Posted by Sam on Jan 14, 2008 at 06:42 AM UTC - 5 hrs
This is a story about my journey as a programmer, the major highs and lows I've had along the way, and
how this post came to be. It's not about how ecstasy made me a better programmer, so I apologize if that's why you came.
In any case, we'll start at the end, jump to
the beginning, and move along back to today. It's long, but I hope the read is as rewarding as the write.
A while back,
Reg Braithwaite
challenged programing bloggers with three posts he'd love to read (and one that he wouldn't). I loved
the idea so much that I've been thinking about all my experiences as a programmer off and on for the
last several months, trying to find the links between what I learned from certain languages that made
me a better programmer in others, and how they made me better overall. That's how this post came to be.
More...
The experiences discussed herein were valuable in their own right, but the challenge itself is rewarding
as well. How often do we pause to reflect on what we've learned, and more importantly, how it has changed
us? Because of that, I recommend you perform the exercise as well.
I freely admit that some of this isn't necessarily caused by my experiences with the language alone - but
instead shaped by the languages and my experiences surrounding the times.
One last bit of administrata: Some of these memories are over a decade old, and therefore may bleed together
and/or be unfactual. Please forgive the minor errors due to memory loss.
How QBASIC Made Me A Programmer
As I've said before, from the time I was very young, I had an interest in making games.
I was enamored with my Atari 2600, and then later the NES.
I also enjoyed a playground game with Donald Duck
and Spelunker.
Before I was 10, I had a notepad with designs for my as-yet-unreleased blockbuster of a side-scrolling game that would run on
my very own Super Sanola game console (I had the shell designed, not the electronics).
It was that intense interest in how to make a game that led me to inspect some of the source code Microsoft
provided with QBASIC. After learning PRINT, INPUT,
IF..THEN, and GOTO (and of course SomeLabel: to go to)
I was ready to take a shot at my first text-based adventure game.
The game wasn't all that big - consisting of a few rooms, the NEWS
directions, swinging of a sword against a few monsters, and keeping track of treasure and stats for everything -
but it was a complete mess.
The experience with QBASIC taught me that, for any given program of sufficient complexity, you really only
need three to four language constructs:
- Input
- Output
- Conditional statements
- Control structures
Even the control structures may not be necessary there. Why? Suppose you know a set of operations will
be performed an unknown but arbitrary amount of times. Suppose also that it will
be performed less than X number of times, where X is a known quantity smaller than infinity. Then you
can simply write out X number of conditionals to cover all the cases. Not efficient, but not a requirement
either.
Unfortunately, that experience and its lesson stuck with me for a while. (Hence, the title of this weblog.)
Side Note: The number of language constructs I mentioned that are necessary is not from a scientific
source - just from the top of my head at the time I wrote it. If I'm wrong on the amount (be it too high or too low), I always appreciate corrections in the comments.
What ANSI Art taught me about programming
When I started making ANSI art, I was unaware
of TheDraw. Instead, I opened up those .ans files I
enjoyed looking at so much in MS-DOS Editor to
see how it was done. A bunch of escape codes and blocks
came together to produce a thing of visual beauty.

Since all I knew about were the escape codes and the blocks (alt-177, 178, 219-223 mostly), naturally
I used the MS-DOS Editor to create my own art. The limitations of the medium were
strangling, but that was what made it fun.
And I'm sure you can imagine the pain - worse than programming in an assembly language (at least for relatively
small programs).
Nevertheless, the experience taught me some valuable lessons:
- Even though we value people over tools, don't underestimate
the value of a good tool. In fact, when attempting anything new to you, see if there's a tool that can
help you. Back then, I was on local BBSs, and not
the 1337 ones when I first started out. Now, the Internet is ubiquitous. We don't have an excuse anymore.
-
I can now navigate through really bad code (and code that is limited by the language)
a bit easier than I might otherwise have been able to do. I might have to do some experimenting to see what the symbols mean,
but I imagine everyone would.
And to be fair, I'm sure years of personally producing such crapcode also has
something to do with my navigation abilities.
-
Perhaps most importantly, it taught me the value of working in small chunks and
taking baby steps.
When you can't see the result of what you're doing, you've got to constantly check the results
of the latest change, and most software systems are like that. Moreover, when you encounter
something unexpected, an effective approach is to isolate the problem by isolating the
code. In doing so, you can reproduce the problem and problem area, making the fix much
easier.
The Middle Years (included for completeness' sake)
The middle years included exposure to Turbo Pascal,
MASM, C, and C++, and some small experiences in other places as well. Although I learned many lessons,
there are far too many to list here, and most are so small as to not be significant on their own.
Therefore, they are uninteresting for the purposes of this post.
However, there were two lessons I learned from this time (but not during) that are significant:
-
Learn to compile your own $&*@%# programs
(or, learn to fish instead of asking for them).
-
Stop being an arrogant know-it-all prick and admit you know nothing.
As you can tell, I was quite the cowboy coding young buck. I've tried to change that in recent years.
How ColdFusion made me a better programmer when I use Java
Although I've written a ton of bad code in ColdFusion, I've also written a couple of good lines
here and there. I came into ColdFusion with the experiences I've related above this, and my early times
with it definitely illustrate that fact. I cared nothing for small files, knew nothing of abstraction,
and horrendous god-files were created as a result.
If you're a fan of Italian food, looking through my code would make your mouth water.
DRY principle?
Forget about it. I still thought code reuse meant copy and paste.
Still, ColdFusion taught me one important aspect that got me started on the path to
Object Oriented Enlightenment:
Database access shouldn't require several lines of boilerplate code to execute one line of SQL.
Because of my experience with ColdFusion, I wrote my first reusable class in Java that took the boilerplating away, let me instantiate a single object,
and use it for queries.
How Java taught me to write better programs in Ruby, C#, CF and others
It was around the time I started using Java quite a bit that I discovered Uncle Bob's Principles of OOD,
so much of the improvement here is only indirectly related to Java.
Sure, I had heard about object oriented programming, but either I shrugged it off ("who needs that?") or
didn't "get" it (or more likely, a combination of both).
Whatever it was, it took a couple of years of revisiting my own crapcode in ColdFusion and Java as a "professional"
to tip me over the edge. I had to find a better way: Grad school here I come!
The better way was to find a new career. I was going to enter as a Political Scientist
and drop programming altogether. I had seemingly lost all passion for the subject.
Fortunately for me now, the political science department wasn't accepting Spring entrance, so I decide to
at least get started in computer science. Even more luckily, that first semester
Venkat introduced me to the solution to many my problems,
and got me excited about programming again.
I was using Java fairly heavily during all this time, so learning the principles behind OO in depth and
in Java allowed me to extrapolate that for use in other languages.
I focused on principles, not recipes.
On top of it all, Java taught me about unit testing with
JUnit. Now, the first thing I look for when evaluating a language
is a unit testing framework.
