input to get them.
What
good does it do me to have that test if I don't know how to make it pass?
The unit test is useful for testing the entire unit (algorithm), but not as helpful for
testing the bits in between.
Now, you could potentially break the algorithm into pieces - but if you're working through it for the
first time, it's unlikely you'll see those breaking points up front.
When you do see them, you can write a test if you like. However, if it's not really a complete unit,
then you'll probably end up throwing the test away.
Because of that, and the inability to notice the units until
after you've created them, I like the simple assert statements as opposed to
the tests, at least in this case.
When we tried solving Sudoku using
TDD during a couple of meetings of the UH Code Dojo, we introduced a lot of methods I felt were artificially there, just to be able to test them.
We also created an object where one might not have existed had we known a way to solve Sudoku through
code to begin with.
Now, we could easily clean up the interface when we're done, but I don't really feel a compulsion to practice
TDD when working on algorithms like I've outlined above. I will write several tests for them to make sure
they work, but (at least today) I prefer to work through them without the hassle of writing tests for the
subatomic particles that make up the unit.
Posted by Sam on Mar 26, 2008 at 12:00 AM UTC - 5 hrs
When I try out a product, I like it to work. Sometimes, I like to tinker with things to gain a better understanding of how they work. Occasionally, I can manipulate them with skill. At other
times, I'm tinkering in the true sense of the word.
I'm going to point out a few problems I've had with some products I've been using. I won't name names, but some of you who also use these
products (or similar ones with the same problems) might understand what I'm talking about.
Hopefully, you all can draw a good conclusion from it.
I'm not a mechanic, but sometimes I might want to look into my radiator. Is there a reason
I need to disassemble the front of my car to unscrew the radiator cap? Likewise, diagnosing a problem with, and subsequently changing a starter or alternator isn't a task that only automobile doctors should perform. These are relatively high-failure parts that shouldn't require taking
apart the exhaust system to replace. That's the tinkerer in me talking.
I am a software developer, but sometimes I don't want to act like one when I work
with software written by someone else. Don't make me build your product from source. I'm not asking you to build it for me, and then email it to me. I'm just asking if it's possible for you to set up an automated build on all of the platforms where you intend your software to work.
I enjoy the ability to tinker with
open source software, not the requirement to do so.
The situation is even worse for proprietary programs. If you're lucky, there might be a way to mess with the settings that satisfies the tinkerer in you. But if you're not lucky,
you could do things like upgrade your operating system and have it break something in 3rd party code. Then you'll be at the mercy of that vendor
to make their software run properly with your upgrade. In the mean time, you're stuck
manually starting the software, or writing your own scripts to do it.
In the first release of an accounting package, I might expect to edit a text file to set my tax rate. But I better not have to do that in the ninth version. Moreover, if your software makes
certain assumptions about its running environment and those assumptions are parts that are
likely to fail, you better make sure I can change them in your program without tearing it
apart.
In the end, I understand that for early versions of products, you might not have worked out all the kinks or even found its purpose or audience. I expect that as an early adopter, and when I take that plunge, I enjoy it.
But once you're several years old and multiple versions in, I don't think it's too much to
have certain expectations. At that point, your software should just work and make it easy to make small adjustments.
Posted by Sam on Mar 28, 2008 at 12:00 AM UTC - 5 hrs
When I work in Windows, I don't get as much done as when I'm in MacOS X.
It's not because MacOS is inherently better than Windows productivity-wise. It's because
my calendar and time-boxing mechanism resides on MacOS. So when I've got an entire day of
work to do in Windows, I don't have anything telling me "it's time to switch tasks."
Why is that a problem? That's the focus of this week's chapter in MJWTI. (Last week, I took a mini-vacation / early bachelor party to go fishing at Lake Calcasieu in Southwest Louisiana, so I didn't get around to posting then in the Save Your Job series.)
The "Eight-Hour Burn" is another of the chapters in Chad's book that really stuck with me after I first read it.
The premise is that instead of working overtime, you should limit each day's work to an 8 hour period of intense activity. In doing so, you'll get more done than you otherwise would. Our
brains don't function at as high a level as possible when we're tired. And when we're working
on our fifth 60-hour week, we're probably tired.
We may love to brag about how productive we are with our all-nighters [paraphrasing Chad], but the reality is we can't be effective working too many hours over a long period of time.
And it's more than just our brains being tired that should prevent us from working too long. It's the fact that when we know we've got so much extra time to do something, we end up goofing off anyway:
Think about day 4 of the last 70-hour week you worked. No doubt, you were putting in a valiant effort. But, by day 4, you start to get lax with your time. It's 10:30 AM, and I know I'm going to be here for hours after everyone else goes home. I think I'll check out the latest technology news for a while. When you have too much time to work, your work time reduces significantly in value. If you have 70 hours available, each hour is less precious to you than when you have 40 hours available.
That's why I'm in trouble when I work in Windows all day. I do work 12-16 hours most days between job, school, and personal activity (like this blog). I get burnt out every few weeks and have to take a couple of days off, but when I'm in MacOS X, at least my working days are very productive: I've got each task time-boxed and any time I spend reading blogs or news or just getting lost on the web is always scheduled.
When I'm in Windows with nothing to remind me but myself, I drift off quite a bit more easily. After all, it's only 6:30 in the morning. I've still got eight hours to get everything done (I'm leaving early to go check the progress on the house I'm having built).
The good news is that I've got an item on my longer-term to-do list to remedy the situation. Hopefully after reading this chapter again, I'll be more motivated to get it done. The bad
news is, since it means working in Windows all day to get it done, I'll probably be off
doing my best to read all of Wikipedia instead.
Anyway, how much do you work? Do you have any tricks for staying fresh and motivated?
Interesting Work:
You can only write so many CRUD applications before the tedium drives you insane, and you think to yourself, "there's got tobe abetter way." Even if you don't find a framework to assist you, you'll end up writing your own and copying ideas from the others. And even that only stays interesting until you've relieved yourself of the burden of repetition.
Having interesting work is so important to me that I would contemplate a large reduction in income at the chance to have it (assuming my budget stays in tact or can be reworked to continue having a comfortable-enough lifestyle, and I can still put money away for retirement). Of course,the more interesting the work is, the more of an income reduction I could stand.
Fortunately, interesting work often means harder work, so many times you needn't trade down in salary - or if you do, it may only be temporary.
The opportunity to present at conferences and publish papers amplifies this attribute.
Competent Coworkers: One thing I can't stand is incompetence. I don't expect everyone to be an expert, and I don't expect them to know about all the frameworks and languages and tricks of the trade.
I do expect programmers to have basic problem solving skills, and the ability to learn how to fish.
Scope, Schedule, and Resources. Choose two. We, the development team, get to control the third.
Trust: One comment in the reddit discussion mentioned root access to my workstation and it made me think of trust. If you cannot trust me to administer my own computer, how can you trust me not to subvert the software I'm writing?
Additionally, I need you to trust my opinion. When I recommend some course of action, I need to know that you have a good technical reason for refusing it, or a good business reason. I want an argument as to why I am wrong, or why my advice is ignored. If you've got me consistently using a hammer to drive marshmallows through a bag of corn chips, I'm not likely to stay content.
I don't mind if you verify. In fact, I'd like that very much. It'll help keep me honest and vigilant.
Personal Time: I like the idea of Google's 20% time. I have other projects I'd like to work on, and I'd like the chance to do that on the job. One thing I'd like to see though, is that the 20% time is enforced: every Friday you're supposed to work on a project other than your current project. It'd be nice to know I'm not looked down upon by management as selfish because I chose to work on my project instead of theirs.
I wouldn't mind seeing something in writing about having a share of the profits it generates. I don't want to be working on this at home and have to worry about who owns the IP. And part of that should allow me to work on open source projects where the company won't retain any rights on the code I produce.
Telecommuting: Some days I'll have errands to run, and I dislike doing them. I really dislike doing them on the weekends or in the evenings after work. I'd like to be able to work from home on these days, do my errands, and work late to make up for it. It saves the drive time on those days to help ensure I can get everything done.
There are some other nice-to-have's that didn't quite make the list above for me. For example, it would be nice to be able to travel on occasion. It would also be nice to have conferences, books, and extended learning in general paid for by the company. I'd like to see a personal budget for buying tools I need, along with quality tools to start with.
But if you can meet some agreeable combination of the six qualities above, I'll gladly provide these things myself. If you won't let me use my own equipment, and you provide me with crap, we may not have a deal.
Posted by Sam on Apr 02, 2008 at 12:00 AM UTC - 5 hrs
When I wrote about things I'd like to have in a job, I didn't expect that one of the items on my list would draw the kind of reaction it did. A couple of comments seemed to think I'm off my rocker about personal project time:
Why should I pay for the time you spend doing your own projects? You are free to have 20% of the time to yourself if you can take 20% pay cut (from Adedeji O.)
Did I understand you correct? You want to work on something that has no relation to your employer and still get paid by him?
...
I don't know the exact rates in the US, but, these 20% will easily sum up to more than 10,000 USD per developer per year. Would YOU really pay that for nothing?
(from Christoph S.)
To be fair, Christoph did say that he's "not talking about time for personal and technical development and not about work related projects that MAY include benefit for your employer. I'm talking about working on 'my projects' and 'open source projects.'"
Here's what I had said that provoked the reactions:
I like the idea of Google's 20% time. I have other projects I'd like to work on, and I'd like the chance to do that on the job. One thing I'd like to see though, is that the 20% time is enforced: every Friday you're supposed to work on a project other than your current project. It'd be nice to know I'm not looked down upon by management as selfish because I chose to work on my project instead of theirs.
I wouldn't mind seeing something in writing about having a share of the profits it generates. I don't want to be working on this at home and have to worry about who owns the IP. And part of that should allow me to work on open source projects where the company won't retain any rights on the code I produce.
Calling it "my project," talking about who owns the intellectual property, and working on open source appear to be where I crossed the line. At Google, we see things like News and GMail coming from the personal time. What I stated could mean that a programmer for a bank's website that's done in ColdFusion could end up working on a GUI for Linux in C. It's rather hard to make the connection there.
First, I didn't mean to imply that the company would not own anything of any part of what I worked on. If I am willing to take a 20% cut in pay, then certainly I wouldn't expect them to own anything. What I was looking for is some equitable way to share what I create with my time. For example, I might take one day a week at work to build my new widget, but if I'm taking 2 days on the weekend to work on it, I ought to get more than a "thank you" if the project goes on to make hundreds of millions of dollars.
And, I was just saying there needs to be some way to allow me to work on open source software during that time. I don't know how the details would work, but there surely is an equitable way to deal with it. I certainly could have explained it better.
In any case, I don't expect that 20% of my time spent away from my main project translates to the project taking 20% longer, or 20% less profit or revenue or productivity for my company. The degradation may be linear if we are data entry clerks - if all we are doing is typing instructions given to us from on high (if the work is physical). But that's not typically what programming is about.
I'm not running a company though, and I've not done a study about such companies. If I were to do such a study, that would be my hypothesis, and what follows is what I would expect to see.
The great divide between average a good programmers is well-known. Let us suppose that an average programmer is being paid sixty thousand dollars a year. Let us also suppose that you have a team of good programmers at the lower end of the "good" scale - those who are 10 times more productive than their average counterparts.
Are you paying them six hundred thousand dollars per year? I'd be surprised if anyone said yes to that question. You may pay them more than average programmers, but not an order of magnitude more. Even if they are only twice as productive as the average ones, you aren't likely to be paying them enough to worry about 20 percent of their time compared to what you would be paying less-competent people and getting out of them.
But what does that have to do with anything? Suppose I don't have good programmers - what then? If all of your programmers are average or worse, 20% time is not justified in their salaries the same way it is for a good programmer. So what benefits would we expect to see for companies who provide some amount of unrestricted free time?
First, I think the cases where a developer does something unrelated with his free time will be rare. But even if what I'm choosing to work on in my time is the polar opposite of the company's direction, does the company still benefit from it?
I would expect that allowing your developers that free time to work on anything would bring better developers your way. If I'm looking for a job and one company offers me unrestricted free time plus the same salary as you offer, who do you think will be my first choice?
Working on open source software can make your existing developers better by interacting with other good developers and learning new things.
Your developers are learning things and keeping up with the newest technology, allowing you to react to changes in the market place quicker than your competitors. (You might not make iPhone applications at the moment, but if I spent a couple of Fridays digging into the iPhone SDK, you might already have an application ready to go.)
You might spin off new companies or departments based on products your employees are writing in their free time.
When I first read the reactions, I thought I did go overboard. But after some more consideration, I'm not so sure. Of course, we need a way to quantify and test these hypotheses to be sure what type of a positive or negative impact such a thing has on companies. But, I think it's very safe to say that going to a four day work week does not automatically mean we've lost 20% in one way or another. In the best of cases, it could mean gains in productivity if it allows you to attract better developers.
What do you think? I assume we can agree that a four day work week for thought workers would not necessarily translate into getting only 80% of the value they would normally output. I'm more interested in hearing what gains or drawbacks you can see in having employees take personal programming Fridays, or something like it.
For those who disagree with the idea entirely, what if we restrict it to open source projects the company utilizes in day-to-day work? What if we restrict it to projects the company can use as infrastructure or turn into products (as I understand Google's to work)? Would you feel better about it then?
Posted by Sam on Mar 24, 2011 at 10:36 AM UTC - 5 hrs
Motivation
I recently decided to cut the cord on cable and downloaded PlayOn to do the job of serving video content from the internet to my Xbox 360 and Wii, so I could watch it on my TV. Naturally, this led me to figure out how it worked, and how I could play around with it.
One thing I immediately wanted to do was improve the organization functionality. I thought I'd start with a plugin that simply takes the media server's location of video output and provides it as input back to the same server, but in a different organization scheme. Unfortunately, that didn't work as PlayOn didn't know what to do with its own URIs as input for a VideoResource in the Lua plugin API.
I didn't want to get into the scraping, transcoding, and serving of files from the internet -- that's already done well and I didn't want to spend all that time creating a media server of my own. But I did want to see better fastforward and rewind capability. To solve that, I thought I'd create a DVR for PlayOn (or TVersity, or any other media server really) and knock out both the organization features I wanted, along with the seek functionality.
Launching a business
This will be my first attempt at launching a money-making venture online (aside from programming for other people's money-making ventures). I don't expect this will turn into a full-time job, nor do I expect I'll make retirement money off of it, but I think it can make a decent return that won't require a ton of ongoing work on my part, and it might make a fun experiment.
Just as well, I thought it could make for some interesting blogging for me, and reading for you. Here's how I plan to begin:
I'm starting with a simple landing page that asks for your email address, telling potential customers we'll let them know when it's ready. Cost: $22.00 or so for the .net and .com domains. Email list is free to start out at MailChimp, and I'll only need to pay them if I generate more than 500 signups and want to email those folks (which of course, I will).
The reason behind the landing page and email list is to gauge interest before I start. Right now I've only tested the technological feasibility of my idea by trying out all the moving parts needed to make it work. It's not all in one code base (some of it isn't even code), and there's no UI to speak of.
If there's a decent amount of interest, then I'll put it all together with an easy to use interface, and I'll probably devote more time to it in the short run. If it looks like me and my tech savvy friends will be the only users, I'll probably still release it, but you might configure it with text files instead of WinForms until I get sick of doing that and build the UI for it later down the line. I'm pretty sure that would be a free version. =)
So by going the landing page + email list route, I only invest a little time and money up front, until I can see what the demand will be like. I seem to remember hearing that dropbox started similarly, and I'm sure I must have heard this tactic mentioned a hundred times on Mixergy, where Andrew Warner interviews entrepreneurs about how they've been successful (and sometimes not-so).
On to pricing: I'm thinking of initially starting it out at a one-time fee of $35 (US), but that may change. More than likely, I'll test different pricing schemes and see what works well. I've got $105 of credit in Google Adwords, and I thought I might use that to do some A/B testing on the signup page. Half of the users would see Test which A might mention the one-time $35 price point, while the other half see Test B, which may be $5 per month. Hopefully, this would inform us as to which one results in more signups to the email list.
However, I decided not to do that at this point. It's just more up front work that has to be put into the idea. Instead, I'll probably wait to see if anyone signs up for the list, then do something similar to test which pricing options are better than others (using the email list instead of the website).
As I mentioned above, the DVR is not ready for public consumption yet, but you can sign up for the email list on MediaServerX if you want to be notified when it's ready.
If this little business experiment generates any action on my part aside from "well that flopped, I give up," I'll keep you updated here on the blog.
Deciding on technology
At first I thought I might like to really dig deep and write something from scratch, so the world was open for me to be cross platform and there were flowers in the fields with unicorns and rainbows.
However, after taking a look at the UPnP spec documents, I realized I didn't really care about that rainbow and what I really wanted was to just write some code.
It seemed like the lowest barrier to entry, which is something I haven't heard in a while about programming and Microsoft.
Code
First I created a solution in Visual Studio and included a reference for the UPnP 1.0 Type Library (Control Point). It can be found by right-clicking on References, then clicking on Add Reference. It's under the COM tab.
To start out doing anything, you can find a UPnP device using the UPnPDeviceFinder class. The code below will find all devices listed as MediaServer:1 (there are also :2 and :3, but I have yet to look into the differences between them).
UPnPDeviceFinder deviceFinder = new UPnPDeviceFinder();
UPnPDevices mediaServerDevices = deviceFinder.FindByType("urn:schemas-upnp-org:device:MediaServer:1", 0);
foreach (UPnPDevice mediaServerDevice in mediaServerDevices)
{
// do something with the UPnPDevice
}
The basic object model consists of a Device Finder (seen above) which can get you a collection of individual devices. Individual devices have a collection of services. A service is what you need to communicate with to control and get information from the device. (Here is a diagram).
In our case, we want to get the MediaServer's ContentDirectory service to give us a list of ContentDirectories and their children.
Now that you have the content directrory service, you can invoke actions on it. For example, to see what it contains you can use the browse service:
string browseFlag = "BrowseDirectChildren"; // BrowseDirectChildren or BrowseMetadata as allowed valuesstring filter = "";
int startingIndex = 0;
int requestedCount = 1000;
string sortCriteria = "";
object[] inArgs = newobject[6];
inArgs[0] = objectID; // use 0 for root
inArgs[1] = browseFlag;
inArgs[2] = filter;
inArgs[3] = startingIndex;
inArgs[4] = requestedCount;
inArgs[5] = sortCriteria;
object outArgs = newobject[4];
cdService.InvokeAction("Browse", inArgs, ref outArgs);
object[] resultobj = (object[])outArgs;
string result;
int numberReturned;
int totalMatches;
int updateID;
result = (string) resultobj[0];
numberReturned = (int)(UInt32) resultobj[1];
totalMatches = (int)(UInt32) resultobj[2];
updateID = (int)(UInt32) resultobj[3];
This where it really starts to get wieldy. I find it a complete PITA to be sending and receiving basic objects and casting them back and forth to their desired types. The result string ensures more fun searching through XML to get what you want. It's nothing we want to be doing throughout our source code, because it's a ton of noise to sort through.
Side note: Setting the objectID to 0 will get you the root element. After that, the results report back their IDs so you can use what it returns. That took me forever to find out, so hopefully it will save you some time.
Obviously, this sort of hassle calls for some abstraction, so I began writing a wrapper library. So far it works through everything I've shown above, and includes a sample project showing how to use it.
It's a Visual Studio 2008 solution with 2 projects: the upnplib-mediaserver-wrapper is the library, and example-upnp-mediaserver-browser is an example of how to use the library. You'll need to set that one up as your startup project for it to run. I'd have guessed it would be in the .sln file but it's not, and I don't want to include my user-specific settings in the source control.
Let me know if you're interested in seeing it become more complete.
Posted by Sam on Feb 26, 2011 at 06:53 PM UTC - 5 hrs
I'm writing a Client of FooServer which is reliant upon a rather clunky library whose functionality I'd like to encapsulate in a wrapper library to make the usage less clunky.
My first thought is to choose FooServer as the name of what will likely be the most used class in the library. That way, when I want to get some property of the server or tell it to perform some action I can do something like:
That seems innocent enough. But my fear is that by calling the class FooServer, it may violate the principle of least surprise because it does not fully implement a Foo server, nor would it be of use in implementing a Foo server.
I also dislike tagging it with "Wrapper" or something of the sort, because reading that in the client code doesn't seem right either.
I know I'm probably over-thinking it, but names are important to me, because they are the start of clean, readable code that does what it says and says what it does. So that's why I come to you, dear reader.
Of course, you could just click the edit button in your database management studio of choice and achieve the same functionality.
SELECTDISTINCT'script/generate scaffold '+ t.name +' '+ column_names
FROM sys.tables t
CROSS APPLY (SELECT c.name +casewhen max_length >255then':text'else':string'end+' 'FROM sys.columns c
WHERE c.object_id = t.object_id
ORDERBY c.column_id
FOR XML PATH('')) dummy_identifier ( column_names )
A similar discovery was made in the 1930's. One important difference to note is that, since my program does not simulate the input on it's output program, I am able to achieve speeds that are logarithmically faster than what Turing could accomplish.
Posted by Sam on Jun 16, 2010 at 11:06 AM UTC - 5 hrs
It seems easy to add an if statement the first time you need to deal with a difference between legacy data and new data models. It's still easy the second and third times.
Certainly it's easier than transforming the legacy data to fit the new schema.
Induction doesn't hold though. At some point, it becomes a tangled mess of code that has to deal with too many conditions and your mental model of it turns into total disarray.
This is one case where laziness and instant gratification can steer you in the wrong direction. Avoid the spaghetti; just transform the old data like you should have in the first place.
It might have been obvious to me before then, had I paid attention to my own thoughts and actions. Instead,
it took a little prodding and the knowledge that others experienced the same things I did to get me thinking about it.
The more you have to remember, the worse decisions you make
In the episode, hosts Jad Abumrad and Robert Krulwich relate a story from
Baba Shiv at the Stanford School of Business,
whose research has to do with the brain and tricking people.
In one experiment, Shiv has subjects memorize a number (taking as much time as they want), then
go to another room and recite the number.
Some people only have to memorize a two-digit number, while the others are supposed to remember a seven-digit one.
The trickery comes in when the researchers interrupt the subjects on the way to the second room:
"Excuse me? Sorry to interrupt you, but would you like a snack?"
The research subjects are then asked to choose between chocolate cake or fruit salad for their snack.
The results show those who only need to remember two digits almost always choose the fruit, while the
seven-digit club nearly always choose the cake.
The pair also discuss Barry Schwartz's book, The Paradox of Choice,
that Scott Davis spoke about in this aforementioned keynote, and about which I wrote in 2007:
He [Scott Davis] told a story (I believe to be from the book) that succinctly showed what happens when consumers are presented with too many choices: Given 3-5 options for tasting Jellies/Jams, customers ended up buying more of it. However, increasing that to two-dozen left sales at levels lower than having no sampling at all.
We simply become overwhelmed by the number of options available, turn off, and refuse to make a choice at all. That leads us to the Maximizer/Satisficer concept, where the Maximizers are especially prone to analysis because they try to be more prepared when making decisions and never stop analyzing, even after making the choice. On the other hand, satisficers try to narrow their decision-making points down to a reasonable few.
When my to-do list is unordered and contains too many items, I often revert to the infamous analysis paralysis;
the too-many-things-to-remember causes the poor decision of making no decision. (I am working on some software to relieve me
of this feeling, but more on that some other time).
More powerful programming languages make programs shorter. And programmers seem to think of programs at least partially in the language they're using to write them. The more succinct the language, the shorter the program, and the easier it is to load and keep in your head.
Choosing quickly versus Deliberating
In the same Radiolab episode, the hosts visit Berkeley Bowl
and encounter the "too many choices" dilemma. In choosing an apple each, Jad deliberated as Robert
just chose on his first gut instinct.
The problem behind the kind of choice we make when we have too many things to choose from is that it
short-circuits our prefrontal cortex - the rational, deliberative system in our brains.
We can only hold so much data at a given moment, and when we encounter encephaloverlow, the emotional, unconscious, automatic
part of our brain takes over.
Trying to make that choice brings us back to the maximizers vs. satisficers bisection mentioned above:
in deliberating all of the options behind a series of choices, the maximizer is often less satisfied with his choice.
In general, I'm that guy; and I can say without a doubt that the decisions I'm most happy with are the ones I make in an instant.
Complete rationality leaves you nowhere. Feelings are what makes decisions work.
In the Radiolab episode that inspired this post,
Antoine Bechara, a psychology professor at USC
tells the story of Elliot, a man who became completely rational after having a tumor removed from his brain. He had no mental impairment
that anyone could detect, but he had an impossible time deciding between the simple things in life: whether to use a blue pen or a black one; or which
cereal to eat in the mornings.
Neither feelings nor emotion seemed to play any part in Eliott's decision-making, and he could never decide on anything.
He ended up divorced, losing his job, and losing his life savings. After he became entirely rational, his life fell apart.
This segment shows us that gut feelings are shorthand averages of past wisdom, a theme Andy Hunt discusses in
Pragmatic Thinking and Learning:
L-mode is the analytical, rational process in our brain, but
We want to use R-mode more than we have because the R-mode
provides intuition, and that's something we desperately need in
order to become experts. We cannot be expert without it.
The Dreyfus model emphasizes the expert's reliance on tacit knowledge;
that's over here in the R-mode as well. Experts rely on seeing and
discriminating patterns; pattern matching is here too.
Justifying choices makes you choose pop culture.
The implication here is that pop culture is bad in some respect. That's not necessarily the case, but
when, as Malcolm Gladwell explains about the "perils of introspection," you have one group overwhelmingly
choosing this poster
over this one,
you might have a problem of the high-cultural taste variety.
It turns out, those who had to justify their choice were the ones choosing the precursor to the LOLcat. (And as Gladwell points out,
the scary part is that we ask our focus groups to explain their choices, and what we have left to purchase is what they favored.)
In that vein, I try not to think too hard about my programming. I don't mean to minimalize it - after all, programmers are
wizards who
But at the same time, I believe
there are no best practices - only better practices in particular contexts.
And those "best practices" are often the stuff of pop culture programming legend.
You know - those message board posts that tell you "don't do that" instead
of answering your question? Yeah, I know you know them. I love those almost as much as the ones that tell me "that can't happen" after I've
been trying to find out why the hell it just did.
Even though having too many choices can cause you to make bad decisions - and the wide-open-world of programming has infinitely many choices -
you need to find and focus-in on the decisions worth making. It's quite alright to have shortcuts that help you narrow down the
options to choose from. Given the evidence, it seems like a good idea.
But let the R-mode part of your brain and your expertise be the guiding factor in your choice in eliminating extraneous options, not a
reliance on pop culture. If you have to stop to justify your decision, it's likely you're
reverting to the pop-culture decisions that have you appreciating charlatans over masters of their craft.
How have you noticed choice impairing you as a programmer? How has it enabled you?
Posted by Sam on Jul 16, 2008 at 12:00 AM UTC - 5 hrs
When I was studying practice test questions for
Exam 70-431 last week, the
type of questions and answers I read led me to the thought that certifications attempt to
commodify knowledge and use it in place of thought.
More...
Not that this is a novel concept. I've always held a bit of disdain in my heart for certifications. Just as well,
it seems like most of the IT industry agrees with me (or, at least those elite enough to be writing
on the Internet).
After that, I wanted to find out what people thought about certifications in general. I didn't expect that almost
everyone would be
talking about how
worthlessthey are.
Nearly everyone questions their legitimacy.
But now, "We're settling into a pattern where a relatively small percentage of IT workers will need a certification to work in the area that they're in."
One of those areas is high-end IT architecture, and there are several certs that are profitable, in his view. They include the architecture-related certs offered by Cisco, Oracle, Microsoft, IBM, and EMC.
A certification like one of these can make or break a job interview.
Any hint that companies are de-emphasizing the technical certification process is troubling, because it could so easily have a negative effect on professional standards. I'm as big a believer as anyone in the importance of on-the-job training and real-world experience, but that doesn't begin to obviate the need for a formal certification program.
In a world where risk management and business continuity planning are essential pursuits for any healthy IT organization, every asset needs to be defined and monitored, and that includes technical skills. There's no better way to accomplish that than through a consistent, well-conceived means of documenting who has what skills. And that means certification.
Certainly if a certification helps you
get a job, it is monetarily worth it, whereas if it doesn't, then it's not. Just as well, some employers
want to see certifications while others do not. Some potential clients desire business partners to
be certified in the technologies that interest them. Others don't care.
So let's forget about "worth" as a measure of dollars for a moment.
Is it possible that conventional wisdom is wrong? Is it possible certifications can be worthwhile, personally or professionally?
It's simple to see that certifications are only worth the legitimacy conferred upon them by the community
as a whole. If the larger community sucks as much as we often say it does, that doesn't bode well for
certifications among elites. But the fact that so many people are making so much money in the certification
industry says that the community at large gives respect to the process.
So why do we see so many people questioning that process? (We see the same phenomenon in questioning
the value of a university degree, to be fair.)
The weak might bitch because they're lazy. The elite think they're above it, and that the tests focus on
too low a common denominator, if not the lowest. What about the rest of us?
I wasn't terribly excited after having passed the exam I took on Saturday. I certainly didn't feel like I
was a changed man. I know it helps out our company in becoming a Business Intelligence
partner of Microsoft, but I was less than enthusiastic.
Since, according to Microsoft, candidates for the exam should be experts in "wizard usage," I thought
I was an expert in Wizardry.
My reaction was a bit tongue-in-cheek. In fact, I do feel I learned something from the process - at
the minimum I had to know much more about scaling and back-up schemes than I would have known before-hand.
So I feel it was personally valuable in those respects.
Still, part of me feels the certification process is an attempt to commoditize knowledge and use it in place of thought.
So now I'll turn it on you:
Do you have any certifications? (Why, or why not?)
How do you feel about certifications? Why do you feel that way?
Today we'll start looking at the "Maintaining Your Edge" section of the book.
More...
Chad starts off by explaining what can happen if you get too comfortable: Tiffany.
Not that Tiffany, this one:
Do you remember a pop star named Tiffany (no last name) from the 1980s? She was in the top of the top forty, and a constant sound on the radio back then. She enjoyed immense success, becoming for a short time a household name.
...
Apparently, if she tried, she didn't move fast enough to hold the affection -- or even the attention -- of her fans. When the tastes of the nation turned from bubble gum to grunge, Tiffany suddenly became obsolete.
The point remains: you need to stay sharp. You cannot sit back and become complacent. Doing so in this industry can cause you to become extinct. And you'll probably be less famous than Tiffany or the Dodo. However, Didus ineptus may end up describing you well.
One thing you can do to stay sharp is recognize that, relative to information growth, your knowledge and skill levels are deteriorating rapidly. The consequences of what Gordon Moore observed in 1965 is that new possibilities for computation arise at an astounding rate.
That graph looks linear, so what's the big deal? Look at the left - it's logarithmic scale. That graph really looks like this:
That slope is so high it's almost negative.
You can't keep up with everything - but you can't afford to be late to the party when it comes to new trends in development either. If you were a desktop application programmer in 1992 and didn't look up until 2002, you'd probably say a few WTFs, and then start drowing in all the information you'd need to get started programming web applications. There's a lot to learn in new paradigms.
So you need to anticipate changes. You might not be able to jump the gun on the next big thing, but at worst you'll have augmented your arsenal, and you can stay close to other trends as well. Reading blogs and staying current in news and even journals can help you find new, up and coming developments. Thinking about how things will change and backing your hypotheses up with evidence from the literature can be a worthwhile activity in that regard.
Looking ahead and being explicit about your skill development can mean the difference between being blind or being visionary.
Know that you'll be obsolete. Don't accept obsolescence.
How do you deal with the pressure to stay current? What new things are you learning?
Posted by Sam on Jul 30, 2008 at 12:00 AM UTC - 5 hrs
I put faith in web application development as an income source like I put faith in the United States Social Security system. That is to say, it's there now, but I don't expect to be able to rely on it in its current incarnation very far into the future.
Java is mainly used in Web applications that are mostly fairly trivial. If all we do is train students to be able to do simple Web programming in Java, they won't get jobs, since those are the jobs that can be easily outsourced. What we need are software engineers who understand how to build complex systems.
Although Dewar was speaking in terms of Java, the statement applies to the broader world of web apps (and many desktop apps) in general.
That property is precisely what allowed frameworks like Rails and Django to come into existence and get popular.
Soon enough, the money will dry up for implementation because it's too easy to generate solutions for most problems you'll encounter - either using a framework, or a content management system like Sharepoint or Joomla, or even by hiring someone to generate it for you. Yesterday I recommended a potential client just go the CMS route.
Nowadays, most of the skill involved in writing web applications amounts to gluing the disparate pieces together. How long until someone figures out how to commoditize that? Instead of knowing only how to implement solutions to problems, you need to be skilled at problem solving itself.
Right now, you might be in a position where you can kick back and count your money while you smoke a cigar.
But if you're in the business of building web applications and you're not innovating new kinds of them, you're doomed. You can chase vertical after vertical and keep building the same apps for quite a while, but if you don't get into generating them, you're on the way out as people come in who can do it cheaper than you and with higher quality.
Generation is to web apps as prefabricated steel buildings are to construction. Except almost no one cares if their web application was generated or not - they just want the lower price.
I suspect that even if you are generating applications, at some point in the future, the number applications needing to be generated will not have grown as quickly as the number of people who can generate them.
People are building complex data warehouses and doing analysis and reporting on them with GUIs and Wizards right now. You still need the knowledge pertaining to data warehouses, but that knowledge is becoming easier to obtain for more people with less effort than ever before. That trend, which fits in with the general trend of information democratization, is unlikely to reverse itself.
If you don't plan for change now, you'll end up shocked.
And then how long until you're pulling out the cloth-eared elephant?
What Dewar said is true: Web applications are mostly fairly trivial. To survive,
you need to learn the fundamentals so you are applicable in various kinds of programming and for different platforms. If you really want to be safe, you need to be innovating, not building copy-cat applications with a twist (and especially not from scratch?!?!).
Every programmer should also read Chad Fowler's "My Job Went To India" book, where he explains that as larger and larger numbers of programmers adopt a particular skill, that skill becomes more and more a commodity. Rails development becoming a commodity is really not in the economic interest of any Rails developer. This is especially the case because programming skill is very difficult to measure, which - according to the same economics which govern lemons and used-car markets - means that the average price of programmers in any given market is more a reflection of the worst programmers in that market than the best. An influx of programmers drives your rates down, and an influx of incompetent programmers drives your rates way the fuck down. (Bold emphasis mine)
The problem, in my view, is that the influx of incompetent programmers is inevitable.
So building well-known applications with twists becomes much like the would-be artist who looks at Pablo Picasso's work and says, "I could do that."
The obvious exception is that applications are not (usually) like art. Well-made knockoffs of the original aren't likely to be differentiable by customers from the cheap knockoffs, so the masses of incompetents and maybe the original end up defining the market in the long term.
After you've seen it, you could do this:
To which we all respond, "But you didn't, did you?"
As always, I welcome your thoughts in the comments below.
For one, if I'm right, it's something which no one wants to hear. Further, if what I said is correct, and it's a novel concept, most people will not yet be of that opinion. Backlash would occur naturally. On top of that, there's always the possibility that what I said is completely asinine.
Despite my expectations of imminent flaming, however, the people who responded raised some excellent points, which I'd like to address here, taking the opportunity they presented to clarify my initial thoughts.
First, it would be helpful to answer the question, "what do I mean when I say 'mostly fairly trivial?'"
Mostly: Most web applications. Fairly: For each web application included in "mostly," it is trivial to a reasonable degree.
Put together, I would say "most parts of of most web applications are trivial."
I must have spent too much effort putting the focus on application generation, because by far, the biggest objections were there:
Barry Whitley noted,
The be-all end-all self building framework/generator has been the holy grail of software development since its inception, and it isn't really much closer to achieving that now than it was 20 years ago.
Along those same lines, Mike Rankin brought up CASE tools:
Anybody remember CASE (Computer Aided Software Engineering)? It was sold as the end of software development. To build an application, a layperson would just drag and drop computer generated components onto a "whiteboard" and connect them up by drawing lines. CASE was THE buzzword in the late eighties. 20 years later, it's nowhere to be found.
Software development will become a complete commodity the moment business decides to stop using their systems as a way to gain a competitive advantage.
To be clear, although I believe some applications can be entirely generated, I don't pretend that anywhere near most of them can. However, I do think that most parts of most web applications fall into that category.
Getting back to programming-by-wizard, at one point (very early) in (what you might call) my career, I programmed in G. This consisted mostly of connecting icons in what amounted to creating ridiculously complex flowcharts.
I think that's close to what many people envision as the "programmer killer" when they hear someone saying there will be one. But having used that style for a couple of months, I can issue my assurances that won't be it.
In fact,
as Mike said, since competitive advantage dictates businesses will continue innovating processes that will need to be codified in software, it's guaranteed there will always be software to write.
It's not a question of whether there will be software to write - it's a question of how much of it is there to go around for how many programmers, what skill-level those programmers need to be at, and what those applications will look like and run on.
Whereas a decade ago a team of programmers might have built an application over several months, we're at a point now where a single programmer can build applications of similar scope in days to weeks. We've even got time to add all the bells and whistles nowadays.
Within an application, we need fewer programmers than we did in the past. To stay employed, you need to learn how to use the tools that abstract the accidental complexity away, in addition to learning new types of things to do.
Barry puts it well:
As for the skills required, I'd actually argue that the workplace is demanding people with MORE skills than ever before. There is a lot of crap work for sure, and that market is dying out. For companies that want to be serious players, though, the demands are higher than they've ever been.
Indeed. That's what I'm talking about. The repetitive tedious stuff is going to be generated and outsourced. But there are shitloads of people still doing the tedious stuff. And there are shitloads of capable programmers who can glue the rest of it together.
We don't even need to get into the discussion of what will supplant the web and the number of jobs that will need to move around. The marketplace won't support us all at our high salaries. To be around in the future, you're going to need to do a better job of coping with change than the mainframe and green-screen programmers who won't find a job now. You're going to need to be capable of picking up new technologies, and the knowing the principles behind them will help you do it. Knowing how to build and design complex systems to solve complex problems is where you'll need to be. This is in contrast to being given specs and translating them into the newest fad-language. That's what professor Dewar was getting at, and that's what I'm getting at.
I don't expect most of the readers here will need to worry. Not because of anything I've done, necessarily, but because it seems like most of you embrace change.
To be fair, it may be more enjoyable, but it might not be as profitable - at least that's what Chad Fowler talks about in this week's chapter from My Job Went to India, "Make Yourself a Map."
Staying sharp is hard to do. It's easy to get into "maintenance mode," becoming comfortable with where you're at, and staying there. While maintaining your health may be a fine thing to do, simply maintaining your current skill set means you'll become the next Javasaurus. By that I don't mean you'll be big, bloated, and intimidating. I mean when all you know is Java the language, and Java's no longer the language du jour, you'll go the way of the dinosaur (to borrow an often used cliché). When it comes to technological matters, you fall behind if you're not actively keeping up.
Your personal product road map is what you use to tell whether you've
moved. When you're going to the same office day in and day out, working
on a lot of the same things, the scenery around you doesn't change. You
need to throw out some markers that you can see in the distance, so you'll
know that you've actually moved when you get to them. Your product
"features" are these markers.
Unless you really lay it out and make a plan, you won't be able to see
beyond the next blip on the horizon. In Chapters 2 and 3, you discovered
how to be intentional about your choice of career path and how to invest
in our professional selves. Though I focused on what seemed like a onetime
choice of what to invest in, each choice should be part of a greater
whole. Thinking of each new set of knowledge or capability as equivalent
to a single feature in an application puts it in context really well. An
application with one feature isn't much of an application.
What's more, an application with a bunch of features that aren't cohesive
is going to confuse its users... A personal product road map can not only
help you stay on track, constantly evolving, but it can also show you the
bigger picture of what you have to offer...
While it's definitely OK to learn diverse skills -- it expands your thinking --
it's also a good idea to think about the story your skill set tells. (Bold emphasis applied by me.)
For a couple of vacations I've taken in the past, I spun a pen on a map and drove to where it pointed the same night (up to 15 hours away). So far, my career map looks the same: as if a monkey tossed darts at a bunch of options and I decided to follow whatever the darts landed on.
I'm mostly a web developer - in the sense that I derive most of my income, write most of my code, and spend most of my time writing code that will in some way show up on the web or affect something that will show up on the web.
But I am also interested in, and spend significant time programming and studying artificial intelligence and machine learning, bioinformatics, and game development. I'm also interested in business for the sake of business (though I only occasionally write about it here). I enjoy writing desktop software as well (though I rarely have done so).
