Posted by Sam on Nov 26, 2013 at 03:26 PM UTC - 5 hrs
I like minitest and I like rspec-mocks, so I wanted to use them together. Now you can too!
Thoughts? Let me know!
Hey! Why don't you make your life easier and subscribe to the full post
or short blurb RSS feed? I'm so confident you'll love my smelly pasta plate
wisdom that I'm offering a no-strings-attached, lifetime money back guarantee!
Posted by Sam on Sep 23, 2013 at 06:46 AM UTC - 5 hrs
minitest-stub_any_instance will define a method stub on any instance of a class for the duration of a block.
String.stub_any_instance(:length, 42) do
assert_equal "hello".length, 42 # this assertion passes!
end
@nashby_ actually extracted the code from SimpleForm to do the job, and suggested it be included in MiniTest itself. But that didn't fly, so I packaged it as a plugin/gem.
Last modified on Sep 23, 2013 at 06:47 AM UTC - 5 hrs
Posted by Sam on Feb 20, 2013 at 09:42 AM UTC - 5 hrs
Last week at the Houston Ruby User Group I made a presentation called "The Website's Slow" Tips and Tools for Identifying Performance Bottlenecks.

That link is to the slides and notes on each slide mentioning a little about what I said.
Basically I went through a couple of different classes of performance issues you're likely to see on the server side of things, what tools you might use to make finding the issue easier, how you can interpret some of the data, and even a suggestion here or there about what to do to resolve common issues I've seen.
Let me know what you think! (Or, if you have any questions, feel free to ask!)
Last modified on Feb 20, 2013 at 09:48 AM UTC - 5 hrs
Posted by Sam on May 28, 2008 at 12:00 AM UTC - 5 hrs
In the field of bioinformatics, one way to measure similarities between two (or more) sequences of
DNA is to perform sequence alignment:
"a way of arranging the primary sequences of DNA, RNA, or protein to identify regions of similarity that may
be a consequence of functional, structural, or evolutionary relationships between the sequences."
Think of it this way: you've got two random strands of DNA - how do you know where one starts and one begins?
How do you know if they come from the same organism? A closely related pair? You might use sequence alignment
to see how the two strands might line up in relation to each other - subsequences may indicate similar
functionality, or conservation through evolution.
In "normal" programming terms, you've got a couple of strings and want to find out how you might align them so they they look
as much like one another as possible.
There are plenty of ways to achieve that goal. Since we haven't done much programming on here lately,
I thought it would be nice to focus on two very similar algorithms that do so:
Needleman-Wunsch and
Smith-Waterman.
The idea behind these two algorithms is that we have a scoring scheme we want to maximize as successive
"matches" occur. One popular substitution matrix for scoring
protein alignment is BLOSUM62
(and here's a good PDF describing how BLOSUM came about).
The particular scoring matrix you use will be determined by the goals you want to acheive.
For our purposes, a simple matrix or two will suffice:
@substitution_matrix =
[[" ", "a","c","g","t"],
["a", 1 , 0 , 0 , 0 ],
["c", 0 , 1 , 0 , 0 ],
["g", 0 , 0 , 1 , 0 ],
["t", 0 , 0 , 0 , 1 ]]
@substitution_matrix2 =
[[" ", "s", "e", "n", "d", "a"],
["s", 4 , 0 , 1 , 0 , 1 ],
["e", 0 , 5 , 0 , 2 , -1 ],
["n", 1 , 0 , 6 , 1 , -2 ],
["d", 0 , 2 , 1 , 6 , -2 ],
["a", 1 , -1 , -2 , -2 , 4 ]]
The first @substitution_matrix is fairly simplistic - give one point for each match, and ignore any mismatches or gaps introduced.
In @substitution_matrix2
what score should be given if "s" is aligned with "a"? (One.) What if "d" is aligned with another "d"? (Six.)
The substitution matrix is simply a table telling you how to score particular characters when they are in the same position in two
different strings.
After you've determined a scoring scheme, the algorithm starts scoring each pairwise alignment, adding to or
subtracting from the overall score to determine which alignment should be returned. It uses
dynamic programming, storing calculations
in a table to avoid re-computation, which allows it to reverse course after creating the table to find and return
the best alignment.
It feels strange to implement this
as a class, but I did it to make it clear how trivially easy it is to derive Smith-Waterman (SW) from Needleman-Wunsch (NW). One design that jumps out at me would be to have a SequenceAligner where you can choose which algorithm as a method to run - then SW could use a NW algorithm where min_score is passed as a parameter to the method. Perhaps you can think of something even better.
Anyway, here's the Ruby class that implements the Needleman-Wunsch algorithm.
class NeedlemanWunsch
@min_score = nil
def initialize(a, b, substitution_matrix, gap_penalty)
@a = a
@b = b
# convert to array if a/b were strings
@a = a.split("") if a.class == String
@b = b.split("") if b.class == String
@sm = substitution_matrix
@gp = gap_penalty
end
def get_best_alignment
construct_score_matrix
return extract_best_alignment_from_score_matrix
end
def construct_score_matrix
return if @score_matrix != nil #return if we've already calculated it
initialize_score_matrix
traverse_score_matrix do |i, j|
if i==0 && j==0
@score_matrix[0][0] = 0
elsif i==0 #if this is a gap penalty square
@score_matrix[0][j] = j * @gp
elsif j==0 #if this is a gap penalty square
@score_matrix[i][0] = i * @gp
else
up = @score_matrix[i-1][j] + @gp
left = @score_matrix[i][j-1] + @gp
#@a and @b are off by 1 because we added cells for gaps in the matrix
diag = @score_matrix[i-1][j-1] + s(@a[i-1], @b[j-1])
max, how = diag, "D"
max, how = up, "U" if up > max
max, how = left, "L" if left > max
@score_matrix[i][j] = max
@score_matrix[i][j] = @min_score if @min_score != nil and max < @min_score
@traceback_matrix[i][j] = how
end
end
end
def extract_best_alignment_from_score_matrix
i = @score_matrix.length-1
j = @score_matrix[0].length-1
left = Array.new
top = Array.new
while i > 0 && j > 0
if @traceback_matrix[i][j] == "D"
left.push(@a[i-1])
top.push(@b[j-1])
i -= 1
j -= 1
elsif @traceback_matrix[i][j] == "L"
left.push "-"
top.push @b[j-1]
j -= 1
elsif @traceback_matrix[i][j] == "U"
left.push @a[i-1]
top.push "-"
i -= 1
else
puts "something strange happened" #this shouldn't happen
end
end
return left.join.upcase.reverse, top.join.upcase.reverse
end
def print_score_visualization
construct_score_matrix
print_as_table(@score_matrix)
end
def print_traceback_matrix
construct_score_matrix
print_as_table(@traceback_matrix)
end
def print_as_table(the_matrix)
puts
puts "a=" + @a.to_s
puts "b=" + @b.to_s
puts
print " "
@b.each_index {|elem| print " " + @b[elem].to_s }
puts ""
traverse_score_matrix do |i, j|
if j==0 and i > 0
print @a[i-1]
elsif j==0
print " "
end
print " " + the_matrix[i][j].to_s
puts "" if j==the_matrix[i].length-1
end
end
def traverse_score_matrix
@score_matrix.each_index do |i|
@score_matrix[i].each_index do |j|
yield(i, j)
end
end
end
def initialize_score_matrix
@score_matrix = Array.new(@a.length+1)
@traceback_matrix = Array.new(@a.length+1)
@score_matrix.each_index do |i|
@score_matrix[i] = Array.new(@b.length+1)
@traceback_matrix[i] = Array.new(@b.length+1)
@traceback_matrix[0].each_index {|j| @traceback_matrix[0][j] = "L" if j!=0 }
end
@traceback_matrix.each_index {|k| @traceback_matrix[k][0] = "U" if k!=0 }
@traceback_matrix[0][0] = "f"
end
def s(a, b) #check the score for bases a. b being aligned
for i in 0..(@sm.length-1)
break if a.downcase == @sm[i][0].downcase
end
for j in 0..(@sm.length-1)
break if b.downcase == @sm[0][j].downcase
end
return @sm[i][j]
end
end
Needleman-Wunsch follows that path, and finds the best global alignment possible. Smith-Waterman truncates
all negative scores to 0, with the idea being that as the alignment score gets smaller, the local alignment
has come to an end. Thus, it's best to view it as a matrix, perhaps with some coloring to help you visualize
the local alignments.
All we really need to get Smith-Waterman from our implementation of Needleman-Wunsch above is this:
class SmithWaterman < NeedlemanWunsch
def initialize(a, b, substitution_matrix, gap_penalty)
@min_score = 0
super(a, b, substitution_matrix, gap_penalty)
end
end
However, it would be nice to be able to get a visualization matrix. This matrix should be able to use windows
of pairs instead of
each and every pair, since there can be thousands or millions or billions of base pairs we're aligning. Let's add a couple of methods to that
effect:
#modify array class to include extract_submatrix method
class Array
def extract_submatrix(row_range, col_range)
self[row_range].transpose[col_range].transpose
end
end
require 'needleman-wunsch'
class SmithWaterman < NeedlemanWunsch
def initialize(a, b, substitution_matrix, gap_penalty)
@min_score = 0
super(a, b, substitution_matrix, gap_penalty)
end
def print_score_visualization(window_size=nil)
return super() if window_size == nil
construct_score_matrix
#score_matrix base indexes
si = 1
#windowed_matrix indexes
wi = 0
windowed_matrix = initialize_windowed_matrix(window_size)
#compute the windows
while (si < @score_matrix.length)
sj = 1
wj = 0
imax = si + window_size-1
imax = @score_matrix.length-1 if imax >= @score_matrix.length
while (sj < @score_matrix[0].length)
jmax = sj + window_size-1
jmax = @score_matrix[0].length-1 if jmax >= @score_matrix[0].length
current_window = @score_matrix.extract_submatrix(si..imax, sj..jmax)
current_window_score = 0
current_window.flatten.each {|elem| current_window_score += elem}
begin
windowed_matrix[wi][wj] = current_window_score
rescue
end
wj += 1
sj += window_size
end
wi += 1
si += window_size
end
#find max score of windowed_matrix
max_score = 0
windowed_matrix.flatten.each{|elem| max_score = elem if elem > max_score}
max_score += 1 #so the max normalized score will be 9 and line up properly
#normalize the windowed matrix to have scores 0-9 relative to percent of max_score
windowed_matrix.each_index do |i|
windowed_matrix[i].each_index do |j|
begin
normalized_score = windowed_matrix[i][j].to_f / max_score * 10
windowed_matrix[i][j] = normalized_score.to_i
rescue
end
end
end
#print the windowed matrix
windowed_matrix.each_index do |i|
windowed_matrix[i].each_index do |j|
print windowed_matrix[i][j].to_s
end
puts
end
end
def initialize_windowed_matrix(window_size)
windowed_matrix = Array.new(((@a.length+1).to_f)/window_size)
windowed_matrix.each_index do |i|
windowed_matrix[i] = Array.new(((@b.length+1).to_f)/window_size)
end
return windowed_matrix
end
end
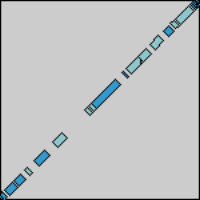
And now we'll try it out. First, we take two sequences and perform a DNA dotplot analysis on them:

Then, we can take our own visualization, do a search and replace to colorize the results by score, and have a look:
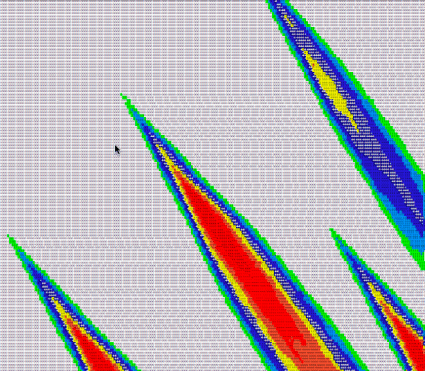
Lo and behold, they look quite similar!
I understand the algorithms are a bit complex and particularly well explained, so I invite questions about
them in particular. As always, comments and (constructive) criticisms are encouraged as well.
Posted by Sam on Jun 05, 2012 at 08:15 PM UTC - 5 hrs
I just read an excerpt from @avdi's new alpha Confident Ruby ebook and it prompted some thoughts:
In the article, he talks about dealing with an account_balance where you iterate over
the transactions of the account and sum up their amounts to arrive at a final balance.
A special case arrives when he points out you're dealing with a transaction.type
whose value is "pending". You clearly don't want to include this in the account_balance because when the transaction processor introduces a new
transaction of "authorized" for the same purchase, your overall balance will be incorrect.
A lot of the code I see (and used to write) looks like Avdi's example:
def account_balance
cached_transactions.reduce(starting_balance) do |balance, transaction|
if transaction.type == "pending"
balance
else
balance + transaction.amount
end
end
end
It cannot be stressed enough how important the advice is to go from code like that to introducing a new object. In my experience, many cases are solved by simply introducing an OpenStruct.new(attributes: "you need", to: "support"), but Avdi advocates going further than that, and introducing a new object entirely.
I'm a fan of that, but typically I'll wait until YAGNI is satisfied, like when I need a method call with parameters.
Doing that is a huge win. As Avdi points out, it
solves the immediate problem of a special type of transaction, without duplicating logic for
that special case all throughout the codebase
But for me, the second benefit he mentions is the biggest, and I hope he'll revisit its importance over and over again:
But not only that, it is exemplary: it sets a good example for code that follows. When, inevitably, another special case transaction type turns up, whoever is tasked with dealing with it will see this class and be guided towards representing the new case as a distinct type of object.
It's something I mentioned in my How to avoid becoming a formerly-employed Rails developer standing in line at the OOP Kitchen presentation, and I'll continue to stress its importance: "it's always easier to go with the flow, even when the flow is taking you through the sewers." So if you can introduce a little example of how to avoid the sewers, do it.
Anyway, I bought the book (which is literally just an introduction right now) based on the strength of that article and Avdi's commitment in his blog post. The article I linked to on Practicing Ruby is not yet in the book, but I hope it makes its way in.
I really enjoy the style of what I've read so far as a narrative, and if the article is any indication, this will be better than Objects on Rails (which I loved). One bit of feedback though: I'd like to see a "Key Takeaway" at the end of every section, so it can double as a quick reference book when I need to remind myself of its lessons.
Last modified on Jun 05, 2012 at 08:16 PM UTC - 5 hrs
Posted by Sam on Feb 27, 2012 at 07:45 AM UTC - 5 hrs
Here's a 35 minute recording of the presentation which I gave to houstonrb on February 21, 2012. It is a practice run I did before the live presentation, so you won't get the discussion, but hopefully you'll find it useful anyway.
How to avoid becoming a formerly-employed Rails developer standing in line at the OOP Kitchen from Sammy Larbi on Vimeo.
You can find the slides here: Slides for the Rails OOP presentation
There is also reference to a project whose purpose is to eventually be a full-scale demonstration of the techniques: Project for the Rails OOP presentation
Let me know what you think in the comments below.
Updated to use HTML5 player at Vimeo.
Last modified on Mar 01, 2012 at 06:10 AM UTC - 5 hrs
Posted by Sam on Dec 21, 2011 at 08:49 AM UTC - 5 hrs
 Type Casing
Type Casing is the act of using case statements
in a program to determine what to do with an object based on what type of object it is. It's an OO fail, often
hoping to implement Multiple Dispatch. (See also
Case Statements Considered Harmful)
Here are three passive-aggressive ways to feel like you're getting back at typecasers.
More...
The first tactic turns your object into an everything, so it's whatever the typecaser was looking for. I've called it
OmniObject.
module OmniObject
def is_a?(*)
true
end
def kind_of?(*)
true
end
def nil?
true
end
end
foo = "hello, world!"
foo.extend OmniObject
puts "Is foo a Fixnum? #{foo.is_a?(Fixnum) ? 'yes' : 'no'}"
puts "Is foo a Kernel? #{foo.is_a?(Kernel) ? 'yes' : 'no'}"
puts "Is foo a NilClass? #{foo.kind_of?(NilClass) ? 'yes' : 'no'}"
puts "foo.nil? => #{foo.nil?}"
The next one makes your object unable to decide what it is, turning it into a FickleTeenager. If he has to check more than once,
the typecaser is going to have a tough time with a kid who can't make up his mind.
module FickleTeenager
def is_a?(*)
sorta
end
def kind_of?(*)
sorta
end
def nil?
sorta
end
def sorta
truish
end
def truish
rand < 0.5
end
end
foo = "hello, world!"
foo.extend FickleTeenager
3.times{ puts "Is foo a String? #{foo.kind_of?(String) ? 'yes' : 'no'}"}
Finally, we have the AntisocialPrivacyAdvocate. When the typecaser asks him what he is, he tells them like it is: It's none of your damn business!
class WhatBusinessOfItIsYoursError < StandardError; end;
module AntisocialPrivacyAdvocate
def is_a?(*)
raise WhatBusinessOfItIsYoursError
end
def kind_of?(*)
is_a?
end
def nil?
is_a?(NilClass)
end
end
foo = "hello, world!"
foo.extend AntisocialPrivacyAdvocate
result = foo.kind_of?(String) rescue "#{$!} OMG, How Rude!"
puts result
Posted by Sam on Oct 24, 2011 at 08:41 AM UTC - 5 hrs
With a name like each_cons, I thought you were going to iterate through all the
permutations of how I could construct a list
you operated upon. For example, I thought
[1,2,3,4].each_cons do |x| # I did not notice the required argument
puts x.inspect
end
would output:
More...
[[1,2,3,4], []]
[[1,2,3], [4]]
[[1,2], [3,4]]
[[1], [2,3,4]]
[[], [1,2,3,4]]
So when I needed to find the local maxima in an image projection to
algorithmically find the staves in sheet music, I
found myself wanting a C-style for loop.
I didn't know you'd provide me with a wonderful sliding window!
[1,2,3,4].each_cons(2) do |x|
puts x.inspect
end
[1, 2]
[2, 3]
[3, 4]
From now on, I'll turn to you when I need that functionality. Thanks for waiting
on me, each_cons. Not everyone would be as patient as you.
Warm Regards,
Sam
PS: In case you're interested, the "cons" in "each_cons" is short for "consecutive," not "construct," as
Matz informed me:
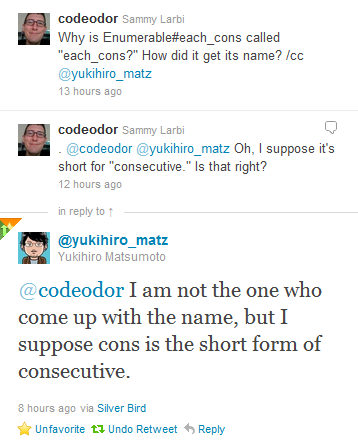
Last modified on Oct 24, 2011 at 08:45 AM UTC - 5 hrs
Posted by Sam on Jul 15, 2011 at 08:08 PM UTC - 5 hrs

Yesterday I wondered if there was a good reason we couldn't gem install <url to git repository> and thought I'd have a look at adding it to rubygems for fun's sake.
Then I saw how many files there were and decided gem install from git with a shell script would be easily achieved in just a few minutes.
#!/bin/bash
gemifgTMPDIR=$TMPDIR"_gemifg"
git clone $1 $gemifgTMPDIR
gemifgOWD=$PWD
cd $gemifgTMPDIR
gem build *.gemspec
gem install *.gem
if [ ! -z "$gemifgTMPDIR" ]
then
rm -rf $gemifgTMPDIR
fi
cd $gemifgOWD
Let me know what you think, or if there are some repositories where it doesn't work for you. I only tested it on utility-belt.