What Ruby taught me that the others didn't
My experience with Ruby over the last year or so has been invaluable. In particular, there are four
lessons I've taken (or am in the process of taking):
-
The importance of code as data, or higher-order functions, or first-order functions, or blocks or
closures: After learning how to appropriately use
yield, I really miss it when I'm
using a language where it's lacking.
-
There is value in viewing programming as the construction of lanugages, and DSLs are useful
tools to have in your toolbox.
-
Metaprogramming is OK. Before Ruby, I used metaprogramming very sparingly. Part of that is because
I didn't understand it, and the other part is I didn't take the time to understand it because I
had heard how slow it can make your programs.
Needless to say, after seeing it in action in Ruby, I started using those features more extensively
everywhere else. After seeing Rails, I very rarely write queries in ColdFusion - instead, I've
got a component that takes care of it for me.
-
Because of my interests in Java and Ruby, I've recently started browsing JRuby's source code
and issue tracker.
I'm not yet able to put into words what I'm learning, but that time will come with
some more experience. In any case, I can't imagine that I'll learn nothing from the likes of
Charlie Nutter, Ola Bini,
Thomas Enebo, and others. Can you?
What's next?
Missing from my experience has been a functional language. Sure, I had a tiny bit of Lisp in college, but
not enough to say I got anything out of it. So this year, I'm going to do something useful and not useful
in Erlang. Perhaps next I'll go for Lisp. We'll see where time takes me after that.
That's been my journey. What's yours been like?
Now that I've written that post, I have a request for a post I'd like to see:
What have you learned from a non-programming-related discipline that's made you a better programmer?
Hey! Why don't you make your life easier and subscribe to the full post
or short blurb RSS feed? I'm so confident you'll love my smelly pasta plate
wisdom that I'm offering a no-strings-attached, lifetime money back guarantee!
Last modified on Jan 16, 2008 at 07:09 AM UTC - 5 hrs
Posted by Sam on Sep 10, 2007 at 12:48 PM UTC - 5 hrs
If you don't care about the background behind this, the reasons why you might want to use
rules based programming, or a bit of theory, you can skip straight the Drools tutorial.
Background
One of the concepts I love to think about (and do) is raising the level of abstraction in a system.
The more often you are telling the computer what, and not how, the better.
Of course, somewhere someone is doing imperative programming (telling it how), but I like to
try to hide much of that somewhere and focus more on declarative programming (telling it what). Many
times, that's the result of abstraction in general and DSLs
and rules-based programming more specifically.
More...
As a side note, let me say that this is not necessarily a zero-sum game. In one aspect you may be declaratively
programming while in another you are doing so imperatively. Example:
function constructARecord()
{
this.name=readFileLineNumber(fileName, 1);
this.phone=readFileLineNumber(fileName, 2);
this.address=readFileLineNumber(fileName, 3);
}
You are telling it how to construct a record, but you are not telling it how to read the file. Instead,
you are just telling it to read the file.
Anyway, enough of that diversion. I hope I've convinced you.
When I finished writing the (half-working) partial order planner in Ruby,
I mentioned I might like "to take actions as functions, which receive preconditions as their parameters,
and whose output are effects" (let me give a special thanks to Hugh Sasse for his help and ideas in trying to use TSort for it while I'm
on the subject).
Doing so may have worked well when generalizing the solution to a rules engine instead of just a planner (they are conceptually
quite similar). That's
often intrigued me from both a business application and game programming standpoint.
The good news is (as you probably already know), this has already been done for us. That was the
subject of Venkat's talk that I attended at No Fluff Just Stuff at the end of June 2007.
Why use rules-based programming?
After a quick introduction, Venkat jumped right into why you might want to use a rules engine.
The most prominent reasons all revolve around the benefits provided by separating concerns:
When business rules change almost daily, changes to source code can be costly. Separation of knowledge
from implementation reduces this cost by having no requirement to change the source code.
Additionally, instead of providing long chains of if...else statements, using a rule engine
allows you the benefits of declarative programming.
A bit of theory
The three most important aspects for specifying the system are facts, patterns, and the rules themselves.
It's hard to describe in a couple of sentences, but your intuition should serve you well - I don't think
you need to know all of the theory to understand a rule-based system.
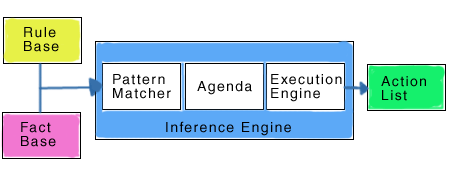
Rules Engine based on Venkat's notes
Facts are just bits of information that can be used to make decisions. Patterns are similar, but can
contain variables that allow them to be expanded into other patterns or facts. Finally, rules have
predicates/premises that if met by the facts will fire the rule which allows the action to be
performed (or conclusion to be made).
(Another side note: See JSR 94 for a Java spec for Rules Engines
or this google query for some theory.
Norvig's and Russell's Artificial Intelligence: A Modern Approach
also has good explanations, and is a good introduction to AI in general (though being a textbook, it's pricey at > $90 US)).
(Yet another side note: the computational complexity of this pattern matching can be enormous, but the
Rete Algorithm will help, so don't
prematurely optimize your rules.)
Drools
Now that we know a bit of the theory behind rules-based systems, let's get into the practical to show
how easy it can be (and aid in removing fear of new technology to become a generalist).
First, you can get Drools 2.5 at Codehaus or
version 3, 4 or better from JBoss.
At the time of writing, the original Drools lets you use XML with Java or Groovy, Python, or Drools' own
DSL to implement rules, while the JBoss version (I believe) is (still) limited to Java or the DSL.
Since I avoid XML like the plague (well, not that bad),
I'll go the DSL route.
First, you'll need to download Drools and unzip it to a place you keep external Java libraries.
I'm working with Drools 4.0.1. After that, I created a new Java project in Eclipse and added a new user
library for Drools, then added that to my build path (I used all of the Drools JARs in the library).
(And don't forget JUnit if you don't have it come up automatically!)
Errors you might need to fix
For reference for anyone who might run across the problems I did, I'm going to include a few of the
errors I came into contact with and how I resolved them. I was starting with a pre-done example, but
I will show the process used to create it after trudging through the errors. Feel free to
skip this section if you're not having problems.
After trying the minimal additions to the build path I mentioned above, I was seeing an error
that javax.rules was not being recognized. I added
jsr94-1.1.jar to my Drools library (this is included under /lib in the Drools download) and it was
finally able to compile.
When running the unit tests, however, I still got this error:
org.drools.RuntimeDroolsException: Unable to load dialect 'org.drools.rule.builder.dialect.java.JavaDialectConfiguration:java'
At that point I just decided to add all the dependencies in /lib to my Drools library and the error
went away. Obviously you don't need Ant, but I wasn't quite in the mood to go hunting for the minimum
of what I needed. You might feel differently, however.