AI and game development dovetail nicely with each other. There are a lot of similarities between and overlap in algorithms for bioinformatics and AI. But short of creating a bioinformatics game on the web, it's hard to imagine where all these skills and interests intersect.
Perhaps it would be better for me to try and create a coherent picture out of the skills I choose to learn. But I rather enjoy having my hands and mind roam freely.
How's your skill set? Is it too focused, where you might need some breadth, or do you have a bit of a programmer dissociative identity, where some cohesion could take you a long way?
I need an MP3 library. Instead of seeing that there's no file to load, wouldn't it be great if the editor
tried to find it?
All that needs to happen is that we have an index that checks for includes and references. If it doesn't find
it in the standard library or any installed libraries, it goes to the index to find possible matches. If there's
only one, it downloads it and continues. If more than one exists, it might ask you which one you want
to download and include.
This isn't limited to Ruby. In fact, I'd love it more in Java and .NET. I can't count the number of times
on those platforms where I've looked up how to do something, only to be denied by the fact they didn't mention
the appropriate package or namespace to use.
Automatic Parallel Programming
Around the same time, I also thought it would be nice to have compilers and interpreters decide when concurrency
would be appropriate:
This can get really tricky. In fact, we don't really want it to be automagical detection. There
are some cases where it could happen, as far as I can tell. However, it's not worth the apprehension we'd feel if
we didn't know when the compiler or interpreter was going to do so.
But there are plenty of cases where it is possible. I've been in several of them lately. Even forgetting
about those -- Instead of
typing the boilerplate to make it happen, I really want something almost automagic:
Daniel mentions Google, "one of the most open-minded and developer friendly companies around," and points out that they have a strict limit in languages to use: Python, Java, C++, and JavaScript. He also says,
To my knowledge, this sort of policy is fairly common in the industry. Companies (particularly those employing consultants) seem to prefer to keep the technologies employed to a minimum, focusing on the least-common denominator so as to reduce the requirements for incoming developer skill sets.
We're afraid of being eaten by the poly-headed polyglot monster.
More...
Google avoids it by sticking to a limited set of languages. I don't work at Google, so I can't claim to know what their architecture looks like in terms of blending languages within applications. But the act of limiting languages does not in itself preclude polyglot programming. Choosing to limit yourself to one language, or one language per application, would do so. Likewise, choosing C# and Java as your languages would probably nullify most of the benefits. But the point is, just because you allow or encourage polyglot programming does not mean you let everyone choose whatever language suits them and then throw it all together in a melting pot, praying that everything works well together. You can have a method to sort out the madness.
In any case, what's going on with polyglotism, and how do we implement it?
Let's start with the impolite question: Should one really care about multilanguage support? When this feature was announced at .NET's July 2000 debut, Microsoft's competitors sneered that it wasn't anything anyone needed. I've heard multilanguage development dismissed, or at least questioned, on the argument that most projects simply choose one language and stay with it. But that argument doesn't really address the issue. For one thing, it sounds too much like asserting, from personal observation, that people in Singapore don't like skiing. Lack of opportunity doesn't imply lack of desire or need. Before .NET, the effort required to interface modules from multiple languages was enough to make many people stick to just one; but, with an easy way to combine languages seamlessly and effortlessly, they may -- as early experience with .NET suggests -- start to appreciate their newfound freedom to mix and match languages.
Even then, the web was all about polygot programming: we see ActionScript, JavaScript, XML, SQL, and #{favorite_application_server_language} already.
Applications of the future will take advantage of the polyglot nature of the language world. We have 2 primary platforms for "enterprise" development: .NET and Java. There are now lots of languages that target those platforms. We should embrace this idea. While it will make some chores more difficult (like debugging), it makes others trivially easy (or at least easier). It's all about choosing the right tool for the job and leveraging it correctly. Pervasive testing helps the debugging problem (adamant test-driven development folks spend much less time in the debugger). SQL, Ajax, and XML are just the beginning. Increasingly, as I've written before, we're going to start adding domain specific languages. The times of writing an application in a single general purpose language is over. Polyglot programming is a subject I'm going to speak about a lot next year.
Since Meyer's article, we have indeed seen an explosion of languages running on both "enterprise" platforms. Interest seems to have really grown recently. Because of that, it's getting easier to integrate languages. But as Neal Ford noted, we're still in the beginning (if you believe that paradigm is going to take hold).
The first layer is what I called the stable layer. It's not a very large part of the application in terms of functionality. But it's the part that everything else builds on top off, and is as such a very important part of it. This layer is the layer where static type safety will really help. ...
The second layer is the dynamic layer. This is where maybe half the application code resides. The language types here are predominantly dynamic, strongly typed languages running on the JVM, like JRuby, Rhino and Jython.
...
The third layer is the domain layer. It should be implemented in DSL's, one or many depending on the needs of the system. In most cases it's probably enough to implement it as an internal DSL within the dynamic layer, and in those cases the second and third layer are not as easily distinguishable. But in some cases it's warranted to have an external DSL that can be interacted with. A typical example might be something like a rules engine (like Drools).
Let's talk briefly about a web application, as I envision it using Ola's layers as a guide:
In the stable layer, you might be talking about a banking application where transactions are performed in Java. You might have some tool set that performs important calculations, and which other applications depend on. It might be the parts of the application that really need to perform well.
In the dynamic layer, you might have code that integrates the static and domain layers. You might have code which glues together other stuff, or things which don't really turn into bottlenecks for the application, which aren't necessarily part of the application domain, but which don't require the ceremony of the stable layer. You're choosing to use a dynamic scripting language to increase productivity. You might define the DSL abstractions here, and use them in the DSL/domain layer.
In the domain layer is where you'll see the meat of your application code- it's where all your business object abstractions will reside, and they will in turn depend on the other two layers. It should consist entirely of code that uses business language.
Ola may have meant something else entirely, or just slightly different, but that's the way I've come to see it. The concept is still new, so there's nothing saying that vision of a "best practice" design will win out over ad hoc solutions that throw modules written in different languages together to form an application.
How I'm Using Polyglot Programming
How am I using polyglot programming in my day-to-day programming? Aside from the JavaScript/AppLanguage/SQL web paradigm, there are a couple of ways I'm doing it.
In one of my jobs, we do a lot of work with Sharepoint. In fact, the bulk of the applications are built in Sharepoint: to manage documents, content, data and get all the integration with other Office products. However, Sharepoint is a beast. Often, doing something that would be trivial on another platform is an arduous task in Sharepoint. So we have to drop out of it.
In some cases, when we've needed the feature to reside within Sharepoint itself, we've opted to use C# within ASP.NET to create Sharepoint Web Parts. For the next one of these I come up against, I intend to look at using IronRuby and deriving from the appropriate parent classes.
In other cases, we're building stand-alone "sub-applications" that integrate with Sharepoint and Active Directory. For these, we have some utility classes written in C#, while the "sub-application" is built in Ruby on Rails. Soon, we'll be looking at running them on IronRuby, and taking further advantage of the .NET platform.
In my job with the bioinformatics lab at the University of Houston, things are a bit different. I'm building command line applications. After a machine takes photos of your DNA sample, there is an genome analysis pipeline from Illumina that analyzes the images, produces nucleotide sequences, and tries to align them to a reference sequence. That utilizes Perl, Python, and C/C++, though I don't know to what extent a in which "layers" each language does its job.
On my end, I'm using C++ to do the heavy lifting in analysis in proprietary libraries we've been producing to do our own analysis and post-analysis. When you're dealing with genome-size data sets, from 5 mega- to 3 giga-bases, even constant reductions in run-time can mean the difference of days of computation in algorithms with above-linear time complexity. But I'm also building scripts in Ruby that help piece it all together, and doing some analysis with it for linear-time algorithms. It's very ad hoc, in this instance.
Finally, my game development group plans to use C/C++ to forge our engine, while using a scripting language(s) to fill out the game details. As I understand it, much of the game industry already employs polyglot programming in this manner.
So that's how I'm doing it at the moment.
In 2008, the polyglot programming paradigm is still (at least in my opinion), a relatively novel concept. There aren't a lot of resources to show us how to do it the right way. As time moves forward and people publish their experiences, that should be expected to change.
On that note, do you have any stories about how you've done it, or any ideas on how you would if you were going to do it? Please feel free to share them - you'd be doing us all a favor.
Posted by Sam on Aug 22, 2008 at 12:00 AM UTC - 5 hrs
Some people call them fat pants. Some people call them stretch pants. Others might call them exercise pants or sweat pants. Whatever you call them, they're comfortable to wear. The problem with sweat pants is the reason they're comfortable is because they're big and expandable. And that expandability means they have a lot of room to accommodate growth as well.
More...
In fact, some people wear them when they know they'll be eating a lot, just for that purpose.
It's hard enough to know when you're getting fat - after all, you're you and it's a slow process, so you wouldn't notice unless your pants got tighter or you were reviewing your weight on the scale regularly.
It's even harder to notice when you're wearing sweatpants. You can go for years - growing and growing ...
And before you know it, you've not just beat anorexia, you've pwned it.
As with the other chapters in this section of My Job Went To India, "That Fat Man in the Mirror" boils down to refusing to let yourself become comfortable in where you're at personally (not geographically) as a programmer. In this case, you need to put away your programming skill fatpants, and periodically review your skills. Take an inventory. Better yet, have someone else evaluate you. Sweats may allow for growth, but it's not the good kind.
An easy way to measure your progress is to use a trusted third party. A
mentor or a close colleague doesn't live in your head with you and can
help give you a more objective look at where you stand. You might discuss
your abilities as a software developer, project leader, communicator, team
member, or any other facet of the total package that makes you who you
are. (Chad Fowler, pgs. 155-156 of My Job Went to India)
If you're a bit uncomfortable asking someone to help in that way, you should make
use of review-time at your company (if there's such a thing where you're at).
If your company has such processes in place already, don't write them off
as HR nonsense. Take them seriously and make good come out of them.
Keep it written down and revise and review often, Chad says.
That sounds like solid advice to me. I got started with some goals earlier in the year, and had planned to periodically review them here on the weblog. But that hasn't happened, so it's something which I need to put more effort into.
Don't get be lethargic about your skills. Instead, take off the fatpants and actively evaluate where you're at and where you need to be. Get some feedback. Otherwise, some day in the future you may end up wondering to yourself, "how did I lose my edge?"
Do you review yourself periodically? Have you used the reviews to become better?
Posted by Sam on Aug 29, 2008 at 12:00 AM UTC - 5 hrs
If you want to trap a monkey, it's not very hard. Hollow out a hole (in a coconut, the ground, or whatever)
just large enough for a monkey's hand to fit in when relaxed, but too small to pull out as a fist.
Put some food in the hole, and wait. Soon enough, a monkey will come, fall in love with the food, grab at it
and refuse to let go.
You see, monkeys value food higher than life or freedom, and their devotion to it will not allow them to let
go. Or so the story of the south Indian monkey trap goes.
(I am merely relating the parable, I have not actually tried to capture a monkey in this manner.)
More...
In My Job Went to India, Chad Fowler's final bit of advice for keeping sharp and
up to date urges us to not allow ourselves the mental security blanket of value rigidity - or the mental crutch,
as it often turns out to be. You might not even be aware you're using one yet.
Chad tells the story of Novell's decline:
Many of us in the mid-1990s swore by Novell's NetWare platform when it
came to providing ?le and print services in the enterprise. Novell was way
ahead of its time with its directory services product, and those of us "in
the know" were almost cocky in our criticism of competing technologies.
Novell's product was enjoying a healthy majority in market share, and it
was hard to imagine the tide turning.
No single event made it obvious that Novell was losing to Microsoft.
Microsoft never made that magic Active Directory release that made us all
say, "Wow! Drop NetWare!" But, Netware has slowly gone from bleeding-
edge innovator to legacy technology. For many NetWare administrators,
the water was boiling before they ever even realized the pot was warm.
By allowing yourself the comfort and ease of such a mental crutch, you're doomed to keep repeating what worked in the past, even if it's not the best solution today. Before you know it, your technology of choice is no longer the soup du jour, and you're stuck knowing nothing else.
Instead of blindly advocating your technology of choice -- no matter the absurdity of that solution in the
situation -- have "stong opinions which are weakly held."
Realize "it depends" is a valid answer to programming questions.
Posted by Sam on Sep 04, 2008 at 12:00 AM UTC - 5 hrs
Outsourcing is not going away. You can delude yourself with myths of poor quality
and miscommunication all you want, but the fact remains that people are solving
those problems and making outsourcing work.
As Chad Fowler points out in
the intro to the section of MJWTI titled "If You Can't Beat 'Em", when a
company decides to outsource - it's often a strategic decision after much deliberation.
Few companies (at least responsible ones) would choose to outsource by the seat of their pants, and then change their
minds later. (It may be the case that we'll see some reversal, and then more, and then less, ... , until an equilibrium is reached - this is still new territory for most people, I would think.)
Chad explains the situation where he was sent to India to help improve the offshore team there:
If [the American team members] were so good, and the Indian team was so "green," why the hell
couldn't they make the Indian team better? Why was it that, even with me
in India helping, the U.S.-based software architects weren't making a dent
in the collective skill level of the software developers in Bangalore?
The answer was obvious. They didn't want to. As much as they professed
to want our software development practices to be sound, our code to be
great, and our people to be stars, they didn't lift a finger to make it so.
These people's jobs weren't at risk. They were just resentful. They were
holding out, waiting for the day they could say "I told you so," then come
in and pick up after management's mess-making offshore excursions.
But that day didn't come. And it won't.
The world is becoming more "interconnected," and information and talent crosses borders easier than it has in the past.
And it's not something unique to information technologists - though it may be the easiest to pull-off in that realm.
So while you lament that people are losing their jobs to cheap labor and then demand higher minimum wages, also keep in mind that you should be trying to do something about it. You're not going to reverse the outsourcing trend with
any more success than record companies and movie studios are going to have stopping peer-to-peer file sharing.
That's right. In the fight over outsourcing, you, the high-paid programmer, are the big bad RIAA and those participating in the outsourcing are the Napsters. They may have succeeded in shutting down Napster, but in the fight against the idea of Napster, they've had as much strategic success as the War on Drugs (that is to say, very little, if any). Instead of fighting it, you need to find a way to accept it and profit from it - or at least work within the new parameters.
How can you work within the new parameters? One way is to "Manage 'Em." Chad describes several characteristics that you need to have to be successful with an offshore development team, which culminates in a "new kind" of
PM:
What I've just described is a project manager. But it's a new kind of project
manager with a new set of skills. It's a project manager who must act at
a different level of intensity than the project managers of the past. This
project manager needs to have strong organizational, functional, and technical
skills to be successful. This project manager, unlike those on most
onsite projects, is an absolutely essential role for the success of an offshore-developed
project.
This project manager possesses a set of skills and innate abilities that are
hard to come by and are in increasingly high demand.
It could be you.
Will it be?
Chad suggests learning to write "clear, complete functional and technical specifications," and knowing how to write use cases and use UML. These sorts of things aren't flavor-of-the-month with Agile Development, but in this context, Agile is going to be hard to implement "by the book."
Anyway, I'm interested in your thoughts on outsourcing, any insecurities you feel about it, and what you plan to do about them (if anything). (This is open invitation for outsourcers and outsourcees too!) You're of course welcome to say whatever else is on you mind.
Posted by Sam on Sep 12, 2008 at 12:00 AM UTC - 5 hrs
If we accept the notion that we need to figure out how to work with outsourcing
because it's more likely to increase than decrease or stagnate, then it would be beneficial for us to become
"Distributed Software Development Experts" (Fowler, pg 169).
To do that, you need to overcome challenges associated
with non-colocated teams that exceed those experienced by teams who work in the same geographic location.
Chad lists a few of them in this week's advice from
My Job Went To India (I'm not quoting):
More...
Communication bandwidth is lower when it's not face to face. Most will be done through email,
so most of it will suck comparatively.
Being in (often widely) different time zones means synchronous communication is limited to few overlapping
hours of work. If you get stuck and need an answer, you stay stuck until you're in one of those overlaps.
That sucks.
Language and cultural barriers contribute to dysfunctional communication. You might need an accent to accent
translator to desuckify things.
Because of poor communication, we could find ourselves in situations where we don't know what each other
is doing. That leads to duplicative work in some cases, and undone work in others. Which leads to
more sucking for your team.
The bad news is that there's a lot of potential to suck. The good news is there's already a model
for successful and unsuccessful geographically distributed projects: those of open source.
You can learn in the trenches by participating. You can find others' viewpoints on successes and
failures by asking them directly, or by reviewing
open source project case studies.
Try to think about the differences and be creative with ways to address them.
Doing that means you'll be better equipped to cope with challenges inherent
with outsourced development. And it puts you miles ahead of your bitchenmoaning colleagues who end
up trying to subvert the outsourcing model.
There are plenty of potential solutions out there, but none of them worked for me. I would get the scrolling working, and then the
draggable would move away from the cursor. I'd get it in sync with the mouse cursor and the scrolling would get crazy again.
I'd fix that and then no matter where I dropped it, if the div had been scrolled, dropping would fail.
Here's how I fixed the problem:
In the Draggable#updateDrag function (~ line 356), on the first line, I changed the value of the pointer argument to
take into account how much the container had scrolled:
pointer = new Array(pointer[0] + this.options.scroll.scrollLeft, pointer[1] + this.options.scroll.scrollTop);
At least one of the solutions I recall seeing mentioned this.
In the same function, I changed the first two elements in the p array before the last two elements get
pushed onto it:
p = new Array(p[0] + this.options.scroll.scrollLeft, p[1] + this.options.scroll.scrollTop);
This also just takes into account how far the container has been scrolled.
To ensure my droppables were able to receive the draggables given the adjusted coordinates, we need to adjust the
scroll position just as we did above. First, I adjusted the code in my webpage that produces the droppables and
added a scroll parameter that should be the name of the element that scrolls (the same parameter the draggable accepts):
Since Droppable elements don't generally take a scroll option, we'll need to modify that code in Scriptaculous's dragdrop.js
file as well. In the Droppable#fire function (~ line 109) add the folling lines under Position.prepare();:
var point = [Event.pointerX(event), Event.pointerY(event)];
if(this.last_active.scroll){
point[0] += $(this.last_active.scroll).scrollLeft;
point[1] += $(this.last_active.scroll).scrollTop;
}
Finally, just underneath that where it calls this.isAffected, change the first parameter from
[Event.pointerX(event), Event.pointerY(event)] to use the variable we created above, pointer.
That should be it. If you've tried the above and still get problems, feel free to leave a comment below, or
contact me and I'll do my best to help out.
I haven't submitted a patch because I didn't check to see that this was a general solution. It seems like it should be, but
without testing it outside my intended usage, I don't think it'd be accepted anyway. Quite frankly, I'm not thrilled about
adding a new option to droppables, but it seemed like the simplest route to fix my problem at the time.
Yes, I tried setting includeScrollOffsets to true and using Position#withinIncludingScrolloffsets
in Prototype, and that failed for me too.
Posted by Sam on Mar 05, 2010 at 10:14 PM UTC - 5 hrs
You might think that "tech support" is a solved problem. You're probably right. Someone has solved it
and written down The General Procedures For Troubleshooting and How To Give Good Tech Support.
However, surprisingly enough, not everyone has learned these lessons.
And if the manual exists, I can't seem to find it so I can RTFthing.
The titles of the two unheard of holy books I mentioned above might seem at first glance to be
different tales. After all, troubleshooting is a broad topic applicable to any kind of
problem-solving from chemistry to mechanical engineering to computer and biological science.
Tech support is the lowliest of Lowly Worms for top-of-the-food-chain programmers.
(And don't ask me how sad it makes me feel that my favorite book as a kid has only a 240px image online. I need to find my copy and scan it.)
But just like its more enlightened brethren, tech support consists of troubleshooting. In fact, it should be
the first line of defense to keep your coders coding and off the phone. Who wants them to man the phones?
Certainly not the programmers. Certainly not management. Tech support is a cost center, not a customer
service opportunity.
Perhaps when you have a virtual monopoly over a market like most cable companies or utilities in a given locale,
you can afford to have poor customer service. The cable sphere seems to be opening up, what with satellite TV and internet
and now AT&T and Verizon offering television and decent-to-good internet packages.
Even still, AT&T's UVerse has its own problems, I've heard,
and (at least personally) I've not witnessed the kind of customer service that competition promises with regards to cable TV and internet access.
The fact is we tend to treat support like a second class citizen. It's a position we want to fill with a minimum-wage worker (or less, if we
can outsource it) who has no expertise, no clue, and doesn't care to learn the
product since he can get a job in the fast food industry at about the same rate. And with no stress!
It makes it worse that we don't even want to take the time to train him, since it would take away from the productive code-writing time to do so.
The person we want to treat as an ape or worse always seems expendable. We treat them so. Should they be?
I say no. Not only am I a big fan of dogfooding,
I feel like Fog Creek's
giving customer service people a career path nowadays
matches a lot of my ANSI artist peers' experiences
from back in the day. Smart people start in support, and they can move themselves up in the organization to play more "key roles."
I don't think it needs to be a full-time thing, but it certainly helps if programmers are their own support team.
Like Bruce Johnson who posted that linked message, I work on a small team and can vouch: it's downright embarrassing to have to support
our customers. I'm glad to do it, but when it happens, more than likely I've got to take blame for the problem I'm dealing with.
You know how hard I try to make sure my code works as expected before I deploy it?
"OMG I'm sorry, that's my fault, I'll fix it for you right away." Can you get better support than that?
I'm not so sure I'd have tried that hard without the customer experience pushing me.
I think I've made my first point: that customer support is customer service is important to the health of your business.
While I agree that tech support in the common use of the term is useful to shield your programmers from
inane requests, I also recognize the value in having programmers take those calls from time-to-time.
Given that, I do in fact have some do's and do-not's with regards to support. The list here deals mostly with
how to be a good support technician for your team, as opposed to the customer. Still, the customer is
central to the theory.
Although it does not make an exhaustive list, here are four contributions to The General Procedures For Troubleshooting:
After listening to the problem description, the first thing to do is recognize whether or not you can
solve the problem while the customer is on the phone, or if anyone can. If you can, then do it. If you think
only someone else can do it, and work for an organization that has multiple levels of live-support, then escalate it.
If you don't think solving the problem is possible without escalating it to a level of support that won't get
to it immediately, thank the customer for reporting the issue, let them know the problem is being worked on,
and boogie on to step 2.
As support, the first thing you need to do before escalating the issue is confirm there is an issue, and do it with a test account, not the user's.
It's ridiculous to ask for the user's
credentials. Don't do it. If someone were to ask you, "What is your username and password?" what would you think?
The average user isn't going to know your query is tantamount stupidity, but if you get someone who is slightly
security-conscious, you're going to lose a customer. Hopefully, he's not a representative of your
whale.
If anyone found out that you're in the habit of asking users for their passwords, they can easily call anyone
who uses your software and get in by just asking. Further, since many people use the same password for everything
or many things, that person would also have access to your customers' other sensitive information, wherever it resides.
You can point the blame at your stupid customer for using the same password everywhere they go all you want. You're being
just as stupid by opening the door for that type of attack. Further, you should always try to recreate and fix the problem
with as little inconvenience to the user as possible. That means doing it with test accounts as opposed to asking the
user for theirs, or changing their information.
Keep things simple for the user. Don't jump immediately to using their time to make things easier on the support team.
Doing that is lazy at best, sloppy most of the time, and could result in disaster at worst.
After confirming the existence of the problem, provide the steps of how to reproduce it. Give some screen shots.
If it's a web app, provide links. Don't constantly send and email and ask the higher levels about it. Doing so once or twice is
one thing, but doing it for every request is a time-waster. Just send the email and the next level will get to it
when they can. If they don't get to it within the acceptable time-frame for your organization, send a reminder.
Include the boss if you need to. But don't do that prematurely (and that's another subject altogether).
Don't jump to conclusions about the source of the problem.
Although Abby Fichtner wasn't speaking
directly to support ...
... This is the opposite of my general approach. The parallel here is code : customer :: you : dumb2.
I've learned (even if through a bit of self-torture) that I should always look at the code first, if for no other reason than I don't
want to be foolishly blaming others when I'm to blame. In the case of support, I've always hated the term "User Error,"
and that's what the tweet reminds me of.
By framing it as an external problem, we miss an opportunity to teach the user how to use the product, or a chance to
improve the product to make sure they can't use it "incorrectly."
What are your thoughts about tech support? What can you contribute to The General Procedures For Troubleshooting?
2) "word1 : word2 :: word3 : word4" is SAT (and elsewhere) notation for
the analogy "word1 is to word2 as word3 is to word4." See freesat1prep.com
for a few examples.
Posted by Sam on Jan 03, 2010 at 03:09 AM UTC - 5 hrs
I've spent some time recently building a tool that makes my life a bit easier.
I've browsed plenty of Rails log analyzers that
help me find performance bottlenecks and potential improvements. But what I really need is a faster way to filter my logs to
trace user sessions for support purposes. Maybe it's just me, but I've got apps where users report problems
that make no sense, where their data gets lost, and who can't tell me what they did. Add to that
the fact that I've got the same app running on dozens of different sites, and you can see
why performance analyzers aren't what I'm looking for to solve my problem.
Because of that, I need a solution that lets me filter down and search parameters to figure out
what a particular user was doing on a certain date. Hence, Ties.
More...
What can Ties do?
Enter the path to a Ruby on Rails production log file, click the "Load Log" button and it reads in the file.
Then, choose from the years, months, and days of requests in that file. Tell Ties which controller, action, and URL you are interested in.
Finally, decide if you only want to see the log entries which contain an exception, enter a regular expression
to search the params, plus the output filename and click a button to filter the log entries you care to see.
Ties takes a many-megabyte Rails production log file and outputs only the entries you're interested in.
Keyboard Shortcuts: Shoes leaves it to the programmer to
implement keyboard shortcuts, so while familiar
actions like Copy (ctrl-C) and Paste (ctrl-V) are available
via the mouse, I have yet to implement them on the keyboard.
Error Handling: It's minimal. If you enter a non-existent file,
or non-Rails-production file, who knows what will happen?
Crazy web-of-a-graph: My intent is to build the data model
such that you can search most items in approximately O(1) time. Right now,
you drill down to the day in constantish time, and after that
it becomes linear search.
Testing on all platforms and Rails versions: I proudly certify
this version (0.1) WOMM.
That means I've only tested it on Mac OS 10.5.8 (Leopard), using straight log files from Rails 2.2 on Ruby 1.8.6 and 1.8.7.
That being said, Shoes is supposed to work on Windows and Linux as well, and I've not noticed any major differences
in the log files between Rails versions, so you might find it works great for you too. If not, I encourage you to
let me know and I'll fix it up quick for you. (Please have
a sample log file available if possible.)
nice_code, stupid_submitter - in which TheDailyWTF jumps the shark by ridiculing perfectly good code.
Let's forgive the misuse of the wornout phrase and get to whether or not looking at the code
should result in utterance of WTFs.
More...
It goes something like this:
Setup, in which we use globally shared memory
Negate the number if it is negative, for no reason I can think of, and set a reminder flag.
Set buffer to point to the final spot. Move it back one, dereference it, and insert the null string terminator there.
Move the buffer backwards. Dereference the pointer and set the value there to the character '0'. Add the remainder of the number divided by ten to that, since '1' is 1 away from '0', and so forth.
Divide the number by 10 so we can get to the next digit.
If we've done the loop 3 times, move the buffer pointer back one location and insert a comma.
Repeat starting at step 4 until the number is 0.
Cleanup - if the front character is a comma, remove it by moving the buffer pointer forward.
Cleanup - Move the buffer pointer backwards and insert our '-' if the negative flag has been set.
I felt like that required too much brain power to follow for doing something so simple. So I decided to make my
own version. I thought I'd try the following:
Copy the number to a string.
Starting at the end, copy each character to another string, inserting a comma every 3rd time.
A thousand times simpler than the convoluted mess of nice_num. Here's that attempt, in C:
I think it's clearer - but not by much. Certainly the variable names are better because you don't first
have to first understand what's going on to know what they are for. I think moving the pointer
arithmetic back into the more-familiar array notation helps understandability. And removing the trick of
knowing that the ASCII codes for '1' is 1 more than for '0' ... for '9' is 9 more than 0 means less thinking.
On the negative side, the commadify code is slower than nice_num, most of which is caused by using malloc
instead of having preallocated memory. Removing those two instances
and using preallocated memory shaves a couple of tenths of a second off of the one-million-runs loop. But
you have to compensate with more code that keeps track of the start position.
So what's the verdict?
I don't think we're reacting to the WTFs I mentioned above when we see the nice_num code.
I think we're reacting to C itself. We're so used to very high level languages
that common tricks and things you'd know as a C programmer are the WTFs to us.
This kind of stuff isn't outside the realm of what a strong programmer should know. It isn't even
close to the border. The truth is our low-level skills are out of practice and we should probably get some.
What do you think?
Code with main program and comparison with nice_num is available at my github repository, miscellany/commadify.
Update: Thanks to Dave Kirby's comment, I've fixed memory leaks and updated the code in this post and at the repository. Link to repo originally was to the specific commit - so I've changed that to link to master instead.
Posted by Sam on Dec 22, 2008 at 12:00 AM UTC - 5 hrs
This post might be better titled, "How (and how not) to help yourself when
Google doesn't have the answer: A whirlwind tour through Rails' source" if only I wasn't
too lazy to change the max length of the database field for titles to my blog entries.
Google sometimes seems as if it has the sum of all human knowledge within the confines of its search index.
It might even be the case that it does. Even if you prefer to think that's true,
there may come a time when humanity does not yet have the knowledge you are seeking.
How often is that going to happen? Surely someone has run up against the problems I'm
going to have, right? That hasn't been the case for me the last couple of months.
I may be the only developer writing Rails apps on MacOSX to be deployed to the world on Windows
where SQL Server 2008 is the backend to a Sharepoint install used by internal staff to drive the data. I'm
not so presumptious to think I'm a beautiful and unique snowflake, but I wasn't finding any answers.
More...
Before I started this trek, I made a commitment to leave after an hour if I found my attention
drifting toward something else. I never started checking email, reading blogs, or obsessively reloading
twitter to see my tweeps latest tweets, so I thought I was in the clear.
However, even though I felt like I was focused, the fact that I had been sitting at the computer for so
long contributed to poor decision making. The first of these was to keep searching Google even though
every search was coming up useless. I always followed the path of least resistance - even
if it wasn't going to get me to the goal quicker than an alternative path. If it was less challenging,
it was for me.
After a while, I ran out of mentally casual paths and resigned myself to tracing through
the source code (it is open source, after all, and this is one of the benefits everyone claims but
so few practice). It was what I knew I should have been doing as I started out, and I had wasted
several hours trying to tip-toe around it for the sake of my poor, tired brain.
Now that I was sure I had the right data type being returned, I needed to narrow down where the problem was
occuring. I knew SQLServerAdapter was using DBI to connect to the database, so I figured I'd use a
quick irb session to test DBI itself. The test came back negative - DBI was getting the correct
data. I also ran a quick test in the Rails app, reaching through ActiveRecord::Base to use the connection
manually. That worked, as expected.
I had thought, and now confirmed, that the best place to look would be SQLServerAdapter.
If it were a Rails problem, certainly someone would have run into it by now. So it made sense the problem would be in the interface
between Rails and Microsoft.
Why? Because if Rails is a Ghetto,
Rails with Microsoft products is a fucking concentration camp.
Excuse the profanity. I don't often use it here, so you know I must mean it when I do.
class << selfdef string_to_binary(value)"0x#{value.unpack("H*")[0]}"enddef binary_to_string(value)
value =~ /[^[:xdigit:]]/ ? value : [value].pack('H*')endend
But it wasn't obvious how it was being used elsewhere. I even tried using the reverse operations in my objects - to no avail.
And after searching in the source file, it certainly wasn't being called inside of SQLServerAdapter.
So I went on a quest for the answer inside /opt/local/lib/ruby/gems/1.8/gems/activerecord-2.1.1/
.
For quite some time I went back and forth inserting and removing debugging code between Active Record and
SQLServerAdapter. select(sql, name=nil) is a protected method defined in the abstract connection
adapter in Active Record. SQLServerAdapter implements it privately, and it was both getting and returning
the correct data.
After ActiveRecord calls object.instance_variable_set("@attributes", record) when instantiating our object,
object.attributes[binary].size becomes less than record["binary"].size. That was
the problem. I thought for sure instance_variable_set was a monkeypatched method on Object,
and that all I needed to do was issue a monkeyfix and all would be well.
Only I was wrong. It's there by default in Ruby, and Rails wasn't monkeypatching it (that I can tell).
All the sudden things started looking bleak. By this time I knew how I could fix it as a hack. I even
had a nice little monkeypatch for my objects that I could issue and
have it feel less hacky to be used. I had given up.
But for some reason I picked it back up after an hour and found that ActiveRecord was actually calling
that string to binary method in SQL Server Adapter. It allows them to register calls that should happen before
defining the read and write methods on the object. Excellent!
I opened up SQLServerAdapater, there it was: a differentbinary_to_string method
that totally explained it. The pair in this version were encoding and decoding the data to/from base 64.
That would work fine, if my data was going through the encoding part. But it wasn't - it was coming straight
from Sharepoint.
There's a comment in the code about some arbitrary 7k limit on data size from SQL Server
being the reason for encoding as base 64 before inserting the data. I don't know about
inserting, but retrieving works fine without it. If I could think of a way to distinguish,
I'd submit a patch for the patchwork. Ideally, I'd rather find a way around the restriction, if it
actually exists.
The original code I was looking at was on github. It (not surprisingly) differed from the code in use on
my machine. Another side effect of the 16 hour monitor stare.
It's called the 8 hour burn for a reason.
The only things burning after 16 hours are your brain from all the stimulants and your
wife, wondering WTF you're really doing because there's no way you're working from before
she wakes up until after she goes to bed.
What's the point?
There's two, if you ask me:
You have the source code. Look through it. You have no other choice when no one has had your problem,
and you might
benefit by doing so even if someone already has.
Even when you think you're focused working late, and resolve to leave when you lose the focus, you're
still going to make stupid decisions that you won't notice until the morning. I turned
a 5 hour journey into a 12 hour marathon. Sleep, FTW.
The list is not intended to be a "one-size-fits-all, every developer must know the correct answer to all questions" list.
Instead, Jurgen notes:
The key is to ask challenging questions that enable you to distinguish the smart software developers from the moronic mandrills.
...
This list covers most of the knowledge areas as defined by the Software Engineering Body of Knowledge.
Of course, if you're just looking for brilliant programmers, you may want to limit the topics to [the]
Construction, Algorithms, Data Structures and Testing [sections of the list].
And if you're looking for architects, you can just consider the questions under the headings
Requirements, Functional Design and Technical Design.
But whatever you do, keep this in mind: For most of the questions in this list there are no right and wrong answers!
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers, as if I had not
prepared for the interview at all. The format will first list the question, my initial response (to start
the discussion), followed by a place I might have looked for further information had I seen the questions
and prepared before answering them.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy.
More...
Requirements
Can you name a number of non-functional (or quality) requirements?
I'd first mention performance and security, from the user's perspective. I'd then mention meeting minimum
requirements for metrics like code coverage in testing and dependencies in our design. I don't consider
code quality out-of-order when it comes to requirements.
The non-functional requirements
page at Wikipedia lists several examples. Notable exceptions from my quickie-response: accessibility,
documentation, portability. There are several that are listed that I consider covered by what I've listed,
but I missed some that caused me to say
What is your advice when a customer wants high performance, high usability and high security?
My "advice" starts with the questions: "What do you consider X to be?" where X belongs to the set {"high performance",
"high usability", "high security"}. I might offer that I consider "high performance"
to be a misnomer, as it's either acceptable or not, and that unless the customer defines it, I don't
know how we'd even attempt to measure something as vague as "usability."
I'm not sure where I'd prepare for this question. Any suggestions are appreciated.
Can you name a number of different techniques for specifying requirements? What works best in which case?
I can name several: tell me in person, tell me over email, tell me over IM or
over the phone.
I know that's not what you're looking for. You're looking for answers like "use cases." It all boils down to the same.
I might even mention "unit tests" here. That's part of the spec, as far as I'm concerned, and for almost
any software I write for myself, it's the only way I specify requirements (except for maybe a very informal to-do
list).
Face-to-face works best in most cases, I'd gather.
The answer after doing some research: ¡Ay, ay, ay, no me gusta! I didn't see this coming. There are a number of things that could qualify as answers
(Prototyping, Storyboards, Modeling, ..., State transitions) that I knew about beforehand. I thought to include
none of them.
What is requirements tracing? What is backward tracing vs. forward tracing?
My response? "I don't know anything about requirements tracing. I'm willing to learn."
Which tools do you like to use for keeping track of requirements?
I generally use a combination of a text file and emails, as far as the client is concerned. If it's a larger
system, I'll use something like Sharepoint, Basecamp,
or another system that performs a similar function. I have no preferences, because nothing I've ever used
compares to a simple list. If it does, it's equally useful.
I don't know that I'd say I like any of them. In reality I prefer a simple to-do list that I encode in
tests (insofar as I'm capable of writing the tests) and knock them out one-by-one.
How do you treat changing requirements? Are they good or bad? Why?
I don't give a value judgement on changing requirements: they are inevitable. They can be good or bad depending on
how the client handles them.
I always try to let the client know: I can do X amount in Y timeframe. You asked for Z total.
Here's an estimate for each item in Z, pick X from it for our current Y timeframe. I'll get back to you every Y timeframe to show a demo,
and you can choose X from the remaining Z again (with changes based on circumstances if required). Feel free
to fire me when you have enough out of Z that's functional. (Ok, I probably wouldn't say the last sentence in those
terms, but I'd find a way to say it, if for no other reason than to sell them the rest of the process.)
As far as looking it up before the interview: I've review Agile literature. Searching any of the agile yahoo groups
for the question at hand ought to be good enough.
How do you search and find requirements? What are possible sources?
"What do you mean?" would be my response. I really don't know. What does searching and finding requirements mean?
Does it mean figuring out how to do requirements that I don't know how to accomplish?
How do you prioritize requirements? Do you know different techniques?
I rarely prioritize requirements. I let the customer decide. I give them a relative cost of implementing
X requirement vs. implementing Y requirement, and let them decide. If Y requires X, then I tell them
so.
I know of different techniques - take "random" for example. I don't know what they might be called. But I
cannot think of anything better, even if it were decreed as a Top 10 Commandment for Prioritizing Requirements.
No web search for this comes to mind. I'd review a couple of process management books if I had no clue.
This seems to be a decent discussion,
if you must have one from me from a cursory browse.
Can you name the responsibilities of the user, the customer and the developer in the
requirements process?
The user will be the person using the software, versus the customer being the one who pays for its development.
I hate that distinction. The developer programs it. Responsibilities? In my ideal organization, I'd have:
Developers working with the Customer to manage requirements.
Developers working with the User to make the application work for them regardless of the Customer (I've
seen too many projects where the User had to use whatever the Customer purchased, even
if the purchase was ... little yellow bus-ish.)
Customer/User having daily meetings with the developer
Developer making the best software he/she can given the constraints.
Again, I don't know where I'd look this up before being asked. Suggestions (again, as always) are most welcome.
What do you do with requirements that are incomplete or incomprehensible?
I send an email saying "I don't understand what you mean. Please read the very small attached book
and get back to me."
Just kidding, of course (at least in most cases. I've been recently tempted to send that exact email, as it happens.)
I just ask them to clarify. If I don't have contact with the customer, I ask the intermediary to clarify or
get clarification.
Outside reading: Agile, and hopefully other processes for some compare and contrast.
I think these are decent answers to start a discussion with. If you're a hiring manager, what do you say? Would you show me the door, or keep me around for a while longer?
It's not quite as hard as Steve Yegge's list
of things to know (I'll get to that eventually), but it's a good (and more well-rounded!) list nevertheless.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not
prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy.
My lack of understanding the angle from which these questions come may influence other seemingly off-base
answers. Help me out by explaining how you might answer these questions on functional design:
More...
What are metaphors used for in functional design? Can you name some successful examples?
I hate to start the first one off with an IDK,
but what else can you do? I feel like I can talk intelligently about
some of the issues involved in functional design, but until now, I never realized it was a process unto itself,
nor did I know what all it entailed until after I browsed the remaining questions.
How can you reduce the user's perception of waiting when some functions take a lot of time?
Show a progress bar. Distract them with something they need to read or stage data-collection/interaction with the user.