Last modified on Jul 15, 2011 at 08:10 PM UTC - 5 hrs
Posted by Sam on Jun 22, 2011 at 06:42 AM UTC - 5 hrs
Yesterday I got sick of typing rake test and rake db:migrate and being told
You have already activated rake 0.9.2, but your Gemfile requires rake 0.8.7. Consider using bundle exec.
I know you should always run bundle exec, but my unconscious memory has not caught up with my conscious one on that aspect, so I always forget to run rake under bundle exec.
So I wondered aloud on twitter if I could just alias rake to bundle exec rake, but confine that setting to specific directories (with bash being my shell).
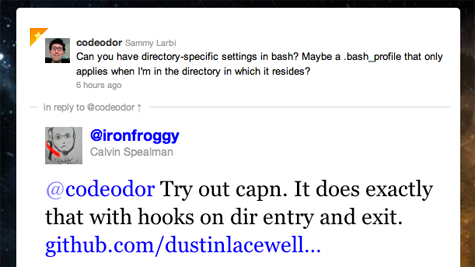
Turns out, it is possible with the help of another tool that
Calvin Spealman pointed me towards: capn.
More...
To successfully run the commands I've listed below, you need to have python and homebrew already installed. If you already have libyaml installed or have another way of getting it, there's no need for homebrew.
The section beginning with the line that starts out with echo and ending with -unalias rake"... creates the capn config file. It's just YAML, so if you'd rather create it with a text editor, you can surely do so. See the capn project for details on the config possibilities.
Either way, you'll want to change the paths I've used to the places you want to do the aliasing.
From the terminal, run the following commands:
curl -O http://python-distribute.org/distribute_setup.py
sudo python distribute_setup.py
sudo easy_install pip
sudo brew install libyaml
sudo easy_install -U pyyaml
sudo pip install capn
echo "
settings:
default_type: path
hooks:
- path: ~/workspace #change this to the path where you want to alias rake
type: tree # if you don't want the whole tree under the path above, remove this line
enter:
- echo aliasing rake to 'bundle exec rake'
- alias rake='bundle exec rake'
exit:
- echo unaliasing rake from 'bundle exec rake'
- unalias rake" > ~/.capnhooks
source capn # put this line in your .bash_profile if you want capn to work when you enter the shell
# to deactivate the hooks, use: unhook
Enjoy the silence now that you don't have to hear the whining.
Posted by Sam on Aug 03, 2010 at 12:46 PM UTC - 5 hrs
Rails Rumble has nothing on this.
Of course, you could just click the edit button in your database management studio of choice and achieve the same functionality.
SELECT DISTINCT 'script/generate scaffold ' + t.name + ' ' + column_names
FROM sys.tables t
CROSS APPLY (
SELECT c.name +
case when max_length > 255 then ':text' else ':string' end + ' '
FROM sys.columns c
WHERE c.object_id = t.object_id
ORDER BY c.column_id
FOR XML PATH('') ) dummy_identifier ( column_names )
A similar discovery was made in the 1930's. One important difference to note is that, since my program does not simulate the input on it's output program, I am able to achieve speeds that are logarithmically faster than what Turing could accomplish.
Posted by Sam on Jan 12, 2009 at 12:00 AM UTC - 5 hrs
I like to use descriptive variable names, and I try to err on the side of more-descriptive if I think there's
any chance of confusion. contract_participants isn't terribly long, but if you're building
up all of its members from different sources (i.e., you can't really loop over it), it can get cumbersome
to type and worse, to read. Moreover, it's different from just "participants" and they certainly
aren't "contracts," so shortening it in this case wasn't going to happen.
More...
contract_participant.first_name = "Joe"
contract_participant.last_name = "Smith"
contract_participant.on_drugs? = params[:on_drugs?]
...
It doesn't really violate the spirit of DRY, but it's
frustrating nevertheless.

I wanted to just have a scope for contract participants and not have to type it every time:
with(contract_participant) do
first_name = "Joe"
last_name = "Smith"
on_drugs? = params[:on_drugs?]
end
Unfortunately, unlike some languages, Ruby doesn't have such a construct. Fortunately, it does have
the facilities to create one. I thought there was already an implementation, but I couldn't find it at
first. So I started to write my own.
For some reason I was looking through Utility Belt and noticed
it had an implementation of with():
class Object
def with(object, &block)
object.instance_eval &block
end
end
Unbelievable! My implementation was running into a WTF in its own right, and here was this one-liner.
Unfortunately, Utility Belt's with() didn't pass the test cases that demonstrate
how I wanted to use it, so I had to move on.
With was created as a result of those efforts. It
works how I want it to in the simple cases I've demonstrated. It still needs some work on left-hand-side
variables that are not members of the aforementioned @foo. It needs some tests for
more complex uses like nested blocks (and
code to make them pass). But it works for what I imagine the majority usage would be.

I opted for the syntax With.object(foo) do ... end so as to not force you to use a
change to Object. However, you can require 'with_on_object' if you prefer
to just use with(@foo). There's also a conditional patch on NilClass if
empty? does not exist. It is added and removed in the same method.
It requires Ruby2Ruby and ParseTree
to do its magic, though that will change soon due to compatibility problems with Ruby 1.9 and other implementations
(for which another project exists, if I've read correctly).
To install, you can use: sudo gem install codeodor-with -s http://gems.github.com
Let me know if you're using it and encounter any problems. I'd like to fix them quickly, if I can.
Posted by Sam on Mar 03, 2009 at 12:00 AM UTC - 5 hrs
A while ago, I was working with a problem in C# where where our code would get deadlocked, and since someone must die or several must starve, I thought it
would be nice to just toss a "try again if deadlocked"
statement into the exception handler. I muttered this thought on twitter to
see if there was any language with such a try-catch-try-again-if construct.
More...

A couple of my tweeps responded with what we we're used to using: loops.


Another two mentioned redo in Ruby.


redo is certainly a cool construct (and underused), but it doesn't do what I want
it to:
begin
raise from_the_dead
rescue
redo
end

Ruby responds, "tryredo.rb:35: unexpected redo." As you might know, you need to use a loop:
class Zombie
def initialize
@starving = true
@last_feeding = DateTime.new
end
def eat(bodypart)
@starving = (DateTime.now - @last_feeding) * 10_000_000 > 3
starving_enough_to_reconsider = @starving && rand > 0.5
unless starving_enough_to_reconsider || bodypart == "braaaiiinzzz"
raise "Zombies don't like #{bodypart}"
end
puts "Mmmmm... #{bodypart}"
@starving = false
@last_feeding = DateTime.now
end
end
zombie = Zombie.new
["feet", "stomach", "intestines", "braaaiiinzzz"].each do |bodypart|
begin
zombie.eat bodypart
sleep 1
rescue
puts $!
redo
end
end
So I'll ask to this larger audience:
Suppose I have a zombie who only really likes eating braaaiiinzzz. Most of the time, he gets exactly
what he wants. But every so often, we try to feed him some other body part. Now, if he's really hungry, he
eats it. We might only have fingers available at the time, so I want
to try to feed him fingers again until brains are available or until he's hungry enough to eat the fingers.
I know that conceptually this is just a loop even if we don't explicitly code it. But does your language have a
try again? What do you think the merits or demerits of such an approach would be? Is it just a harmful
goto?
My zombie is hungry and waiting. Rather impatiently I might add.
Posted by Sam on Mar 12, 2009 at 12:00 AM UTC - 5 hrs
SOAP can be a huge PITA in Ruby if you're not dealing with a web service that falls
under the defaults. In particular, if your web service falls under
HTTPS where you need to change the default
certificate acceptance, or if you need to authenticate before seeing the
WSDL, you're SOL as far as I
can tell as of writing this post. (If you know of a way that doesn't resort to this complexity, please speak up!)
I was using Ruby 1.8.7 and soap4r 1.5.8, but this may apply to other versions.
Anyway, here are a couple of monkey patches to help get you there if you're having trouble.
More...
If you need to change the SSL verify mode, for example, to accept a certificate unconditionally, you can use this
monkeypatch:
def monkeypatch_httpclient_sslsocketwrap(ssl_verify_mode)
return unless ssl_verify_mode
@sslsocket_monkeypatched = true
require 'soap/nethttpclient'
block = <<END
alias :original_initialize :initialize
def initialize(socket, context, debug_dev = nil)
unless SOAP::NetHttpClient::SSLEnabled
raise ConfigurationError.new('Ruby/OpenSSL module is required')
end
@context = context
@context.verify_mode = #{ssl_verify_mode}
@socket = socket
@ssl_socket = create_openssl_socket(@socket)
@debug_dev = debug_dev
end
END
HTTPClient::SSLSocketWrap.class_eval block
end
If you need to authenticate before seeing the WSDL, you'll need this patch:
def monkeypatch_authentication(username, password)
return unless username && password
@auth_monkeypatched = true
require 'wsdl/xmlSchema/importer'
block = <<END
alias :original_fetch :fetch
def fetch(location)
warn("importing: " + location) if $DEBUG
content = nil
normalizedlocation = location
if location.scheme == 'file' or
(location.relative? and FileTest.exist?(location.path))
content = File.open(location.path).read
normalizedlocation = URI.parse('file://' + File.expand_path(location.path))
elsif location.scheme and location.scheme.size == 1 and
FileTest.exist?(location.to_s)
content = File.open(location.to_s).read
else
client = web_client.new(nil, "WSDL4R")
client.proxy = ::SOAP::Env::HTTP_PROXY
client.no_proxy = ::SOAP::Env::NO_PROXY
client.set_auth(location, "#{username}", "#{password}") #added for auth
if opt = ::SOAP::Property.loadproperty(::SOAP::PropertyName)
http_opt = opt["client.protocol.http"]
::SOAP::HTTPConfigLoader.set_options(client, http_opt) if http_opt
end
content = client.get_content(location)
end
return content, normalizedlocation
end
END
WSDL::XMLSchema::Importer.class_eval block
end
Hope that helps someone else avoid days' long foray into piecing together blogs posts, message boards, and
searching through source code.
And because you might get here via a search for related terms, normal access that only requires basic authentication
could be done like this, without opening existing classes:
class SendBasicAuthFilter < SOAP::Filter::StreamHandler
def initialize(loginname, password)
@authorization = 'Basic ' + [ loginname + ':' + password ].pack('m').delete("\r\n")
end
def on_http_outbound(req)
req.header.delete('Authorization')
req.header['Authorization'] = @authorization
end
def on_http_inbound(req, res)
end
end
list_service_url = 'https://somesite/path/?WSDL'
list_service_driver = SOAP::WSDLDriverFactory.new(list_service_url).create_rpc_driver
user = 'username'
pass = 'password'
list_service_driver.streamhandler.filterchain << SendBasicAuthFilter.new(user,pass)
I'm very welcoming of suggestions regarding how these things might be better accomplished. Resorting to this
messy level of monkeypatching just sucks. Let me know in the comments.
Posted by Sam on Apr 14, 2009 at 12:00 AM UTC - 5 hrs
Code in Views and Code in the Wrong Place are two of the top 20 Rails development No-No's that came up in Chad Fowler's straw poll on Twitter about poor practices in Ruby on Rails.

Domain code in controllers and views isn't a problem that's limited to Rails, of course. It's a problem everywhere, and one you generally need to remain vigilant about. Rails doesn't make it easy by making it easy - it's much too easy to do the wrong thing.
You've got the view open and think, "I need to get a list of Widgets."
More...
<% widgets = Widget.find(:all, :conditions=>["owner=?",session[:user_id]]) %>
That was easy, and it's even easier in controllers where you don't have the hassle of angled brackets and percent signs. Worse yet, since you've got what you need right there, it's easy to add more logic around it. Before you know it, your views and controllers are cluttered with a bunch of crap that shouldn't be there.
I fall into the trap more often than I'd like to admit. And I know it's wrong. What of those who haven't a clue?
To combat this syndrome, I created a Rails plugin called FindFail that makes ActiveRecord::Base#find private.
FindFail results in less business logic in your views and controllers because it forces you to open a model and add a
method. Since you're already in the right place, you may as well stay there. It makes it hard to do the wrong thing, and contributes to making it easier to do the right thing.
It preys on your laziness that way.

It's only one line of useful code, but it can help keep the rest of your code clean.
Posted by Sam on Jun 09, 2009 at 12:00 AM UTC - 5 hrs
From time to time I like to actually post a bit of code on this programming blog, so here's
a stream-of-conscious (as in "not a lot of thought went into design quality") example that shows how to:
- Open Excel, making it invisible (or visible) to the user.
- Create a workbook and access individual worksheets
- Add data to a cell, or retrieve data from a cell
- Add a chart to a worksheet, with constants for various chart types
- Save as Excel 97-2003 format and close Excel
If you know where I can find the constants for file type numbers, that would be appreciated. Calling SaveAs
without the type seems to use whatever version of Excel you are running, but I'd like to find how to save as
CSV or other formats.
Needless to say, this requires Excel be on the computer that's running the code.
require 'win32ole'
xl = WIN32OLE.new("Excel.Application")
puts "Excel failed to start" unless xl
xl.Visible = false
workbook = xl.Workbooks.Add
sheet = workbook.Worksheets(1)
#create some fake data
data_a = []
(1..10).each{|i| data_a.push i }
data_b = []
(1..10).each{|i| data_b.push((rand * 100).to_i) }
#fill the worksheet with the fake data
#showing 3 ways to populate cells with values
(1..10).each do |i|
sheet.Range("A#{i}").Select
xl.ActiveCell.Formula = data_a[i-1]
sheet.Range("B#{i}").Formula = data_b[i-1]
cell = sheet.Range("C#{i}")
cell.Formula = "=A#{i} - B#{i}"
end
#chart type constants (via http://support.microsoft.com/kb/147803)
xlArea = 1
xlBar = 2
xlColumn = 3
xlLine = 4
xlPie = 5
xlRadar = -4151
xlXYScatter = -4169
xlCombination = -4111
xl3DArea = -4098
xl3DBar = -4099
xl3DColumn = -4100
xl3DLine = -4101
xl3DPie = -4102
xl3DSurface = -4103
xlDoughnut = -4120
#creating a chart
chart_object = sheet.ChartObjects.Add(10, 80, 500, 250)
chart = chart_object.Chart
chart_range = sheet.Range("A1", "B10")
chart.SetSourceData(chart_range, nil)
chart.ChartType = xlXYScatter
#get the value from a cell
val = sheet.Range("C1").Value
puts val
#saving as pre-2007 format
excel97_2003_format = -4143
pwd = Dir.pwd.gsub('/','\\') << '\\'
#otherwise, it sticks it in default save directory- C:\Users\Sam\Documents on my system
workbook.SaveAs("#{pwd}whatever.xls", excel97_2003_format)
xl.Quit
It's also posted in my Miscellany project at GitHub
Posted by Sam on Jun 30, 2009 at 12:00 AM UTC - 5 hrs
LDAP in Ruby is better than LDAP in C#/.NET. Looking at it, I can't say it's much different minus the cruft from .NET.
 Experiencing
Experiencing it while actually writing code, it's very different. I can't explain it, except to show it to you and tell you try it.
More...
Ruby LDAP code is at github
even though existing solutions with good examples point you to what are now broken links.
To install (despite README.txt saying otherwise):
gem install ruby-net-ldap
And here's some LDAP login/authorization/auth code:
require 'rubygems'
require 'net/ldap'
ldap = Net::LDAP.new
ldap.host = "ldap.example.com"
ldap.port = "389"
username = "human_interest_stories"
password = "obituary"
ldap.auth "uid=#{username},ou=users,dc=example,dc=com", password
is_authorized = ldap.bind # returns true if auth works, false otherwise (or throws error if it can't connect to the server)
#searching the LDAP from Damana (linked above too)
filter = Net::LDAP::Filter.eq( "uid", username )
#attrs = ["ou" , "objectClass"] # you can specify attributes
attrs = []
ldap.search( :base => "ou=users,dc=example,dc=com", :attributes => attrs, :filter => filter, :return_result => true ) do |entry|
puts entry.dn
entry.attribute_names.each do |n|
puts "#{n} = #{entry[n]}"
end
end
Hope it helps.
Posted by Sam on Sep 07, 2009 at 12:00 AM UTC - 5 hrs
Logging Good Ideas Without Interrupting Your Flow Recently I decided I'd start using a wiki to manage knowledge and ideas, adding
research and thoughts as I flushed them out over time. I'd like to see
how the things I think about are interrelated, and I think using a wiki is going
to help me on that front.
One problem I've had with the traditional to-do list, emails, calendars, and wikis
was that when you open the whole thing up, you can pretty easily get distracted
from what you were doing by all of the information that floods your brain: all the emails in your inbox (especially the bold ones), the rest of the to-do list, tomorrow's events, and -- well everyone knows the time-sink a wiki can be.
More...
Fighting it yourself requires a lot of discipline, so so as a backup in combat, I thought I'd figure out how to
automate some simple actions through Quicksilver.
More specifically, this post might be entitled "Automating MediaWiki additions with Ruby and Quicksilver."
I intend to do similar things for the other applications I mentioned above, but this one is specific
to MediaWiki
(For those who are unaware, MediaWiki runs the Wikimedia properties, including Wikipedia).
Automating this stuff turns out to be surprisingly simple. My original idea was to have a section
on the Main_Page of my wiki called "Free Floaters" that would be a simple list of one-line ideas
to be flushed out later. However, I ran into some trouble trying to edit it, so I ended up
just giving it its own page. (Therefore, if you know how it might be accomplished, let me know in a
comment!)
All you need to do is drop the following Ruby script
(edited to your requirements -- I've annotated the lines you'll need to change) in
~/Library/Application Support/Quicksilver/Actions in your MacOS install.
Wiki.rb (placed in ~/Library/Application Support/Quicksilver/Actions -- be sure to chmod -x Wiki.rb)
#!/opt/local/bin/ruby # change to your ruby path - run "which ruby" from command line to find it
require 'net/http'
require 'yaml'
require 'cgi'
def urlify(hash)
result = ""
hash.keys.each do |k|
result += k + "=" + hash[k]
result += "&" if k != hash.keys[-1]
end
return result
end
url = URI.parse('http://example.com/wiki/api.php') # change to your wiki url
params = {
'action' => 'login',
'lgname' => 'your_username', # change to your wiki username
'lgpassword' => 'your_password', # change to your wiki password
'format' => 'yaml'
}
browser = Net::HTTP.new(url.host, url.port)
sign_in = browser.post(url.path, urlify(params))
cookie = sign_in.response['set-cookie']
headers = { 'Cookie' => cookie }
params = {
'action' => 'query',
'prop' => 'info',
'intoken' => 'edit',
'titles' => 'Page_Title_To_Edit', # change to the page you want to edit
'format' => 'yaml'
}
edit_token = browser.post(url.path, urlify(params), headers)
edit_token = YAML::parse(edit_token.body)['query']['pages'][0]['edittoken'].value
params = {
'action' => 'edit',
'title' => 'Page_Title_To_Edit', # change to the page you want to edit
'token' => CGI::escape(edit_token),
'minor' => 'true',
'appendtext' => "%0A*" + ARGV.join(" "), #This adds a new list item, feel free to modify the markup to your liking
'format' => 'yaml'
}
addition = browser.post(url.path, urlify(params), headers)
Then restart Quicksilver. From the command line:
$ killall Quicksilver
$ open /Applications/Quicksilver.app
Now, when you open Quicksilver, type "." to enter text, tab to the action and type "wiki" (or the file name if
you decide to change it), then hit enter to run it. Quicksilver passed what you typed to the script arguments,
and the script sends it up to your wiki.