Now that the dialect was able to be loaded, I got another error:
org.drools.rule.InvalidRulePackage: Rule Compilation error : [Rule name=Some Rule Name, agendaGroup=MAIN, salience=-1, no-loop=false]
com/codeodor/Rule_Some_Rule_Name_0.java (8:349) : Cannot invoke intValue() on the primitive type int
As you might expect, this was happening simply because the rule was receiving an int and was
trying to call a method from Integer on it.
After all that, my pre-made example ran correctly, and being comfortable that I had Drools working,
I was ready to try my own.
An Example: Getting a Home Loan
From where I sit, the process of determining how and when to give a home loan is complex and can change
quite often. You need to consider an applicant's credit score, income, and down payment, among
other things. Therefore, I think it is a good candidate for use with Drools.
To keep the tutorial simple
(and short), our loan determinizer will only consider credit score and down payment in regards to the
cost of the house.
First we'll define the HomeBuyer class. I don't feel the need for tests, because as you'll
see, it does next to nothing.
package com.codeodor;
public class HomeBuyer {
int _creditScore;
int _downPayment;
String _name;
public HomeBuyer(String buyerName, int creditScore, int downPayment) {
_name = buyerName;
_creditScore = creditScore;
_downPayment = downPayment;
}
public String getName() {
return _name;
}
public int getCreditScore(){
return _creditScore;
}
public int getDownPayment(){
return _downPayment;
}
}
Next, we'll need a class that sets up and runs the rules. I'm not feeling
the need to test this directly either, because it is 99% boilerplate and all of the code
gets tested when we test the rules anyway. Here is our LoanDeterminizer:
package com.codeodor;
import org.drools.jsr94.rules.RuleServiceProviderImpl;
import javax.rules.RuleServiceProviderManager;
import javax.rules.RuleServiceProvider;
import javax.rules.StatelessRuleSession;
import javax.rules.RuleRuntime;
import javax.rules.admin.RuleAdministrator;
import javax.rules.admin.LocalRuleExecutionSetProvider;
import javax.rules.admin.RuleExecutionSet;
import java.io.InputStream;
import java.util.ArrayList;
public class LoanDeterminizer {
// the meat of our class
private boolean _okToGiveLoan;
private HomeBuyer _homeBuyer;
private int _costOfHome;
public boolean giveLoan(HomeBuyer h, int costOfHome) {
_okToGiveLoan = true;
_homeBuyer = h;
_costOfHome = costOfHome;
ArrayList<Object> objectList = new ArrayList<Object>();
objectList.add(h);
objectList.add(costOfHome);
objectList.add(this);
return _okToGiveLoan;
}
public HomeBuyer getHomeBuyer() { return _homeBuyer; }
public int getCostOfHome() { return _costOfHome; }
public boolean getOkToGiveLoan() { return _okToGiveLoan; }
public double getPercentDown() { return(double)(_homeBuyer.getDownPayment()/_costOfHome); }
// semi boiler plate (values or names change based on name)
private final String RULE_URI = "LoanRules.drl"; // this is the file name our Rules are contained in
public LoanDeterminizer() throws Exception // the constructor name obviously changes based on class name
{
prepare();
}
// complete boiler plate code from Venkat's presentation examples follows
// I imagine some of this changes based on how you want to use Drools
private final String RULE_SERVICE_PROVIDER = "http://drools.org/";
private StatelessRuleSession _statelessRuleSession;
private RuleAdministrator _ruleAdministrator;
private boolean _clean = false;
protected void finalize() throws Throwable
{
if (!_clean) { cleanUp(); }
}
private void prepare() throws Exception
{
RuleServiceProviderManager.registerRuleServiceProvider(
RULE_SERVICE_PROVIDER, RuleServiceProviderImpl.class );
RuleServiceProvider ruleServiceProvider =
RuleServiceProviderManager.getRuleServiceProvider(RULE_SERVICE_PROVIDER);
_ruleAdministrator = ruleServiceProvider.getRuleAdministrator( );
LocalRuleExecutionSetProvider ruleSetProvider =
_ruleAdministrator.getLocalRuleExecutionSetProvider(null);
InputStream rules = Exchange.class.getResourceAsStream(RULE_URI);
RuleExecutionSet ruleExecutionSet =
ruleSetProvider.createRuleExecutionSet(rules, null);
_ruleAdministrator.registerRuleExecutionSet(RULE_URI, ruleExecutionSet, null);
RuleRuntime ruleRuntime = ruleServiceProvider.getRuleRuntime();
_statelessRuleSession =
(StatelessRuleSession) ruleRuntime.createRuleSession(
RULE_URI, null, RuleRuntime.STATELESS_SESSION_TYPE );
}
public void cleanUp() throws Exception
{
_clean = true;
_statelessRuleSession.release( );
_ruleAdministrator.deregisterRuleExecutionSet(RULE_URI, null);
}
}
I told you there was a lot of boilerplate code there. I won't explain it all because:
- It doesn't interest me
- I don't yet know as much as I should about it
I fully grant that reason number one may be partially or completely dependent on the second one.
In any case, now we can finally write our rules. I'll be starting with a test:
package com.codeodor;
import junit.framework.TestCase;
public class TestRules extends TestCase {
public void test_poor_credit_rating_gets_no_loan() throws Exception
{
LoanDeterminizer ld = new LoanDeterminizer();
HomeBuyer h = new HomeBuyer("Ima Inalotadebt and Idun Payet", 100, 20000);
boolean result = ld.giveLoan(h, 150000);
assertFalse(result);
ld.cleanUp();
}
}
And our test fails, which is what we wanted. We didn't yet create our rule file, LoanRules.drl, so
let's do that now.
package com.codeodor
rule "Poor credit score never gets a loan"
salience 2
when
buyer : HomeBuyer(creditScore < 400)
loan_determinizer : LoanDeterminizer(homeBuyer == buyer)
then
System.out.println(buyer.getName() + " has too low a credit rating to get the loan.");
loan_determinizer.setOkToGiveLoan(false);
end
The string following "rule" is the rule's name. Salience is one of the ways Drools performs conflict resolution.
Finally, the first two lines tell it that buyer is a variable of type HomeBuyer with a credit score of less than 400
and loan_determinizer is the LoanDeterminizer passed in with the object list
where the homeBuyer is what we've called buyer in our rule. If either of
those conditions fails to match, this rule is skipped.
Hopefully that
makes some sense to you. If not, let me know in the comments and I'll try again.
And now back to
our regularly scheduled test:
running it again still results in a red bar. This time, the problem is:
org.drools.rule.InvalidRulePackage: Rule Compilation error : [Rule name=Poor credit score never gets a loan, agendaGroup=MAIN, salience=2, no-loop=false]
com/codeodor/Rule_Poor_credit_score_never_gets_a_loan_0.java (7:538) : The method setOkToGiveLoan(boolean) is undefined for the type LoanDeterminizer
The key part here is "the method setOkToGiveLoan(boolean) is undefined for the type LoanDeterminizer."