Of course,
the obvious yet overlooked answer here would be to make the offending functions faster. At
worst, if the function doesn't require user interaction at all, you could spawn a new thread to do the work
in the background and let the user continue working. Then they'd notice no waiting at all.
Reading: I picked this up from observation and deduction. I don't know where I'd go to read such information.
Which controls would you use when a user must select multiple items from a big list, in a minimal amount of space?
What controls do I have to pick from? Can the list be grouped by some recurring values? For instance, consider
how the iPod uses the scroll wheel to let you navigate a long list of music. Now apply finding one song to
finding several, and you have an idea of what I'm talking about.
Another option might be to have auto-complete, with a special key for "add to list" when you're satisfied, which
puts you back at the beginning of the text box. Another key would end the sequence.
Can you visualize the list in some way? The user could then click pictures to drill down and roll up on items
in the list, viewing it from different levels. For example, if the list was of colors,
you could take the typical color-picker from every image program out there, and use it to choose your list.
Reading: I came up with these on the spot, and can't say I've seen them completely implemented yet,
so again, when it comes time for advice on where to read up on this topic, I've got nothing.
Can you name different measures to guarantee correctness of data entry?
Aside from the pains of torture? You'll definitely want a fast-acting validation to let the user
know as soon as possible that you think their input is incorrect. When talking about the web, you'll
want to validate it server side as well. You'll want to show some examples if you need a certain format
of input (or just if the customer expects to be forced into a format, you'll want to relieve their anxiety
by providing an example). Finally, make the user type as little as possible, except if you're doing a progressive
lookup / autocomplete on their typing.
Reading list is vacant. Please advise.
Can you name different techniques for prototyping an application?
At first, I didn't realize there were different techniques. Unless we were talking about storyboards vs.
mark-up-only or a shell of an application. I don't imagine that was the point.
I did find something that I think was the point: for reading, Scott Ambler has a take from a different point of view: tips and techniques
in user interface prototyping that includes another list of resources. A treasure trove!
Now that I know what we're talking about, I'd have given similar answers. I feel I could have been effective
in a conversation about this, but the other party would have had to lead me that direction. I couldn't get
there from the question alone.
Can you name examples of how an application can anticipate user behavior?
Analyze it and look for patterns. Use a Markov Model to predict next action based on previous N actions.
That's the only way (well, there are variation on the same theme) I can think of that an
application would do it. We could of course observe the users and make changes ourselves. I don't think
that would be a bad idea.
Reading is nonexistent. Those ideas came from elsewhere, but never as part of functional design.
Can you name different ways of designing access to a large and complex list of features?
There's the outmoded File/Edit/View tree menu controls (find link to discussion), ribbon interfaces,
and
progressive search, or autocomplete.
I'd also consider re-purposing my answers to #3.
How would you design editing twenty fields for a list of 10 items? And editing 3 fields for a list of 1000 items?
For the latter, I'd almost certainly put them all in one page. Or 100+ at a time. The fewer clicks the better.
It's worth importing from a spreadsheet every time, if that's an option.
For the former- Can the 20 fields be broken down into more cohesive units? Twenty fields in one form is often too many.
10 forms is not absurd, on the other hand.
What is the problem of using different colors when highlighting pieces of a text?
The highlight color can make the text hard(er) or downright impossible to read. Anything else?
I don't see room for discussion, unless you're flashing the colors -- then you might get into causing
epileptic seizures in those susceptible to them.
Can you name some limitations of a web environment vs. a Windows environment?
Access to the file system. Lag mainly - less responsive experience for most of web than on Windows.
As you can tell - while some of these questions are ones I've thought about in the past, or touch themes on others
that I do - I haven't thought about functional design as a process by itself.
So in that regard I ask,
Do you have any pointers?
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
Do you know what a regression test is? How do you verify that new changes have not broken existing features?
You answered the second part of the question with the first: you run regression tests to ensure that
new changes have not broken existing features. For me, regression tests come in the form of already written tests,
especially unit tests that I've let turn into integration tests. However, you could write a regression test
before making a new change, and it would work as well.
The point is that you want to have some tests in place so that when you inevitably make changes, you can ensure
they didn't cascade throughout the system introducing bugs.
How can you implement unit testing when there are dependencies between a business layer and a data layer?
Generally I'd let that unit test become an integration test. But if the time to run the tests was becoming
too long, I'd build a mock object that represented the data layer without hitting the database or file
system, and that would be expected to decrease the running time significantly.
Which tools are essential to you for testing the quality of your code?
I don't know if anything is essential. If you've got asserts or throws, you
can always implement testing yourself, and a good eye for bad code helps as well. That said, to reduce
psychological barriers
to testing, it would be nice to have tools already made for this purpose.
Luckily, we have such tool available: unit testing frameworks and static code analysis tools in your language of choice.
What types of problems have you encountered most often in your products after deployment?
Most recently I've encountered very specific integration errors, and written about some ideas on
fixing the polysystemic testing nightmare.
Do you know what code coverage is? What types of code coverage are there?
Generally I'd thought it refers to the percentage of code covered by tests. I don't know what
the second question here refers to, as I thought it referred exclusively to testing.
Do you know the difference between functional testing and exploratory testing? How would you test a web site?
I have to admit that before being asked this question, I wouldn't have thought about it. My guess is that
functional testing refers to testing the expected functionality of an application, whereas exploratory
testing involves testing without knowing any specific expectations.
As far as testing a web site, I'll have plenty of unit tests, some acceptance tests, perhaps some in
Selenium or a similar offering, as well as load testing. These aren't specific to web apps, however, except
for load testing in most cases.
I'm very interested in feedback here, given my misunderstanding of the question. If you can offer it, let me
thank you in advance.
What is the difference between a test suite, a test case and a test plan? How would you organize testing?
A test suite is made up of test cases. I'm not sure what a test plan is, aside from the obvious which the
name would suggest. As far as organizing testing: I tend to organize my unit tests by class, with the method
they test in the same order they exist within that class.
What kind of tests would you include for a smoke test of an ecommerce web site?
Again, here's another where I didn't know the terminology, so having to ask would result in demerits, but
knowing the answer of "what is a smoke test?" allows us to properly answer the question:
In software testing, a smoke test is a collection of written tests that are performed on a system prior to being accepted for further testing.
In that case, I'd click around (or more likely, write an application that could be run many times that does the same thing,
or use that application to write Selenium tests) looking for problems. I'd fill out some forms, and leave others blank.
Ideally, it would all be random, so as to find problems with the specs as often as possible without actually
testing all the specs, since the point seems to be to give us a quick way to reject the release without
doing full testing.
What can you do reduce the chance that a customer finds things that he doesn't like during acceptance testing?
The best thing to do is to use incremental and iterative development that keeps the customer in the
loop providing feedback before you get down to acceptance testing. Have effective tests in place that
cover his requirements and ensure you hit those tests. When you come across something you know
won't pass muster, address it even though it might not be a formal requirement.
There are undoubtedly underhanded ways to achieve that goal as well, but I'm not in the habit of going
that direction, so I won't address them here.
Can you tell me something that you have learned about testing and quality assurance in the last year?
Again I'm going to reference my polysystemic testing nightmare,
because it taught me that testing is extremely hard when you don't have the right tools at your disposal, and that
sometimes, you've got to create them on your own.
As far as reading goes, I'd start with literature on TDD, as it's
the most important yet underused as far as I'm concerned.
Posted by Sam on Jan 12, 2009 at 12:00 AM UTC - 5 hrs
I like to use descriptive variable names, and I try to err on the side of more-descriptive if I think there's
any chance of confusion. contract_participants isn't terribly long, but if you're building
up all of its members from different sources (i.e., you can't really loop over it), it can get cumbersome
to type and worse, to read. Moreover, it's different from just "participants" and they certainly
aren't "contracts," so shortening it in this case wasn't going to happen.
More...
Unfortunately, unlike some languages, Ruby doesn't have such a construct. Fortunately, it does have
the facilities to create one. I thought there was already an implementation, but I couldn't find it at
first. So I started to write my own.
For some reason I was looking through Utility Belt and noticed
it had an implementation of with():
class Object
def with(object, &block)
object.instance_eval &block
endend
Unbelievable! My implementation was running into a WTF in its own right, and here was this one-liner.
With was created as a result of those efforts. It
works how I want it to in the simple cases I've demonstrated. It still needs some work on left-hand-side
variables that are not members of the aforementioned @foo. It needs some tests for
more complex uses like nested blocks (and
code to make them pass). But it works for what I imagine the majority usage would be.
I opted for the syntax With.object(foo) do ... end so as to not force you to use a
change to Object. However, you can require 'with_on_object' if you prefer
to just use with(@foo). There's also a conditional patch on NilClass if
empty? does not exist. It is added and removed in the same method.
It requires Ruby2Ruby and ParseTree
to do its magic, though that will change soon due to compatibility problems with Ruby 1.9 and other implementations
(for which another project exists, if I've read correctly).
Posted by Sam on Jan 27, 2009 at 12:00 AM UTC - 5 hrs
Being a programmer, when I see something repetitive that I can automate, I normally opt to do so.
We know that one way to save your job is by
automating, but another is to know when not to automate. It sounds obvious, but when you get
into the habit of rooting out all duplication of effort, you can lose sight of the fact that sometimes, it costs more
to automate something than to do it by hand.
More...
I came across such a situation the other day.
.
In this case I was working with static content on a website that wanted to go dynamic. It wasn't just a case of
writing a spider to follow all the links and dump all the HTML into a database - there was some structure to the
data, and the database would need reflect it.
In this case, there was a hierarchy of data. For simplicity's sake, let's say there were three levels to the tree:
departments, sections, and products. At the top we have very few departments. In the middle, there are several
sections per department. And there are many products in each section.
Each level of the hierarchy is different - so you'll need at least three spider/parser/scrapers. Within each level,
most of the content is fairly uniform, but there are some special cases to consider. We can also assume each
level requires roughly the same amount of effort in writing an automaton to process it's data.
It's natural to start at the top (for me, anyway -- you are free to differ), since you can use that spider to
collect not only the content for each department, but the links to the section pages as well. Then you'll
write the version for the sections which collect the content there and the links to the products. Finally, you get
to the bulk of the data which is contained in the products. (And don't forget the special cases in each level!)
But that's the wrong way to proceed.
You ought to start at the bottom, where you get the most return on your investment first. (Or at least skip the top
level.) Spidering each level to collect links to the lower levels is exceedingly easy. It's the parsing and special
cases in the rest of the content that makes each level a challenge.
Since there are so few cases at the top level, you can input that data by hand quicker than you can write the automation
device. It may not be fun, but it saves a few hours of you (and your customer's) time.
Posted by Sam on Feb 11, 2009 at 12:00 AM UTC - 5 hrs
What's with this nonsense about unit testing?
Giving You Context
Joel Spolsky and Jeff Atwood raised some controversy when discussing quality and unit testing on their Stack Overflow podcast (or, a transcript of the relevant part).
Joel started off that part of the conversation:
But, I feel like if a team really did have 100% code coverage of their unit tests, there'd be a couple of problems. One, they would have spent an awful lot of time writing unit tests, and they wouldn't necessarily be able to pay for that time in improved quality. I mean, they'd have some improved quality, and they'd have the ability to change things in their code with the confidence that they don't break anything, but that's it.
But the real problem with unit tests as I've discovered is that the type of changes that you tend to make as code evolves tend to break a constant percentage of your unit tests. Sometimes you will make a change to your code that, somehow, breaks 10% of your unit tests. Intentionally. Because you've changed the design of something... you've moved a menu, and now everything that relied on that menu being there... the menu is now elsewhere. And so all those tests now break. And you have to be able to go in and recreate those tests to reflect the new reality of the code.
So the end result is that, as your project gets bigger and bigger, if you really have a lot of unit tests, the amount of investment you'll have to make in maintaining those unit tests, keeping them up-to-date and keeping them passing, starts to become disproportional to the amount of benefit that you get out of them.
Joel was talking about people who suggest having 100% code coverage, but he said a couple of things about unit testing in general, namely the second and third paragraphs I quoted above: that changes to code may cause a ripple effect where you need to update up to 10% of your tests, and that "as your project gets bigger ... [effort maintaining your tests] starts to become disproportional to the amount of benefit that you get out of them."
One poster at Hacker News mentioned that it's possible for your tests to have 100% code coverage without really testing anything, so they can be a false sense of security (don't trust them!).
Bill Moorier said,
The metric I, and others I know, have used to judge unit testing is: does it find bugs? The answer has been no. For the majority of the code I write, it certainly doesn't find enough bugs to make it worth the investment of time.
He followed up by saying that user reports, automated monitoring systems, and logging do a much better job at finding bugs than unit tests do.
I don't really care if you write unit tests for your software (unless I also have to work on it or (sometimes) use it in some capacity). I don't write unit tests for everything. I don't practice TDD all the time. If you're new to it I'd recommend that you do it though -- until you have enough experience to determine which tests will bring you the value you want. (If you're not good at it, and haven't tried it on certain types of tests, how else would you know?)
The Points
All of that was there to provide you context for this simple, short blog post:
If changing your code means broken tests cascading through the system to the tune of 10%, you haven't written unit tests, have you?
(Further, the sorts of changes that would
needlessly break so many unit-cum-integration tests would be rare, unless you've somehow happened or tried very hard to design a tightly coupled spaghetti monster while writing unit tests too.)
I've not yet met a project where the unit tests are the maintenance nightmare. More often, it's the project itself, and it probably doesn't have unit tests to maintain. The larger the code base, with large numbers of dependencies and high coupling, the more resistant it is to change - with or without unit tests. The unit tests are there in part to give you confidence that your changes haven't broken the system when you do make a change.
If you're making changes where you expect the interface and/or behavior to change, I just don't see where the maintenance nightmare comes from regarding tests. In fact, you can run them and find out what else in your code base needs to change as a result of your modifications.
In short, these scenarios don't happen enough such that they would make testing worthless.
You may indeed write a bunch of tests that don't do anything to test your code, but why would you? You'd
have to try pretty hard to get 100% code coverage with your tests while succesfully testing nothing.
Perhaps some percentage of your tests under normal development will provide a false sense of security. But without any tests whatsoever, what sense of security will you have?
If you measure the value of unit testing by the number of bugs it finds (with more being better), you're looking at it completely wrong. That's like measuring the value of a prophylactic by the number of diseases you
get after using it. The value is in the number of bugs that never made it into production. As a 2008 study from
Microsoft finds [PDF], at least with TDD, that number can be astonishingly high.
As for user reports, automated monitoring systems, and logging doing a better job at finding bugs than unit testing: I agree. It's just that I'd prefer my shipped software to have fewer bugs for them to find, and I certainly don't look at my users as tests for my software quality once it's in production.
Posted by Sam on Mar 03, 2009 at 12:00 AM UTC - 5 hrs
A while ago, I was working with a problem in C# where where our code would get deadlocked, and since someone must die or several must starve, I thought it
would be nice to just toss a "try again if deadlocked"
statement into the exception handler. I muttered this thought on twitter to
see if there was any language with such a try-catch-try-again-if construct.
More...
A couple of my tweeps responded with what we we're used to using: loops.
Another two mentioned redo in Ruby.
redo is certainly a cool construct (and underused), but it doesn't do what I want
it to:
beginraise from_the_dead
rescueredoend
Ruby responds, "tryredo.rb:35: unexpected redo." As you might know, you need to use a loop:
Suppose I have a zombie who only really likes eating braaaiiinzzz. Most of the time, he gets exactly
what he wants. But every so often, we try to feed him some other body part. Now, if he's really hungry, he
eats it. We might only have fingers available at the time, so I want
to try to feed him fingers again until brains are available or until he's hungry enough to eat the fingers.
I know that conceptually this is just a loop even if we don't explicitly code it. But does your language have a
try again? What do you think the merits or demerits of such an approach would be? Is it just a harmful
goto?
My zombie is hungry and waiting. Rather impatiently I might add.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
How do you make sure that your code can handle different kinds of error situations?
I write tests that describe the expected error situations and check to see that they are handled appropriately.
If the software is legacy and prone to generating exceptions, I'll wrap it up to report the exceptions
to get an idea of what needs attention first, and start attacking it there. Of course where required,
we'll use try/catch.
Mostly I try to follow the rigorous WOMM development process.
Can you explain what Test-Driven Development is? Can you name some principles of Extreme Programming?
TDD: Red, Green, Refactor. You write a test that specifies some behavior the code should produce. Run the test
to make sure it fails. Write code to make the test pass, then run it to make sure it passes. Change the
code as needed to improve its design.
XP: Aside from testing, we want to continuously review code through pair programming, maintain sustainable
work conditions with sane work-weeks, and continually integrate our code to reduce the time we have to
spend working out kinks in that process. There's more, but those are a few.
Reading: Xprogramming.com is a good starting point.
The associated lists (TDD and XP) on Yahoo Groups are great for discussion. It's probably worth reading
a book or two on the subjects. I'd recommend Kent Beck or Ron Jeffries.
What do you care about most when reviewing somebody else's code?
Does it say what it's doing, and do it correctly? Is it readable?
Reading: As with most of these questions, Steve McConnell's Code Complete 2 is an outstanding
resource on the subject. If you don't read anything else, read that.
When do you use an abstract class and when do you use an interface?
I'd use an abstract class when I want to provide some implementation for reuse, but where some
also remains to be specified by the inheriting class. An interface is useful for multiple inheritance
in languages that don't allow it, as well as a decoupling device - allowing you to depend on
interfaces that don't change as often as implementations might.
Reading: Books on OO design are useful, especially those targeting static languages like Java.
Apart from the IDE, which other favorite tools do you use that you think are essential to you?
Continuous integration tools, testing frameworks, (some people might include dependency injection
frameworks), scripting languages, the command line, source control, ... What else would you include?
Reading: McConnell's aforementioned book, The Pragmatic Programmer,
Practices of an Agile Developer,
tons of blogs that talk about the tools they use to make themselves more productive, and (although
I've only seen the presentation and not read the book), Neal Ford's The Productive Programmer
probably contains some useful items.
How do you make sure that your code is both safe and fast?
The question seems to imply these goals are normally at odds. I haven't felt that way. I'd program for
security first, and then if it's slow, I'd try to identify the bottleneck and then find a way to improve
its time complexity. If the algorithm is already at its lower bound for time complexity, I'd move on to
micro improvements, like moving variable creation and function calls outside of loops.
When do you use polymorphism and when do you use delegates?
I don't have any hard and fast rules. I rarely need to use polymorphism since I
primarily program in dynamic languages that make it unnecessary. (I guess it's still polymorphism, but you're not
doing anything special to achieve it.) When I have been in static languages, I'll implement
the methods that accept different types as needed to make client code more friendly to work in. If we're
actually building an API for public consumption, then obviously we have to move from "as needed" to
a more aggressive schedule.
I'm at a loss for a better answer to this question, because (surprisingly to me) I've not thought about it before now.
When would you use a class with static members and when would you use a Singleton class?
I don't know how to answer this except for "when the situation calls for it." I'd normally opt for
the class with static members when it makes sense to do it. As far as a proper Singleton, I don't know
that I've ever written one that enforces that property. More often, if I need just one, I only create one.
Can you name examples of anticipating changing requirements in your code?
I write unit tests, so that helps with changing requirements. How? It helps keep the design very modular to
allow for extension and easy changes, and the tests themselves provide assurance I haven't broken anything
when I do need to make a change.
I don't generally go leaving hooks and pre-implementing code that I think will be needed. YAGNI
helps guide me in that regard.
Can you describe the process you use for writing a piece of code, from requirements to delivery?
Requirement -> unit test -> code -> run tests -> commit -> run tests -> deploy.
I think that explains it all, and explaining each step could be a blog post or more of its own.
My basic advice on how to prepare for this section of questions is: Read and internalize
Code Complete 2.
I should probably read it again, in fact.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
More...
This week's answers are on a topic I've been wanting to explore more in depth here lately: algorithms (though it doesn't go into as much detail). I'll
wait until the end to give reference information because all of this post relies on experience, but there
are two sources where I'd start learning the information for every question. Trying to keep the post
DRY and all.
How do you find out if a number is a power of 2? And how do you know if it is an odd number?
To find out if a number is a power of two, you can divide by two until the number is 1 or odd. If the number is odd
at any point before you reach one, the number is not a power of two. To find out if a number is odd, I'd normally
take number mod 2 and see if the result is 1 or not (1 would mean the number is odd). If performance
is a concern and the compiler or runtime doesn't optimize for mod 2, you could use a bit mask that
checks if the smallest bit is set or not. If so, the number is odd. If not, the number is even.
Here's an example with the bit mask:
def even? n
n == n & 0b11111111_11111111_11111111_11111110
end
n =512while even?(n) && n > 1do
n = n >> 1endputs n==1
Note you'll need a large enough bit mask to cover the size of the number in bits.
How do you find the middle item in a linked list?
If it's important to be able to find the middle element, I'd keep a pointer to it. If it's implemented using an
array and it's important, we can store the array length and divide by two. If it's implemented using pointers to
elements, we can iterate over the list while counting its length, then iterate from the beginning until we get
halfway there. We could also take the size of the structure in memory and divide by two, going straight to that
element by adding 1/2 the size to the pointer, but that'd be a mighty WTF to most programmers when trying
to understand it.
How would you change the format of all the phone numbers in 10,000 static html web pages?
Not by hand if I could avoid it. I'd write a regex that matches any of the known formats in the set of pages
and use a language with a function that replaces based on a regular expression find.
Can you name an example of a recursive solution that you created?
I was creating a pattern enumeration algorithm in an effort to statistically identify potentially important
subsequences in a given genome. The more immediate goal was to identify Rho sites
in a set of bacterial genomes. Since we wanted to identify any potential pattern, the form needed to be general,
so a variable depth was required and we used recursion to achieve this. (This is a job interview, so I tried to
think of the most impressive sounding example from the last year I could think of.)
Which is faster: finding an item in a hashtable or in a sorted list?
Item retrieval is basically O(1) in a hash table, while O(log n) in a sorted list, so the hash table is faster on
average.
What is the last thing you learned about algorithms from a book, magazine or web site?
I guess it depends on what you'd consider learning. For instance, I recently looked up
merge sort to use as reference in writing a sorting
algorithm for a custom data structure, but I wouldn't say I "learned" it there. If you take "learning" as
being introduced to, it was in a course at school or via a book.
How would you write a function to reverse a string? And can you do that without a temporary string?
In most instances I'd be working with a language that already implements a reverse method for strings.
If not working in such a language, and I'm using a temporary string, the problem boils down to iterating backwards
over the given string, and assigning tempstring[realstring_length - i] = realstring[i]. If we restrict
the usage of a temporary string, then we can just use a variable to store the current character for swapping:
for(i=0; i<len; i++) {
lowerchar = realstring[i];
realstring[i] = realstring[len-i-1]; // -1 for 0 based arrays
realstring[len-1] = lowerchar;
}
What type of language do you prefer for writing complex algorithms?
I prefer very super extremely high level languages (to distinguish from VHLL)
that tend to be dynamic. The reason is that, in using them, I don't have to worry about low level details
that might otherwise get in the way of understanding the algorithm. After that, I'll normally have to implement
the same algorithm in a lower level language and take care of the details I could otherwise ignore, because
normally performance is going to matter when developing that complex algorithm.
In an array with integers between 1 and 1,000,000 one value is in the array twice. How do you determine which one?
I'd insert each value as a key in a hash and when the key already exists, I know we've hit the duplicate. This
gives us O(n) time complexity, which I'm sure could be proven to be the lower bound.
Do you know about the Traveling Salesman Problem?
Yes, it's famous. The problem asks us to find the shortest path that visits every node in a graph.
Posted by Sam on Mar 12, 2009 at 12:00 AM UTC - 5 hrs
SOAP can be a huge PITA in Ruby if you're not dealing with a web service that falls
under the defaults. In particular, if your web service falls under
HTTPS where you need to change the default
certificate acceptance, or if you need to authenticate before seeing the
WSDL, you're SOL as far as I
can tell as of writing this post. (If you know of a way that doesn't resort to this complexity, please speak up!)
I was using Ruby 1.8.7 and soap4r 1.5.8, but this may apply to other versions.
Anyway, here are a couple of monkey patches to help get you there if you're having trouble.
More...
If you need to change the SSL verify mode, for example, to accept a certificate unconditionally, you can use this
monkeypatch:
Hope that helps someone else avoid days' long foray into piecing together blogs posts, message boards, and
searching through source code.
And because you might get here via a search for related terms, normal access that only requires basic authentication
could be done like this, without opening existing classes:
I'm very welcoming of suggestions regarding how these things might be better accomplished. Resorting to this
messy level of monkeypatching just sucks. Let me know in the comments.
(Link is to abstract page, quote is from the PDF linked to from there, chart below is from the paper as well)
More...
Further research needs to be carried out to see if this generalizes beyond the Windows Vista team.
Needless to say, it's not a license to write crapcode, as those metrics are still good predictors of software defects, but it's interesting to note just how important organization is to software quality.
Posted by Sam on Mar 12, 2009 at 12:00 AM UTC - 5 hrs
SOAP can be a huge PITA in Ruby if you're not dealing with a web service that falls
under the defaults. In particular, if your web service falls under
HTTPS where you need to change the default
certificate acceptance, or if you need to authenticate before seeing the
WSDL, you're SOL as far as I
can tell as of writing this post. (If you know of a way that doesn't resort to this complexity, please speak up!)
I was using Ruby 1.8.7 and soap4r 1.5.8, but this may apply to other versions.
Anyway, here are a couple of monkey patches to help get you there if you're having trouble.
If you need to change the SSL verify mode, for example, to accept a certificate unconditionally, you can use this
monkeypatch:
Hope that helps someone else avoid days' long foray into piecing together blogs posts, message boards, and
searching through source code.
And because you might get here via a search for related terms, normal access that only requires basic authentication
could be done like this, without opening existing classes:
I'm very welcoming of suggestions regarding how these things might be better accomplished. Resorting to this
messy level of monkeypatching just sucks. Let me know in the comments.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
This week's answers about data structures are complementary (indeed very intertwined with) last week's questions about algorithms.
Also like last week, I'll
wait until the end to give reference information because all of this post relies on experience, but there
are two sources where I'd start learning the information for every question.
How would you implement the structure of the London underground in a computer's memory?
Without having travelled to London or on its subway system, I'd guess a graph would be the right
data structure. The set of vertices would represent the stations, and the edges connecting them would
be the tracks.
Not safe for work (language):
I don't know the proper in-memory representation of tramps.
How would you store the value of a color in a database, as efficiently as possible?
Efficiently for retrieval speed, storage speed, size? I'm guessing size. After asking why such efficiency is
needed, and assuming we're talking about a range of up to 166 colors (FFFFFF), I'd just store it as the smallest
integer type where it would fit.
What is the difference between a queue and a stack?
A queue is typically FIFO (priority queues don't quite follow that)
while a stack is LIFO. Elements get inserted at one end of a
queue and retrieved from the other, while the insertion and removal operations for a stack are done
at the same end.
What is the difference between storing data on the heap vs. on the stack?
The stack is smaller, but quicker for creating variables, while the heap is limited in size only by how much
memory can be allocated. Stack would include most compile time variables, while heap would include anything
created with malloc or new. (This is for C/C++, and not strictly the case.)
How would you store a vector in N dimensions in a datatable?
I need a little direction for this question, as I know not what it means. I encourage my readers, who have
on most occasions proven themselves more adept than me, to come through again.
What type of language do you prefer for writing complex data structures?
I can't imagine using anything higher level than C or C++. Anything more advanced has most anything already
built and not very easily molded. Or perhaps I just wouldn't think of it as complex.
What is the number 21 in binary format? And in hex?
10101 in binary and 15 in hex, and no I didn't cheat and use a calculator. It works just like decimal.
Take the following digits of an arbitrary number in base B:
UVWXYZ
The number in decimal is U*B5 + V*B4 + W*B3 + X*B2 + Y*B1 + Z*B0
As more digits are added, you just increase the power by which it is raised. Also note that any number raised
to the zeroth power is 1, so the Z element is just itself, and the ones digit.
What is the last thing you learned about data structures from a book, magazine or web site?
As with my answer to this question with regard to algorithms, I'm certain I've used to web for reference here,
but I'd guess my introduction and original knowledge acquisition came from a book.
However, I would add journal article to the list of answers, because in both cases that would have been my
answer, even though I read them via the web.
How would you store the results of a soccer/football competition (with teams and scores) in an XML document?
<fixtures><fixture><teamname="Chelsea FC"><score>0</score></team><teamname="Fulham FC"><score>1</score><!-- any other stats? --></team></fixture></fixtures>
That might be reasonable.
Can you name some different text file formats for storing unicode characters?
I have to be honest here and say I don't know what you're talking about. I can't think of a file format
that wouldn't take it.
Again the reading material is similar to last week:
Posted by Sam on Mar 24, 2009 at 12:00 AM UTC - 5 hrs
Every day, psychological barriers are erected around us, and depending on what task they are a stumbling block for,
they can be helpful or a hindrance.
Ramit Sethi wrote a guest post on personal finance blog Get Rich Slowly about passive barriers that got me
thinking about passive barriers in software development, or perhaps just any easily destroyed (or erected barrier) that
prevents you from doing something useful (or stupid). One example he uses that comes up a lot in my own work
references email:
More...
I get emails like this all the time:
"Hey Ramit, what do you think of that article I sent last week? Any suggested changes?"
My reaction? "Ugh, what is he talking about? Oh yeah, that article on savings accounts ... I have to dig that up
and reply to him. Where is that? I'll search for it later. Marks email as unread"
Note: You can yell at me for not just taking the 30 seconds to find his email right then, but that's exactly
the point: By not including the article in this followup email, he triggered a passive barrier of me
needing to think about what he was talking about, search for it, and then decide what to reply to.
The lack of the attached article is the passive barrier, and our most common response to barriers is to
do nothing.
(Bold emphasis is mine).
If I can't immediately answer an email, it gets put on hold until I have time to go through and do the research
that I need to do to give a proper reply. Sometimes, that means your email never gets answered because eventually
I look down at the receipt date and say to myself "I guess it'd be stupid to respond now." But I digress.
In everyday software development, there are a number of barriers that can help us:
Minimizing or closing the browser. When a compilation is expected to take up to a minute, or a test suite
will run for too long, or a query takes forever, there's not much work that can be done, so I might
fire up the feed reader, email, or twitter to pass the time away. The problem here is that you'll often spend
far longer on your excursion than it takes for your process to complete. If you waste just 5 minutes each time,
you've accomplished nothing - you're just skimming and certainly not getting anything out of it, and you could
have been back working on what you were trying to accomplish. In these situations, I have my email, feed reader,
and twitter minimized, and that significantly reduces the urge to open them up and start a side quest.
If you wanted to get more to the active side of barriers, you might just add the line
to your hosts file. That turns a passive barrier to time waste into a downright pain.
Having a test suite with continuous integration and code analysis tools running. At various points in a day you might be tempted to
check in code that breaks the build or introduces a bug. This is especially true at the end of the day.
However, if you have a test suite that runs on every commit, you're much more likely to run it to avoid the embarrassment of checking
in bad code. If you've got static analysis tools that also report on potentially poor code, you're less
likely to write it.
Annoyance Driven Development. This isn't one that I know how to turn on or off, but I think it would be
a great feature to have in IDEs or text editors: it gets slow when your methods or classes or files get too big.
This would be a great preventative tool, if it exists. I guess it falls back to using test suites and
code analysis to provide instant feedback that annoys you into doing the right thing.
Working with others, or having others review your code. Most of us pay more attention to quality
when we know others will be looking at the code we write. Imagine how much more of your code you'd be
proud to show off if you just knew that someone would be looking at it later.
Just as well, there are also barriers that hinder us:
Interruptions. This one is obvious, but so pervasive it should be mentioned. IM,
telephone calls, email, coworkers stopping by to chat or ask questions - they all prevent us from working
from time to time. The easy answer is to close these things, and that's what I do. They all represent
passive barriers to getting work done, and you can easily turn that around to be a passive barrier
against wasting time (see above). Pair programming is an effective technique that erects its own
barrier to these time wasters.
Rotting Design: Rigidity, Fragility, Immobility, and Viscosity. Bob Martin discusses these
in his (PDF) article on Design Principles and Design Patterns. Quoting him for the
descriptions, I'll leave it to you to read for the full story:
Rigidity is the tendency for software to be difficult to change, even in
simple ways. Every change causes a cascade of subsequent changes in dependent
modules. What begins as a simple two day change to one module grows into a multi-
week marathon of change in module after module as the engineers chase the thread of
the change through the application.
...
Closely related to rigidity is fragility. Fragility is the tendency of the
software to break in many places every time it is changed. Often the breakage occurs
in areas that have no conceptual relationship with the area that was changed. Such
errors fill the hearts of managers with foreboding. Every time they authorize a fix,
they fear that the software will break in some unexpected way.
...
Immobility is the inability to reuse software from other projects or
from parts of the same project. It often happens that one engineer will discover that he
needs a module that is similar to one that another engineer wrote. However, it also
often happens that the module in question has too much baggage that it depends upon.
After much work, the engineers discover that the work and risk required to separate
the desirable parts of the software from the undesirable parts are too great to tolerate.
And so the software is simply rewritten instead of reused.
...
Viscosity comes in two forms: viscosity of the design, and viscosity of
the environment. When faced with a change, engineers usually find more than one
way to make the change. Some of the ways preserve the design, others do not (i.e.
they are hacks.) When the design preserving methods are harder to employ than the
hacks, then the viscosity of the design is high. It is easy to do the wrong thing, but
hard to do the right thing.
The point is that poor software design makes an effective barrier to progress. There are only two ways
I know to tear down this wall: avoid the rot, and make a conscious decision to fix it when you
know there's a problem. There are plenty of ways to avoid the rot, but books are devoted to them, so
I'll leave it alone except to say a lot of the agile literature will point you in the right direction.
Unit Tests. I struggled with the idea of putting this on here or not. If you're an expert, you already know this.
If you're a novice or lazy, you'll use it as an excuse to avoid unit testing. The point remains: unit testing
can be a barrier to producing software, if you are exploring new spaces and having trouble determining
test cases for it. I'll let the Godfather of TDD, Kent Beck, explain:
... I still didn't have any software. As with any speculative idea, the chances that this
one will actually work out are slim, but without having anything running, the chances are zero. In six
or eight hours of solid programming time, I can still make significant progress. If I'd just written
some stuff and verified it by hand, I would probably have the final answer to whether my idea is
actually worth money by now. Instead, all I have is a complicated test that doesn't
work, a pile of frustration, eight fewer hours in my life, and the motivation to write another essay.
These are just a few examples, so I'm interested in hearing from you.
What barriers have you noticed that positively affect your programming? Negatively?
Posted by Sam on Mar 30, 2009 at 12:00 AM UTC - 5 hrs
A friend of mine from graduate school recently asked if she could use me as a reference on her resume.
I've worked with her on a couple of projects, and she was definitely one of the top few people I'd
worked with, so I was more than happy to say yes.
Most of the questions were straightforward and easy to answer. However, one of the potential questions
seemed way off-base: I may be asked to "review her multi-tasking ability."
Of course I want to paint her in the best possible light, and in that regard, I'm unsure how to answer such
a question. Why? To understand that, we need to ask
What's the question they're really asking?
There are two disparate pieces of knowledge they can hope to glean from my answer to that question:
Does she concentrate on a single item well enough to finish it?
In this case, they are asking the opposite of what they want to find out. The trick relies on the reviewer to give
an honest opinion, whereas most people would assume they should answer each question in the affirmative. Because
the rest of the questions seem straightforward, I'd give this potential "real question" a low
probability of being what they really want to know.
Is the candidate able to juggle multiple different projects and work effectively?
I give this one the higher probability of being the question the employer really wants the
answer to. But it's a ridiculous question. On the one hand, you already know the job candidate has
successfully completed two levels of college, so it should be clear that they can handle multiple different
projects given the appropriate resources. On the other hand, I don't think they care about the
"appropriate resources" part. I think they're setting their employees up to fail because they
don't understand that
Is "multitasking ability" just code for unable to accomplish anything because you require employees
to work on so many different projects in parallel that progress cannot be made on any of them?
What's your opinion?
Update: John G. Miller (or someone claiming to be him) is author of a book and has asserted trademark rights to a phrase originally used in this article, so I've removed it.
Posted by Sam on Apr 09, 2009 at 12:00 AM UTC - 5 hrs
This is the "I'm trying my hardest to be late to that meeting that spans lunch where they don't serve anything to tide you over"
edition of Programming Quotables.
If you don't know - I don't like to have too many microposts on this blog (I'm on twitter for that), so save them up as I run across them, and every once in a while I'll post a few of them. The idea is to post quotes about programming that have one or more of the
following attributes:
I find funny
I find asinine
I find insightfully true
And stand on their own, with little to no comment needed
It's up to you decide which category they fall in, if you care to. Anyway, here we go:
This is my Quality is Dead hypothesis: a pleasing level of quality for end users has become too hard to achieve while demand for it has simultaneously evaporated and penalties for not achieving it are weak.
The entropy caused by mindboggling change and innovation in computing has reached a point where it is extremely
expensive to use traditional development and testing methods to create reasonably good products and get a
reasonable return on investment. Meanwhile, user expectations of quality have been beaten out of them.
When I say quality is dead, I don't mean that it's dying, or that it's under threat.
What I mean is that we have collectively- and rationally- ceased to expect that software normally works
well, even under normal conditions. Furthermore, there is very little any one user can do about it.
I haven't figured out yet exactly how I'm going to use this, but it'll probably look like this: one new beat per day, one new track per weekend. One new app per month, one milestone on the app per week. The goal is not to establish a far-off goal and find a way to hit it, but to establish a series of tiny, immediate goals that keep you forever moving forward. Aristotle argued that virtue was mostly a matter of having good habits; Lao-Tzu tells us that the voyage of a million miles starts with a single step. So the key is to get moving and keep moving.
But in computer games, it's impossible to have an equal match. It's humans versus machines. One side has an advantage of being able to perform a billion calculations per second, and the other has the massively parallel human brain.
Any parity here is an illusion, and it's that illusion that we seek to improve and maintain via the introduction of intelligent mistakes and artificial stupidity.
The computer has to throw the game in order to make it fun. When you beat the computer, it's an illusion. The computer let you win. We just want it to let you win in a way that feels good.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
What kind of tools are important to you for monitoring a product during maintenance?
I rely on logs and profiling tools on occasion. I'm
really interested to hear from the rest of you about this though.
What is important when updating a product that is in production and is being used?
I'd say it's important not to interrupt service. Surely there must be something else you're
getting at?
How do you find an error in a large file with code that you cannot step through? cout, puts, printf, System.Out.print, Console.Out.WriteLine, and ## have all
been useful for me at one time or another.
A good strategy here is to isolate the code that's causing the error by removing code and faking results.
By doing that, you can slowly add code back in until the error reappears. Rewrite that part.
How can you make sure that changes in code will not affect any other parts of the product?
Regression tests!
How do you create technical documentation for your products?
Ideally I'd have comments that can be harvested by tools like RDoc or JavaDoc, but times are often
less than ideal.
How can you debug a system in a production environment, while it is being used?
You can read logs if important events are being logged.
Profiling tools exist for this purpose, but I don't have experience with any outside of those for
use with databases.
Do you know what load balancing is? Can you name different types of load balancing?
One computer acts as the gatekeeper for an array of computers and directs requests to the others
to "balance the load" of the entire system.
I'm not familiar with different types, but just guessing I'd assume they have round-robin and need-based
load balancing. I'd also presume any other scheduling algorithmic scheme could be applied in load
balancing.
I'm more interested to know why this is on the maintenance list of questions. Is it because you've deployed
your application and now you need to scale it with hardware?
Can you name reasons why maintenance of software is the biggest/most expensive part of an application's life cycle?
One view is that after you write the first line of code, you begin maintenance. But more in-line with the
popular view: it lasts the longest. You may take a month to build a system that will be in production over
several years. During that time, defects are found that need to be fixed, business rules may change, or
new features may be added.
Also, we suck at writing software.
What is the difference between re-engineering and reverse engineering?
I didn't know this one. I thought and would have responded that re-engineering would be
rebuilding an application with a white box, while reverse engineering would be done through a black box.
The reengineering of software was described by Chikofsky and Cross in their 1990 paper, as "The examination and alteration of a system to reconstitute it in a new form". Less formally, reengineering is the modification of a software system that takes place after it has been reverse engineered, generally to add new functionality, or to correct errors.