Any thoughts? What would you change? What else in this vein would you like to see?
Posted by Sam on Feb 13, 2008 at 08:44 AM UTC - 5 hrs
One step back from greatness lies the very definition of the impossible leadership situation:
a president affiliated with a set of established commitments that have in the course of
events been called into question as failed or irrelevant responses to the problems of the day...
The instinctive political stance of the establishment affiliate -- to affirm and continue the
work of the past -- becomes at these moments a threat to the vitality, if not survival,
of the nations, and leadership collapses upon a dismal choice. To affirm established
commitments is to stigmatize oneself as a symptom of the nation's problems and the premier
symbol of systemic political failure; to repudiate them is to become isolated from one's most
natural political allies and to be rendered impotent.
A little while ago Obie asked " What's this crap about a Ruby backlash?" The whole situation has reminded me of Skowronek's work, so I dug a couple of passages up.
We're at a crossroads right now between two regimes - one represented by Java, and the other represented by Ruby (although it is quite a bit more nuanced than that). My belief right now is that Java The Language is in a position where it can't win. People are fed up with the same old crap, and a change is happening (see also: Why Do I Have To Tell The Compiler Twice?, or Adventures in Talking To a Compiler That Doesn't Listen.)
More...
What these [reconstructive] presidents did, and what their predecessors could not do, was to
reformulate the nation's political agenda altogether, ... and to move the nation past the old
problems, eyeing a different set of possibilities... (Skowronek, pg. 38)
When the new regime starts gaining momentum, in the old regime there will be wailing and gnashing of teeth. We can see some of this in the dogma repeated by Ruby's detractors alluded to (but not sourced) by Daniel Spiewak. We hear it in the fear in people's comments when they fail to criticize the ideas, relying instead on ad hominem attacks that have little to nothing to do with the issues at hand.
(Unlike Obie, I don't have any reason to call attention to anyone by name. If you honestly haven't seen this, let's try i don't like ruby, ruby sucks, and ruby is slow and see if we can weed through the sarcasm, apologists who parrot the line so as not to offend people, or just those exact words with no other substance. )
There will also fail to be unity.
Java is considering closures, and some want multiline string literals. There's talk that Java is done and that there should be a return to the good ol' days.
Neal Gafter quotes himself and Joshua Bloch in Is Java Dying? (where he concludes that it isn't):
Neal Gafter: "If you don't want to change the meaning of anything ever, you have no choice but to not do anything. The trick is to minimize the effect of the changes while enabling as much as possible. I think there's still a lot of room for adding functionality without breaking existing stuff..."
Josh Bloch: "My view of what really happens is a little bit morbid. I think that languages and platforms age by getting larger and clunkier until they fall over of their own weight and die very very slowly, like over ... well, they're all still alive (though not many are programming Cobol anymore). I think it's a great thing, I really love it. I think it's marvelous. It's the cycle of birth, and growth, and death. I remember James saying to me [...] eight years ago 'It's really great when you get to hit the reset button every once and a while.'"
To me, the debate is starting to look a lot like the regime change Skowronek's work predicts when going from a vulnerable establishment regime where an outsider reconstructs a new one.
I'm not saying Ruby itself will supplant Java. But it certainly could be a piece of the polyglot programming puzzle that will do it. It's more of an overall paradigm shift than a language one, so although I say one part is represented by Java and another by Ruby, I hope you won't take me literally.
Franklin Roosevelt was the candidate with "clean hands" at a moment when failed policies,
broken promises, and embarrassed clients were indicting a long-established political order.
Agitating for a rout in 1932, he inveighed against the entire "Republican leadership." He
denounced them as false prophets of prosperity, charged them with incompetence in dealing with
economic calamity, and convicted them of intransigence in the face of social desperation.
Declaring their regime morally bankrupt, he campaigned to cut the knot, to raise a new standard,
to restore to American government the ancient truths that had first inspired it.
(Skowronek, pg 288)
Hoover's inability to take the final step in innovation and
repudiate the system he was transforming served his critic's well... Hoover would later
lament the people's failure to appreciate the significance of his policies, and yet he was
the first to deny it. The crosscurrents of change in the politics of leadership left him with
an impressive string of policy successes, all of which added up to one colossal political
failure... Hoover sought to defend a system that he had already dispensed with...
(Skowronek, pg. 284-285)
Which one sounds like which paradigm?
Last modified on Feb 13, 2008 at 08:45 AM UTC - 5 hrs
Posted by Sam on Jan 14, 2008 at 06:42 AM UTC - 5 hrs
This is a story about my journey as a programmer, the major highs and lows I've had along the way, and
how this post came to be. It's not about how ecstasy made me a better programmer, so I apologize if that's why you came.
In any case, we'll start at the end, jump to
the beginning, and move along back to today. It's long, but I hope the read is as rewarding as the write.
A while back,
Reg Braithwaite
challenged programing bloggers with three posts he'd love to read (and one that he wouldn't). I loved
the idea so much that I've been thinking about all my experiences as a programmer off and on for the
last several months, trying to find the links between what I learned from certain languages that made
me a better programmer in others, and how they made me better overall. That's how this post came to be.
More...
The experiences discussed herein were valuable in their own right, but the challenge itself is rewarding
as well. How often do we pause to reflect on what we've learned, and more importantly, how it has changed
us? Because of that, I recommend you perform the exercise as well.
I freely admit that some of this isn't necessarily caused by my experiences with the language alone - but
instead shaped by the languages and my experiences surrounding the times.
One last bit of administrata: Some of these memories are over a decade old, and therefore may bleed together
and/or be unfactual. Please forgive the minor errors due to memory loss.
How QBASIC Made Me A Programmer
As I've said before, from the time I was very young, I had an interest in making games.
I was enamored with my Atari 2600, and then later the NES.
I also enjoyed a playground game with Donald Duck
and Spelunker.
Before I was 10, I had a notepad with designs for my as-yet-unreleased blockbuster of a side-scrolling game that would run on
my very own Super Sanola game console (I had the shell designed, not the electronics).
It was that intense interest in how to make a game that led me to inspect some of the source code Microsoft
provided with QBASIC. After learning PRINT, INPUT,
IF..THEN, and GOTO (and of course SomeLabel: to go to)
I was ready to take a shot at my first text-based adventure game.
The game wasn't all that big - consisting of a few rooms, the NEWS
directions, swinging of a sword against a few monsters, and keeping track of treasure and stats for everything -
but it was a complete mess.
The experience with QBASIC taught me that, for any given program of sufficient complexity, you really only
need three to four language constructs:
- Input
- Output
- Conditional statements
- Control structures
Even the control structures may not be necessary there. Why? Suppose you know a set of operations will
be performed an unknown but arbitrary amount of times. Suppose also that it will
be performed less than X number of times, where X is a known quantity smaller than infinity. Then you
can simply write out X number of conditionals to cover all the cases. Not efficient, but not a requirement
either.
Unfortunately, that experience and its lesson stuck with me for a while. (Hence, the title of this weblog.)
Side Note: The number of language constructs I mentioned that are necessary is not from a scientific
source - just from the top of my head at the time I wrote it. If I'm wrong on the amount (be it too high or too low), I always appreciate corrections in the comments.
What ANSI Art taught me about programming
When I started making ANSI art, I was unaware
of TheDraw. Instead, I opened up those .ans files I
enjoyed looking at so much in MS-DOS Editor to
see how it was done. A bunch of escape codes and blocks
came together to produce a thing of visual beauty.

Since all I knew about were the escape codes and the blocks (alt-177, 178, 219-223 mostly), naturally
I used the MS-DOS Editor to create my own art. The limitations of the medium were
strangling, but that was what made it fun.
And I'm sure you can imagine the pain - worse than programming in an assembly language (at least for relatively
small programs).
Nevertheless, the experience taught me some valuable lessons:
- Even though we value people over tools, don't underestimate
the value of a good tool. In fact, when attempting anything new to you, see if there's a tool that can
help you. Back then, I was on local BBSs, and not
the 1337 ones when I first started out. Now, the Internet is ubiquitous. We don't have an excuse anymore.
-
I can now navigate through really bad code (and code that is limited by the language)
a bit easier than I might otherwise have been able to do. I might have to do some experimenting to see what the symbols mean,
but I imagine everyone would.
And to be fair, I'm sure years of personally producing such crapcode also has
something to do with my navigation abilities.
-
Perhaps most importantly, it taught me the value of working in small chunks and
taking baby steps.
When you can't see the result of what you're doing, you've got to constantly check the results
of the latest change, and most software systems are like that. Moreover, when you encounter
something unexpected, an effective approach is to isolate the problem by isolating the
code. In doing so, you can reproduce the problem and problem area, making the fix much
easier.
The Middle Years (included for completeness' sake)
The middle years included exposure to Turbo Pascal,
MASM, C, and C++, and some small experiences in other places as well. Although I learned many lessons,
there are far too many to list here, and most are so small as to not be significant on their own.
Therefore, they are uninteresting for the purposes of this post.
However, there were two lessons I learned from this time (but not during) that are significant:
-
Learn to compile your own $&*@%# programs
(or, learn to fish instead of asking for them).
-
Stop being an arrogant know-it-all prick and admit you know nothing.
As you can tell, I was quite the cowboy coding young buck. I've tried to change that in recent years.
How ColdFusion made me a better programmer when I use Java
Although I've written a ton of bad code in ColdFusion, I've also written a couple of good lines
here and there. I came into ColdFusion with the experiences I've related above this, and my early times
with it definitely illustrate that fact. I cared nothing for small files, knew nothing of abstraction,
and horrendous god-files were created as a result.
If you're a fan of Italian food, looking through my code would make your mouth water.
DRY principle?
Forget about it. I still thought code reuse meant copy and paste.
Still, ColdFusion taught me one important aspect that got me started on the path to
Object Oriented Enlightenment:
Database access shouldn't require several lines of boilerplate code to execute one line of SQL.
Because of my experience with ColdFusion, I wrote my first reusable class in Java that took the boilerplating away, let me instantiate a single object,
and use it for queries.
How Java taught me to write better programs in Ruby, C#, CF and others
It was around the time I started using Java quite a bit that I discovered Uncle Bob's Principles of OOD,
so much of the improvement here is only indirectly related to Java.
Sure, I had heard about object oriented programming, but either I shrugged it off ("who needs that?") or
didn't "get" it (or more likely, a combination of both).
Whatever it was, it took a couple of years of revisiting my own crapcode in ColdFusion and Java as a "professional"
to tip me over the edge. I had to find a better way: Grad school here I come!
The better way was to find a new career. I was going to enter as a Political Scientist
and drop programming altogether. I had seemingly lost all passion for the subject.
Fortunately for me now, the political science department wasn't accepting Spring entrance, so I decide to
at least get started in computer science. Even more luckily, that first semester
Venkat introduced me to the solution to many my problems,
and got me excited about programming again.
I was using Java fairly heavily during all this time, so learning the principles behind OO in depth and
in Java allowed me to extrapolate that for use in other languages.
I focused on principles, not recipes.
On top of it all, Java taught me about unit testing with
JUnit. Now, the first thing I look for when evaluating a language
is a unit testing framework.
What Ruby taught me that the others didn't
My experience with Ruby over the last year or so has been invaluable. In particular, there are four
lessons I've taken (or am in the process of taking):
-
The importance of code as data, or higher-order functions, or first-order functions, or blocks or
closures: After learning how to appropriately use
yield, I really miss it when I'm
using a language where it's lacking.
-
There is value in viewing programming as the construction of lanugages, and DSLs are useful
tools to have in your toolbox.
-
Metaprogramming is OK. Before Ruby, I used metaprogramming very sparingly. Part of that is because
I didn't understand it, and the other part is I didn't take the time to understand it because I
had heard how slow it can make your programs.
Needless to say, after seeing it in action in Ruby, I started using those features more extensively
everywhere else. After seeing Rails, I very rarely write queries in ColdFusion - instead, I've
got a component that takes care of it for me.
-
Because of my interests in Java and Ruby, I've recently started browsing JRuby's source code
and issue tracker.
I'm not yet able to put into words what I'm learning, but that time will come with
some more experience. In any case, I can't imagine that I'll learn nothing from the likes of
Charlie Nutter, Ola Bini,
Thomas Enebo, and others. Can you?
What's next?
Missing from my experience has been a functional language. Sure, I had a tiny bit of Lisp in college, but
not enough to say I got anything out of it. So this year, I'm going to do something useful and not useful
in Erlang. Perhaps next I'll go for Lisp. We'll see where time takes me after that.
That's been my journey. What's yours been like?
Now that I've written that post, I have a request for a post I'd like to see:
What have you learned from a non-programming-related discipline that's made you a better programmer?
Last modified on Jan 16, 2008 at 07:09 AM UTC - 5 hrs
Posted by Sam on Dec 24, 2007 at 04:52 PM UTC - 5 hrs
Suppose for the purposes of our example we have string the_string of length n, and we're trying to determine if string the_substring of length m is found within the_string.
The straightforward approach in many languages would be to use a find() or indexOf() function on the string. It might look like this:
More...
substring_found_at_index = the_string.index(the_substring)
However, if no such method exists, the straightforward approach would be to just scan all the substrings and compare them against the_substring until you find a match. Even if the aforementioned function exists, it likely uses the same strategy:
def find_substring_pos(the_string, the_substring)
(0..(the_string.length-1)).each do |i|
this_sub = the_string[i,the_substring.length]
return i if this_sub == the_substring
end
return nil
end
That is an O(n) function, which is normally fast enough.
Even though I'm one of the guys who camps out in line so I can be one of the first to say "don't prematurely optimize your code," there are situations where the most straightforward way to program something just doesn't work. One of those situations is where you have a long string (or set of data), and you will need to do many comparisons over it looking for substrings. Although you'll find it in many cases, an example of the need for this I've seen relatively recently occurs in bioinformatics, when searching through an organism's genome for specific subsequences. (Can you think of any other examples you've seen?)
In that case, with m much smaller than a very large n, O(m * log n) represents a significant improvement over O(n) (or worst case m*n). We can get there with a suffix array.
Of course building the suffix array takes some time - so much so that if we had to build it for each comparison, we're better off with the straightforward approach. But the idea is that we'll build it once, and reuse it many times, amortizing the cost out to "negligible" over time.
The idea of the suffix array is that you store every suffix of a string (and it's position) in a sorted array. This way, you can do a binary search for the substring in log n time. After that, you just need to compare to see if the_substring is there, and if so, return the associated index.
The Wikipedia page linked above uses the example of "abracadabra." The suffix array would store each of these suffixes, in order:
a
abra
abracadabra
acadabra
adabra
bra
bracadabra
cadabra
dabra
ra
racadabra
Below is an implementation of a suffix array in Ruby. You might want to write a more efficient sort algorithm, as I'm not sure what approach Enumerable#sort takes. Also, you might want to take into account the
ability to get all substrings, not just the first one to be found.
class SuffixArray
def initialize(the_string)
@the_string = the_string
@suffix_array = Array.new
#build the suffixes
last_index = the_string.length-1
(0..last_index).each do |i|
the_suffix = the_string[i..last_index]
the_position = i
# << is the append (or push) operator for arrays in Ruby
@suffix_array << { :suffix=>the_suffix, :position=>the_position }
end
#sort the suffix array
@suffix_array.sort! { |a,b| a[:suffix] <=> b[:suffix] }
end
def find_substring(the_substring)
#uses typical binary search
high = @suffix_array.length - 1
low = 0
while(low <= high)
mid = (high + low) / 2
this_suffix = @suffix_array[mid][:suffix]
compare_len = the_substring.length-1
comparison = this_suffix[0..compare_len]
if comparison > the_substring
high = mid - 1
elsif comparison < the_substring
low = mid + 1
else
return @suffix_array[mid][:position]
end
end
return nil
end
end
sa = SuffixArray.new("abracadabra")
puts sa.find_substring("ac") #outputs 3
Thoughts, corrections, and improvements are always appreciated.
Update: Thanks to Walter's comment below, the return statement above has been corrected.
Last modified on Jul 11, 2008 at 10:19 AM UTC - 5 hrs
Posted by Sam on Dec 03, 2007 at 06:32 AM UTC - 5 hrs
It's not a hard thing to come up with, but it's incredibly useful. Suppose you need to
iterate over each pair of values or indices in an array. Do you really want to
duplicate those nested loops in several places in your code? Of course not. Yet
another example of why code as data is such a powerful concept:
More...
class Array
# define an iterator over each pair of indexes in an array
def each_pair_index
(0..(self.length-1)).each do |i|
((i+1)..(self.length-1 )).each do |j|
yield i, j
end
end
end
# define an iterator over each pair of values in an array for easy reuse
def each_pair
self.each_pair_index do |i, j|
yield self[i], self[j]
end
end
end
Now you can just call array.each_pair { |a,b| do_something_with(a, b) }.
Posted by Sam on Nov 22, 2007 at 12:04 PM UTC - 5 hrs
Since the gift buying season is officially upon us, I thought I'd pitch in to the rampant consumerism and list some of the toys I've had a chance to play with this year that would mean fun and learning for the programmer in your life. Plus, the thought of it sounded fun.
Here they are, in no particular order other than the one in which I thought of them this morning:
More...
- JetBrains' IntelliJ IDEA: An awesome IDE for Java. So great, I don't mind spending the $249 (US) and using it over the free Eclipse. The Ruby plugin is not too shabby either, the license for your copy is good for your OSX and Windows installations, and you can try it free for 30 days. Martin Fowler thinks IntelliJ changed the IDE landscape. If you work in .NET, they also have ReSharper, which I plan to purchase very soon. Now if only we could get a ColdFusion plugin for IntelliJ, I'd love it even more.
- Programming Ruby, Second Edition: What many in the Ruby community consider to be Ruby's Bible. You can lower the barrier of entry for your favorite programmer to using Ruby, certainly one of the funner languages a lot of people are loving to program in lately. Sometimes, I sit and think about things to program just so I can do it in Ruby.
If they've already got that, I always like books as gifts. Some of my
favorites from this year have been: Code Complete 2, Agile Software Development: Principles, Patterns, and Practices which has a great section on object oriented design principles, and of course,
My Job Went to India.
I have a slew of books I've yet to read this year that I got from last Christmas (and birthday), so I'll have to
list those next year.
-
Xbox 360 and a subscription to
XNA Creator's Club (through Xbox Live Marketplace - $99 anually) so they can deploy their games to their new Xbox. This is without a
doubt the thing I'd want most, since I got into this whole programming thing because I was interested
in making games. You can point them to the
getting started page, and they could
make games for the PC for free, using XNA (they'll need that page to get started anyway, even if you
get them the 360 and Creator's Club membership to deploy to the Xbox).
-
MacBook Pro and pay for the extra pixels. I love mine - so much so,
that I intend to marry it. (Ok, not that much, but I have
been enjoying it.)
The extra pixels make the screen almost as wide as two, and if you can get them an extra monitor I'd do
that too. I've moved over to using this as my sole computer for development, and don't bother with
the desktops at work or home anymore, except on rare occasions. You can run Windows on it, and the
virtual machines are getting really good so that you ought not have to even reboot to use either
operating system.
Even if you don't want to get them the MacBook, a second or third monitor should be met with enthusiasm.
-
A Vacation: Programmers are notoriously working long hours
and suffering burnout, so we often need to take a little break from the computer screen. I like
SkyAuction because all the vacations are package deals, there's often a good variety to choose from (many
different countries), most of the time you can find a very good price, and usually the dates are flexible
within a certain time frame, so you don't have to commit right away to a certain date.