Oops, we forgot that one. So let's add it to LoanDeterminizer:
public void setOkToGiveLoan(boolean value) { _okToGiveLoan = value; }
Now running the test results in yet another red bar! It turns out I forgot something pretty big (and basic) in
LoanDeterminizer.giveLoan(): I didn't tell it to execute the rules. Therefore, the default
case of "true" was the result since the rules were not executed.
Asking it to execute the rules is as
easy as this one-liner, which passes it some working data:
_statelessRuleSession.executeRules(objectList);
For reference, the entire working giveLoan method is below:
public boolean giveLoan(HomeBuyer h, int costOfHome) throws Exception {
_okToGiveLoan = true;
_homeBuyer = h;
_costOfHome = costOfHome;
ArrayList<Object> objectList = new ArrayList<Object>();
objectList.add(h);
objectList.add(costOfHome);
objectList.add(this);
_statelessRuleSession.executeRules(objectList);
// here you might have some code to process
// the loan if _okToGiveLoan is true
return _okToGiveLoan;
}
Now our test bar is green and we can add more tests and rules. Thankfully, we're done with programming
in Java (except for our unit tests, which I don't mind all that much).
To wrap-up the tutorial I want to focus on two more cases: Good credit score always gets the loan and
medium credit score with small down payment does not get the loan. I wrote the tests and rules
iteratively, but I'm going to combine them here for organization's sake seeing as I already demonstrated
the iterative approach.
public void test_good_credit_rating_gets_the_loan() throws Exception {
LoanDeterminizer ld = new LoanDeterminizer();
HomeBuyer h = new HomeBuyer("Warren Buffet", 800, 0);
boolean result = ld.giveLoan(h, 100000000);
assertTrue(result);
// maybe some more asserts if you performed processing in LoanDeterminizer.giveLoan()
ld.cleanUp();
}
public void test_mid_credit_rating_gets_no_loan_with_small_downpayment() throws Exception {
LoanDeterminizer ld = new LoanDeterminizer();
HomeBuyer h = new HomeBuyer("Joe Middleclass", 500, 5000);
boolean result = ld.giveLoan(h, 150000);
assertFalse(result);
ld.cleanUp();
}
And the associated rules added to LoanRules.drl:
rule "High credit score always gets a loan"
salience 1
when
buyer : HomeBuyer(creditScore >= 700)
loan_determinizer : LoanDeterminizer(homeBuyer == buyer)
then
System.out.println(buyer.getName() + " has a credit rating to get the loan no matter the down payment.");
loan_determinizer.setOkToGiveLoan(true);
end
rule "Middle credit score fails to get a loan with small down payment"
salience 0
when
buyer : HomeBuyer(creditScore >= 400 && creditScore < 700)
loan_determinizer : LoanDeterminizer(homeBuyer == buyer && percentDown < 0.20)
then
System.out.println(buyer.getName() + " has a credit rating to get the loan but not enough down payment.");
loan_determinizer.setOkToGiveLoan(false);
end
As you can see, there is a little bit of magic going on behind the scenes (as you'll also find in Groovy) where
here in the DSL, you can call loan_determinizer.percentDown and it will call getPercentDown
for you.
All three of our tests are running green and the console outputs what we expected:
Ima Inalotadebt and Idun Payet has too low a credit rating to get the loan.
Warren Buffet has a credit rating to get the loan no matter the down payment.
Joe Middleclass has a credit rating to get the loan but not enough down payment.
As always, questions, comments, and criticism are welcome. Leave your thoughts below. (I know it was
the length of a book, so I don't expect many.)
For more on using Drools, see the Drools 4 docs.
Finally, as with my write-ups on
Scott Davis's Groovy presentation,
his keynote,
Stuart Halloway's JavaScript for Ajax Programmers,
and Neal Ford's 10 ways to improve your code,
I have to give Venkat most of the credit for the good stuff here.
I'm just reporting from my notes, his slides,
and my memory, so any mistakes you find are probably mine. If they aren't, they likely should have been.
Last modified on Sep 10, 2007 at 05:46 PM UTC - 5 hrs
Posted by Sam on Aug 02, 2007 at 11:15 AM UTC - 5 hrs
A couple of evenings ago, after I wrote about how I got involved in programming and helped a friend with some C++ (he's a historian), I got inspired to start writing a scripting engine for a text-based adventure game. Maybe it will evolve into something, but I wanted to share it in its infancy right now.
My goal was to easily create different types of objects in the game without needing to know much about programming. In other words, I needed a declarative way to create objects in the game. I could just go the easy route and create new types of weapons like this:
More...
short_sword = create_weapon(name="short sword", size="small", description="shiny and metallic with a black leather hilt", damage="1d6+1", quantity_in_game=10, actions="swing, stab, thrust, parry")
But that's not much fun. So I started thinking about how I'd like to let the game system know about new types of weapons. A DSL, perhaps. Eventually, I settled on this syntax:
short_sword =
create_small_shiny_and_metallic_with_a_black_leather_hilt_weapon.
named "Short Sword" do
damage_of 1.d6 + 1
with_actions :swing, :stab, :thrust, :parry
and_there_are 10.in_the_world
end
Then, when you do the following print-outs
puts "Name: " + short_sword.name
puts "Size: " + short_sword.size
puts "Description: " + short_sword.description
puts "Damage: " + short_sword.damage.to_s
puts "Actions: " + short_sword.actions.inspect
puts "Quantity in game: " + short_sword.quantity_existing.to_s
You should end up with output like this:
Name: Short Sword
Size: small
Description: shiny and metallic with a black leather hilt
Damage: 1d6 + 1
Actions: [:swing, :stab, :thrust, :parry]
Quantity in game: 10
We could create just about any game object like that, but I've yet to do so, and I don't think
adding it here would do much of anything besides add to the length of the post.
Ideally, I'd want to remove some of those dots and just keep spaces between the words, but then Ruby
wouldn't know which arguments belonged to which methods. I could use a preprocessor that would allow
me to use spaces only and put dots in the appropriate places, but that would needlessly complicate things
for right now. I'll consider it later.
The first thing I noticed about the syntax I wanted was that the Integer class would
need some changes. In particular, the methods in_the_world and d6
(along with other dice methods) would need to be added:
class Integer
def in_the_world
self
end
def d6
DieRoll.new(self, 6)
end
end
The method in_the_world doesn't really need to do anything aside from return the object it
is called upon, so that the number can be a parameter to and_there_are. In fact, we
could do away with it, but I think its presence adds to the readability. If we kept it at
and_there_are 10, the code wouldn't make much sense.