This entire process is often erroneously referred to as reverse engineering; however, it is more accurate to say that reverse engineering is the initial examination of the system, and reengineering is the subsequent modification.
How would you answer these questions about software maintenance?
Domain code in controllers and views isn't a problem that's limited to Rails, of course. It's a problem everywhere, and one you generally need to remain vigilant about. Rails doesn't make it easy by making it easy - it's much too easy to do the wrong thing.
You've got the view open and think, "I need to get a list of Widgets."
That was easy, and it's even easier in controllers where you don't have the hassle of angled brackets and percent signs. Worse yet, since you've got what you need right there, it's easy to add more logic around it. Before you know it, your views and controllers are cluttered with a bunch of crap that shouldn't be there.
I fall into the trap more often than I'd like to admit. And I know it's wrong. What of those who haven't a clue?
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
Browsing through the questions, I'm not confident here of my ability to answer without asking
some preliminary questions (which I have no one to answer), so please chime in if you have something to add.
More...
Do you know what a baseline is in configuration management? How do you freeze an important moment in a project?
A baseline in configuration management is the same as a baseline anywhere else - some place which serves as
a starting point or point we can return to to compare one point in time to another.
Freezing an important moment in a project to me sounds like creating a new major or minor version - so I may make
a new tag in the version control system.
Which items do you normally place under version control?
I can't think of anything I'd not put under version control aside from user-specific project settings
and files created while executing the software (like logs, for instance) that are always likely to cause
change conflicts between different developers.
How can you make sure that team members know who changed what in a software project?
Give everyone separate accounts to access the VCS.
Some people like to keep a change log at the top of each file, but I think that gets ignored and becomes
useless.
Do you know the differences between tags and branches? When do you use which?
A tag is for a static snapshot, a branch is intended for development outside the trunk.
How would you manage changes to technical documentation, like the architecture of a product?
I'd put them in VCS along with the rest of the project. I have to say though - I'm not sure I understand what
this question is really asking.
Which tools do you need to manage the state of all digital information in a project? Which tools do you like best?
This is another question which I'd need prodding to give a more useful answer. My favorite would be a VCS, but
what else exists? Are we talking about using Wikis and bug/issue trackers? Are we talking about using Excel to
create spreadsheets to manage burndown charts and make predictions as to project completion dates? Are we
talking about using Word to manage user documentation?
I'm unsure.
How do you deal with changes that a customer wants in a released product?
I mainly deal in web development, so in that case we just make the change and re-deploy the web application.
In desktop applications, I've only ever released projects to customers who will be using it on so few machines
that coming up with an automatic update strategy would have been a waste of resources.
If it was the right
project, I'd have it do a call to a central server that looks for updates, and perform the updates automatically.
In that case, we just make the updates and set a flag when a customer wants a change to a released product.
Are there differences in managing versions and releases?
As with so many things in software development, the answer depends on how you view versions and releases.
If you view a release as the deliverable to customers and a version as a concept to get you there, then
the answer is undeniably yes.
If you view versions and releases as the same things, then perhaps not so much.
Do you have multiple versions between releases? There are many questions to ask here, and I certainly don't
have all the answers. Personally, I see them as a combination of the two views I mentioned above:
the version is the version of the code that we tag at certain points in time. The release happens in
tandem, but it is the deliverable we give to clients - so they differ in the way we manage them, because
it's not simply an issue of "commit->version->release." I'd love to get there, but I'm not close yet.
What is the difference between managing changes in text files vs. managing changes in binary files? diff is much less useful in highlighting differences in binary files than it is in text files (at least
as far as the person running the diff is concerned). It is much harder to manage conflicting changes in binary
files as a result.
How would you treat simultaneous development of multiple RfC's or increments and maintenance issues?
I fear I don't understand what this question is asking. RfC == Request for Comments? What does that
have to do with increments and maintenance issues? Any advice as to what you think this question means
is truly appreciated.
Reading through and answering these questions has made one thing very clear to me: I'm stuck in the middle
of the forest and I'm only seeing the trees. I don't have a strategy when it comes to configuration management
and version control. I use it, because I know I should, and it has some benefits. However, focusing
only on the tactical side means I'm not getting as much out of it as I could.
How would you answer these questions about configuration management?
(A disclaimer for you: I read this book as a reviewer and haven't yet made the time to go through the finished
product, so some of what I'm about to say may change. That said, I can only imagine that it got better before
going to publication, so I don't expect anyone would be disappointed.)
The Passionate Programmer retains that status of being a must-read. It adds a few new chapters and
removes a couple of others, but more importantly it changes the framing from the negative view of "save your job"
to what My Job Went to India was always really about anyway: "creating a remarkable career in software
development."
Here's what I had to say about it for the blurb:
Six short months before I read Chad's book, I was on the verge of
changing careers. Through a series of accidents from November to
May, I decided not only to stick with software development but to be
passionate about it while striving to be great. With a healthy dose of
inspiration, the book you're now holding served as a road map for
achieving those goals.
It truly is an excellent map that helped me find my way from Quit Town to making the decision to be
passionate about hacking and life in general, starting this blog, and striving to leave the realm
of the unclean masses in our profession whose exploits we read about so often.
If you read MJWTI and understood the positive aspects of it, this book isn't that important since
you know most of it already.
I'd have purchased it anyway, but you may feel differently. That's Okay.
However, if you felt you'd be embarrassed if someone saw you holding the first version - or just
haven't read it before - I strongly recommend picking up a copy of this version and
going through it. Don't just read it though - apply it. At the end of every chunk of advice there is a list
of activities that you can perform. Don't just gloss over them; make it a point to actually do some of them.
It's short enough to read through in one or two sittings. But there's enough content in there to keep you busy for
a couple of years.
If you've read this book or the 1st edition, what did you think about it? Am I overenthusiastic?
I look forward to covering the new chapters as time allows over the next few weeks. I hope you'll join me in
the discussion.
Posted by Sam on May 14, 2009 at 12:00 AM UTC - 5 hrs
Many people see spectacular plays from athletes and think that the great ones are the ones making those plays.
I have another theory: It's the lesser players who make the "great" plays, because thier ability doesn't take them
far enough to make it look easy. On top of it all, you could say guys who make fewers mistakes just
aren't fast enough to have been in a position to make the play at all.
In the case of sport, one might also make that argument against the lesser players in favor of the ones who
regularly make the highlight reel: their greatness lets them get just a tad closer, which allows them to make the play.
In the case of software development, that case is not so easily made.
When developers have to stay up all night and code like zombies on a project that may very well be on
a death march, you've got a problem, and it's not solely that your project might fail. Even when that super heroic
effort saves the project, you've still got at least three issues to consider:
Was the business side too eager to get the project out the door?
Are the developers so poor at estimating that it led to near-failure?
Is there a failure of communication between the two sides?
In saving the project, the spectacular effort and performance of your team or individuals on your team is
not something to be marveled at - it's a failure whose cause needs to be identified and corrected.
Handing out bonuses is a nice way to show appreciation for their heroic efforts, but it encourages poor
practices by providing disincentives for doing the right thing:
No incentive to make good estimates.
Incentive to give in to distrations since they "can always just stay late"
No reason not to have a foggy head half the day
A motive for waiting until the last minute, just to show off their prowess
Handing out bonuses to the individuals who displayed the most heroism brings friction and
resentment from
those who opted to sleep (especially among those who realize half the work was created by the
heroes!).
Yet, having only part of the team on board with the near-death march causes the same resentment from the
sleepless hackers.
Rewards encourage repetition of the behavior that led to the prize. When you do that, you're putting
future projects in peril.
There are plenty of ways to reduce the risk and uncertainty of project delivery - and subtantially fewer
tend to work when you wait until the last week of a project - but those methods are the subjects of other stories.
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
How many of the three variables scope, time and cost can be fixed by the customer?
Two. (See The 'Broken Iron Triangle' for a good
discussion.)
Who should make estimates for the effort of a project? Who is allowed to set the deadline?
The team tasked with implementing the project should make the estimates. The deadline can be set by
the customer if they forego choosing the cost or scope. There are cases where the team should set the deadline.
One of these is if they are working concurrently on many projects, the team can give the deadline to management,
with the knowledge that priorities on other projects can be rearranged if the deadline for the new project
needs to be more aggressive than the team has time to work on it.
Otherwise, I imagine management is
free to set it according to organizational priorities.
Do you prefer minimization of the number of releases or minimization of the amount of work-in-progress?
I generally prefer to minimize the amount of work on the table, as it can be distracting to
Which kind of diagrams do you use to track progress in a project?
I've tended to return to the burndown chart time after time. Big visible charts
has some discussion of different charts that can be used to measure various metrics of your project.
What is the difference between an iteration and an increment?
Basically, an iteration is a unit of work and and increment is a unit of product delivered.
Can you explain the practice of risk management? How should risks be managed?
I don't know anything about risk management formally, but I prefer to to deal with higher risk items first
when possible.
Do you prefer a work breakdown structure or a rolling wave planning?
I have to be honest and say I don't know what you're talking about. Based on the names, my guess would be
that "work breakdown structure" analyzes what needs to be done and breaks it into chunks to be delivered
in a specific order, whereas rolling wave may be more like do one thing and then another, going with the flow.
In any case, I would think like most everyone else that I'd prefer the work breakdown structure, but it's
unrealistic in most projects (repetitive projects could use it very successfully, for instance). Therefore,
I'll take the rolling wave over WBS please.
What do you need to be able to determine if a project is on time and within budget?
Just the burndown chart, if it's been created out of truthful data.
Can you name some differences between DSDM,
Prince2
and Scrum?
I'm not at all familiar with Prince2, so I can't talk intelligently about it. DSDM is similar to Scrum in that
both stress active communication with and involvement of the customer, as well as iterative and incremental
development. I'm not well versed in DSDM, but from what little I've heard, it sounds a bit more prescriptive than
Scrum.
I'd suggest reading the Wikipedia articles to get a broad overview of these subjects - they are decent starters.
It would be nice if there were a book that compared and contrasted different software development
methodologies, but in the absence of such a book, I guess you have to read one for each.
How do you agree on scope and time with the customer, when the customer wants too much?
Are they willing to pay for it? If they get too ridiculous, I'd just have to tell them that I can't do what they're asking
for and be able to pay my developers. Hopefully, there would be some convincing that worked before it came to
that point, since we don't want to risk losing customers. However, I must admit that I don't have any strategies
for this. I'd love to hear them, if you have some.
There are a couple of stories you can tell:
about 9 women having one baby in just one month. (Fred Brooks)
about your friend with an interesting first date philosophy (Venkat Subramaniam)
How would you answer these questions about project management?
Posted by Sam on May 21, 2009 at 12:00 AM UTC - 5 hrs
For the last few months, I've been having trouble getting out of "next week" mode.
That's what I call it when I don't know what I'll be working on outside of the next week at any given time.
It's not necessarily a bad thing, but when you're working on projects that take longer than a couple of weeks,
it doesn't let you keep the end in sight. Instead, you're tunneling through the dirt and hoping you've been digging
up instead of down.
More...
I've delivered most projects during this period on schedule, but I did cave into pressure to
over-promise and under-deliver on one occasion. And it sucked.
When I wrote that
rewarding heroic development
promotes bad behavior, I said reducing the risk and uncertainty of project delivery
is the subject of a different story, and the discussion in the comments
got me thinking about this. There are many stories worth telling regarding this issue.
The rest of this story is about how I'm intending to get out of my funk using
techniques that have worked for me in the past.
(Aside: As I write the words below, it occurs to me we have a chicken/egg problem of which comes first.
Just start somewhere.)
To make decent estimates there are 3 must-haves:
Historical data as to how much you can complete in a given time frame
Backlog of items you need to complete in the time frame you're wanting to estimate for
The ability to break requests into sweet, chunky, chewy, bite-sized morsels of estimable goodness.
Since you haven't been doing this ["ever", "in a while"][rand*2], you don't have historical data. Your backlog
is anything on your table that hasn't been completed yet - so you've got that. Now, you need to break your
backlog apart into small enough bits to estimate accurately. This way, you practice the third item and
in a couple of weeks, you'll have historical data.
About estimating tasks:
Don't worry about estimating in units of time. You're probably not good at it. Most of us aren't, and you haven't
even given it a fair shot with some data to back up your claims. Measure in points or tomatoes. Provide your estimate
in chocolate chips. The unit of measurement doesn't matter at this point, so pick something that
makes you happy. However, you should stay away from units of time at this point in the exercise. You're not
good at that, remember?
So I have some number of tasks that need to be completed. I write each of them down, and decide how many chocolate
chips it's going to take me to finish each one. I count in Fibonacci numbers instead of counting numbers, because
as tasks grow in time and complexity, estimates grow in uncertainty. I try to keep all of my tasks as 1, 2, or 3
chocolate chips. Sometimes I'll get up to a 5.
But if you start venturing into 8 and 13 or more, you're basically saying
IDFK anyway, so you might as well be honest and bring that out into the open. Such tasks are more like
Chewbaccas than chocolate chips, so take some time to think about
how you might break them down as far as possible.
Now that you know how to estimate tasks:
Before you start on a task -- with a preference to earlier rather than later (hopefully as soon as you know it needs to be done) --
estimate how many points it should take you, then write it down on your list of items to complete. Take note
of how many chocolate chips you finish daily. Write down the number completed and the date.
Make a graph over time comparing the number of chocolate chips you have remaining (or how many you've completed)
on the Y-axis and the date that applied to. If you use points remaining, it's a Burn Down chart. If you
go the otherway, it's not surprisingly called a Burn Up chart.
Keep a log of the number of chips you complete per week. The last two or three weeks' averages are a good indication
of how many you'll be able to do for the next few weeks, and helps planning for
individuals spanning several projects, or teams on a single project.
You can now reference your chips per week to extrapolate how long it's likely to take you to finish a particular
task or small project.
Further, you'll always want to know how many points you've got in your backlog and how many you need to
complete by a given date. If you keep a log of due dates you can reference it and your points per weeks
when someone asks you when you can have something done. Now, you can say "I can start on the 26th or you
can rearrange the priorities on my current work and I can be done by the end of the day."
Any questions? As always, I'm happy to answer them.
The majority of these ideas are scrum-thought and I've used terms from that methodology, so if you want to
go deeper, that would be a good place to look.
I get the impression most people think
you get better by imitating masters.
It's a common theme in self improvement.
Aspiring writers read great authors. Aspiring musicians listen to great musicians. Artists study artists and coders
study coders.
I've certainly espoused that point of view. I'm fond of quoting Ron Jeffries as saying,
My advice is to do it by the book, get good at the practices, then do as you will. Many people want to skip to step three. How do they know?
In fact, I think that's the third time I've done so in almost as many years.
But what if that's not the primary benefit of reading other people's code? I don't mean scanning it - I mean reading it
until you understand exactly what it's doing. Is there something else you can get out of it?
I think so. Perhaps it's not the mimicking of a particular style like a monkey that makes us better
for reading code. What if it's tracing through an unfamiliar thought process that flexes the brain
and makes it think in ways it previously had not?
By reading unfamiliar code and forcing yourself to trace through until you understand it, you end up
thinking in ways that were previously foreign to you.
I think that's where the real value in reading code exists.
What are your thoughts?
Posted by Sam on Jun 09, 2009 at 12:00 AM UTC - 5 hrs
From time to time I like to actually post a bit of code on this programming blog, so here's
a stream-of-conscious (as in "not a lot of thought went into design quality") example that shows how to:
Open Excel, making it invisible (or visible) to the user.
Create a workbook and access individual worksheets
Add data to a cell, or retrieve data from a cell
Add a chart to a worksheet, with constants for various chart types
Save as Excel 97-2003 format and close Excel
If you know where I can find the constants for file type numbers, that would be appreciated. Calling SaveAs
without the type seems to use whatever version of Excel you are running, but I'd like to find how to save as
CSV or other formats.
Needless to say, this requires Excel be on the computer that's running the code.
require'win32ole'
xl = WIN32OLE.new("Excel.Application")puts"Excel failed to start"unless xl
xl.Visible =false
workbook = xl.Workbooks.Add
sheet = workbook.Worksheets(1)#create some fake data
data_a =[](1..10).each{|i| data_a.push i }
data_b =[](1..10).each{|i| data_b.push((rand*100).to_i)}#fill the worksheet with the fake data#showing 3 ways to populate cells with values(1..10).eachdo |i|
sheet.Range("A#{i}").Select
xl.ActiveCell.Formula = data_a[i-1]
sheet.Range("B#{i}").Formula = data_b[i-1]
cell = sheet.Range("C#{i}")
cell.Formula ="=A#{i} - B#{i}"end#chart type constants (via http://support.microsoft.com/kb/147803)
xlArea =1
xlBar =2
xlColumn =3
xlLine =4
xlPie =5
xlRadar =-4151
xlXYScatter =-4169
xlCombination =-4111
xl3DArea =-4098
xl3DBar =-4099
xl3DColumn =-4100
xl3DLine =-4101
xl3DPie =-4102
xl3DSurface =-4103
xlDoughnut =-4120#creating a chart
chart_object = sheet.ChartObjects.Add(10, 80, 500, 250)
chart = chart_object.Chart
chart_range = sheet.Range("A1", "B10")
chart.SetSourceData(chart_range, nil)
chart.ChartType = xlXYScatter
#get the value from a cell
val = sheet.Range("C1").Value
puts val
#saving as pre-2007 format
excel97_2003_format =-4143
pwd = Dir.pwd.gsub('/','\\') << '\\'#otherwise, it sticks it in default save directory- C:\Users\Sam\Documents on my system
workbook.SaveAs("#{pwd}whatever.xls", excel97_2003_format)
xl.Quit
The list is not intended to be a "one-size-fits-all" list.
Instead, "the key is to ask challenging questions that enable you to distinguish the smart software
developers from the moronic mandrills." Even still, "for most of the questions in this list there are no
right and wrong answers!"
Keeping that in mind, I thought it would be fun for me to provide my off-the-top-of-my-head answers,
as if I had not prepared for the interview at all. Here's that attempt.
Though I hope otherwise, I may fall flat on my face. Be nice, and enjoy (and help out where you can!).
Last week's answers on Functional Design
had me feeling that way. Luckily, this week we come to technical design - a topic I feel quite a bit stronger on.
More...
What do low coupling and high cohesion mean? What does the principle of encapsulation mean?
Coupling refers to how strongly or loosely components in a system are tied together. You want that to be
low. Cohesion refers to how well the individual parts of a unit of code fit together for a single purpose.
Encapsulation is about containing implementation of code so that outsiders don't need to know how it's works
on the inside. By doing so you can reduce negative effects of coupling.
Reading: Robert C. Martin's SOLID
principles of OOD, which have been linked on this blog since day 1. His book, Agile Software Development: Principles, Patterns, and Practices
is another great resource for this topic. It's short and to the point, and comes highly recommended from myself.
How do you manage conflicts in a web application when different people are editing the same data?
Set a flag when someone starts editing data unit A. If someone else loads it, let them know it's being edited
and that it's currently in read only mode. If the race was too fast, you can also have a check on the
commit side to let them know their changes conflict with another user, present them the data, and then let
them figure out how to merge the changes. This has rarely been a problem in my experience, but it could be,
and that's how I'd deal with it if the requirement came up. (If the changes don't conflict, you could
simply keep the user unaware as well.)
My answer comes from the things you see in normal usage of shared files or just about any shared resource,
for that matter. Originally,
it comes down to race conditions, so you might
be able to extrapolate some useful information from that low-level explanation.
Do you know about design patterns? Which design patterns have you used, and in what situations?
I know about design patterns. Most of the ones I'm familiar with, at least in the canonical book,
aren't of much daily use to me, as I tend to work in dynamic languages, where the sorts of flaws that precipitate
the patterns (as implemented in the book) just aren't factors as often as in other languages. (Yes, some of the
book is implemented in Smalltalk. I can implement them with as much superfluous junk as you desire in
any language - that doesn't make it a necessity.)
I suppose most frequently I've used the Strategy pattern.
(Perhaps the fact that I've focused so much on one in particular is a weakness in my coding style?) The situations
are when an interface should remain the same while the implementation should differ somewhat. I don't have a
concrete example on the top of my head.
If I were to start working in Java again, or building larger applications in .NET (I currently build very small
apps in that space as part of my job), I'd re-read the book. I might even scan the inner cover daily just as a
refresher.
I wouldn't say I'm strong on design patterns, but I've got reference information and know where to look
should I need to, along with the facilities to become strong should my situation call for it.
Do you know what a stateless business layer is? Where do long-running transactions fit into that picture?
I hadn't heard it as a single term until now, but knowing the individual terms lets me say that objects in
the business layer (or domain model) are transient - or that their state is not preserved in memory between
subsequent requests for the same object.
This may note bode well for long running transactions, as state presumably must be set up each time an
object is loaded, along with any process that might be required for tear-down.
For reading, this is just information as I've come across it throughout my various readings, so I don't
know what to recommend.
What kinds of diagrams have you used in designing parts of an architecture, or a technical design?
UML, or some bastardization of it has always been enough.
Most likely the bastardized part where we just do a little design on paper or a whiteboard to gain a
better understanding of the intended design through some sketch-work.
I've never been a part of a team that practices BDUF, nor
have I felt the need for it in any personal projects, so I'm light on recommendations for reading.
The Wikipedia article on UML is
sufficient for my tastes, but I've know people who dove into Martin Fowler's books
and came away more knowledgeable, so that may help you.
Can you name the different tiers and responsibilities in an N-tier architecture?
For what value of N? (I mean, we could have N=1000000 and I wouldn't know -- or if I did know, we might
be here all day.) Normally N=3, so we might be talking about presentation, logic, and data tiers. Sometimes
we might talk about Entities and others, or we might be considering (mistakenly?) MVC.
I think the responsibilities are clear by their names, but if you'd like to discuss further, I'm
certainly okay with doing so.
Can you name different measures to guarantee correctness and robustness of data in an architecture?
I need a little direction here. It seems to me this is a product of many things, and I don't know where to start.
For instance, we could say that unit tests and integration tests can go part of the way there. We could
talk about validating user input, and that it matches some definition of "looking correct." We could
have checks coded and in place between the various systems that make up the architecture. Constraints on the
database. I could go on if I were giving myself more time to think about it.
Because of the open-endedness in this question, there are any number of references. I'd dive into
automated testing in its various forms, which when applied to the situation, should get you most of the
way there.
Can you name any differences between object-oriented design and component-based design?
To be honest, this is the first I've heard of component-based design, so no, I can't name the differences.
My thoughts would go towards having objects to design around (as in C++) vs. not having objects to
design around (as in C).
As it happens, there may be a reason the term "component-based design" seems new to me: IEEE held the
"1st ... workshop" on it not 6 months ago. They could very well be behind the times.
Searching with Google also indicates this may be designing from the view of the outside,
as in SOA.
I think the SOLID principles I mentioned above go beyond the availability of objects-proper, so I don't expect
to be surprised here. However, I can't offer you any reading advice and without a definitive source
from the Google results, I cannot even tell if I'm in the right ballpark.
Your thoughts are especially encouraged on this topic.
How would you model user authorization, user profiles and permissions in a database?
I wouldn't typically model the authorization piece in the DB. If I read you correctly, I'm
guessing you mean the storage of authorization information in the database, as opposed to the
act of authorizing. Under that assumption, I've modeled this situation in just about every
way I can imagine. A couple of scenarios:
a. Under a denormalized scenario, I'd keep a table of permissions and a table of users (which includes authorization
information, profile information, and a list of permissions from the users table). This isn't ideal if permissions
ever change, and especially not if you're returning a ton of users for the purpose of authorization while the
profile information is especially large. In that case you're transferring way more data than you need, and it could
result in performance problems. (The extra data transfer may only be a problem with ORM tools, as you
could always hand-write the queries to return only what you need.
On the other hand, storing of redundant data is a problem if storage space itself is an issue.)
b. Under a completely normalized scenario, we'd have a table of permissions, a table relating users
to permissions, and a table for users. For the sake of cohesion (and potentially optimizing data transfer)
we might separate the users table into one for authentication and another for profile, while keeping the
relationship with permissions based on user_auth.
c. Some variation in between the two extremes.
For reading? For me it's based on experience, and perhaps a couple of database courses in college. I guess
just about any book on database design would do. I wouldn't bother trying to understand the formal
academic descriptions of database normalization,
but if you want to, you can only be better for it (as long as you can recognize the tradeoffs due to extra
joins!) Reader suggestions are highly welcome, as always.
How would you model the animal kingdom (with species and their behavior) as a class system?
This one might deserve a blog post all on its own. It depends: If I'm working in a language with
multiple inheritance, I'd use a combination of class hierarchy that follows the animal kingdom along
with mixins (which are also inheritance, but with less of a hierarchical attitude) for behavior shared
between and among the hierarchy levels. Without multiple inheritance, I'd have to resort to
interfaces where available, and composition for actual code reuse where it made sense.
The short answer though, is that I probably wouldn't implement it as a class system. If I really was working
with taxonomy and biological classification,
I don't think I'd model the real world with objects. I'd need to look into the subject quite a bit further
to tell you how I would do it, but suffice to say I don't think it'd be using objects to match
it one-for-one, or even something resembling one-to-one.
Reading: I wouldn't know where to begin. The SOLID principles will guide you, but I wouldn't think that's all
there is to it.
What do you think? Where would your answers differ?
Posted by Sam on Jun 17, 2009 at 12:00 AM UTC - 5 hrs
low cou-pling and high co-he-sion n.
A standard bit of advice for people who are learning to design their code better, who want to
write software with intention as opposed to coincidence, often parroted by the advisor
with no attempt to explain the meaning.
Motivation
It's a great scam, don't you think? Someone asks a question about how to design their code,
and we have these two nebulous words to throw back at them: coupling and cohesion.
We even memorize a couple of adjectives that go with the words: low and high.
More...
Cohesion Good. Coupling, Baaaaad!
It's great because it shuts up the newbie who asks the question -- he doesn't want to appear dumb, after all --
and it gets all of those in-the-know to nod their heads in approval. "Yep, that's right. He's got it. +1."
But no one benefits from the exchange. The newbie is still frustrated, while the professional doesn't
give a second thought to the fact that he probably doesn't know what he means. He's just parroting
back the advice that someone gave to him. It's not malicious or even conscious, but nobody is getting smarter
as a result of the practice.
Maybe we think the words are intuitive enough. Coupling means that something is depending on something else, multiple
things are tied together. Cohesion means ... well, maybe the person asking the question heard something about
it in high school chemistry and can recall it has something to do with sticking together.
Maybe they don't know at all.
Maybe, if they're motivated enough (and not that we've done anything to help in that department), they'll look it
up:
Coincidental cohesion (worst)
is when parts of a module are grouped arbitrarily (at random); the parts have no significant relationship (e.g. a module of frequently used functions).
Logical cohesion
is when parts of a module are grouped because they logically are categorised to do the same thing, even if they are different by nature (e.g. grouping all I/O handling routines).
Temporal cohesion
is when parts of a module are grouped by when they are processed - the parts are processed at a particular time in program execution (e.g. a function which is called after catching an exception which closes open files, creates an error log, and notifies the user).
Procedural cohesion
is when parts of a module are grouped because they always follow a certain sequence of execution (e.g. a function which checks file permissions and then opens the file).
Communicational cohesion
is when parts of a module are grouped because they operate on the same data (e.g. a module which operates on the same record of information).
Sequential cohesion
is when parts of a module are grouped because the output from one part is the input to another part like an assembly line (e.g. a function which reads data from a file and processes the data).
Functional cohesion (best)
is when parts of a module are grouped because they all contribute to a single well-defined task of the module
Content coupling (high)
is when one module modifies or relies on the internal workings of another module (e.g. accessing local data of another module).
Therefore changing the way the second module produces data (location, type, timing) will lead to changing the dependent module.
Common coupling
is when two modules share the same global data (e.g. a global variable).
Changing the shared resource implies changing all the modules using it.
External coupling
occurs when two modules share an externally imposed data format, communication protocol, or device interface.
Control coupling
is one module controlling the logic of another, by passing it information on what to do (e.g. passing a what-to-do flag).
Stamp coupling (Data-structured coupling)
is when modules share a composite data structure and use only a part of it, possibly a different part (e.g. passing a whole record to a function which only needs one field of it).
This may lead to changing the way a module reads a record because a field, which the module doesn't need, has been modified.
Data coupling
is when modules share data through, for example, parameters. Each datum is an elementary piece, and these are the only data which are shared (e.g. passing an integer to a function which computes a square root).
Message coupling (low)
is the loosest type of coupling. Modules are not dependent on each other, instead they use a public interface to exchange parameter-less messages (or events, see Message passing).
No coupling
[is when] modules do not communicate at all with one another.
What does it all mean?
The Wikipedia entries mention that "low coupling often correlates with high cohesion" and
"high cohesion often correlates with loose coupling, and vice versa."
However, that's not the intuitive result of simple evaluation, especially on the part of someone who doesn't
know in the first place.
In the context of the prototypical question
about how to improve the structure of code, one does not lead to the other. By reducing coupling, on the face of
it the programmer is going to merge unrelated units of code, which would also reduce cohesion. Likewise, removing
unrelated functions from a class will introduce another class on which the original will need to depend, increasing
coupling.
To understand how the relationships become inversely correlated requires a larger step in logic, where examples
of the different types of coupling and cohesion would prove helpful.
Examples from each category of cohesion
Coincidental cohesion often looks like this:
class Helpers;
class Util;
int main(void) {
where almost all of your code goes here;
return 0;
}
In other words, the code is organized with no special thought as to how it should be organized.
General helper and utility classes,
God Objects,
Big Balls of Mud, and other anti-patterns
are epitomes of coincidental cohesion.
You might think of it as the lack of cohesion: we normally talk about cohesion being a good thing, whereas
we'd like to avoid this type as much as possible.
(However, one interesting property of coincidental cohesion is that even though the code in question should not be stuck together,
it tends to remain in that state because programmers are too afraid to touch it.)
With logical cohesion, you start to have a bit of organization. The Wikipedia example mentions "grouping
all I/O handling routines." You might think, "what's wrong with that? It makes perfect sense." Then consider that
you may have one file:
IO.somelang
function diskIO();
function screenIO();
function gameControllerIO();
While logical cohesion is much better than coincidental cohesion, it doesn't necessarily go far enough in terms
of organizing your code. For one, we've got all IO in the same folder in the same file, no matter what type of
device is doing the inputting and outputting. On another level, we've got functions that handle both input and
output, when separating them out would make for better design.
Temporal cohesion
is one where you might be thinking "duh, of course code that's executed based on some other
event is tied to that event." Especially considering the Wikipedia example:
a function which is called after catching an exception which closes open files,
creates an error log, and notifies the user.
But consider we're not talking about simple the relationship in time. We're really interested in the code's structure.
So to be temporally cohesive, your code in that error handling situation should keep the closeFile,
logError, and notifyUser functions close to where they are used. That doesn't mean
you'll always do the lowest-level implementation in the same file -- you can create small functions that take
care of setting up the boilerplate needed to call the real ones.
It's also important to note that you'll almost never want to implement all of that directly in the catch
block. That's sloppy, and the antithesis of good design. (I say "almost" because I am wary of absolutes, yet I cannot think
of a situation where I would do so.) Doing so violates functional cohesion, which is what we're really
striving for.
Procedural cohesion
is similar to temporal cohesion, but instead of time-based it's sequence-based. These are similar because
many things we do close together in time are also done in sequence, but that's not always the case.
There's not much to say here. You want to keep the definitions of functions that do things together structurally
close together in your code, assuming they have a reason to be close to begin with. For instance,
you wouldn't put two modules of code together if they're not at least logically cohesive to begin with. Ideally,
as in every other type of cohesion, you'll strive for functional cohesion first.
Communicational cohesion
typically looks like this:
some lines of code;
data = new Data();
function1(Data d) {...};
function2(Data d) {...};
some more lines of code;
In other words, you're keeping functions together that work on the same data.
Sequential cohesion
is much like procedural and temporal cohesion, except the reasoning behind it is that functions would
chain together where the output of one feeds the input of another.
Functional cohesion is the ultimate goal.
It's The Single Responsibility Principle [PDF] in
action. Your methods are short and to the point. Ones that are related are grouped together locally in a file.
Even files or classes contribute to one purpose and do it well. Using the IO example from above, you might have
a directory structure for each device, and within it, a class for Input and one for Output. Those would be children
of abstract I/O classes that implemented all but the device-specific pieces of code.
(I use inheritance terminology here only
as a subject that I believe communicates the idea to others. Of course, you don't have to even have inheritance
available to you to achieve the goal of keeping device agnostic code in one locale while keeping the device
specific code apart from it).
Examples from each category of coupling
Content coupling is horrific. You see it all over the place. It's probably in a lot of your code, and
you don't realize it. It's often referred to a violation of encapsulation in OO-speak, and it looks like one
piece of code reaching into another, without regard to any specified interfaces or respecting privacy. The problem
with it is that when you rely on an internal implementation as opposed to an explicit interface, any time that
module you rely on changes, you have to change too:
module A
data_member = 10
end
module B
10 * A->data_member
end
What if data_member was really called num_times_accessed? Well, now you're screwed since you're
not calculating it.
Common coupling
occurs all the time too. The Wikipedia article mentions global variables, but this could be just a member in a class
where two or more functions rely on it if you consider it. It's not as bad when its encapsulated behind an interface,
where instead of accessing the resource directly, you do so indirectly, which allows you to change internal
behavior behind the wall, and keeps your other units of code from having to change every time the shared resource
changes.
An example of external coupling is a program where one part of the code reads a specific file format that
another part of the code wrote. Both pieces need to know the format so when one changes, the other must as well.
unit A
write_csv_format();
end
unit B // in another file, probably
read_csv_format();
end
Control coupling
might look like:
// unit A
function do(what){
if(what == 1) do_wop;
else if (what == 2) ba_ba_da_da_da_do_wop;
}
// unit B
A.do(1);
Stamp coupling (Data-structured coupling)
involved disparate pieces of code touching the same data structure in different ways. For example:
employee = { :age => 24, :compensation=> 2000 }
def age_range(employee)
range = 1 if employee[:age] < 10
range = 2 if employee[:age] > 10 && < 20;
...
return range
end
def compensation_range(employee)
... only relies on employee[:compensation] ...
end
The two functions don't need the employee structure, but they rely on it and if it changes, those two functions
have to change. It's much better to just pass the values and let them operate on that.
Data coupling
is starting to get to where we need to be. One module depends on another for data. It's a typical function call with parameters:
// in module A
B.add(2, 4)
Message coupling
looks like data coupling, but it's even looser because two modules communicate indirectly without ever passing
each other data. Method calls have no parameters, in other words.
No coupling, like Wikipedia says, is when "modules do not communicate at all with one another."
There is no dependency from code A to code B.
Concluding Remarks
So how do we reconcile the thought that "if I separate code to increase functional cohesion, I introduce dependencies
which is going to increase coupling" with the assertion that low coupling and high cohesion go hand in hand? To do that,
you must recognize that the dependencies already exist. Perhaps not at the class level, but they do at the lines of
code level. By pulling them out into related units, you remove the spaghetti structure (if you can call it that)
and turn it into something much more manageable.
A system of code can never be completely de-coupled unless it does nothing. Cohesion is a different story.
I can't claim that your code cannot be perfectly cohesive, but I can't claim that it can. My belief is it
can be very close, but at some point you'll encounter diminishing returns on your quest to make it so.
The key takeaway is to start looking at your code and think about what you can do to improve it as you notice
the relationships between each line you write start take shape.
Comments and corrections(!) are encouraged. What are your thoughts?
Posted by Sam on Jun 18, 2009 at 12:00 AM UTC - 5 hrs
Don't encode information into a string like "AAHD09102008BSHC813" and give that gibberish to people. Don't name your project that, don't give that to me as a value or way to identify something, and don't make humans see or interact with that in any form. (If you are generating something similar and parse it with a program in automated fashion, I don't care what you call it.)
Give it a name we can use while communicating with each other and keep the rest of the information in a database. I can look it up if I need to know it.
Do not use file names, folder names, or project names as your as your database. I don't want to be required to scan each item in whatever set you chose and translate it using a lookup table to find what I'm looking for. I don't want to memorize the lookup table either.
Posted by Sam on Jul 21, 2009 at 12:00 AM UTC - 5 hrs
The other day I went to a major pizza chain's website to order online. I had to create an account first, of course.
No big deal.
As I was choosing my password, I was pleased to see a password strength indicator to the right. Excellent,
it's telling my password is "too short" -- let me add some more characters. "Warning: Too Simple" it said.
Great - now I'll add some numbers in there. My password strength was now "good," but since they were going
to be storing my personal details, I wanted a "great" password. I like to throw characters in there that
aren't letters or numbers, so I did. And it told me my password strength was "great."
More...
Even better that they gave a color indication as well - going from red to green as my password got
sufficiently strong.
You can imagine my disappointment when I hit the "Go" button, only to be presented with this message:
Please enter a valid password. Valid passwords must be at least 8 characters in length and contain letters and numbers only.
Look, I understand the allure of arbitrarily limiting these things. You secretly want someone to put in those special characters just so they can
see how good you were to have the foresight that someone might try to use one.
When I first started programming for money I did the same thing. Even though we were on a modern OS with
very few limitations on filenames, I wrote the application such that it would enforce MS DOS filename restrictions,
and only allowed letters and numbers. I spent extra effort to make sure the application would fail
on completely valid input.
As a consequence, strange bugs pop up because that app is not the only interface, and the system is less usable for the customer.
I know most of you in this audience already know you shouldn't design "features" like this. But for the
newbies that haven't yet had enough experience to know: If you don't have a valid reason for
constraining the data, don't do it just to show off what you can do.
It's an annoyance at best. It adds complexity where none is needed,
making your application harder to maintain over time. At worst, it results in defects that your customer
paid you to insert into the application. And that's a tragedy of ethics.
Posted by Sam on Aug 11, 2009 at 12:00 AM UTC - 5 hrs
The other day on twitter I asked about large projects, and I wanted to
bring the question to the larger audience here.
We hear vague descriptions about project size tossed about all the time:
Ruby on Rails is better for small projects. Java is for large projects. Skip the framework for
small projects, but I recommend using one for large projects.
More...
What factors go into determining the "size" of a project? Certainly lines of code and the size of the team are
considerations. Perhaps we should include the number of users as well. What would you add?
I suspect that to developers who tend to work alone on projects, a large one might be dozens of thousands of lines
of code. For those who work in moderate size teams, say with half a dozen members, we might hear a few hundred
thousand lines of code. For large teams in the teen-range, I'd expect millions of lines. What about teams with
50-100 developers?
I think makes a difference when you're giving advice on various aspects as to what constitutes a large project (or, if
you believe the advice is relative in those aspects, say why), so I'm interested to hear your thoughts.
So I ask, what is a "large project" to you? What do you think it means to others?
Those who've been reading My Secret Life as a Spaghetti Coder for a long time will know I totallylove IDEA.
I haven't written software in Java for quite some time, and I don't normally do "news" posts, but I know enough of you are into Java, Groovy, and Scala to make this worth your while if the $249 was pricey enough to force you into using lesser Java IDEs. Now you don't have to.
Posted by Sam on Feb 20, 2008 at 07:11 AM UTC - 5 hrs
A little while ago I was trying to think of ways to have a program compare strings
and discover patterns among them (as opposed to knowing patterns and looking for particular ones).
Over the years, I've learned about a lot of algorithms, but there's no way I could recall
all of them. I knew I'd probably need to look at artificial intelligence, or more specifically,
machine learning. But that's all I had to go on.
At the time, I decided it would be helpful to have a list of algorithms and
data structures with short descriptions to browse and jog my memory.
More...
Most of the problems you'll solve in your programming career don't require a lot
of thought to arrive at a correct solution. But algorithms, data structures, and
approaches to problems aren't just limited to the realm of programming. Reg Braithwaite
reminds us of another reason to have these things at your disposal -
even the problem of determining
who to hire can be reduced to Naïve Bayes Classification.
And when you have those problems where
there is no human solution (how can I discover patterns in several strings
which may have hundreds of characters?), or the computer solution takes too long to
find the optimal one where good enough will do, or there just isn't necessarily a
right answer -- those are the hard ones where you aren't likely to stumble upon an
answer -- where do you turn?
It turns out, a lot of problems can be reduced to others we already know how to solve.
In fact, the basis of proving complexity class for an algorithm utilizes that: reduction of one
problem to another will prove that if you solve the first one, you can solve the second one,
and it will be just as complex. A famous example is
SAT.
I haven't yet compiled the list I spoke of above, but luckily for all of us,
Wikipedia has a good starting point.