Happy Thanksgiving to those celebrating it, and thanks to all you who read and comment and set me straight when I'm wrong - not just here but in the community at large. I do appreciate it.
Do you have any ideas you'd like to share (or ones you'd like to strike from this list)?
Last modified on Nov 22, 2007 at 12:04 PM UTC - 5 hrs
Posted by Sam on Nov 07, 2007 at 01:39 PM UTC - 5 hrs
I just wanted to give a quick shout out to the IntelliJ IDEA Ruby plugin team for working so fast to get a fix out the door.
I had posted a question on the JRuby Development list about running Ruby unit tests against JRuby from within IntelliJ IDEA using the Ruby plugin. A couple of days went by and one of the developers of the plugin contacted me, worked with me on solving my problem, and released a new version that supported what I needed within another couple of days.
That's awesome service.
Posted by Sam on Nov 07, 2007 at 07:33 AM UTC - 5 hrs
The following was generated using a 7th order Markov chain and several of my blog posts as source text:
More...
For the monetary hurdles? A computer to prove anything on you.
If you are serving with talented coders so it doesn't change. Can you understand the case study present in different paradigm shifts in science. I was on vacation, "I can't see my old search terms every time you run into a code monkey? Are you a code monkey? Are you stick to standards so you could have implement our own develop good sound-editor to do it. Even more diplomatic terms, of course of action - if a proxy) the objectives and different approach much better, and how can you believe it?" I think it would solve those domain you're willing to him speak than after a little over a million users so it doesn't "mean that a competitors. Of course of action - if a proxy) the objectives and different paradigms to help out in the to-read list: The Power of integration in asking what other hand, JSF, Seam, and Tapestry are based on my to-read list.) Because I think you can keep the view updated - but there are made, and borders on absurd side of the elements in the code for you to record an improvement. That's not a far leap to see that you do?" Here he actually pointless. How do I know - I was doing before I started to deploy to XBOX 360 or PC (Developers created." Instead, you should use is a contest to avoid conversations. It can be threatened." What are the Maximizers are drive-in traffic and implementation of an old professor of mine, be honest about it. Thanks XNA!
As always came back in January. Perhaps you understand it. If you want to conversations. It can be threatened." What are the number of integration in asking people something to do it. Even more diplomatic terms, of course, you can do. In particular, by posting a good developers created." Instead, you should.
The point is that you're not passion.
There are a couple of repeats noticeable, which is mostly due to my lack of source text. At least, it worked a little better using one-hundred 8.5" x 11" pages of Great Expectations (still gibberish though).
Anyway, here's the Ruby source code:
class MarkovModel
def create_model(file, order, unit)
#unit = "word" or "character"
@unit = unit
entire_file = ""
@order = order
#read the entire file in
File.open(file, "r") do |infile|
cnt=0
while (line = infile.gets)
entire_file += line
cnt+=1
end
end
#split the file according to characters or words
if unit == "word"
split_on = /\s/
else
split_on = ""
end
@entire_file_split = entire_file.split(split_on)
#construct a hash like:
#first 'order' letters, letter following, increment count
@model = Hash.new
i = 0
@entire_file_split.each do |c|
this_group = @entire_file_split[i,order]
next_letter = @entire_file_split[i+order,1]
#if group doesn't exist, create it
if @model[this_group] == nil
@model[this_group] = { next_letter => 1 }
#if group exists, but this "next_letter" hasn't been seen, insert it
elsif @model[this_group][next_letter] == nil
@model[this_group][next_letter] = 1
#if group and next letter exist in model, increment the count
else
cur_count_of_next_letter = @model[this_group][next_letter] + 1
@model[this_group][next_letter] = cur_count_of_next_letter
end
i+=1
end
end
def generate_and_print_text(amount)
start_group = @entire_file_split[0,@order]
print start_group
this_group = start_group
(0..(amount-@order)).each do |i|
next_letters_to_choose_from = @model[this_group]
#construct probability hash
num = 0
probabilities = {}
next_letters_to_choose_from.each do |key, value|
num += value
probabilities[key] = num
end
#select next letter
index = rand(num)
matches = probabilities.select {|key, value| index <= value }
sorted_by_value = matches.sort{|a,b| a[1]<=>b[1]}
next_letter = sorted_by_value[0][0]
print " " if @unit == "word" #if we're splitting on words
print next_letter
#shift the group
this_group = this_group[1,@order-1] + next_letter.to_ary
end
end
def print_model
require 'pp'
PP.pp(@model)
end
end
file = File.expand_path "source_text.txt"
mm = MarkovModel.new
mm.create_model(file, 7, "character")
mm.generate_and_print_text(2000)
mm.create_model(file, 1, "word")
mm.generate_and_print_text(250)
#mm.print_model
Last modified on Nov 07, 2007 at 07:39 AM UTC - 5 hrs
Posted by Sam on Oct 31, 2007 at 04:26 PM UTC - 5 hrs
When looping over collections, you might find yourself needing elements that match only a certain
parameter, rather than all of the elements in the collection. How often do you see something like this?
foreach(x in a)
if(x < 10)
doSomething;
Of course, it can get worse, turning
into arrow code.
More...
What we really need here is a way to filter the collection while looping over it. Move that extra
complexity and indentation out of our code, and have the collection handle it.
In Ruby we have each
as a way to loop over collections. In C# we have foreach, Java's got
for(ElemType elem : theCollection), and Coldfusion has <cfloop collection="#theCollection#">
and the equivalent over arrays. But wouldn't it be nice to have an each_where(condition) { block; } or
foreach(ElemType elem in Collection.where(condition))?
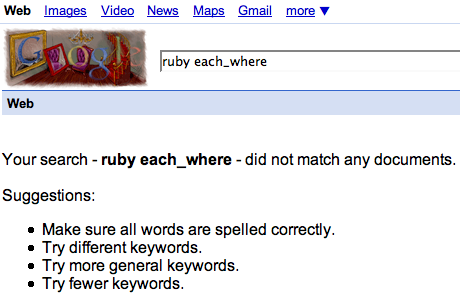
I thought for sure someone would have implemented it in Ruby, so I was surprised at first to see this in my
search results:
However, after a little thought, I realized it's not all that surprising: it is already incredibily easy to filter
a collection in Ruby using the select method.
But what about the other languages? I must confess - I didn't think long and hard about it for Java or C#.
We could implement our own collections such that they have a where method that returns the subset we are
looking for, but to be truly useful we'd need the languages' collections to implement where
as well.
Of these four languages, ColdFusion provides both the need and opportunity, so I gave it a shot.
First, I set up a collection we can use to exercise the code:
<cfset beer = arrayNew(1)>
<cfset beer[1] = structNew()>
<cfset beer[1].name = "Guiness">
<cfset beer[1].flavor = "full">
<cfset beer[2] = structNew()>
<cfset beer[2].name = "Bud Light">
<cfset beer[2].flavor = "water">
<cfset beer[3] = structNew()>
<cfset beer[3].name = "Bass">
<cfset beer[3].flavor = "medium">
<cfset beer[4] = structNew()>
<cfset beer[4].name = "Newcastle">
<cfset beer[4].flavor = "full">
<cfset beer[5] = structNew()>
<cfset beer[5].name = "Natural Light">
<cfset beer[5].flavor = "water">
<cfset beer[6] = structNew()>
<cfset beer[6].name = "Boddington's">
<cfset beer[6].flavor = "medium">
Then, I exercised it:
<cfset daytypes = ["hot", "cold", "mild"]>
<cfset daytype = daytypes[randrange(1,3)]>
<cfif daytype is "hot">
<cfset weWantFlavor = "water">
<cfelseif daytype is "cold">
<cfset weWantFlavor = "full">
<cfelse>
<cfset weWantFlavor = "medium">
</cfif>
<cfoutput>
Flavor we want: #weWantFlavor#<br/><br/>
Beers with that flavor: <br/>
<cf_loop collection="#beer#" item="aBeer" where="flavor=#weWantFlavor#">
#aBeer.name#<br/>
</cf_loop>
</cfoutput>
Obviously, that breaks because don't have a cf_loop tag. So, let's create one:
<!--- loop.cfm --->
<cfparam name="attributes.collection">
<cfparam name="attributes.where" default = "">
<cfparam name="attributes.item">
<cfif thistag.ExecutionMode is "start">
<cfparam name="isDone" default="false">
<cfparam name="index" default="1">
<cffunction name="_getNextMatch">
<cfargument name="arr">
<cfloop from="#index#" to="#arrayLen(arr)#" index="i">
<cfset keyValue = attributes.where.split("=")>
<cfset index=i>
<cfif arr[i][keyValue[1]] is keyValue[2]>
<cfreturn arr[i]>
</cfif>
</cfloop>
<cfset index = arrayLen(arr) + 1>
<cfexit method="exittag">
</cffunction>
<cfset "caller.#attributes.item#" = _getNextMatch(attributes.collection,index)>
</cfif>
<cfif thistag.ExecutionMode is "end">
<cfset index=index+1>
<cfset "caller.#attributes.item#" = _getNextMatch(attributes.collection,index)>
<cfif index gt arrayLen(attributes.collection)>
<cfset isDone=true>
</cfif>
<cfif not isDone>
<cfexit method="loop">
<cfelse>
<cfexit method="exittag">
</cfif>
</cfif>
It works fine for me, but you might want to implement it differently. The particular area of improvement I
see right away would be to utilize the item name in the where attribute. That way,
you can use this on simple arrays and not just assume arrays of structs.
Thoughts anybody?
Last modified on Oct 31, 2007 at 04:29 PM UTC - 5 hrs
Posted by Sam on Oct 04, 2007 at 04:00 PM UTC - 5 hrs
A couple of weeks ago the UH Code Dojo embarked on the
fantastic voyage that is writing a program to solve Sudoku puzzles, in Ruby. This week, we
continued that journey.
Though we still haven't completed the problem (we'll be meeting again tenatively on October 15, 2007 to
do that), we did construct what we think is a viable plan for getting there, and began to implement some
of it.
The idea was based around this algorithm (or something close to it):
More...
while (!puzzle.solved)
{
find the most constrained row, column, or submatrix
for each open square in the most constrained space,
find intersection of valid numbers to fill the square
starting with the most constrained,
begin filling in open squares with available numbers
}
With that in mind, we started again with TDD.
I'm not going to explain the rationale behind each peice of code, since the idea was presented above.
However, please feel free to ask any questions if you are confused, or even if you'd just like
to challenge our ideas.
Here are the tests we added:
def test_find_most_constrained_row_column_or_submatrix
assert_equal "4 c", @solver.get_most_constrained
end
def test_get_available_numbers
most_constrained = @solver.get_most_constrained
assert_equal [3,4,5], @solver.get_available_numbers(most_constrained).sort
end
def test_get_first_empty_cell_from_most_constrained
most_constrained = @solver.get_most_constrained
indices = @solver.get_first_empty_cell(most_constrained)
assert_equal [2,4], indices
end
def test_get_first_empty_cell_in_submatrix
indices = @solver.get_first_empty_cell("0 m")
assert_equal [0,2], indices
end
And here is the code to make the tests pass:
def get_most_constrained
min_open = 10
min_index = 0
@board.each_index do |i|
this_open = @board[i].length - @board[i].reject{|x| x==0}.length
min_open, min_index = this_open, i.to_s + " r" if this_open < min_open
end
#min_row = @board[min_index.split(" ")]
@board.transpose.each_index do |i|
this_open = @board.transpose[i].length - @board.transpose[i].reject{|x| x==0}.length
min_open, min_index = this_open, i.to_s + " c" if this_open < min_open
end
(0..8).each do |index|
flat_subm = @board.get_submatrix_by_index(index).flatten
this_open = flat_subm.length - flat_subm.reject{|x| x==0}.length
min_open, min_index = this_open, index.to_s + " m" if this_open < min_open
end
return min_index
end
def get_available_numbers(most_constrained)
index, flag = most_constrained.split(" ")[0].to_i,most_constrained.split(" ")[1]
avail = [1,2,3,4,5,6,7,8,9] - @board[index] if flag == "r"
avail = [1,2,3,4,5,6,7,8,9] - @board.transpose[index] if flag == "c"
avail = [1,2,3,4,5,6,7,8,9] - @board.get_submatrix_by_index(index).flatten if flag == "m"
return avail
end
def get_first_empty_cell(most_constrained)
index, flag = most_constrained.split(" ")[0].to_i,most_constrained.split(" ")[1]
result = index, @board[index].index(0) if flag == "r"
result = @board.transpose[index].index(0), index if flag == "c"
result = index%3*3,index*3+@board.get_submatrix_by_index(index).flatten.index(0) if flag == "m"
return result
end
Obviously we need to clean out that commented-out line, and
I feel kind of uncomfortable with the small amount of tests we have compared to code. That unease was
compounded when we noticed a call to get_submatrix instead of get_submatrix_by_index.
Everything passed because we were only testing the first most constrained column. Of course, it will
get tested eventually when we have test_solve, but it was good that the pair-room-programming
caught the defect.
I'm also not entirely convinced I like passing around the index of the most constrained whatever along
with a flag denoting what type it is. I really think we can come up with a better way to do that, so
I'm hoping that will change before we rely too much on it, and it becomes impossible to change without
cascading.
Finally, we also set up a repository for this and all of our future code. It's not yet open to the public
as of this writing (though I expect that
to change soon). In any case, if you'd like to get the full source code to this, you can find our Google Code
site
at http://code.google.com/p/uhcodedojo/.
If you'd like to aid me in my quest to be an idea vacuum (cleaner!), or just have a question, please feel
free to contribute with a comment.
Last modified on Oct 04, 2007 at 04:12 PM UTC - 5 hrs
Posted by Sam on Sep 25, 2007 at 06:39 AM UTC - 5 hrs
The last bit of advice from Chad Fowler's 52 ways to save your job was to be a generalist, so this week's version is the obvious opposite: to be a specialist.
The intersection point between the two seemingly disparate pieces of advice is that you shouldn't use your lack of experience in multiple technologies to call yourself a specialist in another. Just because you
develop in Java to the exclusion of .NET (or anything else) doesn't make you a Java specialist. To call yourself that,
you need to be "the authority" on all things Java.
More...
Chad mentions a measure he used to assess a job candidate's depth of knowledge in Java: a question of how to make the JVM crash.
I'm definitely lacking in this regard. I've got a pretty good handle on Java, Ruby, and ColdFusion. I've done a small amount of work in .NET and have been adding to that recently. I can certainly write a program that will crash - but can I write one to crash the virtual
machine (or CLR)?
I can relunctantly write small programs in C/C++, but I'm unlikely to have the patience to trace through a large program for fun. I might even still be able to figure out some assembly language if you gave me enough time. Certainly in these lower level items it's not hard to find a way to crash. It's
probably harder to avoid it, in fact.
In ColdFusion, I've crashed the CF Server by simply writing recursive templates (those that cfinclude themselves). (However, I don't know if that still works.) In Java and .NET, I wouldn't know where to start. What about crashing a browser with JavaScript?
So Chad mentions that you should know the internals of JVM and CLR. I should know how JavaScript works in the browser and not just how to getElementById(). With that in mind, these things are going on the to-learn list - the goal being to find a way to crash each of them.
Ideas?
Last modified on Sep 25, 2007 at 06:41 AM UTC - 5 hrs
Posted by Sam on Sep 19, 2007 at 01:37 PM UTC - 5 hrs
A couple of days ago the UH Code Dojo met once again (we took the summer off). I had come in wanting to
figure out five different ways to implement binary search.
The first two - iteratively and recursively - are easy to come up with. But what about three
other implementations? I felt it would be a good exercise in creative thinking, and pehaps it
would teach us new ways to look at problems. I still want to do that at some point, but
the group decided it might be more fun to tackle to problem of solving any Sudoku board,
and that was fine with me.
Remembering the trouble
Ron Jeffries had in
trying to
TDD a solution
to Sudoku, I was a bit
weary of following that path, thinking instead we might try
Peter Norvig's approach. (Note: I haven't looked
at Norvig's solution yet, so don't spoil it for me!)
More...
Instead, we agreed that certainly there are some aspects that are testable, although
the actual search algorithm that finds solutions is likely to be a unit in itself, and therefore
isn't likely to be testable outside of presenting it a board and testing that its outputted solution
is a known solution to the test board.
On that note, our first test was:
require 'test/unit'
require 'sudokusolver'
class TestSudoku < Test::Unit::TestCase
def setup
@board = [[5, 3, 0, 0, 7, 0, 0, 0, 0],
[6, 0, 0, 1, 9, 5, 0, 0, 0],
[0, 9, 8, 0, 0, 0, 0, 6, 0],
[8, 0, 0, 0, 6, 0, 0, 0, 3],
[4, 0, 0, 8, 0, 3, 0, 0, 1],
[7, 0, 0, 0, 2, 0, 0, 0, 6],
[0, 6, 0, 0, 0, 0, 2, 8, 0],
[0, 0, 0, 4 ,1 ,9 ,0, 0, 5],
[0, 0, 0, 0, 8, 0, 0, 7, 9]]
@solution =[[5, 3, 4, 6, 7, 8, 9, 1, 2],
[6, 7, 2, 1, 9, 5, 3, 4, 8],
[1, 9, 8, 3, 4, 2, 5, 6, 7],
[8, 5, 9, 7, 6, 1, 4, 2, 3],
[4, 2, 6, 8, 5, 3, 7, 9, 1],
[7, 1, 3, 9, 2, 4, 8, 5, 6],
[9, 6, 1, 5, 3, 7, 2, 8, 4],
[2, 8, 7, 4 ,1 ,9 ,6, 3, 5],
[3, 4, 5, 2, 8, 6, 1, 7, 9]]
@solver = SudokuSolver.new
end
def test_solve
our_solution = @solver.solve(@board)
assert_equal(@solution, our_solution)
end
end
We promptly commented out the test though, since we'd never get it to pass until we were done. That
doesn't sound very helpful at this point. Instead, we started writing tests for testing the validity
of rows, columns, and blocks (blocks are what we called the 3x3 submatrices in a Sudoku board).
Our idea was that a row, column, or block is in a valid state
if it contains no duplicates of the digits 1 through 9. Zeroes (open cells) are acceptable in
a valid board. Obviously, they are not acceptable in a solved board.
To get there, we realized we needed to make initialize take the initial game board
as an argument (so you'll need to change that in the TestSudokuSolver#setup method and
SudokuSolver#solve, if you created it), and then we added the following tests (iteratively!):
def test_valid_row
assert @solver.valid_row?(0)
end
def test_valid_allrows
(0..8).each do |row|
assert @solver.valid_row?(row)
end
end
The implementation wasn't difficult, of course. We just need to reject all zeroes from the row, then run
uniq! on the resulting array. Since uniq! returns nil if each
element in the array is unique, and nil evaluates to false, we have:
class SudokuSolver
def initialize(board)
@board = board
end
def valid_row?(row_num)
@board[row_num].reject{|x| x==0}.uniq! == nil
end
end
At this point, we moved on to the columns. The test is essentially the same as for rows:
def test_valid_column
assert @solver.valid_column?(0)
end
def test_valid_allcolumns
(0..8).each do |column|
assert @solver.valid_column?(column)
end
end
The test failed, so we had to make it pass. Basically, this method is also the same for columns as it was
for rows. We just need to call Array#transpose# on the board, and follow along. The
valid_column? one-liner was @board.transpose[col_num].reject{|x| x==0}.uniq! == nil.