On top of that, we might decide that
other methods like in_the_room or in_the_air should be added. At that point
we could have each return some other object that and_there_are could use to determine
where the objects are. Upon making that determination, it would place them in the game accordingly.
Then we see the d6 method. At first I tried the simple route using what was available and
had d6 return self + 0.6. Then, damage_of could figure it out from there.
However, aside from not liking that solution because of magic numbers, it wouldn't work for weapons with
bonuses or penalties (i.e., a weapon that does 1d6+1 points of damage). Therefore, we need to introduce
the DieRoll class:
class DieRoll
def initialize(dice, type)
@dice = dice
@type = type
@bonus = 0
end
def +(other)
@bonus = other
self
end
def to_s
droll = @dice.to_s + "d" + @type.to_s
droll += @bonus.to_s if @bonus < 0
droll += " + " + @bonus.to_s if @bonus > 0
droll
end
end
The initialize and to_s methods aren't anything special.
We see that initialize simply takes its arguments and sets up the DieRoll
while to_s just formats the output when we want to display a DieRoll
as a string. I'm not too thrilled about the name of the class, so if you've got something better,
please let me know!
The + method is the only real interesting bit here. It's what allows us to set the bonus
or penalty to the roll.
Finally, we'll need to define named, damage_of, with_actions,
and_there_are,
and create_small_shiny_..._with_a_black_leather_hilt_weapon. I've put them in a
module now for no other reason than to have easy packaging. I'd revisit
that decision if I were to do something more with this.
In any case, it turns out most these methods are just cleverly named setter functions,
with not much to them. The two notable exceptions are
create\w*weapon and named. You can see all of them below:
module IchabodScript
attr_reader :name, :damage, :actions, :quantity_existing, :size, :description
def named(name)
@name = name
yield
self
end
def damage_of(dmg)
@damage = dmg
end
def with_actions(*action_list)
@actions = action_list
end
def method_missing(method_id, *args)
create_weapon_methods = /create_(\w*)_weapon/
if method_id.to_s =~ create_weapon_methods
@description = method_id.to_s.gsub(create_weapon_methods, '\1')
@size = @description.split('_')[0]
@description.gsub!("_", " ")
@description.gsub!(@size,"")
else
raise method_id.to_s + " is not a valid method."
end
self
end
def and_there_are(num)
@quantity_existing = num
end
alias there_are and_there_are
end
Although it is slightly more than a setter, named is still a simple function. The only
thing it does besides set the name attribute is yield to a block that is passed to it.
That's the block we see in the original syntax beginning with do and ending (surprisingly)
with end.
The last thing is create_size_description_weapon. We use method_missing to
allow for any size and description, and check that the method matches our
regex /create_(\w*)_weapon/ before extracting that data. If it doesn't match, we just raise an
exception that tells us the requested method is not defined.
If I were to take this further, I would
also check if the method called matched one of the actions available for the weapon. If so, we'd
probably find a way to classify actions as offensive or defensive. We could then print something like
"You #{method_id.to_s} your sword for #{damage.roll} points of damage" (assuming we had a
roll method on DieRoll).
As always, any thoughts, questions, comments, and critcisms are appreciated. Just let me know below.
Posted by Sam on Jul 27, 2007 at 03:43 PM UTC - 5 hrs
We could all stand to be better at what we do - especially those of us who write software. Although
many of these ideas were not news to me, and may not be for you either, you'd be surprised at how
you start to slack off and what a memory refresh will do for you.
Here are (briefly)
10 ways to improve your code from the
NFJS
session I attended with Neal Ford.
Which do you follow?
More...
-
Know the fundamentals
It was no surprise that Neal led off with the DRY
principle. Being one from the school of thought that "code reuse" meant "copy-and-pastable with few changes," I
feel this is the most important principle to follow when coding.
Neal uses it in the original sense:
Refuse to repeat yourself not just in your code, but all throughout the system.
To quote (If I remember correctly, The Pragmatic Programmer): "Every piece of knowledge must have a single, unambiguous, authoritative representation within a system."
I can't think of anything that wouldn't be improved by following that advice.
Continuous integration and version control are important fundamentals as well. Continuous integration means you
know the code base at least compiles, and you can have it run your unit tests as well. The codebase is verified as always working
(at least to the specs as you wrote them - you might have gotten them wrong, of course).
Using version control means you don't have to be afraid of deleting that commented out code that you'll probably never use again but
you keep around anyway "just in case." That keeps your code clean.
Finally, Neal suggests we should use static analysis tools such as FindBugs
and PMD that inspect our code, look for bad patterns, and suggest fixes and
places to trim. Those two are for Java. Do you know of similar applications for other platforms? (Leave a comment please!)
-
Analyze code odors and remove them if they stink
Inheritance is a smell. It doesn't always have to smell bad, but at least you should take the time
to determine if what you really need is composition.
Likewise, the existence of helper or utility classes often indicates a "poor design." As
Neal notes, "if you've gotten the abstraction correct, why do you need 'helpers'?" Try to put
them in "intelligent domain object[s]" instead.
Static methods are an indication you are thinking procedurally, and they are "virtually impossible to test."
Seeing the procedural mindset is easy, I think, but why are they hard to test?
Finally, avoid singletons. I know Singleton is everyone's favorite design
pattern because it's so easy to conceptualize, but as Neal mentions:
- They're really just a poor excuse for global variables.
- They violate SRP (link is to a PDF file)
by mixing business logic with policing you from using too many
- They make themselves hard to test
- It's very hard to build a real singleton, as you have to ensure you are using a unified class loader.
- More that I won't get into here...
-
Kill Sacred Cows
Neal started off saying that "sacred cows make the tastiest hamburger" and told the story of the angry monkeys:
A few monkeys were put in a room with a stepladder and a banana that could only be reached if the
monkeys used the stepladder. However, when a monkey would climb upon the stepladder, all the
monkeys would be doused with water. Then new monkeys were introduced and when they
tried to use the stepladder, the other monkeys would get angry and beat him up. Eventually,
the room contained none who had been doused with water, but the monkeys who had been beat up for
using the stepladder were still refusing to allow new monkeys to get the banana.
That is the light in which you may often view sacred cows in software development. In particular,
Neal points out that
- StickingToCamelCaseForSentenceLongTestNamesIsRidiculous so_it_is_ok_to_use_underscores
in languages_that_standardized_on_camel_case for your test names.
-
Using getters and setters does not equate to encapsulation. One of my favorite sayings,
and a reference to why
they are evil is appropriate.
-
Avoidance of multiple returns in a method is antiquated because it comes from a time
when we weren't using tiny, cohesive methods. I still like to avoid them, but will
use them when it makes the code more readable.
-
Polluting interface names with "I", as in ISomeInterface should be avoided.
It is contrary to what interfaces are about. Instead, you should decorate the concrete
class name.
-
Your objects should be Good Citizens. Never let them exist in an invalid state.