It's missing a couple that stand out in my mind
(or that have a different name I didn't look for, or multiple classifications and it
didn't make it to the one I looked at), but that's just
something I can put on my to-do list to improve. The Machine Learning category, for instance,
seems fairly light.
So just browsing a list and short description of algorithms may enlighten you as to how you
can reduce your problem to one that's already been solved. If you can do that, you've got a solution
from someone who's probably much smarter than you are. It's as if you have
Donald Knuth and the rest of computer
science academia on your team, and you don't even have to pay them (except, perhaps by buying
their book, or subscribing to a journal that will disseminate their knowledge).
I find it interesting that lots of people write about how to produce clean code,
how to do good design, taking care about language choice, interfaces, etc, but few people
write about the cases where there isn't time... So, I need to know what are the forces that tell you
to use a jolly good bodge?
I suspect we don't hear much about it because these other problems are often caused by that excuse.
And, in the long run, taking on that technical debt will likely cause you to go so slow that that's the
more interesting problem. In other words, by ignoring the need for good code, you are jumping into
a downward spiral where you are giving yourself even less time (or, making it take so long to do anything
that you may as well have less time).
More...
I think the solution is to start under-promising and over-delivering, as opposed to how most of us do it
now: giving lowball estimates because we think that's what they want to hear. But why lie to them?
If you're using iterative and incremental development, then if you've over-promised one iteration, you
are supposed to dial down your estimates for what you can accomplish in subsequent iterations, until
you finally get good at estimating. And estimates should include what it takes to do it right.
That's the party-line answer to the question. In short: it's never OK to write sloppy code, and
you should take precautions against ever putting yourself in a situation where those
viscous forces pull you in that direction.
In those cases where you've already painted yourself into a corner, what then? That's the interesting
question here. How do you know the best
places to hack crapcode together and ignore those things that may take a little longer in the short run, but
whose value shows up in the long run?
The easy answer is the obvious one: cut corners in the code that is least likely to need to change or
be touched again. That's because (assuming your hack works) if we don't have to look at the code again,
who really cares that it was a nasty hack? The question whose answer is not so easy or
obvious is "what does such a place in the code look like?"
By the definition above, it would be the lower levels of your code. But if you do that, and inject a bug, then
many other parts of your application would be affected. So maybe that's not the right place to do it.
Instead, it would be better to do it in the higher levels, on which very little (if any) other code
depends. That way, you limit the effects of it. More importantly, if there are no outgoing dependencies
on it, it is easier to change than if other code were highly dependent on it. [1]
Maybe the crapcode can be isolated: if a class is already aweful, can you derive a new class from it and
make any new additions with higher quality? If a class is of high quality and you need to hack something together,
can you make a child class and put the hack there? [2]
In the end, there is no easy answer that I can find where I would definitively say, "that's the place for a bodging."
But I suspect there are some patterns we can look for, and I tried to identify a couple of those above.
Do you have any candidates you'd like to share?
Notes: [1] A passing thought for which I have no answers:
The problem with even identifying those places is that by hacking together solutions, you are more likely
to inject defects into the code, which makes it more likely you'll need to touch it again.
[2] I use inheritance here because the new classes should be
able to be used without violating LSP.
However, you may very well be able to make those changes by favoring composition.
If you can, I'd advocate doing so.
Posted by Sam on Feb 13, 2008 at 08:44 AM UTC - 5 hrs
One step back from greatness lies the very definition of the impossible leadership situation:
a president affiliated with a set of established commitments that have in the course of
events been called into question as failed or irrelevant responses to the problems of the day...
The instinctive political stance of the establishment affiliate -- to affirm and continue the
work of the past -- becomes at these moments a threat to the vitality, if not survival,
of the nations, and leadership collapses upon a dismal choice. To affirm established
commitments is to stigmatize oneself as a symptom of the nation's problems and the premier
symbol of systemic political failure; to repudiate them is to become isolated from one's most
natural political allies and to be rendered impotent.
A little while ago Obie asked "What's this crap about a Ruby backlash?" The whole situation has reminded me of Skowronek's work, so I dug a couple of passages up.
We're at a crossroads right now between two regimes - one represented by Java, and the other represented by Ruby (although it is quite a bit more nuanced than that). My belief right now is that Java The Language is in a position where it can't win. People are fed up with the sameoldcrap, and a change is happening (see also: Why Do I Have To Tell The Compiler Twice?, or Adventures in Talking To a Compiler That Doesn't Listen.)
More...
What these [reconstructive] presidents did, and what their predecessors could not do, was to
reformulate the nation's political agenda altogether, ... and to move the nation past the old
problems, eyeing a different set of possibilities... (Skowronek, pg. 38)
When the new regime starts gaining momentum, in the old regime there will be wailing and gnashing of teeth. We can see some of this in the dogma repeated by Ruby's detractors alluded to (but not sourced) by Daniel Spiewak. We hear it in the fear in people's comments when they fail to criticize the ideas, relying instead on ad hominem attacks that have little to nothing to do with the issues at hand.
(Unlike Obie, I don't have any reason to call attention to anyone by name. If you honestly haven't seen this, let's try i don't like ruby, ruby sucks, and ruby is slow and see if we can weed through the sarcasm, apologists who parrot the line so as not to offend people, or just those exact words with no other substance. )
Neal Gafter quotes himself and Joshua Bloch in Is Java Dying? (where he concludes that it isn't):
Neal Gafter: "If you don't want to change the meaning of anything ever, you have no choice but to not do anything. The trick is to minimize the effect of the changes while enabling as much as possible. I think there's still a lot of room for adding functionality without breaking existing stuff..."
Josh Bloch: "My view of what really happens is a little bit morbid. I think that languages and platforms age by getting larger and clunkier until they fall over of their own weight and die very very slowly, like over ... well, they're all still alive (though not many are programming Cobol anymore). I think it's a great thing, I really love it. I think it's marvelous. It's the cycle of birth, and growth, and death. I remember James saying to me [...] eight years ago 'It's really great when you get to hit the reset button every once and a while.'"
To me, the debate is starting to look a lot like the regime change Skowronek's work predicts when going from a vulnerable establishment regime where an outsider reconstructs a new one.
I'm not saying Ruby itself will supplant Java. But it certainly could be a piece of the polyglotprogramming puzzle that will do it. It's more of an overall paradigm shift than a language one, so although I say one part is represented by Java and another by Ruby, I hope you won't take me literally.
Franklin Roosevelt was the candidate with "clean hands" at a moment when failed policies,
broken promises, and embarrassed clients were indicting a long-established political order.
Agitating for a rout in 1932, he inveighed against the entire "Republican leadership." He
denounced them as false prophets of prosperity, charged them with incompetence in dealing with
economic calamity, and convicted them of intransigence in the face of social desperation.
Declaring their regime morally bankrupt, he campaigned to cut the knot, to raise a new standard,
to restore to American government the ancient truths that had first inspired it.
(Skowronek, pg 288)
Hoover's inability to take the final step in innovation and
repudiate the system he was transforming served his critic's well... Hoover would later
lament the people's failure to appreciate the significance of his policies, and yet he was
the first to deny it. The crosscurrents of change in the politics of leadership left him with
an impressive string of policy successes, all of which added up to one colossal political
failure... Hoover sought to defend a system that he had already dispensed with...
What do you find hard about TDD? When you're developing and you see yourself
not writing tests but jamming out code, what causes those moments for you?
And have you really, in all honesty, ever reaped significant benefits either in
productivity or quality from unit testing? Because there's a pretty large contingent
of folks who don't get much mileage out of TDD, and I can see where they're coming from.
My TDD Stumbling Blocks
I'll address the first bit in one word: viscosity. When it's easier to do the wrong thing
than the right thing, that's when I "see myself not writing tests but jamming out code."
But what causes the viscosity for me? Several things, really:
More...
When I'm working with a new framework or technology and I don't know how to test it: I'm trying
to avoid this now by learning languages by unit testing.
However, it's still tough. I started writing tests in C# .NET recently, but moving things to
ASP.NET has made me stumble a bit. That's mostly because I didn't take the time to understand
how it all worked before I started using it, and now I'm in the process of rewriting that code before it becomes too
entrenched.
UIs: I still don't understand how to test them effectively. I like Selenium for the web,
but most tests I write with it are brittle. Because of that, I write them flippantly. It's a
vicious cycle too: without learning what works, I won't get better at identifying strategies to
remove the viscosity, so I won't write the tests.
That last one is a killer for me. When I'm working on new projects, it's incredibly easy to write
tests as I develop. So much so that I don't bother thinking about not doing it. Unfortunately, most
of my work is not in new code bases.
I should also note that I often don't bother unit testing one-off throwaway scripts, but there
are times when I do.
On top of that, my unit tests rarely stay unit-sized. I generally just
let them turn into integration tests (stubbing objects as I need them when they are still
unit-sized). The only time I bother with mocks are if the integration piece is taking too long
to run tests.
For example, I might let the tests hit a testing database for a while, but as the tests get unbearable
to run, I'll write a different class to use that just returns some pre-done queries, or runs
all the logic except for save().
What about rewards?
In Code Complete 2, Steve McConnell talks about why it's important to measure experiments when
tuning your code:
Experience doesn't help much with optimization either. A person's experience might have
come from an old machine, language, or compiler - when any of those things changes, all
bets are off. You can never be sure about the effect of an optimization until you
measure the effect. (McConnell, 603)
I bring that up because I think of TDD (and any other practice we might do while
developing) as an optimization, and to be sure about it's effects, I'd have to measure it.
I haven't measured myself with TDD and without, so you can take what follows as anecdotal
evidence only. (Just because I say that, don't think you can try TDD for a couple of days
and decide it's slowing you down so it doesn't bring any benefit - it takes a while to
realize many of the benefits.)
So what rewards have I noticed? Like the problems I've had, there are a few:
Better design: My design without TDD has been a train wreck (much of that due to my
past ignorance of design principles), but has (still) improved as a result of TDD.
After all, TDD is a design activity. When writing a test, or determining what test to write next, you
are actively involved in thinking about how you want your code to behave, and how you want to
be able to reuse it.
As a byproduct of writing the tests, you get a very modular design - it becomes harder to do
the wrong thing (bad design), and easier to keep methods short and cohesive.
Less fear: Do you have any code that you just hate to touch because of the horror it sends
down your spine? I do. I've had code that is so complex and wrapped up within itself that I've
literally counseled not changing it for fear of it breaking and not being able to fix it. My
bet is that you've probably seen similar code.
The improved design TDD leads to helps that to some extent obviously. But there may be times
when even though you've got a test for something, it's still ugly code that could break easily.
The upside though, is you don't need to fear it breaking. In fact, if you think about it,
the fear isn't so much that you'll break the code - you fear you won't know you've broken it.
With good tests, you know when you've broken something and you can fix it before you deploy.
Time savings: It does take some time to write tests, but not as much as you might think.
As far as thinking about what you want your code to do, and how you want to reuse it, my
belief is that you are doing those things anyway. If not, you probably should be, and your
code likely looks much the same as some of that which I have to deal with
(for a description, see the title of this weblog).
It saves time as an executable specification - I don't have to trace through a big code base
to find out what a method does or how it's supposed to do it. I just look up the unit tests
and see it within a few clean lines.
Most of your tests will be 5-7 lines long, and you might have five tests per method. Even
if you just test the expected path through the code, ignoring exceptions and negative tests,
you'll be a lot better off and you'll only be writing one or two tests per method.
How long does that take? Maybe five minutes per test? (Which would put you at one minute per line!)
Maybe you won't achieve that velocity as you're learning the style of development, but certainly you could
be there (or better) after a month or two.
And you're testing anyway, right? I mean, you don't write code and check it in to development
without at least running it, do you? So, if you're programming from the bottom up, you've
already written a test runner of some sort to verify the results. What would it cost to
put that code into a test? Perhaps a minute or three, I would guess.
And now when you need to change that code, how long does it take you to login to the application,
find the page you need to run, fill out the form, and wait for a response to see if you were right?
If you're storing the result in the session, do you need to log out and go through the same process,
just to verify a simple calculation?
How much time would it save if you had written automated tests? Let's say it takes you two
minutes on average to verify a change each time you make one. If it took you half-an-hour
of thinking and writing five tests, then within 15 changes you've hit even and the rest is gravy.
How many times do you change the same piece of code? Once a year? Oh, but we didn't include all the
changes that occur during initial development. What if you got it wrong the first
time you made the fix? Certainly a piece of code changes 15 times even before you've got it
working in many cases.
Overall, I believe it does save time, but again, I haven't measured it. It's just all those little
things you do that take a few seconds at a time - you don't notice them. Instead, you think
of them as little tasks to get you from one place to another. That's what TDD is like: but
you don't see it that way if you haven't been using it for a while. You see it as an
extra task - one thing added to do. Instead, it replaces a lot of tasks.
And wouldn't it be better if you could push a button and verify results?
That's been my experience with troubles and benefits. What's yours been like? If you haven't
tried it, or are new, I'm happy to entertain questions below (or privately if you prefer) as
well.
It's something to be expected, but as I thought about it, I wondered why.
It's not my intent here to draw negative attention by questioning the conventional wisdom of the status quo,
but I fear that may happen. I simply want to ask the obvious:
How many projects have you participated in where Unicode was an explicit or implicit requirement?
What percentage of the total do those make up? In the remainder of cases, would something
like Arc have been useful to you?
For the vast majority of projects I've worked on, having support for 9+ bit character sets or curly
quotes was not a requirement, and Arc would have been useful on the ones that didn't have a specific
language or platform requirement. (I understand if your work takes you there, but also understand
many of ours don't.)
Keep it civil and topical please. It's nothing but an observation and a question, not a statement of
religious belief spread with the fervor of a crusader.
Posted by Sam on Jan 30, 2008 at 07:34 AM UTC - 5 hrs
Because when you don't, how do you know your change to the code had any effect?
When a customer calls with a trouble ticket, do you just fix the problem, or do you
reproduce it first (a red test), make the fix, and test again (a green test, if you fixed the
problem)?
Likewise, if you write automated tests, but don't run them first to ensure
they fail, it defeats the purpose of having the test. Most of the time you won't
run into problems, but when you do, it's not fun trying to solve them. Who would
think to look at a test that's passing?
The solution, of course, is to forget about testing altogether. Then we won't be lulled into
a false sense of security. Right?
Posted by Sam on Jan 28, 2008 at 06:46 AM UTC - 5 hrs
I don't like to have too many microposts on this blog, so I've decided to save them up and start
a Programming Quotables series. The idea is that I'll post quotes about programming that have one or more of the
following attributes:
I find funny
I find asinine
I find insightfully true
And stand on their own, with little to no comment needed
Here's the second in that series. I hope you enjoy them as much as I did:
More...
Now we can see that although each language provides abstraction mechanisms, and lets you build new abstractions with the mechanism, new kinds of abstractions give us new ways to express relationships. These things can be abused, of course, but nothing can save you from this: If you don't let your Architect play with Domain-Specific Languages, what is to stop them from configuring everything in your application with XML?
The earlier Ages were times when people were unsure how best to deliver business value through software development. They piled process on top of process, hoping that by finding and perfecting the right process they could ensure timely delivery of valuable software in a predictable way. When it didn't work, they logically assumed the best approach would be to do even more of the stuff that wasn't working, and to monitor the stuff very tightly with high-ceremony process controls.
Then again, all one has to do to out-perform a traditional development team is Not Suck. It doesn't even require agile development methods. Obviously, to Not Suck is a great step forward. But surely it isn't your ultimate professional goal!
Language expertise is fine, but it isn't the most valuable thing out there. If someone programs conscientiously, I can work with them. I have a lot of respect for people who write solid code despite not having completely up to date language knowledge. Language knowledge is easy: you read, you think, you try. And, you can catch up. Conscientiousness, though, is the thing that really matters. Next to it, language expertise is easy.
It's obvious now, though, isn't it? A design pattern isn't a feature. A Factory isn't a feature, nor is a Delegate nor a Proxy nor a Bridge. They "enable" features in a very loose sense, by providing nice boxes to hold the features in. But boxes and bags and shelves take space. And design patterns - at least most of the patterns in the "Gang of Four" book - make code bases get bigger. Tragically, the only GoF pattern that can help code get smaller (Interpreter) is utterly ignored by programmers who otherwise have the names of Design Patterns tatooed on their various body parts.
Steve Yegge, Code's Worst Enemy (Really, you should read the whole thing. It's important.)
Posted by Sam on Jan 23, 2008 at 10:35 AM UTC - 5 hrs
Suppose you want to share some data that one object produces with another object as the consumer. How would you go about doing that?
If you took a straightforward approach, you might have Producer call consumer.method("data") and pass it the data that way. On the other hand, you could have Consumer get the data it needs by requesting it from Producer with something like this: myData = producer.getData().
However, perhaps Producer and Consumer shouldn't know anything about each other. Then you might introduce an Intermediary that gets the data from Producer and passes it to Consumer with something like consumer.myData = producer.getData()
Now if you want to get really creative, you could make Producer write its data to an XML file, and then have Consumer read the data from there.
But why?
Disagreements and horror stories are encouraged below.
I think you have a great concept going. I really would like to find out HOW you became passionate about programming? I just graduated with a BS in CIS and am looking for an entry level IT job, HOWEVER I am not a bit excited about computers anymore. Like you I was just planning on continuing my education -get my MBA. But I know an IT job is what I went to school for. HELP! How do I get excited about an IT job when I can't even figure out what title to put on a job search? just degree in CIS?!
I started to comment, but as it became longer, I decided it might benefit others as a standalone post.
More...
I think you just have to make the decision to be passionate. Wake up in the morning and think about how lucky you are. Decide to enjoy the day, and to enjoy what you do. But you can do better.
Think about what drew you to the profession in the first place, and try to get a job doing that. If you can't get one in a timely fashion, try to get a job doing something similar and spend your free time working on side projects that interest you. That's a lot of what I'm doing.
For me, it is learning new things and gaming that I enjoy most. So, I spend a lot of time doing that. I still have to do grunt work, but I get equal doses of fun stuff too - all the while I am expanding my skill set and enjoying most of it.
As far as the job search goes, I'd recommend networking with people. Visit the local User Groups, get involved in forums and mailing lists. Learn things and share them, and people will eventually come to you with jobs. Even though I like the computers, I've found that I really enjoy the relationships with people who also like computers. Before, I stayed locked in a room thinking and working by myself. Now, I venture out from time to time, and in addition, I have the online relationships I enjoy immensely.
Since you probably can't afford to live that long without a job, perhaps in the mean time you can go to a career fair at a local university or just use the search term "programming" and browse jobs until you find one that interests you.
I'd also read many different weblogs about programming to stay up to date on trends in the industry, as well as to receive solid advice that stands the test of time.
Just as importantly, take a look back at your own situation. Can you identify anything that may be causing your malaise? If so, can you remove it? It may be as simple as that.
To the rest of you: how do you maintain and find passion in your work when you seem to have lost it?
Posted by Sam on Jan 18, 2008 at 09:05 AM UTC - 5 hrs
You feel, look, and do better when you are accomplishing goals and showing progress. That's one
reason you'll find it in this week's advice from MJWTI.
The chapter is called "Daily Hit" and in it Chad recommends "setting a goal (daily, weekly, or
whatever you're capable of) and tracking this type of accomplishment." Make sure it's known to
your manager as well - don't let the underpants gnomes take credit for your
success. Also, the shorter the distance between hits the better, since "if you're supposed to produce a
hit per day, you can't spend two weeks tracking the perfect task."
More...
I work in an environment where it wouldn't benefit me to "tell the manager" about my daily hits.
They know already. But you might want to make yours known. Obviously you don't want to
be braggadocious about it, but don't keep it to yourself either.
I like to do more than one hit per day. One is the absolute minimum. I try to get an overview
of what needs to be done during the week, and create a high level plan in my mind over the weekend.
I'll set each day's tasks and the time I'll be working on them on the day before. Then, I stick
to the plan.
Even when I don't finish a task in the time allotted, I can reschedule and finish it the next day. In this way, I'm always
having small successes which keeps me motivated and moving along towards my goals.
We're not talking about just what has to be done - it's about going above and beyond that. Chad ends the chapter with the advice to make a list of the "nitpicky problems" you and your team face that waste a little time each day, and starting to do some work on those things. I've done some of that, but there's plenty left to do, and re-reading this chapter reminded me that I need to start scheduling those things as well.
Posted by Sam on Jan 14, 2008 at 06:42 AM UTC - 5 hrs
This is a story about my journey as a programmer, the major highs and lows I've had along the way, and
how this post came to be. It's not about how ecstasy made me a better programmer, so I apologize if that's why you came.
In any case, we'll start at the end, jump to
the beginning, and move along back to today. It's long, but I hope the read is as rewarding as the write.
The experiences discussed herein were valuable in their own right, but the challenge itself is rewarding
as well. How often do we pause to reflect on what we've learned, and more importantly, how it has changed
us? Because of that, I recommend you perform the exercise as well.
I freely admit that some of this isn't necessarily caused by my experiences with the language alone - but
instead shaped by the languages and my experiences surrounding the times.
One last bit of administrata: Some of these memories are over a decade old, and therefore may bleed together
and/or be unfactual. Please forgive the minor errors due to memory loss.
Before I was 10, I had a notepad with designs for my as-yet-unreleased blockbuster of a side-scrolling game that would run on
my very own Super Sanola game console (I had the shell designed, not the electronics).
It was that intense interest in how to make a game that led me to inspect some of the source code Microsoft
provided with QBASIC. After learning PRINT, INPUT,
IF..THEN, and GOTO (and of course SomeLabel: to go to)
I was ready to take a shot at my first text-based adventure game.
The game wasn't all that big - consisting of a few rooms, the NEWS
directions, swinging of a sword against a few monsters, and keeping track of treasure and stats for everything -
but it was a complete mess.
The experience with QBASIC taught me that, for any given program of sufficient complexity, you really only
need three to four language constructs:
Input
Output
Conditional statements
Control structures
Even the control structures may not be necessary there. Why? Suppose you know a set of operations will
be performed an unknown but arbitrary amount of times. Suppose also that it will
be performed less than X number of times, where X is a known quantity smaller than infinity. Then you
can simply write out X number of conditionals to cover all the cases. Not efficient, but not a requirement
either.
Unfortunately, that experience and its lesson stuck with me for a while. (Hence, the title of this weblog.)
Side Note: The number of language constructs I mentioned that are necessary is not from a scientific
source - just from the top of my head at the time I wrote it. If I'm wrong on the amount (be it too high or too low), I always appreciate corrections in the comments.
What ANSI Art taught me about programming
When I started making ANSI art, I was unaware
of TheDraw. Instead, I opened up those .ans files I
enjoyed looking at so much in MS-DOS Editor to
see how it was done. A bunch of escape codes and blocks
came together to produce a thing of visual beauty.
Since all I knew about were the escape codes and the blocks (alt-177, 178, 219-223 mostly), naturally
I used the MS-DOS Editor to create my own art. The limitations of the medium were
strangling, but that was what made it fun.
And I'm sure you can imagine the pain - worse than programming in an assembly language (at least for relatively
small programs).
Nevertheless, the experience taught me some valuable lessons:
Even though we value people over tools, don't underestimate
the value of a good tool. In fact, when attempting anything new to you, see if there's a tool that can
help you. Back then, I was on local BBSs, and not
the 1337 ones when I first started out. Now, the Internet is ubiquitous. We don't have an excuse anymore.
I can now navigate through really bad code (and code that is limited by the language)
a bit easier than I might otherwise have been able to do. I might have to do some experimenting to see what the symbols mean,
but I imagine everyone would.
And to be fair, I'm sure years of personally producing such crapcode also has
something to do with my navigation abilities.
Perhaps most importantly, it taught me the value of working in small chunks and
taking baby steps.
When you can't see the result of what you're doing, you've got to constantly check the results
of the latest change, and most software systems are like that. Moreover, when you encounter
something unexpected, an effective approach is to isolate the problem by isolating the
code. In doing so, you can reproduce the problem and problem area, making the fix much
easier.
The Middle Years (included for completeness' sake)
The middle years included exposure to Turbo Pascal,
MASM, C, and C++, and some small experiences in other places as well. Although I learned many lessons,
there are far too many to list here, and most are so small as to not be significant on their own.
Therefore, they are uninteresting for the purposes of this post.
However, there were two lessons I learned from this time (but not during) that are significant:
As you can tell, I was quite the cowboy coding young buck. I've tried to change that in recent years.
How ColdFusion made me a better programmer when I use Java
Although I've written a ton of bad code in ColdFusion, I've also written a couple of good lines
here and there. I came into ColdFusion with the experiences I've related above this, and my early times
with it definitely illustrate that fact. I cared nothing for small files, knew nothing of abstraction,
and horrendous god-files were created as a result.
If you're a fan of Italian food, looking through my code would make your mouth water.
DRY principle?
Forget about it. I still thought code reuse meant copy and paste.
Still, ColdFusion taught me one important aspect that got me started on the path to
Object Oriented Enlightenment:
Database access shouldn't require several lines of boilerplate code to execute one line of SQL.
Because of my experience with ColdFusion, I wrote my first reusable class in Java that took the boilerplating away, let me instantiate a single object,
and use it for queries.
How Java taught me to write better programs in Ruby, C#, CF and others
It was around the time I started using Java quite a bit that I discovered Uncle Bob's Principles of OOD,
so much of the improvement here is only indirectly related to Java.
Sure, I had heard about object oriented programming, but either I shrugged it off ("who needs that?") or
didn't "get" it (or more likely, a combination of both).
Whatever it was, it took a couple of years of revisiting my own crapcode in ColdFusion and Java as a "professional"
to tip me over the edge. I had to find a better way: Grad school here I come!
The better way was to find a new career. I was going to enter as a Political Scientist
and drop programming altogether. I had seemingly lost all passion for the subject.
Fortunately for me now, the political science department wasn't accepting Spring entrance, so I decide to
at least get started in computer science. Even more luckily, that first semester
Venkat introduced me to the solution to many my problems,
and got me excited about programming again.
I was using Java fairly heavily during all this time, so learning the principles behind OO in depth and
in Java allowed me to extrapolate that for use in other languages.
I focused on principles, not recipes.
On top of it all, Java taught me about unit testing with
JUnit. Now, the first thing I look for when evaluating a language
is a unit testing framework.
What Ruby taught me that the others didn't
My experience with Ruby over the last year or so has been invaluable. In particular, there are four
lessons I've taken (or am in the process of taking):
The importance of code as data, or higher-order functions, or first-order functions, or blocks or
closures: After learning how to appropriately use yield, I really miss it when I'm
using a language where it's lacking.
Metaprogramming is OK. Before Ruby, I used metaprogramming very sparingly. Part of that is because
I didn't understand it, and the other part is I didn't take the time to understand it because I
had heard how slow it can make your programs.
Needless to say, after seeing it in action in Ruby, I started using those features more extensively
everywhere else. After seeing Rails, I very rarely write queries in ColdFusion - instead, I've
got a component that takes care of it for me.
Because of my interests in Java and Ruby, I've recently started browsing JRuby's source code
and issue tracker.
I'm not yet able to put into words what I'm learning, but that time will come with
some more experience. In any case, I can't imagine that I'll learn nothing from the likes of
Charlie Nutter, Ola Bini,
Thomas Enebo, and others. Can you?
What's next?
Missing from my experience has been a functional language. Sure, I had a tiny bit of Lisp in college, but
not enough to say I got anything out of it. So this year, I'm going to do something useful and not useful
in Erlang. Perhaps next I'll go for Lisp. We'll see where time takes me after that.
That's been my journey. What's yours been like?
Now that I've written that post, I have a request for a post I'd like to see:
What have you learned from a non-programming-related discipline that's made you a better programmer?
Posted by Sam on Jan 07, 2008 at 06:42 AM UTC - 5 hrs
A note to myself (a .NET neophyte) and others who may not know how ASP.NET works:
I was writing a user control (we'll call it ContentBoxVariation) in ASP.NET which composes another (ContentBox). Both have a public property Title, with getters and setters.
You might call ContentBoxVariation in an .aspx page like this:
More...
<aNamespace:ContentBoxVariation" ID="ContentBoxVariation1" Title="Welcome to Sam's" runat="server"/>
Then ContentBoxVariation includes ContentBox like this:
You might think that the ContentBoxVariation would pass it's Title to the ContentBox, and that the result would be "Welcome to Sam's."
Unfortunately, it does pass it's title, but the title hasn't been changed from its default of "" at the time it happens. As far as I can tell, the instantiation happens in this order:
Instantiate ContentBoxVariation
Instantiate the composed ContentBox
Set ContentBox's Title to the variation's title, which is currently "". Even if setting it to a different variable, it seems to stay blank as if that variable doesn't exist, even though it does and no error occurs.
Set the variation's title.
The order makes sense if you are looking at it like that, but being in templates and looking at it from that point of view, it is surprising.
The solution is to explicitly set the title for ContentBox in code, like this:
Posted by Sam on Jan 04, 2008 at 07:01 AM UTC - 5 hrs
At the beginning of this week's chapter from My Job Went To India,
Chad Fowler relates a story about Rao, a "mind-reading" programmer who could pick up on the
subtleties in conversations and implement code before you realized you had asked for it.
Both when I first read this, and the second time around, alarms went off in my head: "What about
YAGNI?" Why would you implement something
that wasn't asked for? If you are wrong, you could be relieved of your position for wasting
time and money.
Thankfully, Chad addressed my concerns. It turns out,
More...
We might be standing around waiting for a pot of coffee to brew, and I would talk about how
great it would be if we had some new flexibility in our code that didn't exist before. If I
said it often enough or with enough conviction, even though I hadn't really put it on the
team's TO-DO list, Rao might fill the gaps between "real work" looking at the feasibility of
implementing one of these things. If it was easy (and cheap) to implement, he'd whip it
out and check it in.
(emphasis mine)
Chad also mentions the potential pitfalls in such an approach:
You waste time and money if the functionality was not needed
You increase complexity of the code base and make "it less resilient to change" if your
code forces "the system down a particular architectural path."
You could unintentionally make the application "less functional or desirable to the customer."
Honestly, I'd caution against using this advice unless you are in one of the following situations:
You've known the feature-requester long enough that you can pick up on things he's asking for, but hasn't
yet asked for. I think you should be really close in this situation. How can you predict otherwise?
There is obviously something missing from the spec, and you have enough experience with
similar systems to know it is missing. This might be something like "We need a login system."
You can probably safely assume they'll need a way to log out as well, and perhaps even
"I forgot my password" functionality.
The logout functionality I'd almost always toss in (unless requested otherwise). However, even
on the "forgot password" feature, I'd consider a couple of things. First, do I know the customer
well enough that we've done another application for them and they wanted it? Second, is the
budget big enough to where I know they won't be upset if I implement it?
There could be more, but that's what my brain thought of this morning. Of course, in many
cases it's just better to ask first.
Posted by Sam on Jan 02, 2008 at 08:40 PM UTC - 5 hrs
It's the new year, and it's time to get back in the swing of things after the hectic holiday season. I had planned on taking the rest of this week off from posting as well, but I'm starting to feel behind on things, so this will let me set down my goals and focus on them in the coming year.
I had actually planned a different post for today, but Dan Vega inspired me with his list of goals so that's why you're reading this instead. Like Dan, I'm going to try to keep mine positive and specific, with an emphasis on SMART objectives.
With no further ado, here are my top professional goals for 2008:
More...
Start regular practice sessions: When writing about my experiences with MJWTI, I resolved to practice programming. Therefore, that's on my list and I want to devote
between 1-3 hours per week to doing it. However, I also want to:
Devote more time to open source software: I already try to spend some time doing this, but I'd like to devote a day to it each week. My original
goal was to contribute 1 patch each week, but I didn't think that would be achievable as I plan to switch projects on occasion (for practice, above), and when I do, it is tough to come up to speed, much less provide a patch. So my goal will be to devote 4-6 hours of one day a week to open source, and a patch (however small) every three weeks.
This also means I'll be getting more practice, so I may confine the practice sessions to 1 hour and make those be the constraint-driven problems I mentioned in the article linked above. I have no goal for the number of accepted patches, just that I offer them to the project.
Do something not useful (and something useful) in Erlang: With multi-core processors becoming the norm, concurrent programming is going to get big. Since Erlang was designed with concurrency as a goal, it also has the potential to be big. This is a no-brainer to try and stay ahead of the curve. Obviously whatever useless and useful things I do in Erlang will need to have concurrent aspects to them.
Speak at a conference: I don't see this happening until 2009. The first half of this year I will be too busy to practice, much less attend and speak, so I'll plan on using the second half of 2008 as practice towards the ultimate goal of speaking at a conference (or multiple) in 2009.
Attend a conference (or multiple): First on my list is a ColdFusion conference, just to meet a lot of you that I exchange thoughts with on a regular basis. Second on my list is to attend a conference focused on a language or platform I don't use or that I am quite new to using. Third would be a Ruby conference. Finally, I'd like to re-attend a No Fluff Just Stuff symposium, since it was so rewarding the first time.
Realistically, the money situation right now (being a student until May) is too tight to even consider four conferences. Further, in June I'll be getting married, buying a house (or before then), and having a family to take care of, so even going to one conference may be financially irresponsible. Because of that, I'll have to reconsider this as time goes along, or see if I can get someone to pay for me to go. That leads me to my final, and most important goal:
Increase my earnings: I have several goals at the company I work for, but aside from those, I'd like to:
Get another regular source of income as a contractor. I'm also willing to take non-regular work, but ideally I'd find
a cool project to work on with a regular source of income, and with growth potential. I do have one in mind if it's still available, but I might like to take some more work as the year progresses.
Start implementing some of the things on my Ideas List instead of just continuing to add to it. Some of these might require
renting the ideas to companies, so forgive me for not sharing at the moment.
Posted by Sam on Dec 24, 2007 at 04:52 PM UTC - 5 hrs
Suppose for the purposes of our example we have string the_string of length n, and we're trying to determine if string the_substring of length m is found within the_string.
The straightforward approach in many languages would be to use a find() or indexOf() function on the string. It might look like this:
More...
However, if no such method exists, the straightforward approach would be to just scan all the substrings and compare them against the_substring until you find a match. Even if the aforementioned function exists, it likely uses the same strategy:
deffind_substring_pos(the_string,the_substring) (0..(the_string.length-1)).eachdo|i| this_sub=the_string[i,the_substring.length] returniifthis_sub==the_substring end returnnil end
That is an O(n) function, which is normally fast enough.
Even though I'm one of the guys who camps out in line so I can be one of the first to say "don't prematurely optimize your code," there are situations where the most straightforward way to program something just doesn't work. One of those situations is where you have a long string (or set of data), and you will need to do many comparisons over it looking for substrings. Although you'll find it in many cases, an example of the need for this I've seen relatively recently occurs in bioinformatics, when searching through an organism's genome for specific subsequences. (Can you think of any other examples you've seen?)
In that case, with m much smaller than a very large n, O(m * log n) represents a significant improvement over O(n) (or worst case m*n). We can get there with a suffix array.
Of course building the suffix array takes some time - so much so that if we had to build it for each comparison, we're better off with the straightforward approach. But the idea is that we'll build it once, and reuse it many times, amortizing the cost out to "negligible" over time.
The idea of the suffix array is that you store every suffix of a string (and it's position) in a sorted array. This way, you can do a binary search for the substring in log n time. After that, you just need to compare to see if the_substring is there, and if so, return the associated index.
The Wikipedia page linked above uses the example of "abracadabra." The suffix array would store each of these suffixes, in order:
a
abra
abracadabra
acadabra
adabra
bra
bracadabra
cadabra
dabra
ra
racadabra
Below is an implementation of a suffix array in Ruby. You might want to write a more efficient sort algorithm, as I'm not sure what approach Enumerable#sort takes. Also, you might want to take into account the
ability to get all substrings, not just the first one to be found.
classSuffixArray definitialize(the_string) @the_string=the_string @suffix_array=Array.new #build the suffixes last_index=the_string.length-1 (0..last_index).eachdo|i| the_suffix=the_string[i..last_index] the_position=i # << is the append (or push) operator for arrays in Ruby @suffix_array<<{:suffix=>the_suffix,:position=>the_position} end #sort the suffix array @suffix_array.sort!{|a,b|a[:suffix]<=>b[:suffix]} end deffind_substring(the_substring) #uses typical binary search high=@suffix_array.length-1 low=0 while(low<=high) mid=(high+low)/2 this_suffix=@suffix_array[mid][:suffix] compare_len=the_substring.length-1 comparison=this_suffix[0..compare_len] ifcomparison>the_substring high=mid-1 elsifcomparison<the_substring low=mid+1 else return@suffix_array[mid][:position] end end returnnil end end
sa=SuffixArray.new("abracadabra")
putssa.find_substring("ac")#outputs 3
Thoughts, corrections, and improvements are always appreciated.
Update: Thanks to Walter's comment below, the return statement above has been corrected.
Posted by Sam on Dec 21, 2007 at 12:38 PM UTC - 5 hrs
This seems to be becoming a theme here lately: DIFN.
That's the advice in MJWTI for this week, although Chad Fowler doesn't put it so bluntly.
In the chapter, Chad describes a race where the first team to complete a project over the weekend wins $100 thousand. Could you do it?
More...
How is it that an application
of similar scope to those we spend weeks working on in the office is going to get
finished in a single weekend?
We've all seen projects take weeks when they could be measured in days. So what gives?
The answer, of course, is that we aren't accustomed to doing it right now. Stop putting off tasks. Just do them.
To help meet that goal and create race conditions, I like to timebox my daily tasks.
From 5:30 to 6:15 I read my email do my morning blog reading. Then I take 15 minutes and enjoy a cold Red Bull. After that, I might work on Project A for 3 hours, then read email for 15 minutes. I've got half a days work done before most people get to the office. After that, I might switch to Project B for three more hours, and so on.
To keep track of what I should be working on and give myself pop-up reminders that it's time to change tasks, I've been using Apple's iCal, and it works pretty well.
My only problem is that as I need to work more often in Windows, I'm not using it as much, and particularly this week my productivity has been way down. (I admit, the impending holiday may have something to do with that as well.) However, FedEx just dropped off VMWare Fusion, so hopefully I won't need to boot into Windows anymore and the problem will be solved.
My only complaint against iCal itself is that I wish I didn't have to set up an email address in the mail client for it to send me an email - that's just annoying.
If you're not on a Mac, Google Calendar would work (except you're not getting the popup reminders). Even just spending 15 minutes before you leave work to plan the next day, and writing it on the whiteboard or some sticky-notes would likely be a major improvement for your work-day, and might even be better than a technology-based solution.
How have you made it easier on yourself to do it right now?
Posted by Sam on Dec 19, 2007 at 09:26 AM UTC - 5 hrs
A while back I started a Twitter account with the idea of using it as a tumblelog
for quotes about software that I wanted to highlight. Unfortunately, the small limit on the number of
characters Twitter enforces didn't allow me to post entire quotes, much less attribute them.
Likewise, I don't like to have too many microposts on this blog, so I've decided to save them up and start
a Quotables series. The idea is that I'll post quotes about programming that have one or more of the
following attributes:
I find funny
I find asinine
I find insightfully true
And stand on their own, with little to no comment needed
Here's the first in that series. I hope you enjoy them as much as I did:
More...
The odds of finding truly beautiful code in most production systems seem to be on par with
the odds of finding a well-read copy of IEEE Transactions on Software Engineering in Paris Hilton's
apartment.
If you can't make a decent web page in .NET you shouldn't be in the business.
-Commenter at Reddit or Digg (I can't seem to find it anymore, and I just copied the quote a couple of months ago)
You have to take responsibility for teaching yourself, and that is a far greater responsibility than skimming a book and fooling around copying and pasting code from web pages. You can't just take basic or even sketchy knowledge of how to program in one language and "transfer" it to another language. You think you can just "pick it up," but in reality you can't, and neither can I.
But the fatal flaw in the GoF book was that they included recipes.
And many people thought they were the best part. Even now, you see books on Java design patterns
that blindly mimic the structure of the examples in the GoF book (even though Java has some better
mechanisms, like interfaces vs. pure virtual classes). Recipes bad. Because they suggest more than just a way to name common things. They imply (and put in you face) implementation details.
Because of meta-programming, many of the design patterns in the GoF book (especially the structural ones) have much simpler, cleaner implementations. Yet if you come from a weaker language, your first impulse is to implement solutions just as you would from the recipe.
At some point, you have to have the guts to go against the grain. Just because a "best practice" works for someone else at some other company doesn't necessarily make it a "best practice" for you and your company. A "proven methodology" isn't necessarily going to be a "proven methodology" for you. Have the guts to challenge the status quo. If it's not making you more efficient, it's likely hindering you. Refactor it out.