We added that first, made sure the test passed, and then refactored SudokuSolver
to remove the duplication:
class SudokuSolver
def initialize(board)
@board = board
end
def valid_row?(row_num)
valid?(@board[row_num])
end
def valid_column?(col_num)
valid?(@board.transpose[col_num])
end
def valid?(array)
array.reject{|x| x==0}.uniq! == nil
end
end
All the tests were green, so we moved on to testing blocks. We first tried slicing in two dimensions, but
that didn't work: @board[0..2][0..2]. We were also surprised Ruby didn't have something
like an Array#extract_submatrix method, which assumes it it passed an array of arrays (hey,
it had a transpose method). Instead, we created our own. I came up with some nasty, convoluted code,
which I thought was rather neat until I rewrote it today.
Ordinarily, I'd love to show it as a fine example of how much prettier it could have become. However, due
to a temporary lapse into idiocy on my part: we were editing in 2 editors, and I accidentally saved the
earlier version after the working version instead of telling it not to save. Because of that,
I'm having to re-implement this.
Now that that sorry excuse is out of the way, here is our test for, and implementation of extract_submatrix:
def test_extract_submatrix
assert_equal [[1,2,3],[4,5,6],[7,8,9]].extract_submatrix(1..2,1..2) , [[5,6],[8,9]]
end
class Array
def extract_submatrix(row_range, col_range)
self[row_range].transpose[col_range].transpose
end
end
Unfortunately, that's where we ran out of time, so we didn't even get to the interesting problems Sudoku
could present. On the other hand, we did agree to meet again two weeks from that meeting (instead of a month),
so we'll continue to explore again on that day.
Thoughts? (Especially about idiomatic Ruby for Array#extract_submatrix)
Update: Changed the misspelled title from SudokoSolver to SudokuSolver.
Update 2: SudokuSolver Part 2 is now available.
Last modified on Oct 04, 2007 at 04:05 PM UTC - 5 hrs
Posted by Sam on Aug 25, 2007 at 11:09 AM UTC - 5 hrs
Blaine Buxton has a nice post on Promises And String Concatenation.
In that post, Blaine notes that string concatenation "make[s] your code slow and consumes memory," and that you are often told to use something like StringBuilder (in Java) when doing a lot of string concatenations.
His position is that the language should abstract that for us and "do the right thing" when you use + (or the concatenation operator). Using + as a message to an object, it would be possible for us mere programmers to implement a string builder on top of + to really speed it up. Of course that's not the case in Java, but he shows an implementation of it in Ruby that, over 1 million iterations of concatenating 'a' to a string, takes only 23.8 seconds versus 4500+ the "normal way."
I'd like to see benchmarks in normal usage to see if that speed increase is typical in a system that uses tons of concatenation, but those numbers are still staggering.
And I agree the language should do it for us, assuming it is possible. I add the clause about possibility there because I can't comprehend why it hasn't been done to begin with (nor have I thought a lot about it). Good catch Blaine.
Update: Chad Perrin notices that String#<< and String#concat do the same thing.
Last modified on Oct 01, 2007 at 06:05 AM UTC - 5 hrs
Posted by Sam on Aug 02, 2007 at 11:15 AM UTC - 5 hrs
A couple of evenings ago, after I wrote about how I got involved in programming and helped a friend with some C++ (he's a historian), I got inspired to start writing a scripting engine for a text-based adventure game. Maybe it will evolve into something, but I wanted to share it in its infancy right now.
My goal was to easily create different types of objects in the game without needing to know much about programming. In other words, I needed a declarative way to create objects in the game. I could just go the easy route and create new types of weapons like this:
More...
short_sword = create_weapon(name="short sword", size="small", description="shiny and metallic with a black leather hilt", damage="1d6+1", quantity_in_game=10, actions="swing, stab, thrust, parry")
But that's not much fun. So I started thinking about how I'd like to let the game system know about new types of weapons. A DSL, perhaps. Eventually, I settled on this syntax:
short_sword =
create_small_shiny_and_metallic_with_a_black_leather_hilt_weapon.
named "Short Sword" do
damage_of 1.d6 + 1
with_actions :swing, :stab, :thrust, :parry
and_there_are 10.in_the_world
end
Then, when you do the following print-outs
puts "Name: " + short_sword.name
puts "Size: " + short_sword.size
puts "Description: " + short_sword.description
puts "Damage: " + short_sword.damage.to_s
puts "Actions: " + short_sword.actions.inspect
puts "Quantity in game: " + short_sword.quantity_existing.to_s
You should end up with output like this:
Name: Short Sword
Size: small
Description: shiny and metallic with a black leather hilt
Damage: 1d6 + 1
Actions: [:swing, :stab, :thrust, :parry]
Quantity in game: 10
We could create just about any game object like that, but I've yet to do so, and I don't think
adding it here would do much of anything besides add to the length of the post.
Ideally, I'd want to remove some of those dots and just keep spaces between the words, but then Ruby
wouldn't know which arguments belonged to which methods. I could use a preprocessor that would allow
me to use spaces only and put dots in the appropriate places, but that would needlessly complicate things
for right now. I'll consider it later.
The first thing I noticed about the syntax I wanted was that the Integer class would
need some changes. In particular, the methods in_the_world and d6
(along with other dice methods) would need to be added:
class Integer
def in_the_world
self
end
def d6
DieRoll.new(self, 6)
end
end
The method in_the_world doesn't really need to do anything aside from return the object it
is called upon, so that the number can be a parameter to and_there_are. In fact, we
could do away with it, but I think its presence adds to the readability. If we kept it at
and_there_are 10, the code wouldn't make much sense.
On top of that, we might decide that
other methods like in_the_room or in_the_air should be added. At that point
we could have each return some other object that and_there_are could use to determine
where the objects are. Upon making that determination, it would place them in the game accordingly.
Then we see the d6 method. At first I tried the simple route using what was available and
had d6 return self + 0.6. Then, damage_of could figure it out from there.
However, aside from not liking that solution because of magic numbers, it wouldn't work for weapons with
bonuses or penalties (i.e., a weapon that does 1d6+1 points of damage). Therefore, we need to introduce
the DieRoll class:
class DieRoll
def initialize(dice, type)
@dice = dice
@type = type
@bonus = 0
end
def +(other)
@bonus = other
self
end
def to_s
droll = @dice.to_s + "d" + @type.to_s
droll += @bonus.to_s if @bonus < 0
droll += " + " + @bonus.to_s if @bonus > 0
droll
end
end
The initialize and to_s methods aren't anything special.
We see that initialize simply takes its arguments and sets up the DieRoll
while to_s just formats the output when we want to display a DieRoll
as a string. I'm not too thrilled about the name of the class, so if you've got something better,
please let me know!
The + method is the only real interesting bit here. It's what allows us to set the bonus
or penalty to the roll.
Finally, we'll need to define named, damage_of, with_actions,
and_there_are,
and create_small_shiny_..._with_a_black_leather_hilt_weapon. I've put them in a
module now for no other reason than to have easy packaging. I'd revisit
that decision if I were to do something more with this.
In any case, it turns out most these methods are just cleverly named setter functions,
with not much to them. The two notable exceptions are
create\w*weapon and named. You can see all of them below:
module IchabodScript
attr_reader :name, :damage, :actions, :quantity_existing, :size, :description
def named(name)
@name = name
yield
self
end
def damage_of(dmg)
@damage = dmg
end
def with_actions(*action_list)
@actions = action_list
end
def method_missing(method_id, *args)
create_weapon_methods = /create_(\w*)_weapon/
if method_id.to_s =~ create_weapon_methods
@description = method_id.to_s.gsub(create_weapon_methods, '\1')
@size = @description.split('_')[0]
@description.gsub!("_", " ")
@description.gsub!(@size,"")
else
raise method_id.to_s + " is not a valid method."
end
self
end
def and_there_are(num)
@quantity_existing = num
end
alias there_are and_there_are
end
Although it is slightly more than a setter, named is still a simple function. The only
thing it does besides set the name attribute is yield to a block that is passed to it.
That's the block we see in the original syntax beginning with do and ending (surprisingly)
with end.
The last thing is create_size_description_weapon. We use method_missing to
allow for any size and description, and check that the method matches our
regex /create_(\w*)_weapon/ before extracting that data. If it doesn't match, we just raise an
exception that tells us the requested method is not defined.
If I were to take this further, I would
also check if the method called matched one of the actions available for the weapon. If so, we'd
probably find a way to classify actions as offensive or defensive. We could then print something like
"You #{method_id.to_s} your sword for #{damage.roll} points of damage" (assuming we had a
roll method on DieRoll).
As always, any thoughts, questions, comments, and critcisms are appreciated. Just let me know below.
Posted by Sam on Jul 28, 2007 at 05:52 PM UTC - 5 hrs
Like many programmers, I started doing this because of my interest in video games. I was 6 years old when I first touched a computer. It was an Apple IIe and I would play a game involving Donald Duck, his nephews, and a playground (I forget the name of the game). I was hooked, and took every available chance to play that I could.
Subsequently, I got a Nintendo and played all sorts of games. Super Mario Bros. was my favorite, of course, and it greatly inspired me. After a while, I was spending more time planning and drawing levels in my notebook for two-dimensional side-scrolling video games than I was playing them. It wasn't long before I envisioned my own game console.
More...
Fast forward a few years to when I had a computer of my own. As I recall, it had a blazing fast 80368 processor running at 33 MHz. With 4 MB of RAM and a 20MB hard drive. I was set.
I spent a lot of time rummaging through the QBasic source code of Nibbles, attempting to figure out how it worked, and modifying it in places to see what happened. Eventually, I got sick of looking at other people's code and decided to write my own. Once I figured out how to PRINT and INPUT, I was ready to program my first text-based adventure game (I think I was 12 or 13 at the time).
Since then (in the last 15 years or so), I've kept the dream alive, but haven't done much to pursue it. Some friends and I spent a night trying to figure out how to program a MUD, I spent some time working with OpenGL (but found it too tedious for what I wanted to do), and started a couple of web based games that never got far off the ground except for fleshing out concepts and plots for the games.
Anyway, recently on Ruby-Talk there was a question about programming a game and a couple of good responses that gave me some resources I'd like to share (and record for my future inspection). Here they go:
-
Gosu - a "2D game development library for the Ruby and C++ programming languages."
-
RRobots - a "simulation environment for robots" whose source code I'd like to peruse.
-
Game Programming Wiki
-
Novashell - a "high-level 2D game maker that tries to handle all the hard work behind the scenes" from Seth Robinson, creator of one of my all-time favorite games, Legend Of the Red Dragon. (Incidentally, one of my friends and fellow ANSI artists from the BBS days, Zippy, did some art for Part II. Unfortunately, I couldn't find him online.)
Seth also has some source code available for several games he created. By happenstance, I stumbled across him while searching for domain names for the UH Code Dojo.
-
RPG Maker XP - A graphical game engine that "is equipped with the Ruby Game Scripting System (RGSS), based on the Ruby language and customized especially for this program."
-
Gamebryo - the granddaddy of them all, this engine has been used by Civilization IV and The Elder Scrolls IV. No telling how much it costs though.
Do you have any others to share?
Last modified on Jul 28, 2007 at 05:54 PM UTC - 5 hrs
Posted by Sam on Jul 12, 2007 at 08:23 AM UTC - 5 hrs
Yesterday, Ola Bini (from the JRuby team) described a new feature in JRuby that lets you steal
methods from one class and add them to an object of another class. Ordinarily, you could only reuse methods through modules (as mixins), or of course the usual
inheritance or aggregation.

It turns out someone wrote evil.rb, which does that and more in Ruby. Somehow, they are messing with Ruby's internals, or so I've read. I browsed the source quickly, and to be honest I don't have the experience to understand the trickery well enough to do a sam_larbi("evil.rb").inspect. My guess is that it will not work outside of
MRI.
When Ola said the magic words - "there is no way to get hold of a method and add that to an unrelated other class or module" - I had to give it my own shot, however.
More...
#first, we create our thief
module Thief
def steal_method(klass, meth)
k = klass.new
self.class.send(:define_method, meth, k.method(meth).to_proc)
end
end
#then, add him to Object
class Object
include Thief
end
class A
def initialize
@which_class = "A"
end
def foo
puts "A#foo called"
end
def bar(arg)
puts "A#bar called with '" + arg + "'"
end
end
class B
def initialize
@which_class = "B"
end
end
b = B.new
b.steal_method A, :foo
b.foo
b.steal_method A, :bar
b.bar("I'm here!")
puts "Everything looks to be working as we expected!"
#change foo to see which member variable it's using
class A
def foo
puts "A#foo called from class " + @which_class
end
end
#need to steal it again because it changed since we instantiated A
b.steal_method A, :foo
b.foo #outputs "A#bar called from class A"
#oh no! we stole the method but it came with A's @which_class
So it turns out if we just used simple examples where the methods are self-contained, it appears to work, but when those methods need to use
object-specific data, it's not going to do what we want it to. Now, there may be a way to fake it by going through A and adding everything we need from B, but using this plan at least, even that won't get us what we really want.
Any ideas on other approaches?
Posted by Sam on Jun 21, 2007 at 09:11 AM UTC - 5 hrs
Bruce Eckel posted an article on how to use Flex with a Python back end over at Artima.
He said its possible to do the same thing "with any language that has support for creating an XML-RPC server."
In any case, I'm going to look into this in the future (I still haven't hopped onto the bandwagon). Anyone else played with it? What has been your experience?
Posted by Sam on Jun 18, 2007 at 02:50 PM UTC - 5 hrs
This one refers to the 40+ minute presentation by Obie Fernandez on Agile DSL Development in Ruby. (Is InfoQ not one of the greatest resources ever?)
You should really view the video for better details, but I'll give a little rundown of the talk here.
Obie starts out talking about how you should design the language first with the domain expert, constantly refining it until it is good - and only then should you worry about implementing it (this is about the same procedure you'd follow if you were building an expert system as well). That's where most of the Agility comes into play.
More...
Later, he moves on to describe four different types of design for your DSL. This was something I hadn't really thought about before, therefore it was the most interesting for me. Here are the four types:
- Instantiation: The DSL consists simply of methods on an object. This is not much different from normal programming. He says it is "DSLish," perhaps the way Blaine Buxton looks at it.
- Class Macros: DSL as methods on some ancestor class, and subclasses can then use those methods to tweak the behavior of themselves and their subclasses. This follows a declarative style of programming, and is the type of DSL followed by Ruby on Rails (and cfrails) if I understand him correctly.
- Top-level methods: Your application defines the DSL as a set of top-level methods, and then invokes
load with the path to your DSL script. When those methods are called in the configuration file, they modify some central (typically global) data, which your application uses to determine how it should execute. This is like scripting, and (again) if I understood correctly, this is the style my (almost working correctly) Partial Order Planner uses.
- Sandboxing (aka Contexts): Similar to the Instantiation style, but with more magic. Your DSL is defined as methods of some object, but that object is really just a "sandbox." Interaction with the object's methods modifies some state in the sandbox, which is then queried by the application. This is useful for processing user-maintained scripts kept in a database, and you can vary the behavior by changing the execution context.
Note: These are "almost" quotes from the slides/talk (with a couple of comments by myself), but I didn't want to keep rewinding and such, so they aren't exact. Therefore, I'm giving him credit for the good stuff, but I stake a claim on any mistakes made.
The talk uses Ruby as the implementation language for the example internal DSLs, but I think the four types mentioned above can be generalized. At the least, they are possible in ColdFusion - but with Java, I'm not so sure. In particular, I think you'd need mixin ability for the Top-level methods style of DSL.
Next, Obie catalogs some of the features of Ruby you see used quite often in crafting DSLs: Symbols (because they have less noise than strings), Blocks (for delayed evaluation of code), Modules (for cleaner separation of code), Splats (for parameter arrays), the different types of eval (for dynamic evaluation), and define_method and alias_method.
Finally, he winds up the presentation with a bit about BNL. I liked this part because I found Jay Fields' blog and his series of articles about BNL.
As always, comments, questions, and thoughts are appreciated. Flames - not so much.
Posted by Sam on Jun 15, 2007 at 09:18 PM UTC - 5 hrs
Sean Corfield responded in some depth to " Is Rails easy?", and explained what I wish I could have when I said (awkwardly, rereading it now) "I think my cat probably couldn't [code a Rails app]."
Sean makes it quite clear (as did Venkat's original post) that it isn't that using a framework, technology, or tool in general is easy or hard (although, you can certainly do things to make it easier or harder to use). In many cases, what it does for you is easy to begin with - in the case of Rails, it is stuff you do all the time that amounts to time-wasting, repetitive, boring busy-work. Rather, the right way to look at them is that they are tools that make you more productive, and it takes a while to learn to use them.
If you go into them thinking they are easy, you're likely to be disappointed and drop a tool that can really save you time before you learn to use it. And that could be tragic, if you value your time.
Posted by Sam on Jun 11, 2007 at 09:52 AM UTC - 5 hrs
Want to get a report of a certain session? I'll be attending No Fluff Just Stuff in Austin, Texas at the end of June. So, look at all that's available, and let me know what you'd like to see.
I haven't yet decided my schedule, and it's going to be tough to do so. I'm sure to attend some Groovy and JRuby sessions, but I don't know which ones. In any case, I want to try to leave at least a couple of sessions open for requests, so feel free to let me know in the comments what you'd like to see. (No guarantees though!). Here's what I'm toying with so far (apologies in advance for not linking to the talks or the speakers' blogs, there are far too many of them =)):
More...
First set of sessions: No clue. Leaning toward session 1, Groovy: Greasing the Wheels of Java by Scott Davis.
Second set: 7 (Groovy and Java: The Integration Story by Scott Davis), 8 (Java 6 Features, what's in it for you? by Venkat Subramaniam), 9 (Power Regular Expressions in Java by Neal Ford), or 11 (Agile Release Estimating, Planning and Tracking by Pete Behrens). But, no idea really.
Third set: 13 (Real World Grails by Scott Davis), 15 (10 Ways to Improve Your Code by Neal Ford), or 17 (Agile Pattern: The Product Increment by Pete Behrens). I'm also considering doing the JavaScript Exposed: There's a Real Programming Language in There! talks in the 2nd and 3rd sets by Glenn
Vanderburg.
Fourth set: Almost certainly I'll be attending session 20, Drooling with Groovy and Rules by Venkat Subramaniam, which will focus on declarative rules-based programming in Groovy, although Debugging and Testing the Web Tier by Neal Ford (session 22) and Java Performance Myths by Brian Goetz (session 24) are also of interest to me.
Fifth set: Again, almost certainly I'll go to Session 27, Building DSLs in Static and Dynamic Languages by Neal Ford.
Sixth set: No clue - I'm interested in all of them.
Seventh set: Session 37, Advanced View Techniques With Grails by Jeff Brown and Session 39, Advanced Hibernate by Scott Leberknight, and Session 42, Mocking Web Services by Scott Davis all stick out at me.
Eighth set: Session 47, Pragmatic Extreme Programming by Neal Ford, Session 46, What's New in Java 6 by Jason Hunter, Session 45, RAD JSF with Seam, Facelets, and Ajax4jsf, Part One by David Geary, or Session 44, Enterprise Applications with Spring: Part 1 by Ramnivas Laddad all seem nice.
Ninth set: Session 50, Enterprise Applications with Spring: Part 2 by Ramnivas Laddad or Session 51, RAD JSF with Seam, Facelets, and Ajax4jsf, Part Two by David Geary are appealing, which probably means the eight set will be the part 1 of either of these talks.