-
Use Test Driven Development
TDD provides "explicit dependency management" because you must think about dependencies
as you code. It provides instant feedback and encourages you to implement the simplest
thing that works.
You can take it further by analyzing your dependencies with JDepend.
And don't forget about YAGNI. Quoting
Neal,
Speculative development saves time if
• You have nothing better to work on right now
• You guarantee that it won't take longer to fix later
Is that ever going to be true?
-
Use reflection when you can (and when it makes sense)
It's not slow, and it can be extremely useful!
-
Colour Your World
Nick Drew, a ThoughtWorker in the UK came up with a system of coloring the code you write
by classifying it as to who will use the feature: only a specific business customer,
only a particular market, many markets, or unchangeable infrastructure. Based on
the color and amount of it, you can decide what value or cost your code has.
It's a very interesting system, so I recommend seeing a more detailed overview in
Neal's handout (PDF).
You can find it on pages 21-22.
-
Use a DSL style of coding
It lets you "[Build] better abstraction layers, using language instead of trees" while
"utilizing" current building blocks. As he pointed out, "every complicated human endeavor
has its own DSL. [If you can] make the code closer to the DSL of the business [then] it is
better abstracted."
I'll add that it's easier to spot logical errors as well.
A funny quote from Neal: "It's almost as if in Java we're talking to a severely retarded person."
Regarding that, he recommended looking at EasyMock as a good
example of fluent interfaces, and that having setters return void in a waste.
Instead, we should return this so that calls can be chained together (and if
you are using fluent-interface type names, you could construct sentences in your DSL that way).
Neal also noted a distinction between an API and DSL: API has an explicit context that must
be repeated with each call. However, a DSL uses an implicit context.
-
SLAP tells us to keep
all lines of code in a method at the same level of abstraction.
Steve McConnell's Code Complete 2
tells us about this as well, but I don't recall if it had the clever acronym.
-
And finally, Think about Antiobjects.
Quoting Neal, "Antiobjects are the inverse of what we perceive to be the computational objects."
So instead of solving the really hard "foreground" problem, have a look at the "background"
problem (the inverse) to see if it is easier to solve.
As an example, he used PacMan:
Rather than constructing a solution for the "shortest route around the maze," the game has
a "notion of a PacMan 'scent'" for each tile." That way, the ghosts follow the strongest scent.
As with my write-ups on
Scott Davis's Groovy: Greasing the Wheels of Java,
and Stuart Halloway's JavaScript for Ajax Programmers,
Neal gets all the credit for the good stuff here. I'm just reporting from my notes, his mindmap,
and my memory, so any mistakes you find are probably mine. If they aren't, they probably should
have been.
So which strategies have you used? Will you start using any of the above?
Posted by Sam on Jun 19, 2007 at 12:19 PM UTC - 5 hrs
It's no big secret that I'm not a huge fan of XML. But, when I posted about Bob Martin's revolt against XML, it was half-jokingly. I use XML when I find it useful, and certainly I wouldn't go so far as to say (quoting Bob Martin)
What is the matter with these people? How, after all the experience we've had with XSLT, Ant, WSDL, etc., etc., could they create YET ANOTHER XML language. Are they dolts? Are they idiots?
But when Peter posted a comment asking "how quickly can you write a parser...," I revisited the post from Bob, and dug into it a little.
More...
I'm going to go out on a limb here and use something I learned in school (this doesn't happen often, at least not with the "theoretical" stuff). There are concise ways to describe languages and grammars, so one would think there exists a tool that can take that description and automatically parse some text for you. It sounds reasonable, anyway. In fact, checking up on it, that's what tools like ANTLR and YACC seem to do.
As far as rolling your own parser: if your language is very simple, you can easily write a parser using string.split(pattern) that would do the job. It's only when the language gets more complex that the parsing becomes difficult. In this case, Robert Martin mentioned that you should "write a little YACC grammar that is nice, and small, and translates into that hideous XML." Since I couldn't find a download for YACC, I decided to get ANTLR and give it a whirl.
I'll show a very simple dependency injection DSL that follows this basic rule: make bean: id, class, constructor-arg {name=value, name2=value2,...}. Obviously, when writing a real one you'd want to take some time to make it simpler for the user, which would lead to a more complex grammar than this. In any case, the code if you were to write it might look like:
make bean: samuel_adams, beer.SamAdams, constructor-arg {rating=6.1}
make bean: jack_daniels, liquor.whiskey.jd, constructor-arg {rating=8.1}
make bean: dp, champagne.domPerignon, constructor-arg {rating=9.5, year=1996}
First, lets define the tokens for the lexer. In ANTLR, these start with a capital letter, so we have:
MakeBean, BeanID, Class, TypeOfInjection, ArgName, and ArgValue. (I'll put it all together in legal ANTLR statements below)
Then, we'll want to define the rules for our parser. These start with lowercase letters. For this, we have statements, expressions, args and prog, our program. Statements consist of expressions followed by CRLF which may lead to another expression or the end. I added args in, which could have easily been put right into the statement if I had wanted.
Here's the code you'd use in ANTLR. So far, I see that it draws state machines for me, but I don't yet know how to feed it input and get output (however, I imagine that wouldn't be too difficult). I've tried to add comments to explain what I understand to be going on.
grammar expr;
options { // not sure what all can go here
output=AST;
ASTLabelType=CommonTree; // type of $stat.tree ref etc...
}
//not sure what all can go here
prog: ( statements {System.out.println($stat.tree.toStringTree());} )+ ;
statements: expression CRLF -> expression // expression followed by CRLF can lead to a new expression
| CRLF -> //or newline can lead to nothing (end of program)
;
expression:
MakeBean WS* ':' WS* BeanID WS* ',' WS* Class WS* ',' WS* TypeOfInjection WS* '{' WS* args WS* '}' WS*
;
args:
ArgName WS* '=' WS* ArgValue (',' ArgName WS* '=' WS* ArgValue)*
;
// stuff I put in for reusable components
Identifier : (Char|'_') + (Int|Char|'_')*; // composition of characters, _'s, and digits
Int : '0'..'9'+ ; // any digit, one or more times
CRLF:'\r'? '\n' ; // carriage return / line feed
WS : (' '|'\t')+ {skip();} ; // whitespace
Char : ('a'..'z'|'A'..'Z'); // any character
Float : Int+ '.' Int+; // one or more digits followed by a period and some more digits
// Tokens we described eariler
MakeBean: 'make bean';
BeanID : Identifier;
Class : Identifier ('.' Identifier)*;
TypeOfInjection: 'constructor-arg';
ArgName : Identifier;
ArgValue: Identifier|Int|Float;
I don't claim that this design is the optimal (or even close to optimal) one - this is the first I've done something like this outside of an academic setting, where the goal was to explain the kinds of strings something like this might generate (or, given some strings, construct a grammar that can generate it). In fact, if you've got a better design (with reasons, or some heuristics we can follow), I'd especially love to hear from you in the comments. Also, feel free to ask questions and I'll answer them to the best of my ability.