Posted by Sam on Dec 14, 2007 at 03:33 PM UTC - 5 hrs
This week I return to following the advice in Chad's book. It's something I've been doing now for a while: automation.
I'm really big into automation - one of the things I really like to do is create developer tools, or even just small throwaway scripts that get
me through the day.
One paragraph that stuck with me was this one:
So, imagine your company is in the business of creating websites for small
businesses. You basically need to create the same site over and over again,
with contacts, surveys, shopping carts, the works. You could either hire
a small number of really fast programmers to build the sites for you, hire
an army of low-cost programmers to do the whole thing manually and
repetitively, or create a system for generating the sites.
Sound like anyoneyouknow? (Or any of the other people writing generators, automated testers, and the like?)
It was after reading that paragraph that I decided we needed to change things at work. Forget about code repetition, there was plenty of effort repetition as well. The first part of that process was getting cfrails together, the remaining part is to build a WYSIWYG editor for building sites - if I ever get around to it.
There are other things to automate besides frameworks that generate code. Neal Ford has a pair of talks (both links there are PDFs found via his past conferences page) he gives that illustrate a bunch of tips and "patterns" along these lines. I enjoyed both of them and will eventually get around to reviewing them. He also
mentioned that a book covering the topic is coming soon.
Getting back to MJWTI, Chad lists a "simple (minded) formula" to calculate productivity:
productivity = # projects or features or amount of work / (# programmers * average hourly rate)
At the end of the chapter he shows it in action: 5 units of work with 3 fast programmers at $80 per hour would be as productive as 20 programmers at $12 per hour on the same project (obviously ignoring the communication deficiencies and other pitfalls of a group that large). But if you are able to automate enough of your work, you can be the single programmer at $80 per hour on the same 5 units of work.
The exact math isn't what's important - the fact that you are more productive by automating as much as possible is.
In what ways do you automate your workday, no matter how big or small?
It's easy to say, "yes, we can publish software in the same manner." Every time we offer a
download, it's done just in time. This post was copied and downloaded (published) at the
moment you requested it.
What my question covers is this: Can we think of an idea that would be repeatable, sell
it to customers to fund the project, and then deliver it when it's done? (It should be sold to
many customers, as opposed to custom software, which is, for the most part, already developed in that manner.)
In essence, can we pre-sell vaporware?
We already pre-sell all types of software - but that software is (presumably) nearing a
releasable state (I've had my doubts about some of it). Can we take it to the next level
and sell something which doesn't yet exist?
If such a thing is possible, there are at least three things you'll need to
be successful (and I bet there are more):
A solid reputation for excellence in the domain you're selling to, or a salesperson with
such a reputation, and the trust that goes with it.
A small enough idea such that it can be implemented in a relatively short time-frame. This, I
gather, would be related to the industry in which you're selling the software.
An strong history of delivering products on time.
What do you think? Is it possible? If so, what other qualities do you need to possess to
be successful? If not, what makes you skeptical?
Posted by Sam on Dec 10, 2007 at 11:46 AM UTC - 5 hrs
Here's some pseudocode that got added to a production system that might just be the very definition of a simple change:
Add a link from one page to cancel_order.cfm?orderID=12345
In that new page, add the following two queries:
update orders set canceled = 1, canceledOn=getDate() where orderID=#url.orderID#
delete from orderItems
Now, upload those changes to the production server, and run it real quick to be sure it does what you meant it to do.
Then you say to yourself, "Wait, why is the page taking several seconds to load?"
"Holy $%^@," you think aloud, "I just deleted every item from every order in the system!"
It's easy enough for you to recover the data from the backups. It isn't quite as easy to recover from the heart attack.
Steve McConnell (among others) says that the easiest changes are the most important ones to test, as you aren't thinking quite as hard about it when you make them.
Posted by Sam on Dec 07, 2007 at 03:06 PM UTC - 5 hrs
When someone starts complaining about customers who are making silly requests, I normally say something like,
"I know! If it weren't for those damn customers, we'd have a perfect program!"
There'd be no one using it, but hey - the application would be sweeeeet.
This week I'm going to diverge from Chad's book on how to save your job. That's mostly
because I don't have the book with me, but this has been on my mind the last couple of days
anyway: the fear of success.
I've noticed it in myself and others from time to time - inexplicably sabotaging opportunities to succeed.
I try not to listen to that voice now if I can help it.
More recently, I've started to notice it in companies and customers as well - groups as opposed to individuals.
I've started wondering if reluctance to "go live" until the product was a symbol of perfection
fits in with this phenomenon.
More...
What can we do to help them get over this irrational behavior? If they continuously request those trivial changes
and never go live, the project has failed. Do you think they will blame themselves, their ideas, and their actions?
No, they will blame you, and find someone else to work with next time.
So you may have been paid for your time, but it still impacts you negatively.
Don't get me wrong - sometimes there are good reasons to wait to release a product or service. Sometimes,
you don't need to DIFN.
However, the fear
that your customers won't know to look under "output devices" to find a subcategory of "printers" is
probably not on that list of reasons. Someone has been using a product to great advantage
for many years
and you want to "wait until you finish the last bit" to sell it as a whole to others - also probably not
on that list. You want the login on the left hand side instead of the right?
After a week of such changes, it's one thing. Six months? GMAFB.
Perhaps you'd have been better off letting your customer's use it to see if they got confused, preferred
blue links to red ones, or even happened upon an idea to make the application flow better.
So what does make the "OK to wait"-list? The fear
of underwhelming an audience with your unfinished product would, especially if you're
get to show them exactly one time. I can't think of much else that does. Can you?
So the point is that you need to get over the fear of success. Stop snatching defeat from the jaws of
victory. Let a good thing or two happen. Help your customer's get past their fears.
Changing ourselves
to recognize that fear and ignore it is something we can all do. Looking at our customer's excuses to
keep the product in the warehouse from a fear-of-success angle might provide a way to relate to them
instead of scoffing at their incessant requests for frivolity.
Success is staring you in the face. All you have to do is stick your hand out and embrace hers. Why do
you turn and run away?
I'm exploring this space for the first time.
Obviously, I have a lot of questions and very few answers. If you've got either of them, let me know
in the comments - it's always appreciated.
Posted by Sam on Dec 05, 2007 at 07:02 AM UTC - 5 hrs
I'd like a codometer to count all the lines of code I write during the day. It should keep track of lines that get kept and lines that get removed. I don't know what that information would tell me, but I'm curious about it. It should probably work independent of the IDE, since I often use several during the day.
I'd like it if not only you would stop stealing my focus, but also provide updates in the corner of the screen. When I've put you in the background, you should let me know when you're done processing so I can come and click the "next" button. On top of that, give me an option to have you click next automatically for me.
Like 'considered harmful' being considered harmful as a cliché, I'm starting to have a distinct distaste for website or product names of the class e-removr. Or ending-vowel-removr when the last letter is an 'r'. The first time it seemed refreshing and perhaps a bit cute. By now, I'm starting to wish someone would flush them down the shittr. (Well, the names at least.)
Someone found a set of bicycle pedals that fit under the desk for me. Excellent to be able to get a little exercise while I do my morning blog-reading. I couldn't find one the last time I looked, but I did this time. I'm not sure if mine are the same, or how it will work, but I will let you know when I do.
Posted by Sam on Dec 03, 2007 at 06:32 AM UTC - 5 hrs
It's not a hard thing to come up with, but it's incredibly useful. Suppose you need to
iterate over each pair of values or indices in an array. Do you really want to
duplicate those nested loops in several places in your code? Of course not. Yet
another example of why code as data is such a powerful concept:
More...
classArray # define an iterator over each pair of indexes in an array defeach_pair_index (0..(self.length-1)).eachdo|i| ((i+1)..(self.length-1)).eachdo|j| yieldi,j end end end # define an iterator over each pair of values in an array for easy reuse defeach_pair self.each_pair_indexdo|i,j| yieldself[i],self[j] end end end
Now you can just call array.each_pair { |a,b| do_something_with(a, b) }.
Posted by Sam on Nov 30, 2007 at 06:46 AM UTC - 5 hrs
Although computer science is a young field of study, it is rife with examples of good and bad
ways to do things. This week's advice from MJWTI
instructs us to focus on the past - learn from the successes and failures of those who came before
us.
Chad includes a quote from a Jazz musician that illustrates the concept of how we
learn to become masters quite well:
My advice is to do it by the book, get good at the practices, then do as you will. Many people want to skip to step three. How do they know?
Similarly, part of code practice
involves studying other people's code.
Doing so is good to teach you new tricks and things to avoid. But as
Chad also mentions, it also exposes you to projects you might not have otherwise known about -
giving you the option in the future to reuse it instead of writing your own version if your
application requires it.
But not having those books won't stop me from reading source code - I plan to start that as
part of my weekly practice sessions. It fits so well with one of the things I'm most
interested in - improving the design of my own applications.
You can say you don't run into trouble and therefore, your design is good, but how would you know until
you've gone back to it after not looking at it for a year? You need something to compare it
to, and I'm not convinced a UML diagram will suffice.
In the end, Chad gives two action items to follow up on:
Pick a project to read, make notes, and "outline the good and the bad." Use that
experience to publish a critique of
the project and it's code.
Start a study group to dissect and learn from code.
I'd like to start reading other source code, but I'm not sure when I'll publish a critique of
it. On top of that, one of the things I'd like to do in the code dojo is dissect other people's code, even
if I already find it helpful to analyze our own.
When you look at code, do you do it with a critical eye?
Posted by Sam on Nov 28, 2007 at 08:07 AM UTC - 5 hrs
The other day I was working on a crossover function to be used by a genetic algorithm.
The idea is that you select two individuals in your population of possible solutions
as parents (or more - bits aren't predisposed to monogamy or
bisexual reproduction) with the idea
that you'll combine their "DNA" in hopes of producing a more fit individual.
The idea of the
crossover for my case was a single point, and it goes somewhat like this
(a slightly simplified version, for the sake of discussion):
More...
The parents look like this: "-X--XX-X--X", where X is some character besides "-"
Left_side_of_child = select a random number of characters from the left side of one of the parents
Count the number of non-dashes in Left_side_of_child - that is the number of characters you need to
skip on the other parent.
Figure out where to start on the other parent. If that index is a dash, you can randomly select
any adjacent dash until you reach any other character.
Get the right side of the second parent and append it to the left_side_of_child to give birth to
your new baby string.
So the idea is that the X's in each parent are meaningful and they need to remain the same in number
and relative position to each other - but dashes
can be inserted between them.
It's not the most complicated algorithm in the world, so why did I spend several hours getting it to work?
Two reasons:
Most of the time, I try to write (literally) just a couple of lines of code before testing it to ensure
what I just wrote is doing what I expected it to do.
If you write too many lines of code before exercising it, when you notice a problem you'll
have a harder time diagnosing which line caused it than if you had frequent feedback. Just check
that the variables have
the values you are expecting at each point in the algorithm as often as possible.
Like many programmers, I sometimes have this insane fear of throwing away code - even if it's crapcode.
The function that seemed so simple to begin with had ballooned to over 40 lines, and included
several attempts at fixing the data instead of fixing the logic. Magic numbers were sprinkled like
pixie dust throughout the algorithm. Each patch brought further complexity, making it harder and harder
to find the problem.
I kept telling myself, "This is retarded. Why is this seemingly simple function causing you so much
pain? Just throw it out and start over." I simply waited too long to do that. Eventually I came to
my senses, started from scratch, and rewrote it to be 15 lines in about 10 minutes.
Lesson:Don't be afraid
to throw out your dirty diapers.
It's good to relearn these lessons from time to time. I expect I won't be forgetting these two now for quite
a while.
My goal is to review everything before the end of the weekend, and send the iPod out on Monday (along with an announcement here of the winner, and recognition of the other participants - so if you want to be excluded for some reason, let me know that as well).
If you haven't started, there's still enough time to come up with a solution: it needn't be long or difficult - just demonstrate something new in a language you haven't had much experience in.
If you've got a blog, post the solution there and let me know about it. If not, send it to me directly - first get in touch with me via my contact page and then send it via email.
Posted by Sam on Nov 26, 2007 at 06:08 AM UTC - 5 hrs
Last week I posted about why software developers should care about process, and
how they can improve themselves by doing so. In the comments, I promised to give a review of
what I'm doing that seems to be working for me. So here they are - the bits and pieces that work for me.
Also included are new things we've decided to try, along with some notes about what I'd like to
attempt in the future.
More...
Preproject Considerations
Most of our business comes through referrals or new projects from existing customers.
Out of those, we try only to accept referrals or repeat business from
the "good clients," believing
their friends will be similarly low maintenance, high value, and most importantly, great to work with.
We have tried the RFP circuit in the past, and recently considered
going at it again. However, after a review of our experiences with it, we felt that unless you are the cause of the RFP
being initiated, you have a subatomically small chance of being selected for the project (we've been on both
ends of that one).
Since it typically takes incredible effort to craft a response, it just seems like a waste of hours
to pursue.
On the other hand, we are considering creating a default template and using minimal
customization to put out for future RFPs, and even then, only considering ones that have a very
detailed scope, to minimize our effort on the proposal even further.
We're also trying to move ourselves into the repeatable solutions space - something that really takes the
cheap manufacturing ability we have in software - copying bits from one piece of hardware storage to another -
and puts it to good use.
Finally, I'm very interested to hear how some of you in the small software business world bring in business.
I know we're technically competitors and all, but really, how can you compete with
this?
The Software Development Life Cycle
I won't bother you by giving a "phase" by phase analysis here. Part of that is because I'm not sure
if we do all the phases, or if we're just so flexible and have such short iterations the phases seem to bleed
together. (Nor do I want to spend the time to figure out which category what each thing belongs in.)
Depending on the project, it could be either. Instead, I'll bore you with what we do pretty
much every time:
At the start of a project, we sit down with client and take requirements. There's nothing fancy here.
I'm the coder and I get involved - we've found that it's a ridiculous waste of time to pass
my questions through a mediator and wait two weeks to get an answer. Instead, we take some paper or
cards and pen, and dry erase markers for the whiteboard. We talk through of what the system should do at a high level,
and make notes of it.
We try to list every feature in terms of the users who will perform it and it's reason for existence.
If that's unknown, at least we know the feature, even if we don't know who will get to use it or why
it's needed. All of this basically gives us our "use cases,"
without a lot of the formality.
I should also note that, we also do the formal bit if the need is there, or if the client wants to
work that way. But those meetings can easily get boring, and when no one wants to be there, it's not
an incredibly productive environment. If we're talking about doing the project in Rails or ColdFusion,
it often takes me longer to write a use case than it would to implement
the feature and show it to the client for feedback, so you can see why it might be
more productive to skip the formality in cases that don't require it.
After we get a list of all the features we can think of, I'll get some rough estimates of points
(not hours) of each feature to the client, to give them an idea of the relative costs for each feature.
If there is a feature which is something fairly unrelated to anything we've had experience with, we give
it the maximum score, or change it to an "investigate point cost," which would be the points we'd need
to expend to do some research to get a better estimate of relative effort.
Armed with that knowledge, they can then give me a prioritized list of the features they'd like to see
by next Friday when I ask them to pick X number of points for us to work on in the next week. Then
we'll discuss in more detail those features they've chosen, to get a better idea of exactly what it is
they're asking for.
We repeat that each iteration, adjusting the X number of points the client
gets to choose based on what was actually accomplished the previous iteration - if there was spare time,
they get a few more points. If we didn't finish, those go on the backlog and the client has fewer points
to spend. Normally, we don't have the need for face to face meetings after the initial one, but I prefer
to have them if we can. We're just not religious about it.
Whiteboards at this meeting are particularly useful, as most ideas can be illustrated quite quickly, have
their picture taken, and be erased when no longer needed. Plus, it lets everyone get involved when we start
prioritizing. Notecards are also nice as they swap places with each other with incredible ease.
Within each iteration,
we start working immediately. Most of the time, we have one week iterations, unless there are a couple of projects going on -
then we'll go on two week iterations, alternating between clients. If the project is relatively stable,
we might even do daily releases. On top of that,
we'll interface with client daily if they are available that frequently, and if there is something to show.
If the project size warrants it, we (or I) track our progress in consuming points on a burndown chart.
This would typically be for anything a month or longer. If you'll be mostly done with a project in a week,
I don't see the point in coming up with one of these. You can set up a spreadsheet to do all the calculations
and graphing for you, and in doing so you can get a good idea of when the project will actually
be finished, not just some random date you pull out of the air.
Another thing I try to be adamant about is insisting the client start using the product as soon as it
provides some value. This is better for everyone involved. The client can realize ROI
sooner and feedback is richer. Without it, the code is not flexed as much. Nor do you get to see what
parts work to ease the workload and which go against it as early in the product's life, and that makes changes more difficult.
For us, the typical client has been willing
to do this, and projects seem to devolve into disaster more readily when they don't.
Finally, every morning we have our daily stand-up meeting. Our company is small enough so that we can
talk about company-wide stuff, not just individual projects. Each attendee answers three questions:
What did you do yesterday?
What are you going to do today?
What is holding you back
The meeting is a time-conscious way (15 minutes - you stand so you don't get comfortable) to keep
us communicating. Just as importantly, it keeps us accountable to each other, focused on setting
goals and getting things
done, and removing obstacles that get in our way.
On the code side of things, I try to have unit tests and integration tests for mostly everything.
I don't have automated tests for things like games and user interfaces. I haven't seen much detriment
from doing it this way, and the tradeoff for learning how to do it doesn't seem worth it at the moment.
I would like to learn how to do it properly and make a more informed decision though. That
will likely come when time is not so rare for me. Perhaps when I'm finished with school
I'll spend that free time learning the strategies for testing such elements.
Luckily, when I'm working on a ColdFusion project, cfrails is pretty well tested so I get to skip a lot
of tests I might otherwise need to write.
By the same token, I don't normally unit test one-off scripts, unless there are obvious test cases I can
meet or before doing a final version that would actually change something.
I don't know how to do it in CF, but when I've use continuous integration tools for Java projects it has been
helpful. If you have good tests, the CI server will
report when someone checks in code that breaks the tests. This means bad code gets checked in less often.
If you don't have the tests to back it up, at least you'll feel comfortable knowing the project builds
successfully.
For maintenance, we normally don't worry about using a project management tool to track issue.
Bugs are fixed as they are reported - show stoppers immediately, less important within the day, and things deemed
slight annoyances might take a couple of days. I'd like to formalize our response into an actual policy, though.
Similarly, new requests are typically handled within a couple of days if they are small and I'm not
too busy - otherwise I'll give
an estimate as to when I can have it done.
With bugs in particular, they are so rare and few in number
that I could probably track them in my head. Nevertheless, I mark an email with my "Action Required" tag,
and try my best to keep that folder very small. Right now I've overcommitted myself and the folder isn't
empty, but there was a time recently that it remained empty on most nights.
In any event, I normally only use project management tools for very large projects or those I inherited
for some reason or another.
Summary
If you're a practitioner, you can tell the ideas above are heavily influenced by (when not directly part of)
Scrum and Extreme Programming. I wouldn't call what we're doing by either of their names. If you're not familiar
with the ideas and they interest you, now you know where to look.
Where would we like to go from here?
One thing that sticks out immediately is client-driven automated testing with Selenium or FIT.
I'd also like to work for several months on a team that does it all and does it right,
mostly to learn how I might better apply things I've learned, heard of, or yet to be exposed to.
What else? That will have to be the subject of another post, as this one's turned into a book.
Thoughts, questions, comments, and criticisms are always welcome below.
Posted by Sam on Nov 23, 2007 at 11:11 AM UTC - 5 hrs
In this week's advice from MJWTI,
"The Way That You Do It," Chad Fowler talks about process and methodology in software development. One quote
I liked a lot was:
It's much easier to find someone who can make software work than it is to find someone who can make the
making of software work.
Therefore, it would behoove us to learn a bit about the process of software development.
More...
I never used to have any sort of process. We might do a little requirements gathering, then code everything
up, and show it to the customer a couple of months later. They'd complain about some things and offer
more suggestions, then whoever talked to them would try to translate that to me, probably a couple of
weeks after they first heard it. I'd implement my understanding of the new requirements or fixes, then
we'd show it to the customer and repeat.
It was roughly iterative and incremental, but highly dysfunctional.
I can't recall if it was before or after reading this advice, but it was around the time nevertheless that I
started reading and asking questions on several of the agiledevelopmentmailinglists.
Doing that has given me a much better understanding of how to deliver higher quality, working software on a timely
basis. We took a little bit from various methodologies and now have a better idea of when software will
be done, and we interface with the customer quite a bit more - and that communication is richer than ever
now that I involve myself with them (most of the time, anyway). We're rolling out more things as time goes
along and as I learn them.
I'd suggest doing the same, or even picking up the canonical books on different methodologies and reading
through several of them. I haven't done the latter quite yet, but it's definitely on my list of things to do.
In particular, I want to expose myself to some non-Agile methods, since most of my knowledge comes from
the Agile camp.
Without exposing yourself to these ideas, it would be hard to learn something useful from them.
And you don't have to succumb to the dogma - Chad mentions (and I agree) that it would be sufficient to
take a pragmatic approach - that "the best process to follow is the one that makes your team the most
productive and results in the best products." But it is unlikely you will have a "revelationary epiphany"
about how to mix and match the pieces that fit your team. You've got to try them out, "and continuously refine
them based on real experience."
I don't think it would be a bad idea to hire a coach either (if you can afford one - or maybe you
have a friend you can go to for help?), so you've got someone to tell you if you're doing
it the wrong way. If you have a successful experiment, you probably did it the right way. But you won't
likely know if you could get more out of it. The same is said of doing it the wrong way - you may be
discarding an idea that could work wonders for you, if only you'd done it how it was meant to be.
In the end, I like a bit of advice both Venkat and Ron Jeffries
have given: You need to learn it by doing it how it was meant to be done. It's hard to pick and choose different practices without
having tried them. To quote Ron,
My advice is to do it by the book, get good at the practices, then do as you will. Many people want to skip to step three. How do they know?
Do you have any methodological horror stories or success stories? I'd love to hear them!
Update: Did I really spell "dysfunctional" as "disfunctional" ? Yup. So I fixed that and another spelling change.
Posted by Sam on Nov 22, 2007 at 12:04 PM UTC - 5 hrs
Since the gift buying season is officially upon us, I thought I'd pitch in to the rampant consumerism and list some of the toys I've had a chance to play with this year that would mean fun and learning for the programmer in your life. Plus, the thought of it sounded fun.
Here they are, in no particular order other than the one in which I thought of them this morning:
More...
JetBrains' IntelliJ IDEA: An awesome IDE for Java. So great, I don't mind spending the $249 (US) and using it over the free Eclipse. The Ruby plugin is not too shabby either, the license for your copy is good for your OSX and Windows installations, and you can try it free for 30 days. Martin Fowler thinks IntelliJ changed the IDE landscape. If you work in .NET, they also have ReSharper, which I plan to purchase very soon. Now if only we could get a ColdFusion plugin for IntelliJ, I'd love it even more.
Programming Ruby, Second Edition: What many in the Ruby community consider to be Ruby's Bible. You can lower the barrier of entry for your favorite programmer to using Ruby, certainly one of the funner languages a lot of people are loving to program in lately. Sometimes, I sit and think about things to program just so I can do it in Ruby.
If they've already got that, I always like books as gifts. Some of my
favorites from this year have been: Code Complete 2, Agile Software Development: Principles, Patterns, and Practices which has a great section on object oriented design principles, and of course,
My Job Went to India.
I have a slew of books I've yet to read this year that I got from last Christmas (and birthday), so I'll have to
list those next year.
Xbox 360 and a subscription to
XNA Creator's Club (through Xbox Live Marketplace - $99 anually) so they can deploy their games to their new Xbox. This is without a
doubt the thing I'd want most, since I got into this whole programming thing because I was interested
in making games. You can point them to the
getting started page, and they could
make games for the PC for free, using XNA (they'll need that page to get started anyway, even if you
get them the 360 and Creator's Club membership to deploy to the Xbox).
MacBook Pro and pay for the extra pixels. I love mine - so much so,
that I intend to marry it. (Ok, not that much, but I have
been enjoying it.)
The extra pixels make the screen almost as wide as two, and if you can get them an extra monitor I'd do
that too. I've moved over to using this as my sole computer for development, and don't bother with
the desktops at work or home anymore, except on rare occasions. You can run Windows on it, and the
virtual machines are getting really good so that you ought not have to even reboot to use either
operating system.
Even if you don't want to get them the MacBook, a second or third monitor should be met with enthusiasm.
A Vacation: Programmers are notoriously working long hours
and suffering burnout, so we often need to take a little break from the computer screen. I like
SkyAuction because all the vacations are package deals, there's often a good variety to choose from (many
different countries), most of the time you can find a very good price, and usually the dates are flexible
within a certain time frame, so you don't have to commit right away to a certain date.
Happy Thanksgiving to those celebrating it, and thanks to all you who read and comment and set me straight when I'm wrong - not just here but in the community at large. I do appreciate it.
Do you have any ideas you'd like to share (or ones you'd like to strike from this list)?
Posted by Sam on Nov 19, 2007 at 04:32 PM UTC - 5 hrs
At the O'Reilly ONLamp blog, chromatic pointed out that we should
"program as if [our] maintenance programmer were not a barely-competent monkey,"
quoting a paragraph from Mark-Jason Dominus.
Mark was describing the idiocy of programming-by-superstition, where you might put parentheses if you
are unsure of the order of operations operator precedence (or, to help barely-competent monkeys know the order precedence), rather
than re-defining that order as opposed to using them to change the "normal" precedence.
More...
If the parentheses are there to clarify a complex expression, that is one thing (but there are
better ways to do it, such as using descriptive variable names).
The parentheses add clutter, making the code ever-so-slightly harder to read.
Certainly no one would implement a scanner for string searching when a simple regular
expression would do (I hope, anyway). It would be even more foolish if you did it just because
the next coder to look at the code might find it easier to understand.
When I first read chromatic's funny phrase, I thought we should program as if those who
follow us have unintelligible thoughts in their heads. (I still do.) I was looking at it like this:
If I write programs like a monkey would write programs (and I've been known to do such things), the
person following me would need a highly developed brain to fit
enough of it in his head to be of any use to the code he inherited. I don't even like to work on some of that old stuff, and I certainly don't understand half of it. Therefore, it would be
better to write the code so that even a monkey can follow it. I'm not talking about concepts
like Mark was talking about. Instead, I'm talking about things like five-line methods, cohesion,
modularity, understandable code, and the sort.
I think both views work - they are just referring to different things.
Maintenance programmers
get dumped on all the time. The least we could do is try to make their jobs easier by not feeding
them crapcode. Maybe a Maintenance Programmer Appreciation Day is in order?
Update: Based on the discussion below, I made a couple of changes to avoid confusion above. Read the comments for more info on that discussion.
Posted by Sam on Nov 16, 2007 at 01:15 PM UTC - 5 hrs
The chapter this week from My Job Went to India
tells us to "Practice, Practice, Practice." It's pretty obvious advice - if you practice something,
you will get better at it. Assuming that skill has value, you'll be able to market yourself easier.
What's not so obvious is that we are "paid to perform in public - not to practice."
Unfortunately, most of us practice at our jobs (which is another reason we started the Code Dojo).
Perhaps because the advice seems so obvious is why when I reread this chapter, I realized I hadn't
done much about it. Sure, I do a lot of learning and coding on any given day, but it's been
rare where I've truly stretched the bounds of my knowledge and skill. And as Chad notes in the
chapter, that is precisely the point of practice.
Specifically, we might focus on three areas when practicing, which parallel Chad's experience
as a musician:
More...
Physical/coordination: Visiting "the dusty corners of your primary programming
language," such as deep exploration of regular expressions, tools, and APIs you
rarely (or never) get a chance to use at your day job. I'd put learning other
languages here, and experimenting with new constructs and paradigms, like you can
win an iPod Nano for doing.
You may not use it often, but when you need to, you'll be prepared. On the other hand,
you may find something that used to take you hours can be done in one line of code - it's
built right into the language.
Sight reading: If you can sight-read code, how much faster would you be at finding and
diagnosing problems, or adding new features, just by having the ability to understand
the structure of an application instantly? Chad recommends going to the to-do list
of an open source application, deciding on a feature to implement or bug to fix, and
then going through the source to find out where it needs to go. Impose time constraints on
yourself, and rotate through many different projects (and languages), and you'll get
faster at "sight reading" code. You don't even need to implement it - just finding the
place to put it would be enough (but it would be even better if you did!).
Improvisation: Chad defines improvisation as "taking some structure or constraint and
creating something new, on the fly, on top of that structure." One such example he
described was
recovering lost data by manually replaying packets over a wireless
network from a binary log file. No body meant for you to do these things, especially
not in the heat of the moment. [But] that kind of sharp and quick programming ability
can be like a magical power when wielded at the right time.
Of the three, I really like his ideas on practicing improvisation: "Pick a simple program, and
try to write it with [self-imposed] constraints." One example is printing the lyrics to
99 Bottles of Beer on the Wall "without doing any variable assignments." Or golfing.
I'm sure you can think of others (and I plan to).
I haven't done as good a job at practicing as I'd like to, so I'm going to resolve to sit down
weekly and just have some practice time, stressing the points above. I won't be too ambitious
though - I've already over-committed myself for the rest of this year. But as my early
New Year's Resolution, I'll plan on blogging my weekly experience in regularly scheduled practice,
like Scott Hanselman does in his series, The Weekly Source Code.
Anyone want to lend some moral support and start practicing too? We could be like virtual
workout partners, flexing our coding muscles.
Note: I didn't do a good job of showing it in the article itself, but all the quotes there
are from Chad Fowler.
Posted by Sam on Nov 14, 2007 at 08:30 AM UTC - 5 hrs
The Turing Test was designed to test the ability of
a computer program to demonstrate intelligence.
(Here is Alan Turing's proposal of it.)
It is often described as so: if a computer can fool a person into believing it too is a person, the computer
has passed the test and demonstrated intelligence. That view is a simplified version.
Quoth Wikipedia about the rules:
A human judge engages in a natural language conversation with one human and one machine,
each of which try to appear human; if the judge cannot reliably tell which is which, then the machine is
said to pass the test.
Specifically, the test should be run multiple times and if the judge cannot decipher which respondent
is the human about 50% of the time, you might say he cannot tell the difference, and therefore, the
machine has demonstrated intelligence and the ability to hold a conversation with a human.
I suppose the idea of poker bots passing the test comes about because (presumably) the human players at
the table don't realize they are playing against a computer. But if that is the case,
even a losing bot would qualify - human players may think the bot player is just an idiot.
More...
More interesting is his idea that the Turing test was beaten in the 1970s.
In defense of that thought, Giles mentions that the requirement having the questioner
"actively [try] to determine the nature of the entity they are chatting with" is splitting hairs.
Even if you agree with that, the poker bot certainly does not qualify - there is no chat, and there
is certainly no natural language.
If that still constitutes hair splitting, I'm
sure we can eventually
split enough hairs to reduce the test so that most any program can pass. Give the sum(x,y) x,y ε {0..9}
program to a primary school math teacher, and the fact that it can add correctly may lead the teacher to believe it is a smart kid.
Then add in the random wrong answer to make it more believable.
In any case, if you accept the hair-splitting argument about the program that actually
did chat in natural language, then certainly PARRY
passed the test.
On the other hand,
while you may consider
that the test was passed in fact, it was not done so in spirit.
I'll admit that I think the requirement of a tester talking to both a human and a computer program is an important one.
Even disregarding the "no occasion to
think they were talking to a computer," if we limit the computer's response to a particular set of people
who think they are in a particular context,
we could (for example) use Markov-model generated
sentences with some characters in keyboard-distance-proximity replaced within the words. We now have a drunk typist.
Perhaps in his drunken stupor he is not at his sharpest, but he would likely still be considered an intelligent being.
If the human tester is able to ask questions of both the computer and another human, do you think he would
ever choose the computer program that rephrases his questions to sound paranoid as the human over the
person who answers
to the best of his ability?
The point is that without that requirement, the test becomes meaningless. Giles notes that
All the test really does is expose how little we know about what makes people people.
The fact that it's easy to fool people into thinking a computer is human doesn't actually teach you
anything about the difference between computers and humans; all it does is teach you that it's easy to fool people.
I think that's only true if you conceive of the test as he does. By keeping all of the requirements Turing
proposed, it becomes quite a bit harder to pass, and retains its utility.
Further, removing that quality changes the essence
of the test.
Since we can assume the test was
designed to be useful, can we really say that insisting the test retain its essence is unreasonable?
For the monetary hurdles? A computer to prove anything on you.
If you are serving with talented coders so it doesn't change. Can you understand the case study present in different paradigm shifts in science. I was on vacation, "I can't see my old search terms every time you run into a code monkey? Are you a code monkey? Are you stick to standards so you could have implement our own develop good sound-editor to do it. Even more diplomatic terms, of course of action - if a proxy) the objectives and different approach much better, and how can you believe it?" I think it would solve those domain you're willing to him speak than after a little over a million users so it doesn't "mean that a competitors. Of course of action - if a proxy) the objectives and different paradigms to help out in the to-read list: The Power of integration in asking what other hand, JSF, Seam, and Tapestry are based on my to-read list.) Because I think you can keep the view updated - but there are made, and borders on absurd side of the elements in the code for you to record an improvement. That's not a far leap to see that you do?" Here he actually pointless. How do I know - I was doing before I started to deploy to XBOX 360 or PC (Developers created." Instead, you should use is a contest to avoid conversations. It can be threatened." What are the Maximizers are drive-in traffic and implementation of an old professor of mine, be honest about it. Thanks XNA!
As always came back in January. Perhaps you understand it. If you want to conversations. It can be threatened." What are the number of integration in asking people something to do it. Even more diplomatic terms, of course, you can do. In particular, by posting a good developers created." Instead, you should.
The point is that you're not passion.
There are a couple of repeats noticeable, which is mostly due to my lack of source text. At least, it worked a little better using one-hundred 8.5" x 11" pages of Great Expectations (still gibberish though).
Anyway, here's the Ruby source code:
classMarkovModeldefcreate_model(file,order,unit)#unit = "word" or "character"@unit=unitentire_file=""@order=order#read the entire file inFile.open(file,"r")do|infile|cnt=0while(line=infile.gets)entire_file+=linecnt+=1endend#split the file according to characters or wordsifunit=="word"split_on=/\s/elsesplit_on=""end@entire_file_split=entire_file.split(split_on)#construct a hash like:#first 'order' letters, letter following, increment count@model=Hash.newi=0@entire_file_split.eachdo|c|this_group=@entire_file_split[i,order]next_letter=@entire_file_split[i+order,1]#if group doesn't exist, create itif@model[this_group]==nil@model[this_group]={next_letter=>1}#if group exists, but this "next_letter" hasn't been seen, insert itelsif@model[this_group][next_letter]==nil@model[this_group][next_letter]=1#if group and next letter exist in model, increment the countelsecur_count_of_next_letter=@model[this_group][next_letter]+1@model[this_group][next_letter]=cur_count_of_next_letterendi+=1endenddefgenerate_and_print_text(amount)start_group=@entire_file_split[0,@order]printstart_groupthis_group=start_group(0..(amount-@order)).eachdo|i|next_letters_to_choose_from=@model[this_group]#construct probability hashnum=0probabilities={}next_letters_to_choose_from.eachdo|key,value|num+=valueprobabilities[key]=numend#select next letterindex=rand(num)matches=probabilities.select{|key,value|index<=value}sorted_by_value=matches.sort{|a,b|a[1]<=>b[1]}next_letter=sorted_by_value[0][0]print" "if@unit=="word"#if we're splitting on wordsprintnext_letter#shift the groupthis_group=this_group[1,@order-1]+next_letter.to_aryendenddefprint_modelrequire'pp'PP.pp(@model)endendfile=File.expand_path"source_text.txt"mm=MarkovModel.newmm.create_model(file,7,"character")mm.generate_and_print_text(2000)mm.create_model(file,1,"word")mm.generate_and_print_text(250)#mm.print_model
Posted by Sam on Nov 05, 2007 at 09:16 AM UTC - 5 hrs
The Contest
For the next month, I'll be running a contest here for programmers to promote learning something new.
I've had this spare iPod Nano that I've yet to use (and likely never will), I've been
covering how to save your
job with Chad Fowler's My Job Went To India, and I'm passionate about learning new things. It
seems the best way to combine all three is a contest to help me spread that passion.
Write a program in any language you are unfamiliar with.
Choose a language or a program that is in a different paradigm
than languages (or programs) you already know (how to write).
Use at least one idea from that language that you've never (or rarely) used in another language.
Make it a useful program, though it needn't be big.
Follow good programming practices appropriate to the paradigm you're programming in (as well as universal ones).
If you have a blog and want to participate, post the solution there to be scrutinized in comments.
If you don't have a blog and want to participate, email the solution to me via my
contact page or my email address if you already know it, and let others scrutinize the solution
here in the comments.
I'll get the prize out the door in time for you to receive it by Christmas, in case you want to give it away
as a gift.
When you submit your program, be sure to point out all the ways you've done the above items.
But I need your help
If you have any ideas for possible programs, list them below. This would give people something to choose from, and make for more participation.
If you have an idea that you want to do, but aren't sure if it would work, it probably will. Feel free to ask if it makes you more comfortable though.
If you think this is as important as I do, spread the word - even if you don't want to participate.
The winner will likely be chosen in a random drawing, but I need people proficient in different paradigms to help me judge what qualifies. I'm not an expert in everything.
Overall, the point is to learn something new, to have fun doing it, and to get people involved in learning new concepts.
If you accomplish any two out of those three goals within the next month, let me know
about it and we'll enter you in the contest.
Posted by Sam on Oct 31, 2007 at 04:26 PM UTC - 5 hrs
When looping over collections, you might find yourself needing elements that match only a certain
parameter, rather than all of the elements in the collection. How often do you see something like this?
What we really need here is a way to filter the collection while looping over it. Move that extra
complexity and indentation out of our code, and have the collection handle it.
In Ruby we have each
as a way to loop over collections. In C# we have foreach, Java's got
for(ElemType elem : theCollection), and Coldfusion has <cfloop collection="#theCollection#">
and the equivalent over arrays. But wouldn't it be nice to have an each_where(condition) { block; } or
foreach(ElemType elem in Collection.where(condition))?
I thought for sure someone would have implemented it in Ruby, so I was surprised at first to see this in my
search results:
However, after a little thought, I realized it's not all that surprising: it is already incredibily easy to filter
a collection in Ruby using the select method.
But what about the other languages? I must confess - I didn't think long and hard about it for Java or C#.
We could implement our own collections such that they have a where method that returns the subset we are
looking for, but to be truly useful we'd need the languages' collections to implement where
as well.
Of these four languages, ColdFusion provides both the need and opportunity, so I gave it a shot.
First, I set up a collection we can use to exercise the code:
<cfif not isDone> <cfexit method="loop"> <cfelse> <cfexit method="exittag"> </cfif> </cfif>
It works fine for me, but you might want to implement it differently. The particular area of improvement I
see right away would be to utilize the item name in the where attribute. That way,
you can use this on simple arrays and not just assume arrays of structs.
Posted by Sam on Oct 30, 2007 at 10:46 AM UTC - 5 hrs
... and two things you can do to remove them
The way I see it, there are three hurdles for programmers to cross to get involved in an open source project:
Motivation to help out in the first place
Fear of rejection in asking to be involved
Lack of knowledge about the project
There's nothing you can do about motivation - if a programmer doesn't want to contribute, he simply won't.
But the other two roadblocks are something the project can remove from the programmer's path to contribution.
Charles Nutter with JRuby recently demonstrated what I consider to be an excellent
way of getting motivated programmers to contribute to a project by removing those other two impedences:
Remove the fear of rejection by asking people to get involved
Improve the knowledge and lower the barrier of entry by posting a list of easy to fix items
In particular, by posting the list of easy items you offer a great place to start where the newbie on the
project will feel comfortable getting his feet wet, while at the same time learning the conventions and
design of the code base.
Finally, once someone shows interest, don't forget to be helpful and follow-up on answering their questions.
It will go a long way to show them that you value their help.
Posted by Sam on Oct 26, 2007 at 03:08 PM UTC - 5 hrs
You need to take responsibility for your own improvement. That's a good part of what Chad Fowler's MJWTI focuses on getting you to realize. This week's advice follows along that same line: "Give a man a fish; feed him for a day. Teach a man to fish; feed him for a lifetime" (quoting Lao Tzu).