Tenth set: Session 59, Productive Programmer: Acceleration, Focus, and Indirection by Neal Ford is looking to be my choice, though the sessions on Reflection, Spring/Hibernate Integration Patterns, Idioms, and Pitfalls, and NetKernel (which "turns the wisdom" of "XML is like lye. It is very useful, but humans shouldn't touch it," "on its head" all interest me.
Final set: Most probably I'll go to Session #65: Productive Programmer: Automation and Canonicality by Neal Ford.
As you can see, there's tons to choose from - and that's just my narrowed down version. So much so, I wonder how many people will leave the symposium more disappointed about what they missed than satisfied with what they saw =).
Anyway, let me know what you'd like to see. Even if its not something from the list I made, I'll consider it, especially if there seems to be enough interest in it.
Last modified on Jun 11, 2007 at 09:58 AM UTC - 5 hrs
Posted by Sam on Jun 11, 2007 at 07:36 AM UTC - 5 hrs
I take my second weekend in a row (mostly) off of a computer, and look at all the cool things happening!
Adobe releases AIR (previously known as Apollo) and Flex 3 public beta, both products have been on my list of things to do for quite some time, still with no action taken.
Ruby ( MRI) released bug fixes in version 1.8.6.
JRuby officially went 1.0 (though it has yet to be posted to the website as I write this). And Ruby.NET released version 0.8 (IronRuby uses its scanner and parser, according to the article -- and this happened a couple of days before the weekend).
More...
For web developers, InfoQ let us know about Browser Shots, which is a service that will test your web sites in tons of different browsers and present screen shots to you. It lets you choose whether to enable Flash, Javascript, or certain media players, and allows you to set the color depth and screen resolution. It's quite slow at the moment (set it and come back in four hours or so), but it shows us what can be possible! ( Screenshots of codeodor.com, as they are coming in more will pop up)
Also, InfoQ completed its first official year. It was "pre-released" (I forget the exact term they used) I think in May 2006, but it went officially live a year ago Friday. Congrats to Floyd Marinescu and the entire InfoQrue! (And they have a lot of relevant news (to me) I'll be posting links to today)
Last modified on Jun 11, 2007 at 08:29 AM UTC - 5 hrs
Posted by Sam on Jun 04, 2007 at 09:35 AM UTC - 5 hrs
As I was trying to find a reference today for golfing (in code), I came across
CodeGolf.com, a site for Perl, Python, PHP, and Ruby golfers. Looks like fun if you're into "good code ruined," as the site's tagline calls it (the point is to solve the problem using the least number of (key) strokes).
Enjoy!
Posted by Sam on Jun 03, 2007 at 12:12 PM UTC - 5 hrs
Last night Thomas Enebo announced on Ruby Talk that JRuby 1.0 RC 3 has been released, and that it "will likely be our final release candidate before our 1.0 release."
I'm interested to deploy a web app trying Ruby on Rails with JRuby (or JRuby on Rails, perhaps), and also in experimenting with Sean Corfield's Scripting for CF 8 to run Ruby within ColdFusion.
Anyone else planning to do good things with JRuby?
Posted by Sam on Jun 02, 2007 at 02:14 PM UTC - 5 hrs
I've been wanting to do a Ruby Quiz now for quite some time, but I've always had some excuse about being too busy. But this week's Ruby Quiz is FizzBuzz, so I had to take the two minutes and write up a solution.
Some of the discussion on Ruby Talk has been around getting the smallest solution possible (even though the quiz directs us to do as we might for a job interview). There are plenty of claims ranging from 56 to 72 bytes. I couldn't even get under 100, so I'm quite interested to see the different solutions when they are published - not because I think code so terse as to be unintelligible is something we should strive for, but because surely I'll learn new tricks (and some of which I'd expect are understandable!).
More...
Anyway, here's my Ruby FizzBuzz (how exciting):
class Integer
def fizzbuzz
fizzable = self % 3 == 0
buzzable = self % 5 == 0
print "Fizz" if fizzable
print "Buzz" if buzzable
print self if !(fizzable || buzzable)
puts
end
end
(1..100).each {|i| i.fizzbuzz}
The one part where I did learn something was that self gets me the member variable holding the integer here. I didn't know that before, and I started out looking for "how to find the name of the member variable in Ruby Integer class" (or some such search query). When I didn't find anything, I thought I'd try the obvious - self. Of course, like many things in Ruby, it followed the principle of least surprise, and my guess worked.
Last modified on Jun 02, 2007 at 02:19 PM UTC - 5 hrs
Posted by Sam on May 30, 2007 at 09:23 AM UTC - 5 hrs
The Lone Star Ruby Conference has recently announced the 2007 dates and call for papers. The paper deadline is rather short - June 10, 2007, and the conference itself will be September 7-8, 2007 in Austin, Texas (for only $200).
I haven't decided yet whether I'll be making the drive up to Austin for it. That's right around my birthday and Austin City Limits Music Festival is the weekend after, so I've got some decisions to make. In any case, I thought I'd let ya'll Texans know about it (who don't already).
Posted by Sam on May 30, 2007 at 08:14 AM UTC - 5 hrs
Kenji HIRANABE (whose signature reads "Japanese translator of 'XP Installed', 'Lean Software Development' and 'Agile Project Management'") just posted a video (with English subtitles) of himself, Matz (creator of Ruby), and Kakutani-san (who translated Bruce Tate's "From Java To Ruby" into Japanese) to his blog. According to Matz (if I heard correctly in the video), Kenji's a "language otaku," so his blog may be worth checking out for all you other language otakus (though, from my brief look at it, it seems focused between his company's product development and more general programming issues).
In any case it's supposed to be a six part series where the "goal is to show that 'Business-Process-Framework-Language' can be
instanciated as 'Web2.0-Agile-Rails-Ruby' in a very synergetic manner, but each of the three may have other goals."
The first part discusses the history of Java, Ruby, and Agile. I found it interesting and am looking forward to viewing the upcoming parts, so I thought I'd link it here.
Posted by Sam on May 19, 2007 at 01:25 PM UTC - 5 hrs
Peter Bell's presentation on LightWire
generated some comments I found very interesting and thought provoking.
(Perhaps Peter is not simply into application generation, but comment generation as well.)
The one I find most interesting is brought up by several people whose opinions I value -
Joe Rinehart, Sean Corfield,
Jared Rypka-Hauer, and others during and after the presentation.
That is: what is the distinction between code and data, and specifically, is XML code or data
(assuming there is a difference)?
More...
The first item where I see a distinction that needs to be made is on, "what do we mean when we are talking about
XML?" I see two types - XML the paradigm where you use tags to describe data, and the XML you write - as in,
the concrete tags you put into a file (like, "see that XML?"). We're talking about XML you've written, not
the abstract notion of XML.
The second idea: what is code? What is data? Sean Corfield offers what I would consider to be a concice,
and mostly correct definition: "Code executes, non-code (data) does not execute." To make it correct (rather
than partially so), he adds that (especially in Lisp) code can be data, but data is not code. You see this
code-as-data any time you are using closures or passing code around as data. But taking it a bit further -
your source code is always just data to be passed to a compiler or interpreter, which figures out what the
code means, and does what it has been told to do.
So is XML code? Certainly we see it can be: ColdFusion, MXML, and others are languages where your
source code is written (largely) in XML. But what about the broader issue of having a programmatic
configuration file versus a "data-only" config file?
Is the data in the config file executable? It depends on the purpose behind the data. In the case of data
like
<person>
<name>
Bill
</name>
<height>
4'2"
</height>
</person>
I think (assuming there is nothing strange going on) that it is clearly data. Without knowing anything about the
back end, it seems like we're just creating a data structure. But In the case of
DI (and many others uses for config files),
I see it as giving a command to the DI framework to configure a new bean. In essence, as Peter notes,
we've just substituted one concrete syntax for another.
In the case of XML, we're writing (or using)
a parser to send data to an intepreter we've written that figures out what "real" commands to run based on
what the programmer wrote in the configuration file. We've just created a higher level language than we had before
- it is doing the same thing any other non-machine code language does (and you might even argue
about the machine code comment). In the configuration case,
often it is a DSL (in the DI case specifically, used to describe which objects depend on which other
objects and load them for us).
While we don't often have control structures, there is nothing stopping us from implementing them,
and as Peter also notes, just because a language is not
Turing complete), doesn't mean it is not
a programming language. In the end, I see it as code.
Both approaches are known to have their benefits and drawbacks, and choosing one over the other is largely a matter
of personal taste, size and scope of problem, and problem/solution domain. For me, in the worlds of
JIT compiling and interpreted langages, the programmatic way
of doing things tends to win out - especially with large configurations because I prefer to have
the power of control structures to help me do my job (without having to implement them myself).
On the other hand, going the hard-coded XML route is especially popular in the compiled world, if not
for any other reason than you can change configurations without recompiling your application.
I don't make a distinction between the two on terms of XML is data, while programming (or using an in-language DSL)
in your general-purpose language is code. To me, they are both code, and if either is done incorrectly it will
blow-up your program.
Finally, I'm not sure what value we gain from seeing that code is data (and in many cases config data is code),
other than perhaps a new way of looking at problems which might lead us to find better solutions.
But that isn't provided by the distinction itself, just the fact that we saw it.
Comments, thoughts, questions, and requests for clarifications are welcome and appreciated.
Posted by Sam on May 04, 2007 at 08:26 AM UTC - 5 hrs
For background and history on partial order planners, see
What is Partial Order Planning?,
Selected History of POP Part 1, and
POP History Part 2.
Or, you can read the entire thing in
PDF format.
Our goal is to give commands to the partial order planner, telling it what the goal is, the initial state (if it exists), and actions it can perform. The actions contain the name of the action, any preconditions that must be fulfilled before that action can be performed, and a set of effects the action has on the world state. After giving this information to the planner, it should output a plan if one exists.
For simplicity's sake, I've used a STRIPS-like notation,
without the complexity of existentially or universally quantified variables, among other things.
Further, only one possible plan is returned, rather than attempting to find all plans.
The one returned is not guaranteed to be optimal, though (inadequate) tests have shown that it is correct.
Plans are to improve these limitations in the future, moving to a less restrictive ADL-style syntax,
and adding support for returning multiple plans.
More...
In the meantime, the first task is to allow a user to enter commands in a syntax that looks like:
PlanName("Put on Shoes")
Goal(:RightShoeOn ^ :LeftShoeOn)
Action(:RightShoe, EFFECT => :RightShoeOn, PRECOND => :RightSockOn)
Action(:RightSock, EFFECT => :RightSockOn)
Action(:LeftShoe, EFFECT => :LeftShoeOn, PRECOND => :LeftSockOn)
Action(:LeftSock, EFFECT => :LeftSockOn)
Also, it should allow function-like notation, such as:
PlanName("Change Tire")
Init(At(:Flat,:Axle) ^ At(:Spare,:Trunk))
Goal(At(:Spare,:Axle))
Action(Remove(:Spare,:Trunk),
PRECOND => At(:Spare,:Trunk),
EFFECT => NotAt(:Spare,:Trunk) ^ At(:Spare,:Ground))
Action(Remove(:Flat,:Axle),
PRECOND => At(:Flat,:Axle),
EFFECT => NotAt(:Flat,:Axle) ^ At(:Flat,:Ground))
Action(PutOn(:Spare,:Axle),
PRECOND => At(:Spare,:Ground) ^ NotAt(:Flat,:Axle),
EFFECT => NotAt(:Spare,:Ground) ^ At(:Spare,:Axle))
Action(:LeaveOvernight,
EFFECT => NotAt(:Spare, :Ground) ^ NotAt(:Spare,:Axle) ^
NotAt(:Spare,:Trunk) ^ NotAt(:Flat,:Ground) ^
NotAt(:Flat,:Axle))
The domain described in Code Sample 1 should produce a plan such as: LeftSock → LeftShoe →
RightSock → RightShoe and RightSock → LeftSock → LeftShoe → RightShoe.
As one can surmise from looking at the domain as it is written, any plan where the socks are on before
the shoes is sufficient.
Finally, the domain given in Code Sample 2 should render plans like Remove(Flat,Axle) →
Remove(Spare,Trunk) → PutOn(Spare,Axle), switching the first two actions depending on which
it decides to do first (since either one would work).
Implementing (or allowing) such syntax in Ruby turns out to be simple. To get the conjunction operator ^, we simply define a module with ^ as a method, and include that module in Ruby's String, Symbol, and Array classes, since we'll be using each of these as symbols in our "new" language (See Code Sample 3).
module Logic
def ^(condition)
[self, condition]
end
end
#modify the symbol class to include the ^ operation
class Symbol
include Logic
end
#modify the array class to include the ^ operation
class Array
include Logic
end
#modify the string class to include the ^ operation
class String
include Logic
end
Next, we need to allow the use of function-style symbols, such as Remove(:Spare,:Trunk).
As with most things in Ruby, this is also simple. We just use the method_missing method in our module:
# when the user enters a function, turn it into an action
def method_missing(method_id, *args)
symbol_name = "#{method_id}("
args.each { |arg| symbol_name += arg.to_s + "," }
symbol_name[0,symbol_name.length-1] + ")"
end
We now have the ability to use the syntax we laid forth in the first two blocks of code
to define our problems that need planning. All that remains are to implement
the functions in our "language" that allow us to define the problem domain, and an
algorithm to solve for plans.
To do so, first, we initialize the start state with an Init() function that simply stores
the conditions it is passed. Similarly, the goal state and initial open preconditions are simply stored
into member variables as they are passed via the Goal() method.
Finally, actions are constructed from a name and a hash with keys PRECOND and EFFECT.
#constants to use to store hash for precondition and effect
#(only for purposes of keeping the DSL looking close to the original)
PRECOND = :precondition
EFFECT = :effect
#store the start-state conditions
def Init(conditions)
@start_state = conditions
end
alias init Init
#store the goal defined by the user
def Goal(conditions)
@goal = conditions
@open_preconditions = @goal
end
alias goal Goal
# store actions defined by the user
def Action(name, precondition_effect)
action= ["name" => name,
"precondition" => precondition_effect[PRECOND],
"effect" => precondition_effect[EFFECT]]
@actions = [] if !@actions
@actions = @actions + action
end
alias action Action
Finally, we come to the meat of the problem, the partial-order planning algorithm. The algorithm itself follows a fairly simple path:
- From the list of open preconditions, choose one.
- Find an action whose effect is the same as the precondition we chose and add it to the plan.
- Add to the list of preconditions any requirements for that action.
- Remove from the list of preconditions any that match the effects for the chosen action.
- Repeat steps 1-4 until the set of open preconditions is empty, or no action that satisfies a precondition can be found.
- Remove any preconditions from the open list that match the starting state.
- If the set of open preconditions is empty, return the plan. Otherwise, fail.
The algorithm in Ruby follows:
def make_plan
action_plan = []
fail = false
while (@open_preconditions.size > 0 && !fail)
#randomize the open_preconditions and actions to show order
#doesn't matter
@open_preconditions=@open_preconditions.sort_by { rand }
#find an action that solves it the first open precondition
attempted_precondition = @open_preconditions.shift
action_to_take = find_action_for attempted_precondition
if (action_to_take != nil)
add_preconditions_for action_to_take
remove_preconditions_fulfilled_by action_to_take
#add the action to the plan
action_plan.push(action_to_take["name"])
else
#put the precondition back on the open_preconditions, since
#it wasn't fulfilled by an action
fail = true if @open_preconditions.size == 0
@open_preconditions.push attempted_precondition
remove_preconditions_matching_start_state
fail = false if @open_preconditions.size == 0
end
end
if @open_preconditions.size > 0 || fail
puts "There appears to be no plan that satisfies the problem."
puts "Open preconditions: "
puts @open_preconditions
action_plan = []
end
sanitize_plan(action_plan.reverse)
end
Most of the code is aptly named where there are functions
(see RubyPOP.zip for the complete source), but two issues in this algorithm immediately
jump to the forefront. The first is: why aren't we also randomizing the list of actions?
Clearly, if there are two actions that satisfy the same precondition, the first one encountered will always win. This was done because randomizing the list of actions (if two or more satisfy the same precondition) has the potential to cause a loop of preconditions/effects, and thus cause incorrect plans to be generated. Since no attempt was made at finding the optimal plan, I didn't want to clutter the code and make it harder to follow. Correct plans are still generated, and a future version meant for more demanding environments would indeed allow a random action to be chosen.
The second issue that is not immediately clear begs the question: "just what is that sanitize_plan method doing there?" Some actions may add duplicate preconditions to the set of open preconditions. The algorithm as it stands allows this to happen for readability purposes, and simply cleans up the plan later with the sanitize_plan function.
Finally, it is also clear that a more "elegant" solution may have been to take actions as functions, which receive preconditions as their parameters, and whose output are effects. The thought of such an implementation is interesting and worthy of exploration, though time constraints prevented me from doing so in this case.
As mentioned above, a complete version of the code and three manual tests can be found in the RubyPOP.zip file.
Posted by Sam on May 01, 2007 at 06:49 AM UTC - 5 hrs
Apparently, at MIX07, Microsoft announced a new open source project to get Ruby running on the CLR. InfoQ and CNET talk about it just a little bit.
Posted by Sam on Apr 24, 2007 at 09:05 AM UTC - 5 hrs
This morning has been strange. On the drive to work, I started out thinking about encapsulation, and how much I hate the thought of generating a bunch of getAttribute() methods for components that extend cfrails.Model (in cfrails, of course). To top it off, I don't know how I'd generate these methods other than to write them to a file and then cfinclude it. But as I said, I really hate the idea of (say in the views) having to write code like #person.getSocialSecurityNumber()#. That's just ugly.
But then again, I don't like the alternative of leaving them public in the this scope either, because then there is no method to override if you wanted to get or set based on some calculations (of course, you could provide your own, but you'd have to remember to use them, and the attributes themselves would remain public. Currently, this is the way its done, because I feel like providing default getters and setters is not really encapsulating anything on its own. The encapsulation part only enters the game when you are hiding some implementation of how they are calculated or set.
More...
Then, of course there are the generic getters and setters that Peter Bell is often talking about. You know, where you have some implementation like (excuse the pseudocode -- I'm just lazy right now =), but it shows the idea):
function get(attr)
{
if (methodExists("get"+attr)) return callMethod("get"+attr);
else return variables[attr];
}
This is easy enough to implement without resorting to file I/O, and it has the side benefit of allowing you to check if a getAttribute() method already exists, and call it if so. And where this morning starts getting wierd is that I randomly came across this post from David Harris where he and Peter are discussing this strategy in the comments. What a coincidence.
But what I really wanted is something you see in Ruby (and other languages too): the attr_accessor (or reader and writer) in Ruby. You can do something like this:
class Cow
attr_accessor :gender, :cowtype
# or equivalently, we can have writers and readers separate:
# attr_reader :gender, :cowtype
# attr_writer :gender, :cowtype
def initialize(g, t)
@gender= g
@cowtype = t
end
end
elsie = Cow.new("female", "milk")
#if we did not have the attr_reader defined, the next line would choke
puts "Elsie is a " + elsie.cowtype + " cow."
#change the cowtype + this line would break without the writer defined
elsie.cowtype = "meat"
puts "Elsie is now a " + elsie.cowtype + " cow."
#here we'll change the class (this is happening at runtime)
class Cow
# add a setter for cowtype, which overrides the default one
def cowtype=(t)
@cowtype="moo " + t
end
end
#change elsie to a model cow
elsie.cowtype = "model"
#what type of cow is elsie now?
puts "What a hot mamma! She's turned into a " + elsie.cowtype + "!"
#she's a moo model!