In all, it is hard to measure how long this took me. I had tons of different distractions going on while doing this, so discounting those I'd estimate about an hour or two to get this VERY minor grasp of ANTLR- but I also have the benefit of already being exposed to the grammar description language, so your mileage may vary. In case you're interested, here are some ANTLR tutorials.
The main drawback to ANTLR is that it has only a few target languages (at the moment): Java, C#, Objective C, C, Python and Ruby. On the other hand, Perl, C++, and Oberon are being worked on, and you are able to add support for others. (Does anyone want to make one of these for ColdFusion?)
But, even with that limitation, is it starting to look like all those benefits to using XML as a DSL container aren't exclusive to XML? I can imagine how easy this would be once I learn what I'm doing. Guess its time to buy The Definitive ANTLR Reference: Building Domain-Specific Languages (the Elk?).
Last modified on Jun 25, 2007 at 06:04 PM UTC - 5 hrs
Posted by Sam on Jun 18, 2007 at 07:19 PM UTC - 5 hrs
About a month ago, Robert Martin posted what has to be the funniest critique on using XML I've ever read.
More...
"I hereby declare a revolt. From now on anyone who considers themselves to be a serious professional must refuse to write another line of XML."

Viva la revolución!
Posted by Sam on Jun 18, 2007 at 02:50 PM UTC - 5 hrs
This one refers to the 40+ minute presentation by Obie Fernandez on Agile DSL Development in Ruby. (Is InfoQ not one of the greatest resources ever?)
You should really view the video for better details, but I'll give a little rundown of the talk here.
Obie starts out talking about how you should design the language first with the domain expert, constantly refining it until it is good - and only then should you worry about implementing it (this is about the same procedure you'd follow if you were building an expert system as well). That's where most of the Agility comes into play.
More...
Later, he moves on to describe four different types of design for your DSL. This was something I hadn't really thought about before, therefore it was the most interesting for me. Here are the four types:
- Instantiation: The DSL consists simply of methods on an object. This is not much different from normal programming. He says it is "DSLish," perhaps the way Blaine Buxton looks at it.
- Class Macros: DSL as methods on some ancestor class, and subclasses can then use those methods to tweak the behavior of themselves and their subclasses. This follows a declarative style of programming, and is the type of DSL followed by Ruby on Rails (and cfrails) if I understand him correctly.
- Top-level methods: Your application defines the DSL as a set of top-level methods, and then invokes
load with the path to your DSL script. When those methods are called in the configuration file, they modify some central (typically global) data, which your application uses to determine how it should execute. This is like scripting, and (again) if I understood correctly, this is the style my (almost working correctly) Partial Order Planner uses.
- Sandboxing (aka Contexts): Similar to the Instantiation style, but with more magic. Your DSL is defined as methods of some object, but that object is really just a "sandbox." Interaction with the object's methods modifies some state in the sandbox, which is then queried by the application. This is useful for processing user-maintained scripts kept in a database, and you can vary the behavior by changing the execution context.
Note: These are "almost" quotes from the slides/talk (with a couple of comments by myself), but I didn't want to keep rewinding and such, so they aren't exact. Therefore, I'm giving him credit for the good stuff, but I stake a claim on any mistakes made.
The talk uses Ruby as the implementation language for the example internal DSLs, but I think the four types mentioned above can be generalized. At the least, they are possible in ColdFusion - but with Java, I'm not so sure. In particular, I think you'd need mixin ability for the Top-level methods style of DSL.
Next, Obie catalogs some of the features of Ruby you see used quite often in crafting DSLs: Symbols (because they have less noise than strings), Blocks (for delayed evaluation of code), Modules (for cleaner separation of code), Splats (for parameter arrays), the different types of eval (for dynamic evaluation), and define_method and alias_method.
Finally, he winds up the presentation with a bit about BNL. I liked this part because I found Jay Fields' blog and his series of articles about BNL.
As always, comments, questions, and thoughts are appreciated. Flames - not so much.
Posted by Sam on Jun 18, 2007 at 12:57 PM UTC - 5 hrs
Lot's of stuff on DSLs today (though most of it is old news). First, we have chromatic a little peeved that DSL doesn't seem to mean much, asking isn't it just an API? Probably so (but does that mean it can't be viewed as a DSL?).
More...
But then David A. Black (not really in the order I'm presenting them here) asks if really what people mean by "a DSL" is really just "DSL," or do they mean they are using domain specific language, not a domain specific language?
Werner Schuster at InfoQ brought all this to my attention, and quoted Blaine Buxton, who said " a DSL is a healthy bi-product of a good object-oriented design."
We've also got Peter Bell reintroducing us to Martin Fowler's talk on InfoQ as a good 25-minute introduction to DSLs, and Fowler's short description of the subject.
Then we have this absolutely marvelous post from Peter about why in the world DSLs should matter to you ( if you read only one of the links I've pointed to here, make this the one).
The posts from Martin (and video), Peter, and Blaine pretty much describe my view, and the response to chromatic I was planning on writing. But I don't think it's valuable by itself to describe precisely what a DSL is (in fact, Fowler mentioned there is no such line that can be drawn). And, since they've said it better than I likely could have, I've just pointed to them so as to avoid having a post dedicated solely to that purpose, which would have been a colossal waste of time.
Posted by Sam on May 23, 2007 at 11:23 AM UTC - 5 hrs
Something I haven't thought much about, but am beginning to (want to) get into is the auto-generation of reports. Autogenerating forms, validation, and operations for CRUD is quite simple - the approach I've used simply gets what metadata it can from the database, and dynamically builds around it. So, NOT NULL fields become required, datetimes build different form fields from nvarchars, and validate as such (as do other types), and field maxlengths are honored on the HTML side based on the DB metadata (among other things). That is incredibly useful by itself, but not useful enough for a real, production quality application (should the user really be required to remember the categoryID?)
More...
Of course not -- some fields should map to a foreign key which should show up as a select form element, which lists the human readable descriptions of those fields (as opposed to their database identifiers). Further, some fields should be hidden, and some fields should be compositions of others. Values for some fields should be in a range of legitimate values, and so the list of possible customizations goes on. In those special cases (which occur frequently enough), you just need to provide a means to override the default behaviors (through extra, user-defined metadata, a DSL, or some other tactic or a combination of them).
Then, in the really rare edge cases, you can always drop out of the framework and code it yourself (or have it generate a template for you to modify). Even for search forms (which I think are more often in need of customization than simple CRUD stuff), you can provide the basics and allow the programmer to customize as needed (and drop out of the framework all together if need be).