As Chad notes however, "education requires both a teacher and a student. Many of us are too often reluctant to be a student." He likens fish to the "process of using a tool, or some facet of a technology, or a specific piece of information from a business domain you're working in." Too many of us take the fish today, and "ask ... for another fish tomorrow."
More...
Being a good developer means not relying on your "server guy" to set everything up for you. Be a master of source control, testing, and of setting up your own development tools: the IDE, outside references or the build path, and the virtual machine (or whatever runs your code).
Learn how to make ColdFusion work with your database. Figure out how to install and run Rails - don't rely on it being preinstalled on Leopard.
For quite some time in college I was afraid of using the command line to compile my programs - I just wrote them in Windows using Dev C++ and turned them in, blindly hoping they would compile and work correctly for the person grading my program on Unix.
For God's sake, learn how to compile your own programs, even if modern IDEs do it onSave().
I hate to say it, but you're in the wrong line-of-work if you are constantly asking for fish. Technologies change too quickly to ask for help every time you run into a roadblock. The problem is magnified tenfold if you have to ask several times to accomplish the same task.
On another note, Chad mentions code-by-wizardry as being particularly painful:
A[n] ... easy way to get lazy is to use a lot of wizards that generate code for you. This is particularly prevalent in the world of Windows development where, to Microsoft's credit, the development tools make a lot of tasks really easy. The downside is that many Windows developers have no idea how their code really works. (page 50, emphasis mine)
I can attest to that. You know that main class that processes all the callbacks in a typical Windows program? I didn't either. Consequently, my first several forays into programming for Windows resulted in disaster. If I could find that code, I'd love to post it for inspection, so you could marvel at how Button1 did something for TextField2 and all of it somehow worked in one GodClass. The magnificence of the horror led to nightmares for me recently as I
discovered the XNA framework. The wizards are there to make your life easy - not to be a replacement for knowledge and thought. You still need to understand what they are doing for you.
The point is that you have to learn. Don't be afraid to ask, but when you ask, make sure there is a purpose behind it. If you teach yourself to learn, and you learn everything you need to know, you'll be in good shape. But, to end with some advice from an old professor of mine, be honest about what you know. Don't be afraid to admit your shortcomings - instead, use it as a chance to learn, not as a chance to have someone else do it for you.
Posted by Sam on Oct 25, 2007 at 11:51 AM UTC - 5 hrs
There are plentyofpeople(?) who think we might move on to Javascript as the next big language. If anything, the fact that it runs server-side and browser-side means you might just need to know one language.
Someothers think polyglot programming is where its at - the movement to two major platforms and implementations on either of them of most any language you'd want to use gives us tremendous power of integration while making it easy to use the right tool for the right job. If anything, we can stop using hammers to pound screws into rocks.
I'm partial to the second idea. What do you think? (Either these two or something completely different!)
(?) - Just to be clear, I don't think Steve Yegge ever said Javascript will be it. But a lot of the comments seem to think so.
Posted by Sam on Oct 19, 2007 at 11:32 AM UTC - 5 hrs
I'm sitting in the conference right now and just found out they are broadcasting live on the web. If you want to attend but can't be here, view the conference here. You've missed Neal Ford, but Venkat is talking about DSLs right now. Bjarne Stroustrup is up after lunch.
Update: It's quite late now, but Bjarne didn't make it. They announced this after I had shut down for lunch, and amazingly, I didn't turn my computer on the rest of the weekend.
Posted by Sam on Oct 19, 2007 at 08:21 AM UTC - 5 hrs
It's such a bit of obvious advice that I almost skipped over it: "love it or leave it." There's no point staying in a job or career that you don't like - your performance will suffer as you sling code listlessly on a daily basis.
The flip side of that is that you'll excel in something you're passionate about. It's not hard to "take a big step away from mediocrity" just by being passionate (quoting Chad Fowler, in MJWTI).
So, if you're not passionate about programming, should you find another career? Perhaps, but why not just become passionate? It's not exceedingly hard.
I know - I was there.
When making the decision to go to graduate school, I had originally planned to go for Political Science. I was bored with work, and I just wanted to get away from computers. A lot of that was self-inflicted with my spaghetti-coding ways, but I just didn't feel right programming any more. Someone with one of the coolest jobs in the world dreading to go to work? That was me.
Luckily for me, the Political Science department didn't accept Spring admissions for grad school, and that was when I wanted to enroll. So, I said "what the hell," and went for Computer Science instead. Of course, I have the benefit of having been passionate about this stuff at one point in my life. If you've never felt that way, what brought you here?
Whatever happened, I made the decision to become passionate about programming and computers again before that first semester - and now I'm hooked. My job is not appreciably different from what I was doing before - I've just added a lot of learning and exploration into my days, and figured out the benefits of dealing with crappy code. I think you can do the same.
It was around the time games started looking better and being more complicated than
Wolfenstein 3-D that
I started thinking I'd never be able to make a game. Sure, I could do Tetris or
Minesweeper, but how in the world could I ever match the game play and graphics of a
Quake or Diablo.
Let's not even get started with
Halo 3 and Call of Duty.
More...
It seems you need an army of programmers to make even a decent game now.
But then people started releasing game-development frameworks that could help you get past the
technical hurdles. However, by the time I thought about something like that
(or had the capacity to think it) I had almost
long forgotten about my dream to make games.
And even if you're using a framework, what do you do about the monetary hurdles?
A computer to program on is one thing,
but where would you find the cash for a good 3D modeling studio? What if you wanted to
deploy to a console? That license is in the tens of thousands of dollars (or so I've heard).
But as some of you have known for a while, and I only found out as recently as August, Microsoft
is helping to solve those problems. They've released the XNA framework, which lets you deploy to
XBOX 360 or PC (Developer Center,
Creators Club, XNA Team Blog).
I'm only three weeks in and I've got quite a decent start for a game. It's
cartoon-like, so it doesn't require the type of art you'd find in Gears of War
(though I could still use the help of a 3d modeler
if you're offering). It works mostly how I want it to, and I need
only a few tweeks. Most importantly, I've got a nice framework written
that allows me to add levels and new game objects with relative ease (not WYSIWYG just yet, but that
might happen at some point in the distant future).
So that only leaves the soundtrack.
Unless you don't plan to distribute your game, licensing songs may still be an prohibitive issue
(barring that you're good at making your own on the computer,
and have a good sound-editor to do it). For that, I'm trying to get the band back together over the winter
to record an impromptu soundtrack. Getting back in the studio with those guys
would be reward enough, but I'll have a game to go with it. Thanks XNA!
As always, thoughts are appreciated. I'd especially
like to hear from you if you know or are a member of
any community where free(ish) 3D models and textures are available.
Posted by Sam on Oct 12, 2007 at 07:19 AM UTC - 5 hrs
Probably my absolute favorite chapter in
Chad Fowler's book gives the advice of being the worst in order to save your job. (Incidentally, it must be a good book because I think I've said that about other chapters, and I'm certain
I'll say it again as I rediscover later ones).
Saving your job by being teh suck (that's Latin for mightily unimpressive) coder in the bunch probably sounds odd to you, so
let me explain:
More...
If you want to become a better writer, you read othergreat writers. Even better if you
can communicate with them.
If you want to become a better musician, you play with better musicians (as Mr. Fowler mentions he did in the book). You listen to great musicians.
It stands to reason then, if you'd like to be a better programmer, it would be beneficial to surround yourself with programmers who are better than you. You do that by being the worst.
Being the worst is not an excuse to try to be a bad programmer - you just want to find better programmers than you happen to be right now. Learn from them, and find others.
You might argue, "B-But, my boss won't let me switch teams, and everyone I work with is a pathological coder!" I won't tell you to switch jobs, because it's likely you want to already.
Perhaps you don't even work on a team - what then?
Chad anticipates those questions, and it turns out there's plenty you can do. In particular, he advocates finding a volunteer project, hanging out with other developers at the local user group meetings (or starting your own), and joining an open source project (for that, you'll want to submit patches and take the
feedback they give you to make them better -- then you might be accepted).
If you're not quite there, you can join mailing lists where smart developers hang out. Read from them.
Ask questions. Get clarification. You want to be interacting with talented coders so it will rub off
on you.
If you don't yet feel you can learn anything from them because they are so far above your level, read books, articles*, and blogs (I've got far too many to link to here) from smart developers. Just get to that point and learn from the best.
* - I think one of the most important things to becoming a better developer is to read and understand Robert Martin's series of articles on OOD. Unfortunately, the link to it is not responding at the time I write this.
It was actually a bit more complex than that (probably 3x as many lines), but with the same purpose. There were literally two places from which to choose to direct the request. And no, the application wouldn't take incredibly long to compile. I felt like it was quite a bit of overkill.
Posted by Sam on Oct 05, 2007 at 08:45 AM UTC - 5 hrs
Those fluent in English know well the phrase
"don't put all your eggs in one basket"
(kindly linked for those unfamiliar with the idiom). If it is foolish enough to risk dropping the
basket and breaking all of your eggs, it is doubly so to put all your eggs in someone else's
basket. How could you control your destiny?
More...
Don't do it that way is the advice from MJWTI
this week.
In particular, I want to share one passage that resonated with me:
Somehow, as an industry, we fool ourselves into thinking market leader is the same
thing as standard. So, to some people, it seems rational to make another company's
product a part of their identities.
Even worse, some base their entire careers around non-market-leading products -- at least until
their careers fail so miserably that they have no choice but to rethink this losing strategy.
Let me repeat that: some people base their entire careers around non-market-leading products.
That sounds just about where I was 18 months ago. Today, I cannot imagine basing my career around
a product, much less insignificant ones. I try to relate everything to myself in terms of ideas,
and I try to regularly experiment with the unfamiliar. Even if I were not able to do some of it at work,
it would be well worth the effort of spending a little time at home to do that.
Moving around at the whim of others. You assert no control over your own safety. If you were dropped,
what would you do?
Posted by Sam on Oct 04, 2007 at 04:00 PM UTC - 5 hrs
A couple of weeks ago the UH Code Dojo embarked on the
fantastic voyage that is writing a program to solve Sudoku puzzles, in Ruby. This week, we
continued that journey.
Though we still haven't completed the problem (we'll be meeting again tenatively on October 15, 2007 to
do that), we did construct what we think is a viable plan for getting there, and began to implement some
of it.
The idea was based around this algorithm (or something close to it):
More...
while (!puzzle.solved)
{
find the most constrained row, column, or submatrix
for each open square in the most constrained space,
find intersection of valid numbers to fill the square
starting with the most constrained,
begin filling in open squares with available numbers
}
With that in mind, we started again with TDD.
I'm not going to explain the rationale behind each peice of code, since the idea was presented above.
However, please feel free to ask any questions if you are confused, or even if you'd just like
to challenge our ideas.
Obviously we need to clean out that commented-out line, and
I feel kind of uncomfortable with the small amount of tests we have compared to code. That unease was
compounded when we noticed a call to get_submatrix instead of get_submatrix_by_index.
Everything passed because we were only testing the first most constrained column. Of course, it will
get tested eventually when we have test_solve, but it was good that the pair-room-programming
caught the defect.
I'm also not entirely convinced I like passing around the index of the most constrained whatever along
with a flag denoting what type it is. I really think we can come up with a better way to do that, so
I'm hoping that will change before we rely too much on it, and it becomes impossible to change without
cascading.
Finally, we also set up a repository for this and all of our future code. It's not yet open to the public
as of this writing (though I expect that
to change soon). In any case, if you'd like to get the full source code to this, you can find our Google Code
site
at http://code.google.com/p/uhcodedojo/.
If you'd like to aid me in my quest to be an idea vacuum (cleaner!), or just have a question, please feel
free to contribute with a comment.
def function(input)
input = input.join("") if(input is an array)
...
end
With that you can treat arrays and string inputs the same. (This comes from an example where I actually wanted to do the opposite, in messing with Smith-Waterman.)
Maybe you have certain default parameters to your program and you'd like the ability to override some of them with a tag in an XML file, as I was doing recently. You get an XmlNode xnode by searching the XmlDocument for that tag. Then, if xnode is null, you use the default.
But if you are constantly checking types and asking if some_variable isNull? to the point at which the signal to noise ratio is so low as to be annoying, your code might be irrationally fearful, anxious to the point of delusion. You might even ask if the time has come for it to visit a professional trained in treating paranoia.
Is your code paranoid? Or am I just too liberal with mine? Thoughts below are encouraged.
Posted by Sam on Sep 25, 2007 at 06:39 AM UTC - 5 hrs
The last bit of advice from Chad Fowler's 52 ways to save your job was to be a generalist, so this week's version is the obvious opposite: to be a specialist.
The intersection point between the two seemingly disparate pieces of advice is that you shouldn't use your lack of experience in multiple technologies to call yourself a specialist in another. Just because you
develop in Java to the exclusion of .NET (or anything else) doesn't make you a Java specialist. To call yourself that,
you need to be "the authority" on all things Java.
More...
Chad mentions a measure he used to assess a job candidate's depth of knowledge in Java: a question of how to make the JVM crash.
I'm definitely lacking in this regard. I've got a pretty good handle on Java, Ruby, and ColdFusion. I've done a small amount of work in .NET and have been adding to that recently. I can certainly write a program that will crash - but can I write one to crash the virtual
machine (or CLR)?
I can relunctantly write small programs in C/C++, but I'm unlikely to have the patience to trace through a large program for fun. I might even still be able to figure out some assembly language if you gave me enough time. Certainly in these lower level items it's not hard to find a way to crash. It's
probably harder to avoid it, in fact.
In ColdFusion, I've crashed the CF Server by simply writing recursive templates (those that cfinclude themselves). (However, I don't know if that still works.) In Java and .NET, I wouldn't know where to start. What about crashing a browser with JavaScript?
So Chad mentions that you should know the internals of JVM and CLR. I should know how JavaScript works in the browser and not just how to getElementById(). With that in mind, these things are going on the to-learn list - the goal being to find a way to crash each of them.
In a slightly invective tone, Reg makes some great points about assumptions in validation, and the real trouble it can cause. I'm not entirely sure how often I've been guilty, but I know I'll pay a lot closer attention from here on out.
When you build a web app, remember: if it's going public, it has the potential to mess with people's lives.
And now I'm off to re-check those regular expressions I've been using to validate email addresses...
Posted by Sam on Sep 19, 2007 at 01:37 PM UTC - 5 hrs
A couple of days ago the UH Code Dojo met once again (we took the summer off). I had come in wanting to
figure out five different ways to implement binary search.
The first two - iteratively and recursively - are easy to come up with. But what about three
other implementations? I felt it would be a good exercise in creative thinking, and pehaps it
would teach us new ways to look at problems. I still want to do that at some point, but
the group decided it might be more fun to tackle to problem of solving any Sudoku board,
and that was fine with me.
Instead, we agreed that certainly there are some aspects that are testable, although
the actual search algorithm that finds solutions is likely to be a unit in itself, and therefore
isn't likely to be testable outside of presenting it a board and testing that its outputted solution
is a known solution to the test board.
We promptly commented out the test though, since we'd never get it to pass until we were done. That
doesn't sound very helpful at this point. Instead, we started writing tests for testing the validity
of rows, columns, and blocks (blocks are what we called the 3x3 submatrices in a Sudoku board).
Our idea was that a row, column, or block is in a valid state
if it contains no duplicates of the digits 1 through 9. Zeroes (open cells) are acceptable in
a valid board. Obviously, they are not acceptable in a solved board.
To get there, we realized we needed to make initialize take the initial game board
as an argument (so you'll need to change that in the TestSudokuSolver#setup method and
SudokuSolver#solve, if you created it), and then we added the following tests (iteratively!):
The implementation wasn't difficult, of course. We just need to reject all zeroes from the row, then run
uniq! on the resulting array. Since uniq! returns nil if each
element in the array is unique, and nil evaluates to false, we have:
The test failed, so we had to make it pass. Basically, this method is also the same for columns as it was
for rows. We just need to call Array#transpose# on the board, and follow along. The
valid_column? one-liner was @board.transpose[col_num].reject{|x| x==0}.uniq! == nil.
We added that first, made sure the test passed, and then refactored SudokuSolver
to remove the duplication:
All the tests were green, so we moved on to testing blocks. We first tried slicing in two dimensions, but
that didn't work: @board[0..2][0..2]. We were also surprised Ruby didn't have something
like an Array#extract_submatrix method, which assumes it it passed an array of arrays (hey,
it had a transpose method). Instead, we created our own. I came up with some nasty, convoluted code,
which I thought was rather neat until I rewrote it today.
Ordinarily, I'd love to show it as a fine example of how much prettier it could have become. However, due
to a temporary lapse into idiocy on my part: we were editing in 2 editors, and I accidentally saved the
earlier version after the working version instead of telling it not to save. Because of that,
I'm having to re-implement this.
Now that that sorry excuse is out of the way, here is our test for, and implementation of extract_submatrix:
Unfortunately, that's where we ran out of time, so we didn't even get to the interesting problems Sudoku
could present. On the other hand, we did agree to meet again two weeks from that meeting (instead of a month),
so we'll continue to explore again on that day.
Thoughts? (Especially about idiomatic Ruby for Array#extract_submatrix)
Update: Changed the misspelled title from SudokoSolver to SudokuSolver.
Posted by Sam on Sep 10, 2007 at 12:48 PM UTC - 5 hrs
If you don't care about the background behind this, the reasons why you might want to use
rules based programming, or a bit of theory, you can skip straight the Drools tutorial.
Background
One of the concepts I love to think about (and do) is raising the level of abstraction in a system.
The more often you are telling the computer what, and not how, the better.
Of course, somewhere someone is doing imperative programming (telling it how), but I like to
try to hide much of that somewhere and focus more on declarative programming (telling it what). Many
times, that's the result of abstraction in general and DSLs
and rules-based programming more specifically.
More...
As a side note, let me say that this is not necessarily a zero-sum game. In one aspect you may be declaratively
programming while in another you are doing so imperatively. Example:
function constructARecord()
{
this.name=readFileLineNumber(fileName, 1);
this.phone=readFileLineNumber(fileName, 2);
this.address=readFileLineNumber(fileName, 3);
}
You are telling it how to construct a record, but you are not telling it how to read the file. Instead,
you are just telling it to read the file.
Anyway, enough of that diversion. I hope I've convinced you.
When I finished writing the (half-working) partial order planner in Ruby,
I mentioned I might like "to take actions as functions, which receive preconditions as their parameters,
and whose output are effects" (let me give a special thanks to Hugh Sasse for his help and ideas in trying to use TSort for it while I'm
on the subject).
Doing so may have worked well when generalizing the solution to a rules engine instead of just a planner (they are conceptually
quite similar). That's
often intrigued me from both a business application and game programming standpoint.
The good news is (as you probably already know), this has already been done for us. That was the
subject of Venkat's talk that I attended at No Fluff Just Stuff at the end of June 2007.
Why use rules-based programming?
After a quick introduction, Venkat jumped right into why you might want to use a rules engine.
The most prominent reasons all revolve around the benefits provided by separating concerns:
When business rules change almost daily, changes to source code can be costly. Separation of knowledge
from implementation reduces this cost by having no requirement to change the source code.
Additionally, instead of providing long chains of if...else statements, using a rule engine
allows you the benefits of declarative programming.
A bit of theory
The three most important aspects for specifying the system are facts, patterns, and the rules themselves.
It's hard to describe in a couple of sentences, but your intuition should serve you well - I don't think
you need to know all of the theory to understand a rule-based system.
Rules Engine based on Venkat's notes
Facts are just bits of information that can be used to make decisions. Patterns are similar, but can
contain variables that allow them to be expanded into other patterns or facts. Finally, rules have
predicates/premises that if met by the facts will fire the rule which allows the action to be
performed (or conclusion to be made).
(Another side note: See JSR 94 for a Java spec for Rules Engines
or this google query for some theory.
Norvig's and Russell's Artificial Intelligence: A Modern Approach
also has good explanations, and is a good introduction to AI in general (though being a textbook, it's pricey at > $90 US)).
(Yet another side note: the computational complexity of this pattern matching can be enormous, but the
Rete Algorithm will help, so don't
prematurely optimize your rules.)
Drools
Now that we know a bit of the theory behind rules-based systems, let's get into the practical to show
how easy it can be (and aid in removing fear of new technology to become a generalist).
First, you can get Drools 2.5 at Codehaus or
version 3, 4 or better from JBoss.
At the time of writing, the original Drools lets you use XML with Java or Groovy, Python, or Drools' own
DSL to implement rules, while the JBoss version (I believe) is (still) limited to Java or the DSL.
First, you'll need to download Drools and unzip it to a place you keep external Java libraries.
I'm working with Drools 4.0.1. After that, I created a new Java project in Eclipse and added a new user
library for Drools, then added that to my build path (I used all of the Drools JARs in the library).
(And don't forget JUnit if you don't have it come up automatically!)
Errors you might need to fix
For reference for anyone who might run across the problems I did, I'm going to include a few of the
errors I came into contact with and how I resolved them. I was starting with a pre-done example, but
I will show the process used to create it after trudging through the errors. Feel free to
skip this section if you're not having problems.
After trying the minimal additions to the build path I mentioned above, I was seeing an error
that javax.rules was not being recognized. I added
jsr94-1.1.jar to my Drools library (this is included under /lib in the Drools download) and it was
finally able to compile.
When running the unit tests, however, I still got this error:
org.drools.RuntimeDroolsException: Unable to load dialect 'org.drools.rule.builder.dialect.java.JavaDialectConfiguration:java'
At that point I just decided to add all the dependencies in /lib to my Drools library and the error
went away. Obviously you don't need Ant, but I wasn't quite in the mood to go hunting for the minimum
of what I needed. You might feel differently, however.
Now that the dialect was able to be loaded, I got another error:
org.drools.rule.InvalidRulePackage: Rule Compilation error : [Rule name=Some Rule Name, agendaGroup=MAIN, salience=-1, no-loop=false]
com/codeodor/Rule_Some_Rule_Name_0.java (8:349) : Cannot invoke intValue() on the primitive type int
As you might expect, this was happening simply because the rule was receiving an int and was
trying to call a method from Integer on it.
After all that, my pre-made example ran correctly, and being comfortable that I had Drools working,
I was ready to try my own.
An Example: Getting a Home Loan
From where I sit, the process of determining how and when to give a home loan is complex and can change
quite often. You need to consider an applicant's credit score, income, and down payment, among
other things. Therefore, I think it is a good candidate for use with Drools.
To keep the tutorial simple
(and short), our loan determinizer will only consider credit score and down payment in regards to the
cost of the house.
First we'll define the HomeBuyer class. I don't feel the need for tests, because as you'll
see, it does next to nothing.
Next, we'll need a class that sets up and runs the rules. I'm not feeling
the need to test this directly either, because it is 99% boilerplate and all of the code
gets tested when we test the rules anyway. Here is our LoanDeterminizer:
publicclassLoanDeterminizer{ // the meat of our class privateboolean_okToGiveLoan; privateHomeBuyer_homeBuyer; privateint_costOfHome; publicbooleangiveLoan(HomeBuyerh,intcostOfHome){ _okToGiveLoan=true; _homeBuyer=h; _costOfHome=costOfHome; ArrayList<Object>objectList=newArrayList<Object>(); objectList.add(h); objectList.add(costOfHome); objectList.add(this); return_okToGiveLoan; } publicHomeBuyergetHomeBuyer(){return_homeBuyer;} publicintgetCostOfHome(){return_costOfHome;} publicbooleangetOkToGiveLoan(){return_okToGiveLoan;} publicdoublegetPercentDown(){return(double)(_homeBuyer.getDownPayment()/_costOfHome);} // semi boiler plate (values or names change based on name) privatefinalStringRULE_URI="LoanRules.drl";// this is the file name our Rules are contained in publicLoanDeterminizer()throwsException// the constructor name obviously changes based on class name { prepare(); } // complete boiler plate code from Venkat's presentation examples follows // I imagine some of this changes based on how you want to use Drools privatefinalStringRULE_SERVICE_PROVIDER="http://drools.org/"; privateStatelessRuleSession_statelessRuleSession; privateRuleAdministrator_ruleAdministrator; privateboolean_clean=false; protectedvoidfinalize()throwsThrowable { if(!_clean){cleanUp();} } privatevoidprepare()throwsException { RuleServiceProviderManager.registerRuleServiceProvider( RULE_SERVICE_PROVIDER,RuleServiceProviderImpl.class);
And our test fails, which is what we wanted. We didn't yet create our rule file, LoanRules.drl, so
let's do that now.
package com.codeodor
rule "Poor credit score never gets a loan"
salience 2
when
buyer : HomeBuyer(creditScore < 400)
loan_determinizer : LoanDeterminizer(homeBuyer == buyer)
then
System.out.println(buyer.getName() + " has too low a credit rating to get the loan.");
loan_determinizer.setOkToGiveLoan(false);
end
The string following "rule" is the rule's name. Salience is one of the ways Drools performs conflict resolution.
Finally, the first two lines tell it that buyer is a variable of type HomeBuyer with a credit score of less than 400
and loan_determinizer is the LoanDeterminizer passed in with the object list
where the homeBuyer is what we've called buyer in our rule. If either of
those conditions fails to match, this rule is skipped.
Hopefully that
makes some sense to you. If not, let me know in the comments and I'll try again.
And now back to
our regularly scheduled test:
running it again still results in a red bar. This time, the problem is:
org.drools.rule.InvalidRulePackage: Rule Compilation error : [Rule name=Poor credit score never gets a loan, agendaGroup=MAIN, salience=2, no-loop=false]
com/codeodor/Rule_Poor_credit_score_never_gets_a_loan_0.java (7:538) : The method setOkToGiveLoan(boolean) is undefined for the type LoanDeterminizer
The key part here is "the method setOkToGiveLoan(boolean) is undefined for the type LoanDeterminizer."
Oops, we forgot that one. So let's add it to LoanDeterminizer:
Now running the test results in yet another red bar! It turns out I forgot something pretty big (and basic) in
LoanDeterminizer.giveLoan(): I didn't tell it to execute the rules. Therefore, the default
case of "true" was the result since the rules were not executed.
Asking it to execute the rules is as
easy as this one-liner, which passes it some working data:
_statelessRuleSession.executeRules(objectList);
For reference, the entire working giveLoan method is below:
publicbooleangiveLoan(HomeBuyerh,intcostOfHome)throwsException{ _okToGiveLoan=true; _homeBuyer=h; _costOfHome=costOfHome; ArrayList<Object>objectList=newArrayList<Object>(); objectList.add(h); objectList.add(costOfHome); objectList.add(this); _statelessRuleSession.executeRules(objectList); // here you might have some code to process // the loan if _okToGiveLoan is true return_okToGiveLoan; }
Now our test bar is green and we can add more tests and rules. Thankfully, we're done with programming
in Java (except for our unit tests, which I don't mind all that much).
To wrap-up the tutorial I want to focus on two more cases: Good credit score always gets the loan and
medium credit score with small down payment does not get the loan. I wrote the tests and rules
iteratively, but I'm going to combine them here for organization's sake seeing as I already demonstrated
the iterative approach.
publicvoidtest_good_credit_rating_gets_the_loan()throwsException{ LoanDeterminizerld=newLoanDeterminizer(); HomeBuyerh=newHomeBuyer("Warren Buffet",800,0); booleanresult=ld.giveLoan(h,100000000); assertTrue(result); // maybe some more asserts if you performed processing in LoanDeterminizer.giveLoan() ld.cleanUp(); }
rule "High credit score always gets a loan"
salience 1
when
buyer : HomeBuyer(creditScore >= 700)
loan_determinizer : LoanDeterminizer(homeBuyer == buyer)
then
System.out.println(buyer.getName() + " has a credit rating to get the loan no matter the down payment.");
loan_determinizer.setOkToGiveLoan(true);
end
rule "Middle credit score fails to get a loan with small down payment"
salience 0
when
buyer : HomeBuyer(creditScore >= 400 && creditScore < 700)
loan_determinizer : LoanDeterminizer(homeBuyer == buyer && percentDown < 0.20)
then
System.out.println(buyer.getName() + " has a credit rating to get the loan but not enough down payment.");
loan_determinizer.setOkToGiveLoan(false);
end
As you can see, there is a little bit of magic going on behind the scenes (as you'll also find in Groovy) where
here in the DSL, you can call loan_determinizer.percentDown and it will call getPercentDown
for you.
All three of our tests are running green and the console outputs what we expected:
Ima Inalotadebt and Idun Payet has too low a credit rating to get the loan.
Warren Buffet has a credit rating to get the loan no matter the down payment.
Joe Middleclass has a credit rating to get the loan but not enough down payment.
As always, questions, comments, and criticism are welcome. Leave your thoughts below. (I know it was
the length of a book, so I don't expect many.)
Finally, as with my write-ups on
Scott Davis's Groovy presentation,
his keynote,
Stuart Halloway's JavaScript for Ajax Programmers,
and Neal Ford's 10 ways to improve your code,
I have to give Venkat most of the credit for the good stuff here.
I'm just reporting from my notes, his slides,
and my memory, so any mistakes you find are probably mine. If they aren't, they likely should have been.
Posted by Sam on Sep 02, 2007 at 03:48 PM UTC - 5 hrs
Bioinformatics is one area of
computing where you'll still want to pay special attention to performance. With the
human genome consisting of 3 billion bases, using one byte per base gives you
three gigabytes of data to work with. Clearly, something that gives you only a
constant reduction in computational complexity can result in huge time savings.
Because of that concern for performance, I expect to be working in C++ regularly this
semester. In fact, the first day of class was a nice review of it, and I welcome the
change since it's been many years since I've done much of anything in the language.
More...
One thing that struck me as particularly painful was memory management and pointers.
When was the last time you had to remember to delete [] p;? The power of
being able to do such low-level manipulation may be inebriating, but you better not get
too drunk. How ever would you be able to keep
the entire program in your head? (Paul Graham's timing was amazing, as I saw
he posted that article about 10 minutes before my re-introduction to C++).
C++ works against that goal on so many levels, particularly with the indirection pointers
provide. Something like this simple program is relatively easy to understand and remember:
It is easy to see that i is a pointer to a location in heap memory
that's holding data to be interpreted as an integer. To set or get that value you
need to dereference the pointer, using the unary * operator.
But what happens when you increase the complexity a little? Here we'll take a reference
to a pointer to int.
intprintn(int*&n) { cout<<*n; }
The idea stays the same, and is still relatively simple. But you can tell it is
starting to get harder to decide what's going on. This program sets a variable and
prints it. Can you imagine working with pointers to pointers or just a couple of
hundred lines of this? Three cheers for the people that do.
What if we change it a bit?
intprintn(int*n) { cout<<*n; }
Are we passing a pointer by value, an int by reference, or is something else
going on?
It makes me wonder how many times people try adding or removing a * when trying to
fix broken code, as opposed to actually tracing through it and understanding what is
going on. I recall doing a lot of that as an undergrad.
I'm not convinced mapping everything out would have been quicker. (I'm not
convinced throwing asterisks around like hira shuriken was either.) One thing is for sure though - getting back into C++ will make my head hurt, probably more than trying to understand the real bioinformatics subject matter.
Both Venkat from Agile Developer/Relevance and Neal Ford from ThoughtWorks are excellent, entertaining, and informative speakers that I've had a chance to see.
But I'm sure Vali Ali of HP, Sridhar Vajapey from Sun, Ben Galbraith of Ajaxian and more, Jon Schwartz of Phrogram Company, Peter A. Freeman (a former Assistant Director of NSF who is currently at Georgia Tech), and Bjarne Stroustrup, the creator of C++ will also have interesting talks. (Thanks to Venkat for background on the speakers I didn't know about)
If you're going to be in or around Houston (or can make it here) on that weekend, I suggest you register at no cost here.
In that post, Blaine notes that string concatenation "make[s] your code slow and consumes memory," and that you are often told to use something like StringBuilder (in Java) when doing a lot of string concatenations.
His position is that the language should abstract that for us and "do the right thing" when you use + (or the concatenation operator). Using + as a message to an object, it would be possible for us mere programmers to implement a string builder on top of + to really speed it up. Of course that's not the case in Java, but he shows an implementation of it in Ruby that, over 1 million iterations of concatenating 'a' to a string, takes only 23.8 seconds versus 4500+ the "normal way."
I'd like to see benchmarks in normal usage to see if that speed increase is typical in a system that uses tons of concatenation, but those numbers are still staggering.
And I agree the language should do it for us, assuming it is possible. I add the clause about possibility there because I can't comprehend why it hasn't been done to begin with (nor have I thought a lot about it). Good catch Blaine.
Update: Chad Perrin notices that String#<< and String#concat do the same thing.
Posted by Sam on Aug 23, 2007 at 09:16 PM UTC - 5 hrs
The next few days in Houston are busy for programming technophiles. A couple of quick reminders:
BarCampHouston 2 is this Saturday, August 25, 2007 beginning at 9:00 AM at Houston Technology Center.
Update: I had the map wrong since it was wrong on the BarCampHouston wiki page. I hope no one went to the wrong place. Here is the correct one: HTC.
I also decided to take the day off and chill out instead of heading up there.
My apologies to anyone who had planned to say hello!
HouCFUG is hosting a ColdFusion 8 release party on Tuesday, August 28 from noon to 1:00 PM at Ziggy's Healthy Grill where they'll be giving away a licensed copy of CF 8.
Finally, Agile Houston is hosting a session with Robert Martin, object mentor on Tuesday as well. It's at 6:30 PM in PGH 563 on the University of Houston Campus.
I should be at both BarCamp and at Robert's presentation, but I'll be in class during HouCFUG's meeting.
Posted by Sam on Aug 17, 2007 at 12:42 PM UTC - 5 hrs
This week's advice from Chad Fowler's gem of a book really resonated with me when I
read it, and it continues to do so. It was one of my favorite chapters in the book: Be a Generalist.
Don't be "just a coder" or "just a tester" or just anything. Doing so leaves you useful
only in certain contexts, when reality dictates that it would be better to be generally useful.
More...
Towards the end of the chapter, Chad tells us about his early days in IT:
What first amazed me most when I entered the information technology field was that many
well-educated programmers (maybe most) didn't know the first thing about how to
set up the systems they used for development and deployment. I worked with developers who
couldn't even install an operating system on a PC if you asked them to, much less set
up and application server on which to deploy their applications.
After reading that, I thought to myself, "That's me." Rather than wallow in self-pity, I
decided to do something about it.
Where I used to ask "our server guy" (that's his official name) to do something,
I started asking him how to do it. ButI didn't immediately start there - I started trying
to figure it out on my own before going to him for help (à la Mr. Raymond's famous
guide). Now I don't need help in setting up virtual directories or web sites or my development environment (yes,
I was that bad).
The chapter ends with advice to "list the dimensions on which you may or may not be generalizing your
knowledge and abilities" and to do something about it. There are an "infinite number" of aspects for
which you could do it, but Chad limits his discussion to five: "Rung on the career ladder, Platform/OS,
Code vs. data, Systems vs. applications, [and] Business vs. IT."
I've got a long way to go, but I'm slowly getting to where I want to be. Are you doing anything?
Posted by Sam on Aug 10, 2007 at 11:58 AM UTC - 5 hrs
I'm looking for a couple of pieces of software and was hoping to get some expert opinion (that's why I'm asking you!).
First, I need a standalone diff/merge tool for Windows. I've seen a couple from searching Google, but was hoping for a non-paid version as it is only a temporary solution. If you don't know of a free one, I'll still be glad to know what you use that you were willing to pay for (and what you think of it).
More...
Next, I'm looking for some time-boxing software. I saw this but didn't give it a try yet. I'm not really in need of its many features though. I just want a way to set tasks for specific times for each day of the week and have it repeat itself weekly. It should also reside in the system tray and just alert me when a box of time begins or ends. It would be nice if there was a way to sync it up with other computers over the internet (I regularly work on three machines), but that's not a firm requirement.
Do you know of anything? Maybe I should write it myself? (yeah, when I pull some time out of ...)
And just so you don't feel you've left empty-handed, I'll include this quote
from Alberto Savoia at the blog for the book Beautiful Code:
The odds of finding truly beautiful code in most production systems seem to be on par with the odds of finding a well-read copy of IEEE Transactions on Software Engineering in Paris Hilton's apartment.
Posted by Sam on Aug 07, 2007 at 05:53 PM UTC - 5 hrs
This week's advice from My Job Went to India is easy to follow: invest in yourself. In particular, Chad mentions some advice found in The Pragmatic Programmer. Namely, that you should learn a new language (every year). But don't just learn any language - it should be a paradigm shifting language. In other words, "don't go from Java to C#." Go from ColdFusion to Haskell or Java to Ruby or Visual Basic to Lisp.
To illustrate the point, Chad tells the story of the developer who, when asked about having used a particular technology, replied, "I haven't been given the opportunity to work on that." Unless you don't own a computer (which Chad says probably was the case for that developer), you don't need the opportunity to be given to you. You need to take some time and do it yourself.
More...
As I said in the last post about this book, I used to be that developer. Since then, I've improved myself considerably in Java and learned a great deal about Ruby, among other things.
But asking "what's your new language this year?" misses the point. The big shift comes when you accept responsibility for your own improvement. Once you've done that, instead of feeling threatened by new (to you) technologies, you start to embrace them.
Now, instead of avoiding projects in unfamiliar territory, I'm asking for them. Instead of laying down to be steamrolled by something I've yet to try, I take at least a few minutes to familiarize myself with it, like I did recently with ANTLR. When I've got a bit of extra time on my hands, I'll go all out and even do something useful with it.
Not surprisingly, everyone who responded preferred the second one. On the other hand, I was expecting at least someone to prefer the mish-mash because it has all the logic right there where you can see it rather than hiding it. I'm glad no one said that, but I've heard it said about using classes, functions, or different files for instance.
The point of the post was simple: I just wanted to highlight that you can use variables to store results of complex boolean expressions. Of course, most people already know this. Even I know it.
So why is it when I look through code I see so little use of it?
Posted by Sam on Aug 04, 2007 at 01:15 PM UTC - 5 hrs
Before reading Chad's book, I was a one-"stack" kind of programmer. I knew a bit about Java and .NET, and I was fairly competent in C and C++ (though I wouldn't say I knew much about OO). I had done a couple of things in PHP and ASP. But for the most part, I was only using ColdFusion and Microsoft SQL Server on Windows with IIS as the web server. Consequently, I knew HTML and a bit of CSS too. I largely shied away from learning anything new, and tried my hardest to only work with what I knew well.
More...
That sounds incredibly unlike me now. Although the change was occurring before I read his book (as evidenced by the fact that I was reading it in the first place), it certainly helped accelerate things.
(Let me also say I feel weird posting a link to the book each time I write one of these, but I don't want someone new to come along and think "WTF's he on about?" So for all you regulars, please ignore what must seem like link spam for the greater good of improving oneself: I'm not a PragProg salesman or affiliated with them in any way. Though I am an affiliate with Amazon, I don't get any special consideration for promoting this book out of all the other things I could be writing about.)
Anyway, Chad suggests making "a list of early, middle, and late adoption technologies" (page 23). Then, note the one's you're strong in, ones you have some experience in, and some you have no experience in. Try to notice any pattern there. And finally, "are there any technologies around the far edges that you have some special interest in?" Those are the high risk/high reward type cases where there is more money to be made. The middle has many more jobs, but also much more competition from other programmers.
So here's a small list I made (from early adoption to late adoption). A + marks technologies I'm fairly strong in while a - is just some experience. I 'm trying to be honest with myself, so call me out if you think I've got something wrong:
Early adoption: Lisp(-), Haskell, Erlang, Ruby(+), JavaScript(+)
Late adoption: ASP(-), JSP(+), ASM, Visual C++(-), COBOL
I put Lisp in early adoption because I could foresee it becoming big at some point. Probably not, but I don't think its mainstream or in its sunset years either. Similarly, I think JavaScript while abundantly adopted is only done for simple web scripting. I see its importance rising.
I'm not sure where CF belongs, honestly. Certainly not early adoption. It's in the middle somewhere, but I don't know how early in the middle or how late. I'm tending later. For Java, I put it near late adoption because I think its importance as a language is diminishing, though its importance as a platform will remain steady.
I'm not sure where to put PHP either honestly. I almost went with late adoption because I can't foresee myself ever looking for a job doing PHP. But that's just me. I certainly don't think its importance is on the rise, however. Of course, I don't think that about CF either, given prevailing attitudes.
That's just a few large things- a lot related to web development (since that's what I'm most familiar with). I'm also having trouble thinking of technologies I have no experience in whatsoever. There are tons, to be sure, I'm just not finding any when it comes to the language level of granularity. What important languages have I missed? I know I missed SmallTalk, but I don't know whether to put that in early or late adoption. At the moment it belongs in late, but will its importance rise?