See how easy that is?! That's what I really want to be able to do in ColdFusion. And the best part is, it really would only (as far as I can tell) require a couple of changes to the language. The first one being something like if (cowtype= is defined as a method on the object I'm working with) call it when doing an assignment; and the second one is being able to define a method like so:
<cffunction name="cowtype=">
</cffunction>
In any case, the morning got more coincidental when I ran into this post on InfoQ about Adding Properties to Ruby Metaprogramatically, which I'd recommend reading if you're wanting to metaprogram with Ruby (or if you are just interested in that sort of thing).
It's now time for me to crawl back into my hole and write about the wonderful world of The History of Partial-Order Planners. (The good news on that is I'm getting close to the fun part - actually programming one).
So method= is going on my wishlist for CF9, and in the mean time I'll probably end up going the generic getter/setter route. What are your thoughts? What would you go with?
Posted by Sam on Apr 22, 2007 at 11:47 AM UTC - 5 hrs
YAGNI, KISS, and the simplest thing that could possibly work reared their heads again (at least for me) at the April meeting of the UH Code Dojo. Luckily for me, a couple of our members bailed us out of what could have been a disaster - greatly complicating a simple problem. (And my apologies for waiting so long to write this up - with finals and final projects all due these couple of weeks, I've just been super busy, as all you other students know all too well).
We decided on using a recent Ruby Quiz as our problem: Microwave Numbers. The basic idea is: given a number in seconds, identify the most efficient way to push the buttons (based on distance) to get that number of seconds (the actual problem left some room for fuzziness, but we didn't bother with that). This boils down to calculating the distance between any two numbers on the pad, and determining if the number of seconds is greater than 60 (in which case, there will be 2 options to check). Well, at least thats what we came up with.
More...
You can tell immediately I'm suffering from a bad case of not solving little problems that require some thought like this very often. My thoughts are, "ok, lets build a graph of the pad and write a traversal algorithm that we'll run to see how far apart any two numbers are." Luckily, Gino had thought through the problem and had an easier solution: represent the buttons as points in a plane, and calculate the distance as a function given 2 points. Well, that was easy, wasn't it?
The next problem was figuring out how to map the point to which button it represented. Here again, I was thinking of much more complicated things than I needed to be thinking about. Matt came up with the simple solution here: just store the buttons as a string and use the division and modulus to figure the row and column based on the index in the string. Problem solved. After about 15 minutes of thinking through it, we started programming. My laptop is dead at the moment, so we started using why the lucky stiff's online Ruby interpreter on the computer that was set up in the room (which, didn't have a ruby interpreter as far as I could tell).
As you can imagine, that was a nightmare. But, Gino came to the rescue again and let us use his laptop. After the meeting, he cleaned up the code and sent it to us, and Matt did some of the programming, so its in camelCase style (and I didn't want to spend the time to rubify it), but it works just fine. Next time, I want to write some unit tests first - as it would have been helpful for verification purposes here, rather than trying to run separate tests by hand each time we made a change. Anyway, with no further ado, here's the code we came up with for you to enjoy:
class Microwave
def initialize
@buttons = "123456789#0*"
end
def getShortestEntry(seconds)
minDistance = 10000;
minPress = "";
opt = 1;
puts "Input:#{seconds}\n---------------"
(0..seconds/60).each do|minute|
remSeconds = seconds - 60 * minute
if remSeconds < 100
buttonPress = timeEntry(minute, remSeconds)
totalDistance = 0
(0..buttonPress.length() - 2).each do |char|
totalDistance += manhattanDistance(buttonPress[char, 1], buttonPress[char + 1, 1])
end
puts "opt#{opt}: #{buttonPress} d=#{totalDistance}"
opt = opt + 1
if totalDistance < minDistance
minDistance = totalDistance
minPress = buttonPress
end
end
end
return minPress
end
def manhattanDistance(from, to)
fromIndex = @buttons.index(from.to_s)
toIndex = @buttons.index(to.to_s)
rowFrom = fromIndex/3
colFrom = fromIndex%3
rowTo = toIndex / 3
colTo = toIndex % 3
return ((rowFrom - rowTo).abs + (colFrom - colTo).abs)
end
def timeEntry(minute, seconds)
str = (minute == 0 ? "" : minute.to_s)
str = str + (seconds < 10 ? "0" : "") + seconds.to_s
return (str + "*")
end
end
mwave = Microwave.new
[33, 61, 99, 101, 71, 120, 123, 222, 737].each do |inSeconds|
puts "The shortest entry for #{inSeconds} seconds: #{mwave.getShortestEntry(inSeconds)}\n "
end
Posted by Sam on Mar 29, 2007 at 03:54 PM UTC - 5 hrs
Wow, six posts in one day. I'm exhausted. My last link to InfoQ today comes in thanking them for the timely post Ruby Domain Specific Languages Buzz. There, I got that out of the way.
It is timely for me, because a couple of weeks ago I decided I was going to try to implement a Partial-Order Planner DSL in Ruby. I haven't yet started, nor have I decided on a full course of action. But, I do have a vague strategy outlined in my head, and while I have yet to decide if I will be using the code provided by Reginald Braithwaite in his post about "an Approach to Composing Domain-Specific Languages in Ruby," the content will probably prove helpful. Another link they put was to Creating DSLs with Ruby posted by Jim Freeze to Artima's Ruby Code and Style.
I'll let you know how my progress goes. I'll probably start a little survey of what Partial-Order Planning is - similar to my paper on k-means - and cover some research about it first and post piece by piece to build my paper this time, rather than waiting to post it all at once. I'm not married to that approach, so you might see some code first ... but I'm leaning that way.
Posted by Sam on Mar 29, 2007 at 02:24 PM UTC - 5 hrs
It had been a while since I visited InfoQ, but the other day I got one of their mailings in my inbox, and tons of it was relevant to my interests (even more so than normal). Rather than having a separate post for all of it, I decided to combine much of it into this post.
First, this post let me know that Thoughtworks has released CruiseControl.rb, which is good news for Ruby users who also want continuous integration. I've yet to use it, but those guys are a great company and it seems like everything they touch turns to gold.
More...
Next, of interest to Java programmers and ORM fans, Google has contributed code to Hibernate that allows people to "keep their data in more than one relational database for whatever reason-too much data or to isolate certain datasets, for instance-without added complexity when building and managing applications."
Then, Bruce Tate, who is probably best known for his books Beyond Java and From Java to Ruby (by me anyway) has a case study on ChangingThePresent.org, his new project that uses Rails. It looks like a good starting point if you are developing a high-traffic Rails site. And, the site does some good charity work - taking only the credit card processing fee from your donation to the causes of your choice.
Finally, Gilad Bracha speaks about dynamic languages on the JVM. Until recently he was the Computational Theologist (is that someone who studies the religion of computation?) at Sun. The talk is just over 30 minutes long, and is at a surprisingly low level - so geeks only! He discusses a few of the challenges with implementation details on getting dynamic languages to run natively in byte-code (as opposed to writing an interpreter in Java which would then interpret the dynamic language). This includes a new instruction for invoking methods - invokedynamic, as well as a discussion on possible implementations of hotswapping - the technique that allows you to modify code at runtime. Very interesting stuff.
For today, I should be done referencing InfoQ, except to give them credit in my next post for turning me on to a couple of good resources for implementing DSLs in Ruby (which is the subject of my next post). I'll post the link in the comments when I'm done with it - I try not to edit these posts anymore since MXNA likes to visit every 30 seconds and thinks the date is the unique identifier of the post... you know, instead of using the XML field called "guid." =) (sorry guys, just poking a little fun - thanks for aggregating me).
Posted by Sam on Mar 25, 2007 at 10:33 AM UTC - 5 hrs
Update: Ruby 1.9.3 adds the ability to use ranges as arguments to rand, which produces more obvious code. So if you're using it, instead of using "magic offsets" like I did in the original post (as Joni Orponen mentions in the comments below), it would be better to use rand(1..6) to simulate a die roll.
So to summarize: if you need a percentage between 0 and 1, just call rand. If you need an integer between 0 and x (not including x), you can still call rand(x). Finally, if you need a number in a specific range, just call rand(x..y) where x is the lower bound of the range, and y is the higher end.
(And recall that if you want a non-inclusive range, you can use 3 periods, like rand(1...100) to get numbers from 1 to 99. Although if you're typing the number out, it's certainly better to use 1..99, if you had used a variable in the higher part of the range, the 3rd period is preferable to 1..(x-1), in my opinion.)
The original post follows:
Another quick note today... I surprisingly have yet to need a random number in Ruby up to this point (or forgot if I did), so I went through a little hassle trying to find out how. Turns out, you can simply use rand(int). So, if you needed a random integer to simulate a roll of a six-sided die, you'd use: 1 + rand(6). A roll in craps could be simulated with 2 + rand(6) + rand(6).
Finally, if you just need a random float, just call rand with no arguments. After that, you can modify the range as you normally would in anything else (i.e., using addition and multiplication).
I guess I used some crappy search terms, because I couldn't find this via google, and I didn't see it skimming the usual suspects in the Ruby docs.
Last modified on Feb 15, 2012 at 05:58 AM UTC - 5 hrs
Posted by Sam on Mar 06, 2007 at 12:13 PM UTC - 5 hrs
Our second meeting of the UH Code Dojo was just as fun as the first. This time, we decided to switch languages from Java to Ruby. And although we started quite slowly (we came unprepared and undecided on a problem and a language), we pretty much finished the anagram problem.
Now, I mentioned it was slow at first - because we were trying to decide on a problem. I'm guessing we spent about 30-45 minutes just looking over Ruby Quiz and then moving on to Pragmatic Dave's Code Kata. We learned from our experience though, and resolved to determine before-hand what we would do in the future. In any case, we finally decided on anagrams as our problem, and one of us mentioned something to the effect of "I don't know about you all, but I use Java too much at work." Of course, there's not much you can say to an argument like that - Ruby it was!
Since we found ourselves violating YAGNI at the first meeting, we decided to do a little more discussion of the problem before we started coding. One of the initial paths we explored was looping over each letter and generating every possible combination of letters, from 1 to n (n being the length of the input). We then realized that would need a variable number of nested loops, so we moved on to recursion. After that, we explored trying to use yield in conjunction with recursion, in an isolated environment. I don't recall the reasoning behind it, but whatever it was, we were starting to discover that when we passed that fork on the road a few minutes back, we took the path that led to the cannibals. (As a side note, if you're unfamiliar: yield sits in a function, which takes a closure as an argument, and runs the code in the closure -- I think that's a simple way of putting it, anyway).
After smelling the human-stew awaiting us, we backtracked a little and started looking for another idea. Enter idea number two: I'm not sure how to describe it in words, so I'll just show the code now and try to explain it afterwards:
char_count = Array.new(26).fill(0)
dictionary = ['blah', 'lab', 'timmy', 'in', 'hal', 'rude', 'open']
word = "BlAhrina".downcase
word.each_byte { |x| char_count[x - ?a] += 1 }
dictionary.each do |entry|
char_count2 = char_count.clone
innocent = true
entry.each_byte do |letter|
index = letter - ?a
if char_count2[index] > 0
char_count2[index] -= 1
else
innocent = false
break
end
end
puts entry if innocent
end
That's it: quite simple. First we initialize an array with a cell corresponding to each letter of the alphabet. Each cell holds a number, which represents the number of times that letter is used in out input, called word. These cells are set by using the line word.each_byte {...}.
Then for each entry in the dictionary, we do something similar: loop through each letter. If the total count for each letter goes to 0, we have a match (and in our case, simply print it to the standard output device). It's really a simple, elegant solution, and I think we're all glad we didn't go down the painful path of recursion. It would be fairly trivial to add a file which contained a real dictionary, and loop over that instead of each word in our array, but we didn't have one handy (nor did we happen to notice that Dave had provided one). And it would have been just an extra step on top of that to find all the anagrams in the dictionary.
I know this is just a silly little problem that you're not likely to encounter in real life, but it shows how even the simplest of problems can be tough without some thought, and I found it to be great practice. In particular, one problem we had was with trying to use TDD. Although we spent some time looking for tests we could write, and ways to test, and we even wrote an empty test thinking about what to put in there - none of us seemed to find anything to test. Now that we see the solution, it's fairly easy to figure out how to test it, but trying to drive the design with the test was proving fruitless for us. Dave alluded to this on the Kata page:
Apart from having some fun with words, this kata should make you think somewhat about algorithms. The simplest algorithms to find all the anagram combinations may take inordinate amounts of time to do the job. Working though alternatives should help bring the time down by orders of magnitude. To give you a possible point of comparison, I hacked a solution together in 25 lines of Ruby. It runs on the word list from my web site in 1.5s on a 1GHz PPC. It’s also an interesting exercise in testing: can you write unit tests to verify that your code is working correctly before setting it to work on the full dictionary.
I didn't read that before we had started (in fact, it wasn't until we had finished that anyone noticed it), but as you can tell, this exercise performed as promised. Our solution was under 25 lines, and while we didn't test it on his word list, I think our results would have been comparable (in fact, I wouldn't be surprised if we had the same basic solution he did).
Thoughts anybody?
Last modified on Mar 06, 2007 at 12:15 PM UTC - 5 hrs
Posted by Sam on Feb 27, 2007 at 06:31 AM UTC - 5 hrs
One of the things I've been dreading is getting Rails to work with IIS, although it appears to be getting easier (last time I checked, there was no such "seamless integration"). But eWeek has some good news. They note that core developer on the JRuby project, Charles Nutter
said the JRuby project will announce, possibly as soon as this week, that JRuby supports the popular Ruby on Rails Web development framework. Ruby on Rails is sometimes referred to as RoR or simply Rails.
"We're trying to finish off the last few test cases so we can claim that more than 95 percent of core Rails tests passed across the board," Nutter said.
Moreover, the JRuby team is inviting Rails developers to try out real-world usage of JRuby and help them find any Rails issues the unit tests do not cover, or any remaining failures that are crucial for real applications, Nutter said.
Support for Ruby on Rails is important because "once Rails can run on JVM alongside other Java apps, existing Java shops will have a vector to bringing Rails apps into their organizations. They won't have to toss out the existing investment in servers and software to go with the new kid on the block," Nutter said.
The article also mentions "Microsoft is looking at support for Ruby developers and broader uses of Ruby, including having it run on the CLR."
Both bits of good news for fans of Ruby who want it to play well with Windows and IIS. Not to mention that using JRuby (or NRuby, if it will be called that for .NET) should open up all of those libraries available to Java/.NET developers, which has been considered by some to be one of Ruby's weaker spots.
Posted by Sam on Feb 02, 2007 at 09:34 AM UTC - 5 hrs
The good folks at InfoQ have released another minibook, Mr. Neighborly's
Humble Little Ruby Book. The PDF is free, and you can buy a print version for $9.95.
I haven't read it yet, but the description sounds like it would be a good introduction to the language. I've got
the 2nd Pickaxe, which is available from PragProg.
The Humble Little Ruby Book is considerably shorter (144 pages versus 864).
Another good, free resource for Ruby is the first edition of Programming Ruby,
available at Ruby Docs. You might also check
Introduction to Ruby on Rails for more resources.
Posted by Sam on Jan 29, 2007 at 06:57 AM UTC - 5 hrs
When I was young and didn't know much about programming, I remember someone saying to me "functions can return only one value." I also remember thinking to myself, "then I'm going to be the guy to write a language that allows you to return multiple values."
I was naive back then, to say the least.
Of course, there are plenty of ways to return more than one value from a function. In languages with pointers, like C and C++, you can pass in an "out" parameter to functions, and have the function dereference that pointer, setting values to it. In languages with ADTs, you can return say, a Point which would then encompass two or more variables. In many of these, you might have to do that via an out parameter as well.
Of course, there are arrays and structs and components in Coldfusion. And there are string lists in just about any language (some of which may be implemented via arrays).
But I always wanted to do something like this:
var_one, var_two, var_three = some_method()
Fortunately for me, Ruby allows you to do just that. It is implemented as an array (to my knowledge), but the syntax is so elegant you'd never know it:
More...
def some_function
return 1, 2, 3
end
one, two, three = some_function
puts one #outputs "1"
puts two #outputs "2"
puts three #outputs "3"
Pretty sweet if you ask me.
Last modified on Jan 29, 2007 at 06:59 AM UTC - 5 hrs
Posted by Sam on Jan 15, 2007 at 10:23 AM UTC - 5 hrs
Do you find yourself writing more classes in other languages than in Coldfusion? I do.
For instance, I certainly develop more classes in Java than Coldfusion.
Is it due to the fact that I've developed bad habits in CF and haven't yet broken out of them
(i.e., I'm just unable to spot needs for new classes) or is it because CF is so much more high-level
than Java? A third option may be that the performance issues with instantiating
CFCs contribute to me not wanting
to break out?
More...
I think part of it may be due to bad habits and not having the ability to notice a spot where I need
another class. But, I have no evidence of this, since I haven't been able to notice it =).
I do have evidence of the other two options however: CF being so much more high-level than Java is fairly
self-evident: Where I'll often use a façade to interact with a database in Java, in Coldfusion it would
be pretty useless - since there is no need to instantiate a connection, prepare a statement, prepare a
record set, and then close/destroy them all when you don't need them any more. The other,
about the performance hits, I know sometimes stops me from creating more classes. For instance,
I recently used a mixin to achieve some code reuse with a utility method that didn't belong to any of
the classes that used it. Clearly it broke the "is-a" relationship rule, but I didn't
want to incur the cost of instantiating an object just to use
a single, simple method (the application was already seeming to perform slow).
Of course, this is not a zero-sum game. It is certainly due in part to all three. I'd like to think
it is mostly due to the expressiveness of Coldfusion, but I'll always have to wonder about the bad habits.
In Ruby, I've developed a couple of "significant" applications, but those didn't approach
the size of the one's I've done in Coldfusion or Java. It's hard to say for sure, but I'd guess that I'm
writing much fewer classes in Ruby than I would in Java. Again, this is mostly due to Ruby's expressiveness.
In any case, have you noticed yourself writing fewer classes in CF than in other languages? Have you
thought about it? Come to any conclusions?
Last modified on Jan 15, 2007 at 10:23 AM UTC - 5 hrs
Posted by Sam on Jan 09, 2007 at 04:44 PM UTC - 5 hrs
For those that don't know, cfrails is supposed to be a very light framework for obtaining MVC architecture with little to no effort (aside from putting custom methods where they belong). It works such that any changes to your database tables are reflected immediately throughout the application.
For instance, if you change the order of the columns, the order of those fields in the form is changed.
If you change the name of a column or it's data type, the labels for those form fields are changed, and
the validations for that column are also changed, along with the format in which it
is displayed (for example, a money field displays with the local currency,
datetime in the local format, and so forth).
I've also been developing a sort-of DSL for it,
so configuration can be performed quite easily programmatically (not just through the database), and you can follow DRY to the extreme. Further, some of this includes (and will include) custom data types (right now, there are only a couple of custom data types based on default data types).
More...
In a nutshell, the goal is to have such highly customizable "scaffolding" that there really is no scaffolding - all the code is synthesized - or generated "on the fly." Of course, this only gets you so far. For the stuff that really makes your application unique, you'll still have to code that. But you can compose views from others and such, so it's not like related tables have to stay unrelated, but I do want to stress that right now there is no relationship stuff implemented in the ORM.
I've skipped a few "mini-versions" from 0.1.3 to 0.2.0 because there were so many changes that I haven't documented one-by-one. That's just sloppiness on my part. Basically, I started by following Ruby on Rails' example, and taking my own experience about what I find myself doing over and over again. That part is done, except that the ORM needs to be able to auto-load and lazy-load relationships at the programmer's whim. In any case, once I got enough functionality to start using it on my project, I've been developing them in parallel. The problem is, I've fallen back on poor practices, so the code isn't as nice as it could be.