But is there a similar strategy for generating reports? My initial thought is that there isn't. Reports just seem to need too much customization to have any useful automagic generation. But, I'm trying to look past that initial impression, because I don't have as many years of experience in hand-writing the same crap code over and over again in reporting as I do in writing CRUD operations (now, I have the same crap code for CRUD in one place and it just figures out what to do, but at least I don't ever need to write it again =)).
In any case, I just don't see it. But, I can see using metadata/DSL, where you can define the tables and columns you want to report on, and generally it will still be much faster for developing reports (can you tell I'm trying to work on this at the moment?). Taking the idea further, what about bringing convention over configuration into this realm? Once you get out of the world of 8.3 filenames and realize you can name variables (or columns) pretty much anything you want, it is easy to see the benefit of having names that describe what you want the user to see. For instance, instead of orderGTot, just go ahead and name the column order_grand_total or orderGrandTotal. Who cares about the extra characters? It's not like you have to type them that many times, since the framework (presumably) takes care of most of it for you, and you don't have to define what the user should see in more than one place.
Of course, this is also just metadata. But, instead of having what amounts to the same metadata in different places, you've just got it in one - your column name. So if we take this idea to reporting, what if we just tag certain columns with something like _reportable? I haven't figured out how we might generate reports on that amount of information alone, but I see it as a useful start.
When your classes average between zero and twenty lines of code (which amounts to just customizing interfaces and performing validations, along with perhaps a couple of calculations), it's time to stop worrying about DAOs, DTOs, PPOs, and Cheerios. Skip to the IPO and let the frameworks worry about the rest. I want one to do my reporting for me, because that seems to be one of the last major hurdles that I see (at least, as far as getting rid of repetition goes).
What do you think?
Posted by Sam on May 19, 2007 at 01:25 PM UTC - 5 hrs
Peter Bell's presentation on LightWire
generated some comments I found very interesting and thought provoking.
(Perhaps Peter is not simply into application generation, but comment generation as well.)
The one I find most interesting is brought up by several people whose opinions I value -
Joe Rinehart, Sean Corfield,
Jared Rypka-Hauer, and others during and after the presentation.
That is: what is the distinction between code and data, and specifically, is XML code or data
(assuming there is a difference)?
More...
The first item where I see a distinction that needs to be made is on, "what do we mean when we are talking about
XML?" I see two types - XML the paradigm where you use tags to describe data, and the XML you write - as in,
the concrete tags you put into a file (like, "see that XML?"). We're talking about XML you've written, not
the abstract notion of XML.
The second idea: what is code? What is data? Sean Corfield offers what I would consider to be a concice,
and mostly correct definition: "Code executes, non-code (data) does not execute." To make it correct (rather
than partially so), he adds that (especially in Lisp) code can be data, but data is not code. You see this
code-as-data any time you are using closures or passing code around as data. But taking it a bit further -
your source code is always just data to be passed to a compiler or interpreter, which figures out what the
code means, and does what it has been told to do.
So is XML code? Certainly we see it can be: ColdFusion, MXML, and others are languages where your
source code is written (largely) in XML. But what about the broader issue of having a programmatic
configuration file versus a "data-only" config file?
Is the data in the config file executable? It depends on the purpose behind the data. In the case of data
like
<person>
<name>
Bill
</name>
<height>
4'2"
</height>
</person>
I think (assuming there is nothing strange going on) that it is clearly data. Without knowing anything about the
back end, it seems like we're just creating a data structure. But In the case of
DI (and many others uses for config files),
I see it as giving a command to the DI framework to configure a new bean. In essence, as Peter notes,
we've just substituted one concrete syntax for another.
In the case of XML, we're writing (or using)
a parser to send data to an intepreter we've written that figures out what "real" commands to run based on
what the programmer wrote in the configuration file. We've just created a higher level language than we had before
- it is doing the same thing any other non-machine code language does (and you might even argue
about the machine code comment). In the configuration case,
often it is a DSL (in the DI case specifically, used to describe which objects depend on which other
objects and load them for us).
While we don't often have control structures, there is nothing stopping us from implementing them,
and as Peter also notes, just because a language is not
Turing complete), doesn't mean it is not
a programming language. In the end, I see it as code.
Both approaches are known to have their benefits and drawbacks, and choosing one over the other is largely a matter
of personal taste, size and scope of problem, and problem/solution domain. For me, in the worlds of
JIT compiling and interpreted langages, the programmatic way
of doing things tends to win out - especially with large configurations because I prefer to have
the power of control structures to help me do my job (without having to implement them myself).
On the other hand, going the hard-coded XML route is especially popular in the compiled world, if not
for any other reason than you can change configurations without recompiling your application.
I don't make a distinction between the two on terms of XML is data, while programming (or using an in-language DSL)
in your general-purpose language is code. To me, they are both code, and if either is done incorrectly it will
blow-up your program.
Finally, I'm not sure what value we gain from seeing that code is data (and in many cases config data is code),
other than perhaps a new way of looking at problems which might lead us to find better solutions.
But that isn't provided by the distinction itself, just the fact that we saw it.
Comments, thoughts, questions, and requests for clarifications are welcome and appreciated.
Posted by Sam on May 01, 2007 at 09:36 AM UTC - 5 hrs
There are a couple of drawbacks (or some incompleteness) to scaffolding being truly useful. The one that seems to be most often cited is that normally (at least in Ruby on Rails, which seems to have popularized it) it looks like crap (it is only scaffolding though). Of course, most who make that complaint also recognize that it is only a starting point from which you should build.
Django has been generating (what I feel is) production-quality "admin" scaffolding since I first heard about it. It looks clean and professional. Compare that to the bare-bones you get by default in Rails, and you're left wondering, "why didn't they do that?" Well, as it happens, it has been done. In particular, there are at least 4 such products for use with Rails: Rails AutoAdmin (which professes to be "heavily inspired by the Django administration system"), ActiveScaffold (which is just entering RC2 status), Hobo, and Streamlined (whose site is down for me at the moment).
More...
My interest lies in the second complaint though - that writing it to a live file (rather than dynamically figuring it out - which I've been calling "synthesis," as opposed to generation) means you can't get the benefits of upgrades to the scaffolding engine (and, it is not following DRY!). But, if you just use the default scaffolding, what happens if it doesn't come out just right (assuming you've even passed the notUgly test in the first place)? Well, thats a big part of what I'm trying to solve with cfrails, by using a DSL that provides tweakability to the scaffolding, without requiring you to write to a file (though, if the tweaks won't work, you are always welcome to go to a file with HTML and the like). The interesting part for me about the RoR plugins above, therefore, is that it appears (I haven't checked them out yet) that at least Hobo contains a DSL, called DRYML, to help along those lines.
I'll be having a closer look at those when free time becomes a bit less scarce. What do you think? Is it the holy grail, or can there be very useful
"scaffolding"?
Last modified on May 01, 2007 at 09:37 AM UTC - 5 hrs
|
Me

|