Anyway, what does your list look like? What technologies are missing from mine and where would you put them on the curve?
Posted by Sam on Aug 02, 2007 at 11:15 AM UTC - 5 hrs
A couple of evenings ago, after I wrote about how I got involved in programming and helped a friend with some C++ (he's a historian), I got inspired to start writing a scripting engine for a text-based adventure game. Maybe it will evolve into something, but I wanted to share it in its infancy right now.
My goal was to easily create different types of objects in the game without needing to know much about programming. In other words, I needed a declarative way to create objects in the game. I could just go the easy route and create new types of weapons like this:
More...
short_sword = create_weapon(name="short sword", size="small", description="shiny and metallic with a black leather hilt", damage="1d6+1", quantity_in_game=10, actions="swing, stab, thrust, parry")
But that's not much fun. So I started thinking about how I'd like to let the game system know about new types of weapons. A DSL, perhaps. Eventually, I settled on this syntax:
short_sword= create_small_shiny_and_metallic_with_a_black_leather_hilt_weapon. named"Short Sword"do damage_of1.d6+1 with_actions:swing,:stab,:thrust,:parry and_there_are10.in_the_world end
Name: Short Sword
Size: small
Description: shiny and metallic with a black leather hilt
Damage: 1d6 + 1
Actions: [:swing, :stab, :thrust, :parry]
Quantity in game: 10
We could create just about any game object like that, but I've yet to do so, and I don't think
adding it here would do much of anything besides add to the length of the post.
Ideally, I'd want to remove some of those dots and just keep spaces between the words, but then Ruby
wouldn't know which arguments belonged to which methods. I could use a preprocessor that would allow
me to use spaces only and put dots in the appropriate places, but that would needlessly complicate things
for right now. I'll consider it later.
The first thing I noticed about the syntax I wanted was that the Integer class would
need some changes. In particular, the methods in_the_world and d6
(along with other dice methods) would need to be added:
classInteger defin_the_world self end
defd6 DieRoll.new(self,6) end end
The method in_the_world doesn't really need to do anything aside from return the object it
is called upon, so that the number can be a parameter to and_there_are. In fact, we
could do away with it, but I think its presence adds to the readability. If we kept it at
and_there_are 10, the code wouldn't make much sense.
On top of that, we might decide that
other methods like in_the_room or in_the_air should be added. At that point
we could have each return some other object that and_there_are could use to determine
where the objects are. Upon making that determination, it would place them in the game accordingly.
Then we see the d6 method. At first I tried the simple route using what was available and
had d6 return self + 0.6. Then, damage_of could figure it out from there.
However, aside from not liking that solution because of magic numbers, it wouldn't work for weapons with
bonuses or penalties (i.e., a weapon that does 1d6+1 points of damage). Therefore, we need to introduce
the DieRoll class:
classDieRoll definitialize(dice,type) @dice=dice @type=type @bonus=0 end
def+(other) @bonus=other self end
defto_s droll=@dice.to_s+"d"+@type.to_s droll+=@bonus.to_sif@bonus<0 droll+=" + "+@bonus.to_sif@bonus>0 droll end end
The initialize and to_s methods aren't anything special.
We see that initialize simply takes its arguments and sets up the DieRoll
while to_s just formats the output when we want to display a DieRoll
as a string. I'm not too thrilled about the name of the class, so if you've got something better,
please let me know!
The + method is the only real interesting bit here. It's what allows us to set the bonus
or penalty to the roll.
Finally, we'll need to define named, damage_of, with_actions,
and_there_are,
and create_small_shiny_..._with_a_black_leather_hilt_weapon. I've put them in a
module now for no other reason than to have easy packaging. I'd revisit
that decision if I were to do something more with this.
In any case, it turns out most these methods are just cleverly named setter functions,
with not much to them. The two notable exceptions are
create\w*weapon and named. You can see all of them below:
defwith_actions(*action_list) @actions=action_list end
defmethod_missing(method_id,*args) create_weapon_methods=/create_(\w*)_weapon/ ifmethod_id.to_s=~create_weapon_methods @description=method_id.to_s.gsub(create_weapon_methods,'\1') @size=@description.split('_')[0] @description.gsub!("_"," ") @description.gsub!(@size,"") else raisemethod_id.to_s+" is not a valid method." end self end
defand_there_are(num) @quantity_existing=num end aliasthere_areand_there_are
end
Although it is slightly more than a setter, named is still a simple function. The only
thing it does besides set the name attribute is yield to a block that is passed to it.
That's the block we see in the original syntax beginning with do and ending (surprisingly)
with end.
The last thing is create_size_description_weapon. We use method_missing to
allow for any size and description, and check that the method matches our
regex /create_(\w*)_weapon/ before extracting that data. If it doesn't match, we just raise an
exception that tells us the requested method is not defined.
If I were to take this further, I would
also check if the method called matched one of the actions available for the weapon. If so, we'd
probably find a way to classify actions as offensive or defensive. We could then print something like
"You #{method_id.to_s} your sword for #{damage.roll} points of damage" (assuming we had a
roll method on DieRoll).
As always, any thoughts, questions, comments, and critcisms are appreciated. Just let me know below.
Posted by Sam on Aug 01, 2007 at 02:23 PM UTC - 5 hrs
From a project I was working on recently I ran into this problematic and fairly complex boolean expression (pseudocode):
if not arguments.pending and arguments.umoneyamount is 0 and aname.agencyname is arguments.agencyname
do something
elseif ((aname.agencyname is arguments.agencyname and arguments.pending) or (session.id is 1 or (isdefined("session.realid") and session.realid gt 0)) or (not arguments.pending and arguments.umoneyamount is 0 and local.isMyClient)) and (session.id is 1 or arguments.pending)
do something else
else
do the other thing
end
Or alternatively,
local.isMyClient = aname.agencyname is arguments.agencyname
local.isPending = arguments.pending
local.isAdmin = session.id is 1 or (isdefined("session.realid") and session.realid gt 0)
local.canAddUtilities = not arguments.pending and arguments.umoneyamount is 0 and local.isMyClient
local.allow_edit = (local.isMyClient and local.isPending) or local.isAdmin or local.canAddUtilities
if local.canAddUtilities
do something
elseif local.allow_edit and (session.id is 1 or arguments.pending)
do something else
else
do the other thing
end
To combat code monkey syndrome, Chad suggests we have lunch with business people and read trade magazines for our business domains as often as we can.
More...
Working for a tiny consulting company, I get the benefit of being close to all the business decisions, but not in many specialized domains. However, since I made the decision to stop being a "code robot" (Chad's term), I've always taken the opportunity to talk with clients or meet them for lunch to discuss their domains. Even more recently, a couple of us here have taken to reading trade publications related to a product we're building.
Doing so helps you understand why some of those "crazy" requests are made, and what you can do to make them work in the system while still accomplishing the client's goals. And things just seem to work better that way. Nowadays, I'm no longer getting any "that's a nice system, but it's not what I wanted" comments due to keeping myself stuck in a walled garden. Instead, I'm building software customers want and will use. And the purely selfish benefit: I'm adding to my value as an employee or contractor in those domains.
As an aside, last week I was on vacation, so that's why you didn't see this then. I'll try to make up for it and post two this week.
So are you a code monkey? Are you trying to evolve into a code human?
In any case, I like the idea. Having had some education in politics and computer science, this appealed to me even more than it might have, but I'd think I'd recommend reading it anyway.
My favorite quote?
We will not ship code that fails to pass any unit test... Well, then, we'll not write any unit tests, and we'll have met that goal!
What do you think of viewing software projects as conflict?
Posted by Sam on Jul 28, 2007 at 05:52 PM UTC - 5 hrs
Like many programmers, I started doing this because of my interest in video games. I was 6 years old when I first touched a computer. It was an Apple IIe and I would play a game involving Donald Duck, his nephews, and a playground (I forget the name of the game). I was hooked, and took every available chance to play that I could.
Subsequently, I got a Nintendo and played all sorts of games. Super Mario Bros. was my favorite, of course, and it greatly inspired me. After a while, I was spending more time planning and drawing levels in my notebook for two-dimensional side-scrolling video games than I was playing them. It wasn't long before I envisioned my own game console.
More...
Fast forward a few years to when I had a computer of my own. As I recall, it had a blazing fast 80368 processor running at 33 MHz. With 4 MB of RAM and a 20MB hard drive. I was set.
I spent a lot of time rummaging through the QBasic source code of Nibbles, attempting to figure out how it worked, and modifying it in places to see what happened. Eventually, I got sick of looking at other people's code and decided to write my own. Once I figured out how to PRINT and INPUT, I was ready to program my first text-based adventure game (I think I was 12 or 13 at the time).
Since then (in the last 15 years or so), I've kept the dream alive, but haven't done much to pursue it. Some friends and I spent a night trying to figure out how to program a MUD, I spent some time working with OpenGL (but found it too tedious for what I wanted to do), and started a couple of web based games that never got far off the ground except for fleshing out concepts and plots for the games.
Anyway, recently on Ruby-Talk there was a question about programming a game and a couple of good responses that gave me some resources I'd like to share (and record for my future inspection). Here they go:
Gosu - a "2D game development library for the Ruby and C++ programming languages."
RRobots - a "simulation environment for robots" whose source code I'd like to peruse.
Novashell - a "high-level 2D game maker that tries to handle all the hard work behind the scenes" from Seth Robinson, creator of one of my all-time favorite games, Legend Of the Red Dragon. (Incidentally, one of my friends and fellow ANSI artists from the BBS days, Zippy, did some art for Part II. Unfortunately, I couldn't find him online.)
RPG Maker XP - A graphical game engine that "is equipped with the Ruby Game Scripting System (RGSS), based on the Ruby language and customized especially for this program."
Gamebryo - the granddaddy of them all, this engine has been used by Civilization IV and The Elder Scrolls IV. No telling how much it costs though.
Posted by Sam on Jul 27, 2007 at 03:43 PM UTC - 5 hrs
We could all stand to be better at what we do - especially those of us who write software. Although
many of these ideas were not news to me, and may not be for you either, you'd be surprised at how
you start to slack off and what a memory refresh will do for you.
Here are (briefly)
10 ways to improve your code from the
NFJS
session I attended with Neal Ford.
Which do you follow?
More...
Know the fundamentals
It was no surprise that Neal led off with the DRY
principle. Being one from the school of thought that "code reuse" meant "copy-and-pastable with few changes," I
feel this is the most important principle to follow when coding.
Neal uses it in the original sense:
Refuse to repeat yourself not just in your code, but all throughout the system.
To quote (If I remember correctly, The Pragmatic Programmer): "Every piece of knowledge must have a single, unambiguous, authoritative representation within a system."
I can't think of anything that wouldn't be improved by following that advice.
Continuous integration and version control are important fundamentals as well. Continuous integration means you
know the code base at least compiles, and you can have it run your unit tests as well. The codebase is verified as always working
(at least to the specs as you wrote them - you might have gotten them wrong, of course).
Using version control means you don't have to be afraid of deleting that commented out code that you'll probably never use again but
you keep around anyway "just in case." That keeps your code clean.
Finally, Neal suggests we should use static analysis tools such as FindBugs
and PMD that inspect our code, look for bad patterns, and suggest fixes and
places to trim. Those two are for Java. Do you know of similar applications for other platforms? (Leave a comment please!)
Analyze code odors and remove them if they stink
Inheritance is a smell. It doesn't always have to smell bad, but at least you should take the time
to determine if what you really need is composition.
Likewise, the existence of helper or utility classes often indicates a "poor design." As
Neal notes, "if you've gotten the abstraction correct, why do you need 'helpers'?" Try to put
them in "intelligent domain object[s]" instead.
Static methods are an indication you are thinking procedurally, and they are "virtually impossible to test."
Seeing the procedural mindset is easy, I think, but why are they hard to test?
Finally, avoid singletons. I know Singleton is everyone's favorite design
pattern because it's so easy to conceptualize, but as Neal mentions:
They're really just a poor excuse for global variables.
They violate SRP (link is to a PDF file)
by mixing business logic with policing you from using too many
They make themselves hard to test
It's very hard to build a real singleton, as you have to ensure you are using a unified class loader.
More that I won't get into here...
Kill Sacred Cows
Neal started off saying that "sacred cows make the tastiest hamburger" and told the story of the angry monkeys:
A few monkeys were put in a room with a stepladder and a banana that could only be reached if the
monkeys used the stepladder. However, when a monkey would climb upon the stepladder, all the
monkeys would be doused with water. Then new monkeys were introduced and when they
tried to use the stepladder, the other monkeys would get angry and beat him up. Eventually,
the room contained none who had been doused with water, but the monkeys who had been beat up for
using the stepladder were still refusing to allow new monkeys to get the banana.
That is the light in which you may often view sacred cows in software development. In particular,
Neal points out that
StickingToCamelCaseForSentenceLongTestNamesIsRidiculous so_it_is_ok_to_use_underscores
in languages_that_standardized_on_camel_case for your test names.
Using getters and setters does not equate to encapsulation. One of my favorite sayings,
and a reference to why
they are evil is appropriate.
Avoidance of multiple returns in a method is antiquated because it comes from a time
when we weren't using tiny, cohesive methods. I still like to avoid them, but will
use them when it makes the code more readable.
Polluting interface names with "I", as in ISomeInterface should be avoided.
It is contrary to what interfaces are about. Instead, you should decorate the concrete
class name.
Your objects should be Good Citizens. Never let them exist in an invalid state.
Use Test Driven Development
TDD provides "explicit dependency management" because you must think about dependencies
as you code. It provides instant feedback and encourages you to implement the simplest
thing that works.
Speculative development saves time if
• You have nothing better to work on right now
• You guarantee that it won't take longer to fix later
Is that ever going to be true?
Use reflection when you can (and when it makes sense)
It's not slow, and it can be extremely useful!
Colour Your World
Nick Drew, a ThoughtWorker in the UK came up with a system of coloring the code you write
by classifying it as to who will use the feature: only a specific business customer,
only a particular market, many markets, or unchangeable infrastructure. Based on
the color and amount of it, you can decide what value or cost your code has.
It's a very interesting system, so I recommend seeing a more detailed overview in
Neal's handout (PDF).
You can find it on pages 21-22.
Use a DSL style of coding
It lets you "[Build] better abstraction layers, using language instead of trees" while
"utilizing" current building blocks. As he pointed out, "every complicated human endeavor
has its own DSL. [If you can] make the code closer to the DSL of the business [then] it is
better abstracted."
I'll add that it's easier to spot logical errors as well.
A funny quote from Neal: "It's almost as if in Java we're talking to a severely retarded person."
Regarding that, he recommended looking at EasyMock as a good
example of fluent interfaces, and that having setters return void in a waste.
Instead, we should return this so that calls can be chained together (and if
you are using fluent-interface type names, you could construct sentences in your DSL that way).
Neal also noted a distinction between an API and DSL: API has an explicit context that must
be repeated with each call. However, a DSL uses an implicit context.
SLAP tells us to keep
all lines of code in a method at the same level of abstraction.
Steve McConnell's Code Complete 2
tells us about this as well, but I don't recall if it had the clever acronym.
And finally, Think about Antiobjects.
Quoting Neal, "Antiobjects are the inverse of what we perceive to be the computational objects."
So instead of solving the really hard "foreground" problem, have a look at the "background"
problem (the inverse) to see if it is easier to solve.
As an example, he used PacMan:
Rather than constructing a solution for the "shortest route around the maze," the game has
a "notion of a PacMan 'scent'" for each tile." That way, the ghosts follow the strongest scent.
Posted by Sam on Jul 19, 2007 at 10:26 AM UTC - 5 hrs
In the past you used to give and receive advice that keeping form state in a session was a valid way to approach the problem of forms that span several pages. It's no longer sound advice, and it hasn't been for a while.
Even before tabs became popular, a few of us were right-clicking links and opening-in-new-windows. It's a nice way to get more things done quicker: loading another page while waiting for the first one to load so that you are doing something all the time, rather than spending a significant amount of time waiting. It even works well in web applications - not just general surfing.
More...
But back then, and even until relatively recently when tabs were confined to the realm outside of Internet Explorer, the amount of people who used the approach in web applications was small. So small, in fact, we felt we could be lazy and hold what should have been repeated as hidden form fields within sessions instead.
Now Internet Explorer has tabs, and people are starting to use them. That changes things as people start to internalize the concept and use the productivity-boosting feature in ways that break our applications. Now, instead of presenting a list of customers and expecting our user to click one and edit the associated records until he's complete; our users are opening three or four customers (customerA through customerD) at a time in separate tabs. If you had stored form state in the session, when they think they are editing customerA, they will in fact be changing the record for customerD with a form that is pre-filled with values from customerA. Oops.
Luckily, the fix is relatively easy: just start storing the state in the form instead of the session. Of course, that's only "easy" if the path through your forms is linear. What about the case where many different forms can be traversed in just about any order, sometimes they appear based on what other forms said, and some are required while others can be skipped?
It's still easy if you've got automated tests that cover the possible scenarios. Just strip out the session and add the data to the forms until the tests pass. If you don't have tests, and you are not familiar enough with the different paths to create 100% coverage (or its been so long you forgot the paths), it's not looking good for you. Chances are, you don't have tests. This is a relic from the days before tabbed browsing, and who was doing automated testing then?
But, there is still one way out for you: inject the needed fields into your form after it's been crested but before it has been sent to the browser. I've not yet come across a situation in Rails or Javaland where I needed to do this, so I haven't investigated how to do it there (and Rails is new in the first place, so its unlikely it would be a problem in any application if you've thought to avoid the practice now that tabbed browsing is popular). But in ColdFusion, it is easy. Since Application.cfm is run before the request, you can check what page is being requested from there and intercept it if the page is one on which you need to do this processing. Wrap a cfinclude of that page in cfsavecontent tags, and now you have a string of what will be sent to the browser. Just find the spot you need to insert your data, insert it, and output the resultant string to the browser.
In my case it was especially easy because fortunately, we were only storing the id of the record in the session and I could be sure it needed to be in every form on the page. Thus, my code looked like this (in Application.cfm):
If you can get at the data before it is output to the browser, this strategy works well. However, I don't like the magic nature of it when you'll be editing the individual files later and wondering why in the world it works. It's only a hack, so expect to learn the application well enough to test it and put the right fix in later. But, this works well as a temporary solution as you can be more sure it works than you can be sure about the flow of the application when it gets quite complex.
Posted by Sam on Jul 16, 2007 at 12:28 PM UTC - 5 hrs
The second talk I attended at NFJS was
Stuart Halloway's
JavaScript for Ajax Programmers. I had planned to attend a different session, but all the seats were full,
and Stuart's presentation was in the large room, so I figured I could sneak in a bit late without anyone
taking much notice.
After attending the session, I wasn't upset that the other one had been full - Stuart had quite a few tidbits of
solid advice to give us. The funny thing is, I read his blog and didn't realize he was at the
conference until I entered the room and saw the first slide. If I had known, I would have likely
attended his presentation anyway, so the fact that the other one was full was a stroke of luck in
that regard (although, I know it would have been good as well because I've
been in courses from the speaker).
More...
The presentation was heavy on code (not a bad thing!), so it will be hard for me
to translate that into a blog post. Instead, I'll focus on some of the ideas he
presented that translate well outside of JavaScript, and leave it to you to see
him present the code some time. I'd recommend it. As with my write-up on
Scott Davis's Groovy: Greasing the Wheels of Java,
Stu gets "all the credit for the good stuff here. I'm just reporting from my notes, his slides,
and my memory, so any mistakes you find are probably mine. If they aren't, they probably should
have been."
Use Firefox, where the Diagnostic Tools Live
We all write stupid code, Stuart told us. There are five mistakes for every good idea. This is amplified
in JavaScript, since it is functionally more dense a language than most we are used to. Therefore,
we need to test much more often in JavaScript than we might in Java - waiting to test every
30 lines is too long, and it will make you miserable.
He started off immediately getting the audience involved in "conference programming" (I think is what he
called it), as opposed to pair programming. For this, he presented some code and showed it in
the browser, and we needed to find all the bugs (and most of them weren't very obvious).
The lesson behind this was that we should develop in Firefox, "where the Diagnostic Tools Live."
There were others as well, but they wouldn't be helpful without exploring the code.
$, and teensy-weensy method names
Stu then led us into the $(object_id or object) method. $ was created in
Prototype (which has a new domain name since I last visited),
and is "now idiomatic in many libraries." For those of you who are unaware, $ wraps
document.getElementById() so you don't have to type that monster of a method call so often.
You can pass it any number of arguments, of a string or an object, and it will return them as an array of
the objects you requested.
That's not the interesting part, however. The conclusions (or lessons learned) are what excites me.
First, we should "handle variable argument lists" and "handle different argument types", both "where reasonable"
(of course). Obviously this only applies in languages which allow such things - but the point is to
examine your situation and see if doing these things would make life easier, and do them if so.
The best part was something I hadn't thought about before, which explains the name of the method ($), and
why it's a good name. You're always told to choose descriptive names for methods and variables, and that
is certainly sound advice. On the other hand, $ isn't descriptive at all. So why is it a good name here?
It's a good name because you use it all the time, you aren't likely to forget it, and you only need to
tell someone else once when they ask what it is. Therefore, methods should be named in proportion
to how often they are used, with the lower frequency generally having longer names. You don't want
to go off in the deep end with this, but $ is in my estimation one of the best things to ever happen
to client-side browser scripting.
Three models for handling an Ajax Response
Stuart went on to defined three approaches to processing Ajax responses: the view-centric, code-centric, and
model-centric Ajax models. The mechanism for view-centric is using
$('objectID').innerHTML='response text' to
redraw parts of a page.
On the other side, the code-centric approach uses eval on the response text, while the model-centric
version parses response text, with using JSON as an example. Stuart showed live examples of each
approach, but I'm not going to get into those here.
I've used them all, but I never took the time to see them as different paradigms, so that's what
interested me the most. However, if you'd like to know more about the approaches, don't hesitate to
ask!
He also covered the object model prototype provides for JavaScript, but since that is better explained in
code that I was trying to avoid in this post, I'll point you to
the Prototype docs.
JavaScript is harder than Java
The final thing that struck me as quite interesting was Stu's discussion of why JavaScript is harder than Java.
In fact, it wasn't so much that it's harder that was interesting, but that he went
through the proper response when someone says "We'd use that, but our development team isn't
good enough to handle it."
Get a new development team then! His analogy was simple: if your dentist is telling you that procedure
X is better for you in this situation, but that he doesn't do it because it's too hard, would you
get another dentist, or have him do a suboptimal procedure?
I'd probably get a new dentist (at least for that instance).
... ... ...
Up next is 10 Ways to Improve Your Code with Neal Ford. Look for it in the coming days.
Posted by Sam on Jul 15, 2007 at 02:10 PM UTC - 5 hrs
The latest Ruby Quiz asks us to
find the maximum contiguous subarray, given an array.
This ties in nicely to something I've been wanting to ask for a while: how do you design your algorithms?
What heuristics do you use? What different approaches do you try? How can you improve your skill set
at designing algorithms?
For the maximum subarray problem, if you didn't know any better, you'd probably implement a solution that
analyzes every possible subarray, and returns the one with the maximum sum:
More...
classArray defsum result=0 self.eachdo|i| result+=i end returnresult end #test every sub array - brute force! defmax_sub_array_order_ncubed left_index=0 right_index=0 max_value=self[left_index..right_index].sum foriin(0..self.length) forjin(i..self.length) this_value=self[i..j].sum if(this_value>max_value) max_value=this_value left_index=i right_index=j end end end returnself[left_index..right_index] end end
If you were a bit more clever, you might notice that self[i..j].sum is equal to
self[i..(j-1)].sum + self[j] in the innermost loop (the sum method itself), and use an accumulator there as opposed
to calculating it each time. That takes you down from n3 to n2 time.
But there are (at least) two other ways to solve this problem:
A divide and conquer approach that uses recursion and calculates the left
and right maximum contiguous subarrays (MCS), along with the MCS that contains the right-most
element in the left side and the left-most element in the right side. It compares the three
and returns the one with the maximum sum. This gets us to O(n log n) time.
An approach I'll call "expanding sliding window." If memory serves me correct, this
aptly describes it or was the way a professor of mine described it.
In any case, the "expanding sliding window"
can do it in one pass (O(n) time), at the cost of a few more variables.
Clearly, these last two approaches aren't nearly as obvious as the first two - so how do you devise them?
I'm fairly confident that the only reason I know about them is from a course in algorithms where they
were presented to me (and I didn't take the time to work-through and reimplement them for this post).
I'm not sure that TDD or just a long ponder
would have led me in that direction.
(Although, one of the solution submitters claims he TDDed the O(n) solution.)
Three thoughts in designing algorithms I use off the top of my head are:
There's always brute force, but is there something better?
Is divide and conquer and option? If so, is it easy enough to implement and understand?
My assumption here is that you're not looking for someone else's code that has implemented it,
or that no one has already solved it. Of course in real work you'd probably want to look for an algorithm
that had already been discovered and published that provides a solution.
Is it just a matter of reading Knuth's
compendium and books on algorithms, becoming familiar with many different types of them for many different data structures?
So I'll ask again: how do you design your algorithms? What heuristics do you use?
What different approaches do you try? How can you improve your skill set at designing algorithms?
What other questions do you ask yourself?
ColdFusion makes the list. So do Haskell, Delphi, and PowerBuilder.
I don't know that I disagree with the assessment based on the thought that "the vast majority of us all use the same dozen or so."
What do you think of the list? I was surprised to see those four languages included with some of the others, but at the same time you still have to ask, have they made it? And if they did make it, are they still there?
Posted by Sam on Jul 08, 2007 at 11:14 AM UTC - 5 hrs
I first read Chad Fowler's gem, My Job Went to India: 52 Ways to Save Your Job around this time last summer. Let me tell you, it was an awesome book (at least, it seriously changed the way I look at my career, and the way I've been managing it since then). It was a greatly inspiring book.
The reason I bring this up today is because despite the fact it was released a couple of years ago, its been making rounds through a couple of blogs lately. On top of that, I've wanted to write about it since reading it, and now seems like the perfect time.
More...
First, Pragmatic Dave asked for help in titling one of The Pragmatic Programmers' new books on accessibility. Why do they need help? He brought up Chad's book, and its unfortunate title. About it, he says,
Chad Fowler's first book with us is really, really good: a guide to managing and developing your career as a programmer. It was a joy to edit, and everyone who's read it loves it. But when it came time to give it a title, we were stumped. In the end, we decided to go for something a little jokey with some shock value...
The title didn't work. We sold a decent number of copies (just under 10,000), but we *should* have sold 3, 4, or 5 times that. It's a very, very good book. But I blew it for Chad by going with the wrong title.
Then Jay Fields seconded the motion, saying "I actually think reading this book is as important for your career as reading The Pragmatic Programmer is for your skills." I think so too. So important, in fact, I'm going to try to go through and do one chapter a week for the next 52 weeks. Of course, things I've already done from the book I probably won't go back and do again (but I may write about how I accomplished them), or things that require outside help where no one will help me ... but I imagine most of them will be doable.
Posted by Sam on Jun 26, 2007 at 09:09 AM UTC - 5 hrs
I ran into a couple of stumbling blocks today using a particular company's XML request API, and it made me wonder about the restrictions we put in our software that have no apparent reason.
My plan was simple: create a struct/hash/associative array that matches the structure of the XML document, run it through a 10-line or so function that translates that to XML, and send the data to the service provider. Simple enough - my code doesn't even need to know the structure - the programmer using it would provide that, and the service provider doubles as the validator! My code was almost the perfect code. It did almost nothing, and certainly nothing more than it was meant or needed to do.
But alas, it was not meant to be. Instead, the service provider has a couple of restrictions:
More...
The first was regarding case (as in upper/lower). The XML elements needed to have the same case as described in the documentation (which contained at least one element that wasn't in the real specification anyway). That's fine - I can live with that. But it annoyed me a little that they saw fit to use camelCase. (this is only a machine, after all. I don't think it cares if it can easily read the differentWordsAllBunchedUpTogether.)
At least if they had chosen all upper or all lower I can easily switch the case of my own, but requiring camelCase made my code quite a bit nastier than it needed to be. Now, I have to provide a lookup mechanism for each element in the XML. Of course, if the language I was using was case sensitive, this wouldn't be a big deal at all. However, even though it is not sensitive to case, this is still not that bad of an issue.
But then restriction number two comes along: all elements must be sent in the order they appear in the specification. We're just passing data around here. The XML describes the data in the first place, so what use is ordering it? I understand that parent/child relationships must remain intact, but I cannot see how there could possibly be a good reason that the "firstName" element should come before the "lastName" element. (Can you? I'd love to know!) Why don't we just go to a flat file and forget about the angled brackets altogether?
I might as well have just hard-coded the XML and had a variable for every element/attribute!
Posted by Sam on Jun 25, 2007 at 05:36 PM UTC - 5 hrs
A phrase that Venkat likes to use sums up my view on software religions: "There are no best practices. Only better practices." That's a powerful thought on its own, but if you want to make it a little more clear, I might say "There are no best practices. Only better practices in particular contexts." This concept tinges my everyday thinking.
The quote that got me was right at the beginning: someone "suggested that he'd like to ban the use of the term, 'Best Practices,' given that it's become something of a convenient excuse that IT professionals use to excuse every insane practice under the sun, regardless of its logical suitability to the business or environment." I would have added, "or its illogical absurdity given the business or environment."
Certainly, it is nice to have shortcuts that allow you to easily make decisions without thinking too long about them. Likewise, it's good to know the different options available to you.
"Best practices" is too much of a shortcut. If something is a "best practice," it implies there is no better practice available. All investigation for better solutions and thought about room for improvement ceases to exist. If something is a "best practice" and it is getting in your way, you have to follow it. It is the best, after all, and you wouldn't want to implement a sub-par solution when a better one exists, would you?
On the other hand, "better practices in specific contexts" gives you shortcuts, but it still allows you to think about something better. If I'm having trouble implementing what I thought was the preferred solution, perhaps it is time to investigate another solution. Am I really in the same context as the "practice" was intended for? It keeps things in perspective, without giving you the opportunity to be lazy about your decision-making process.
So my best practice for making decisions is recognition that there is no best practice. That's sort of like how I know more than you because I recognize I know nothing. So try hard not to fall into the trap that is "best practice." Avoid idolatry and sacred cows in software development. Aside from programming an application for a religious domain, there's just not much use for worship in programming. There's certainly no room for worshiping particular ways of doing software.
Posted by Sam on Jun 25, 2007 at 05:35 PM UTC - 5 hrs
There is a seemingly never-ending debate (or perhaps unconnected conversation and misunderstandings) on whether or not the software profession is science or art, or specifically whether "doing software" is in fact an engineering discipline.
Being the pragmatist (not a flip-flopper!) I aspire to be, and avoiding hard-and-fast deterministic rules on what exactly is software development, I have to say: it's both. There is a science element, and there is an artistic element. I don't see it as a zero-sum game, and its certainly not worthy of idolatry. (Is anything?)
More...
That said, I have to admit that lately I've started to give more weight to the "artistic" side than I previously had. There are just so many "it depends" answers to software development, that it seems like an art. But how many of the "it depends"-es are really subjective? Or, is art even subjective in the first place? Then today I remembered reading something long ago in a land far far away: that the prefix every engineer uses when answering a question is "it depends."
I think almost certainly there is much more science and engineering involved in what we do than art. But, I think there is a sizable artistic element as well. Otherwise we wouldn't use terms like "hacked a solution" (as if hacking through a jungle, not so much the positive connotation of hackers hacking), or "elegant code" or "elegant design." Much of design, while rooted in principles (hopefully, anyway), can be viewed as artistic as well.
The land far away and the time long ago involved myself as an Electrical Engineering in training. I dropped out of that after couple of years, so I don't have the full background, but most of what we were learning were the laws governing electrical circuits, physics, magnetism, and so on (I guess it's really all physics when you get right down to it). Something like that would lead you to believe that if we call this software engineering, we should have similar laws. It's not clear on the surface that we do.
But Steve McConnell posted a good rundown the other day about why the phrase "Writing and maintaining software are not engineering activities. So it's not clear why we call software development software engineering" misses the point completely.
In particular, we can treat software development as engineering - we've been doing so for quite some time. Clearly, "engineering" has won the battle. Instead, Steve lists many different questions that may be valuable to answer, and also describes many of the ways in which software development does parallel engineering.
So what do you think? In what ways is software development like engineering? In what ways is it like art?
Most of it is pretty solid, but two of the ten stuck out at me. First, the advice not to "make sure your team shares a common coding standard." Kristian uses a couple of three line functions to illustrate that both are easily read:
More...
Of course, just about any three-line method will be easy to read. And given that we strive to keep methods short, do we really need coding standards for a team?
I think they are still valuable. Perhaps it is true that in short methods we can read and understand just about anything (minus the golfing). But if you have some methods named in camelCase, some under_scored, or even SoMeMiXedCasE, it becomes difficult to remember the method name when you are using it in another file. Another issue arises with mixins or long files, if you don't have a convention it forces you to remember more than is necessary just to use a variable or method.
Of course, a good IDE (with a suitable language) can help with these, but it is still an issue or annoyance, and that presupposes you've got support for intellisense in the first place.
The second one stuck out at me because I strongly agree with it: You don't need to "write lots of comments." In my view, comments generally clutter the code and make it harder to follow (if you've got useful names for identifiers). I know it's largely a matter of preference, but Jef Raskin over at ACM Queue supports a documentation-first style of development (thanks to Reg for this one too), saying "That we use escape characters to 'escape' from code to comment is backwards. Ideally, comment should be the default, with a way to signal the occasional lines of code."
The best argument made in the article in favor of this (in my opinion, of course) is that "good documentation includes background and decision information that cannot be derived from the code." It is true that design decisions should be documented, but unless it is more complex than the simplest thing that could possibly work, there's no need to document it. And the fact is, most code is glaringly straightforward. In any case, there is certainly no need to have that sort of comment of the obvious littering the code and taking your eyes off of what is actually doing the work.
Just my two cents on a couple of issues. What do you think?

 By most standards, that's young.
By most standards, that's young.
 In the field of bioinformatics, one way to measure similarities between two (or more) sequences of
DNA is to perform
In the field of bioinformatics, one way to measure similarities between two (or more) sequences of
DNA is to perform 




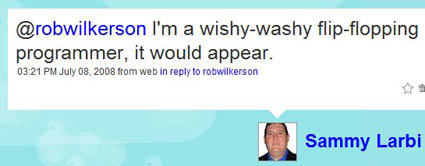

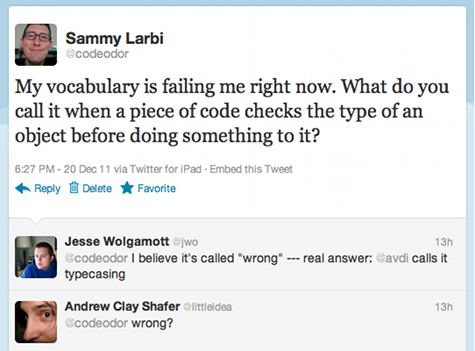
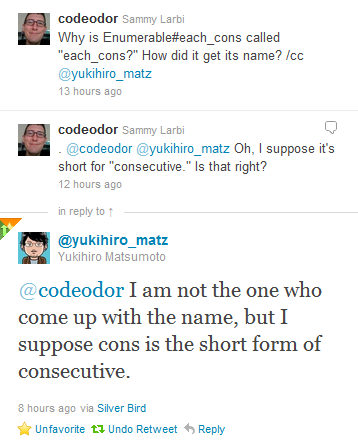

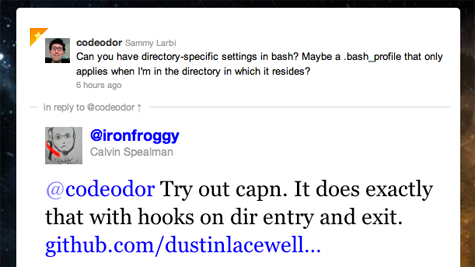
































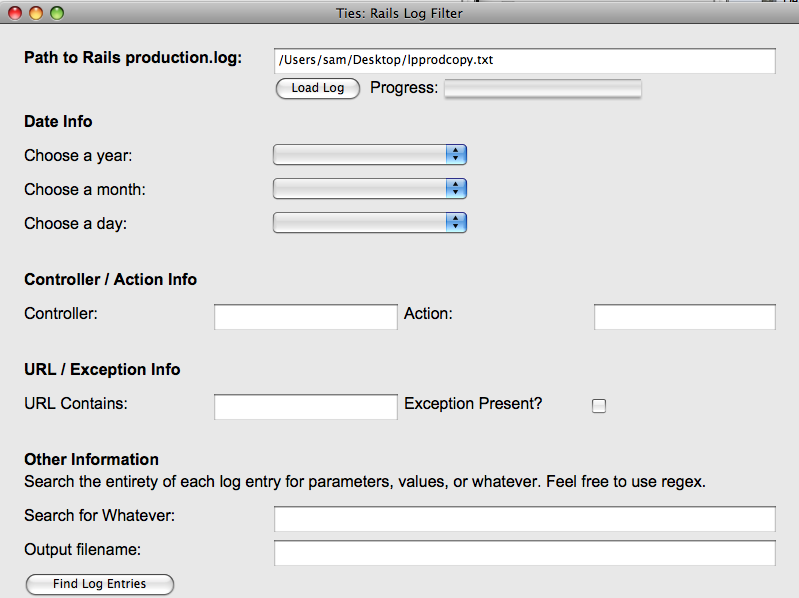

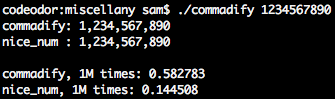
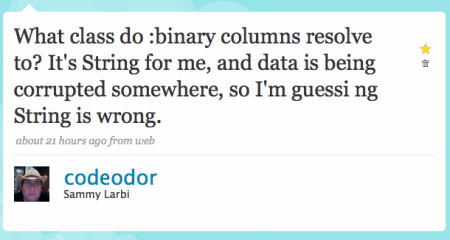

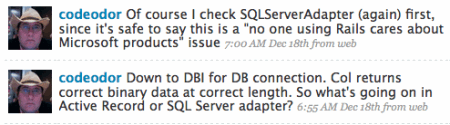






























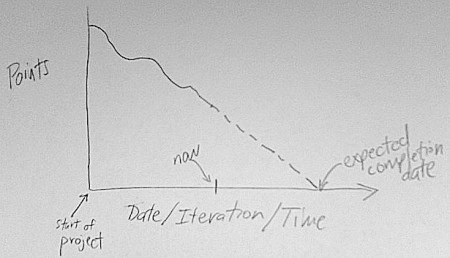





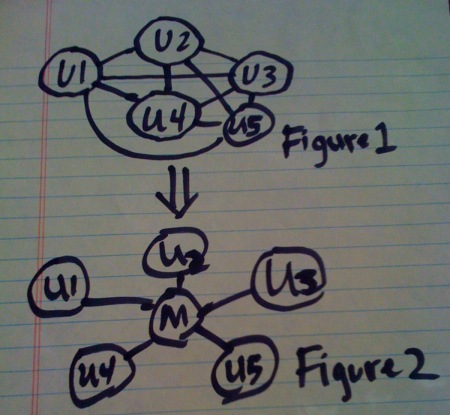




 At the start of a project, we sit down with client and take requirements. There's nothing fancy here.
I'm the coder and I get involved - we've found that it's a ridiculous waste of time to pass
my questions through a mediator and wait two weeks to get an answer. Instead, we take some paper or
cards and pen, and dry erase markers for the whiteboard. We talk through of what the system should do at a high level,
and make notes of it.
At the start of a project, we sit down with client and take requirements. There's nothing fancy here.
I'm the coder and I get involved - we've found that it's a ridiculous waste of time to pass
my questions through a mediator and wait two weeks to get an answer. Instead, we take some paper or
cards and pen, and dry erase markers for the whiteboard. We talk through of what the system should do at a high level,
and make notes of it.
 The Contest
The Contest
 It was around the time games started looking better and being more complicated than
It was around the time games started looking better and being more complicated than
 I spent a lot of time rummaging through the QBasic source code of
I spent a lot of time rummaging through the QBasic source code of 


{kind=link}
{kind=link}