In particular, there aren't any new automated tests after the first couple of releases, which isn't as bad as it might otherwise be, since a lot of the core code was tested in them. But on that note, I haven't run the existing tests in a while, so they may be broken.
Further, since I've been thinking in Ruby and coding in Coldfusion, you'll see a mix of camelCase and under_score notations. My original goal was to provide both for all the public methods, and I still plan to do that (because, since I can't rely on case from all databases for the column names -- or so I think -- I use the under_score notation to tell where to put spaces when displaying the column names). But right now, there is a mix. Finally, the DSL needs a lot more thought put behind it - Right now it is a mix-and-match of variables.setting variables and set_something() methods. Right now it is really ugly, but when I take the time to get some updated documentation up and actually package it as a zip, I should have it cleaned up. In fact, I shouldn't have released this yet, but I was just starting to feel I needed to do something, since so much had be done on it and I hadn't put anything out in quite some time. Besides that, I'm quite excited to be using it - it's been a pain to build, but it's already saved me more time than had I not done anything like it.
In the end, I guess what I'm trying to say is: 1) Don't look at it to learn from. There may be
some good points, but there are bad points too, and 2) Don't rely too heavily on the interfaces.
While I don't anticipate changing them (only adding to them, and not forcing you to set
variables.property), this is still less than version 1, so I reserve the right
to change the interfaces until then. =)
Other than that, I would love to hear any feedback if you happen to be using it, or need help because the documentation is out of date, or if you tried to use it but couldn't get it to work. You can contact me here. You can find
cfrails at http://cfrails.riaforge.org/ .
Last modified on Jan 09, 2007 at 04:45 PM UTC - 5 hrs
Posted by Sam on Jan 08, 2007 at 02:10 PM UTC - 5 hrs
InfoQ has an interview with Ryan "zenspider" Davis, a "hardcore Ruby hacker." The interview covers several topics, but those of interest to me and the stuff I've been working on lately with cfrails include DSLs and metaprogramming. It doesn't give too much of an in-depth treatment of these topics, as it's only an interview, but I found it interesting so I thought I'd link it.
Posted by Sam on Dec 18, 2006 at 08:50 AM UTC - 5 hrs
There are plenty of uses for closures, but two of the most useful ones I've found
(in general) are when you really want/need to encapsulate something, and when you want to implement
the Template Method pattern.
Actually, implementing the Template Method pattern using closures may be misusing it, or
I may be mischaracterizing it. It's more of like a "generalized" template
method (particularly since we're not following the pattern, but implementing the intent).
I still don't understand all of the Gang of Four patterns, so have mercy on me if I've
gotten it wrong. =) More on all this below.
So as I get ideas from other languages, I always wonder "how can I use that idea in language X."
For instance, I like the way Coldfusion handles queries as a data structure - so I tried to
implement something similar in Java (which, I will eventually get around to posting).
I encountered closures for the first time in Lisp a few years ago in an Artificial Intelligence
course, I'm sure. But it wasn't until more recently in my experience with
Ruby that I started to understand them. Naturally, I thought "could this be done in Coldfusion?"
More...
Luckily for us,
Sean Corfield made a Closures for CF
package available a couple of months ago (as far as I can tell).
A couple of days ago, I gave it a whirl.
The first thing I have to say is that I had to move the CFCs into the same
directory as my closure_test.cfm file because it wasn't able to find the
temporary templates it was generating. Sean let me know it was because of a pre CF 7.0 bug in
expandPath(), which explains why I had trouble with that function in cfrails. Anyway,
I've posted a "fix" for 6.0/6.1 to the comments on his blog, which basically just
replaces expandPath(".") when it is creating a temp file to
use getDirectoryFromPath(getCurrentTemplatePath()).
After that, it did take a while to understand what was going on, but once I figured it out,
it was pretty cool. So here's my first class of using closures, and what I did in Coldfusion
to implement it: really "encapsulating" something.
Encapsulation is a word you see thrown around quite often. But you don't achieve it by
putting getters and setters everywhere - particularly if you are passing back complex data
structures from a get() method (without first making duplicates, of course).
The idea behind it, as far as I've been able to understand, is to hide implementation
details from code which doesn't need to know it. Not only does this make the client
code need to be less complex, it certainly lowers your coupling as well. However,
if you have a Container (for instance), how can you encapsulate it?
If you return an array representation, you've just let the client code know too much.
If you don't let the client code know too much, how will it ever iterate over the
contents of your Container?
Certainly an Iterator comes to mind. You could provide that if you wanted to,
complete with next(), previous() and anything else you might need.
But you could also use a closure to allow you to encapsulate iteration over the Container,
while still allowing you the freedom to do what you wanted within the loop. Here's my CF code:
<!--- container.cfc --->
<cfcomponent>
<cfscript>
variables._arr = arrayNew(1);
variables._curIndex = 0;
// adds an element to the container
function add(value)
{
_curIndex = _curIndex + 1;
_arr[_curIndex]=value;
}
// iterates over the container, letting a closure
// specify what to do at each iteration
function each(closure)
{
closure.name("run");
for (i=1; i lte _curIndex; i=i+1)
{
closure = closure.bind(value=_arr[i]);
closure.run();
}
}
</cfscript>
</cfcomponent>
And here's the resulting code that uses Container.each(), and passes a closure to it:
<!--- closure_test.cfm --->
<cfscript>
cf = createObject("component","org.corfield.closure.ClosureFactory");
container = createObject("component","container");
container.add(10);
container.add(20);
container.add(30);
beenhere = false;
c = cf.new("<cfset value = value + 3><cfoutput>#value#</cfoutput><cfset beenhere = true>");
container.each(c);
c = cf.new("<br/><cfoutput>This container has the value #value# in it</cfoutput>");
container.each(c);
</cfscript>
<cfoutput>
#beenhere# <!--- outputs false --->
</cfoutput>
Now, from my understanding of closures, you should be able to modify "outer" variables within them. Thus,
to be a "true" closure, outputting beenhere above should show true. This
would be relatively easy to do by sending the appropriate scopes to the closure,
but the only ways I can think of to do that would muck up the syntax. Other than that, it is not code
that makes me comfortable, so to speak. The closure_test needs to know that it is expected
to use value as the name of the variable. There may very well be a simple way around this that
doesn't screw up the syntax, but I have yet to spend enough research in figuring it out. In fact, in
Ruby you'd use |value| do_something_with(value), so it's probably as simple as that, or providing
an extra parameter (as I saw in one of Sean's examples). Perhaps I will
when I run across a need for it (and I'm sure I will be using this in the future).
And now for comparison purposes, I've included the Ruby version that does the same thing:
class Container
def initialize
@arr = []
@curIndex=-1
end
def add(value)
@curIndex = @curIndex+1
@arr[@curIndex] = value
end
def each
cnt = 0
(@curIndex+1).times do
yield @arr[cnt]
cnt += 1
end
end
end
#trial run
container = Container.new
container.add 15
container.add 25
container.add 35
beenhere = false
container.each{|v| v+=1; beenhere=true}
puts beenhere #displays true
This isn't normally how you'd code in Ruby, but I tried to keep the look approximately the same.
In particular, the each() method is already implemented for arrays in Ruby, so there
would certainly be no need to rewrite it.
As you can see, the syntax is a bit cleaner in Ruby than in the CF version. It's so easy to do,
one doesn't need to think about using closures - you just do it when it comes naturally. Even with
all that, I think Sean reached his goal of proving himself wrong (he said
"I was having a discussion about closures with someone recently and
I said they wouldn't make sense for ColdFusion because the syntax would be too ugly.
On Friday evening, I decided to try to prove myself wrong"). I think it might be possible to
improve it a little, but I don't think it would ever become as "pretty" as Ruby's style (unless, of
course, it was built into the language). Because of that, and the effort involved in creating them,
I don't think it will ever become a natural solution we turn to in CF (although, if I started using them
enough, it would eventually become a natural solution). In any case, he certainly did an awesome job,
made the syntax much cleaner than I would have thought possible, and gave us a new tool to solve problems with.
In closing, I'd like to talk a bit about the "other" use for closures I've found, what I called a generalized
Template Method pattern above. Really, this is just a general case of the way encapsulation was furthered
with the each method above. Basically, you are defining the skeleton of an algorithm, and allowing
someone else to define its behavior. I mentioned that it's not really the template method pattern,
since we aren't confining it to subclasses, and we aren't actually following the pattern - we're just implementing
its intent, in a more general way. So basically, you might think of it as a delayed evaluate for letting
some other code customize the behavior of your code that expects a closure. I don't know if I've made
any sense, but I sure hope so (and if not, let me know what I might clarify!).
Finally I'd like to thank Sean for providing this tool to us, and ask everyone, "what uses
have you found for closures, if any?"
Update: Thanks to Brian Rinaldi, Sean Corfield found this post and addressed the problems I encountered. It turns out I was just doing it wrong, so to see it done right, visit his blog. I also responded to a few of the issues raised here.
Last modified on Jan 06, 2007 at 09:33 AM UTC - 5 hrs
Posted by Sam on Dec 12, 2006 at 09:29 AM UTC - 5 hrs
OK, maybe its not the stupidist ever, but its almost on par with that error I get from time to time that tells me I need a primary key passed to cfupdate when I've got a primary key passed in, and to top it off it works sometimes (the cfupdate one). This one has to do with lists.
I love lists and list processing in Coldfusion. I use them for everything. But one thing I can't stand (which is something I feel I ought to be able to do), is when I get an exception because the list is too short (or sometimes too long). In this case, I was trying to delete an element from the list, but the element didn't exist. So, I got an "Invalid list index 0" error.
Maybe I'm too used to Ruby and its ability to index arrays with say, -1 to get the last element. But I don't feel its asking too much to have
<cfset listdeleteat(local.hotellist,listcontainsnocase(local.hotellist,"other"))>
not bomb if listcontainsnocase returns 0.
How do you feel? How often do you use lists? All the time like me?
Last modified on Dec 12, 2006 at 09:32 AM UTC - 5 hrs
Posted by Sam on Nov 19, 2006 at 05:11 PM UTC - 5 hrs
So, I was playing around a little in Ruby and noticed that DateTime is a subclass of Date, yet the method today is
not defined for it. I asked Venkat about it (in an email), he inspected the source code (why didn't I think of that?), and he replied that
the culprit! is line 1261 in date.rb, within DateTime class
class << self; undef_method :today end rescue nil
I thought it was interesting: Certainly this violates LSP, yet certainly a DateTime shouldn't have the method today. So, are there instances where it makes sense to violate LSP, in favor of keeping up with the metaphor?
I wonder why Date isn't a subclass of DateTime, rather than the other way around? At least for this case, it would not have violated LSP. So, I posted about this on the Ruby-Talk mailing list - I'll update you when I hear back from that group.
Update: I just realized if we made Date a child of DateTime, we'd get a similar problem in that we'd be removing the time part from the class. How would you resolve it?
Update 2: After some thought and some help from the Ruby community, I'm not so sure this is a violation of LSP. You see, the method today can only be called on Date, not an object of Date. So therefore, there is no violation when an object of Date is replaced by one of DateTime. Robert Klemme chimed in with this, which of course I addressed above, but he said it much better than I did:
Once can certainly argue whether DateTime *is a* Date or rather *has a* Date. But it is definitively clear that Date *is not* a DateTime simply because it does not provide the same set of information that DateTime provides (date *and* time)
So in the end, it appears as if there is no problem at all. Sorry for being alarmist - I guess I should have tested it first, right? =).
Last modified on Nov 20, 2006 at 07:29 AM UTC - 5 hrs
Posted by Sam on Sep 26, 2006 at 07:40 AM UTC - 5 hrs
Given a class LeapYear with method isleap? and a data file consisting of year, isleap(true/false) pairs, we want to generate individual tests for each line of data. Using Ruby, this is quite simple to do. One way is to read the file, and build a string of the code, then write that to a file and then load it. That would certainly work, but using define_method is a bit more interesting. Here is the code my partner Clay Smith and I came up with:
require 'test/unit'
require 'leapyear'
class LeapYearTest < Test::Unit::TestCase
def setup
@ly = LeapYear.new
end
def LeapYearTest.generate_tests
filename = "testdata.dat"
file = File.new(filename, "r") #reading the file
file.each_line do |line| #iterate over each line of the file
year, is_leap = line.split; #since a space separates the year from if it is a leap year or not, we split the line along a space
code = lambda { assert_equal(is_leap.downcase=="true", @ly.isleap?(year.to_i)) } #create some code
define_method("test_isleap_" + year, code) #define the method, and pass in the code
end
file.close
end
end
LeapYearTest.generate_tests
One thing to note, that I initially had trouble with, was the to_i. At first, it never occurred to me that I should be using it, since with Coldfusion a string which is a number can have operations performed on it as if it were a number. In Ruby, I needed the to_i, as isleap? was always returning false with the String version of year.
A more interesting item to note is that in the line where we define the method, if you were to attach a block like this:
define_method("test_isleap_"+year) { assert_equal(is_leap.downcase=="true", @ly.isleap?(year.to_i)) }
Then the solution will not work. It creates the correct methods, but when it evaluates them, it appears as though it will use the last value of year, rather than the value at the time of creation.
Last modified on Sep 26, 2006 at 07:42 AM UTC - 5 hrs
Posted by Sam on Sep 22, 2006 at 06:47 AM UTC - 5 hrs
I could have sworn I had RadRails and Instant Rails working and was able to develop Ruby on Rails applications several months ago. But, I think I had a funktified setup, as yesterday I couldn't get it to work at all.
So, I went looking for what was wrong, and came across Matt Griffith's screencast about how to get started with Rails (in less than 5 minutes!).
The first thing to do was get InstantRails. I already had it, but I downloaded again just in case I had old versions of everything. Then, I followed his easy directions. I've restated them here, since I'm new to this and easily forget.
- Unzip Instant Rails where you want it to reside. I chose C:\InstantRails
- Start Instant Rails. Click the "OK" button to let it update the configuration file
- If IIS is running (you get port 80 is in use by inetinfo.exe, stop IIS by typing iisreset /stop at the command prompt
- Open a Ruby console window through Instant Rails by clicking The "I" button -> Rails Applications -> Open Ruby Console Window
- You should be in C:\InstantRails\rails_apps. If you are working on a new application, generate it by using the command:
rails <project_name>. Matt called his demo, so the command was "rails demo."
- Move to the project directory, C:\InstantRails\rails_apps\demo
- Generate a controller: ruby script/generate controller <ControllerName>
- Generate a model: ruby script/generate model <ModelName>
- Create a migration by editing the file: C:\InstantRails\rails_apps\demo\db\migrate\001_create_posts.rb (assuming your model was called Post
- In the self.up method in that file, add the columns (one per line). For instance,
t.column :title, :string on the first line, then t.column :body, :text (he is using a blog as an example).
- Open the configuration file for the database. This is found in C:\InstantRails\rails_apps\demo\config\database.yml. Basically, you can find the names of the databases you are going to need to create. We'll be doing demo_development.
- Start Apache to create the database using php administrator interface to MySQL. You can start Apache by clicking on Apache->Start in Instant Rails. Be sure to unblock it if Windows Security asks.
- Click I->Configure->Database (via PhpMyAdmin)
- That will open a browser to the admin page. Just type in the name of the database and submit the form. Ours is called demo_development.
- Stop Apache (in Instant Rails click Apache->Stop)
- Start WEBrick: In C:\InstantRails\rails_apps\demo, type the command: ruby script/server. If Windows asks, unblock it. Take note of the port it will be using.
- Set up the controller to have something. Open C:\InstantRails\rails_apps\demo\app\controllers\blog_controller.rb. In the class, type
scaffold :post
- To create the database, run the migration. In C:\InstantRails\rails_apps\demo type the command: rake db:migrate
- Now you can go to http://localhost:3000 (or whatever port it is using). Here you'll see the "Welcome Aboard" page from Rails.
- To see your application, go to http://localhost:3000/blog. Play around, have fun.
If you are working on an existing application, obviously you can skip several of those steps (like, every one that involves creating a new application).
Now, I'll see about getting RadRails working in the next few days.
Last modified on Sep 26, 2006 at 08:15 AM UTC - 5 hrs
Posted by Sam on Sep 08, 2006 at 08:16 AM UTC - 5 hrs
Since school has been back in, I've been much busier than (seemingly) ever. I haven't had the opportunity to do some of the things I've wanted (such as writing more in TDDing xorBlog), but I wanted to share my Wizard, which you can teach to learn spells. I should also note that this is the product of work with my partner, Clayton Smith.
We were given the assignment as a few unit tests:
require 'wizard'
require 'test/unit'
class WizardTest < Test::Unit::TestCase
def setup
@wiz = Wizard.new
end
def test_teach_one_spell
got_here = false
@wiz.learn('telepathy') { puts "I see what you're thinking"; got_here = true}
@wiz.telepathy
assert(got_here)
end
def test_teach_another_spell
got_here = false
spell_code = lambda { puts "no more clouds"; got_here = true}
@wiz.learn('stop_rain', &spell_code)
@wiz.stop_rain
assert(got_here)
end
def test_teach_a_couple_of_spells
got_here1 = false
got_here2 = false
@wiz.learn('get_what_you_want') { |want| puts want; got_here1 = true }
@wiz.learn('sleep') { puts 'zzzzzzzzzzzz'; got_here2 = true}
@wiz.get_what_you_want("I'll get an 'A'")
@wiz.sleep
assert(got_here1 && got_here2)
end
def test_unknown_spell
@wiz.learn('rain') { puts '...thundering...' }
assert_raise(RuntimeError, "Unknown Spell") {@wiz.raln }
end
end
We simply had to make the tests pass:
class Wizard
def initialize()
@spells=Hash.new
end
def learn(spell, &code)
@spells[spell]=code
end
def method_missing(method_id, *args)
begin
@spells["#{method_id}"].call(args)
rescue
raise("Unknown Spell")
end
end
end
Basically, all that happens is that when you create a Wizard, the initialize() method is called, and it creates a Hash to store spells in. Then you have a method, learn(), which takes as a parameter a block of code and stores that code in the Hash. Then when someone calls a method that doesn't exist for an object, Ruby automatically calls the method_missing() method. In this method, all I do is try to call the code stored in the hash under the name of the method they tried to call. If that doesn't work, I raise an exception with the message "Unknown Spell." Quite simple to do something so complex. I can't even imagine how I'd do something like that in a more "traditional" language (though, I can't say that I've tried either).
Can you imagine how cool it would be to say, have one programmer who wrote this Wizard into a game, and other programmers who just litter places in the game (in SpellBooks, consisting of Spells of course) with code that names the spell and specifies what it does? Without even needing to know anything about each other! Instantly extending what a Wizard can do, without even having to so much as think about changing Wizard - it's a beautiful world, indeed.
Last modified on Sep 26, 2006 at 08:19 AM UTC - 5 hrs
Posted by Sam on Aug 31, 2006 at 10:45 AM UTC - 5 hrs
Oh my! I almost forgot the most important part in 'Beginning Ruby' - how to test your code!
require 'test/unit'
class MyTest < Test::Unit::TestCase
def test_hookup
assert(2==2)
end
end
Running that in SciTE gives the following output:
Loaded suite rubyunittest
Started
.
Finished in 0.0 seconds.
1 tests, 1 assertions, 0 failures, 0 errors
On the other hand, if you change one of those twos in the assert() to a three, it shows this:
Loaded suite rubyunittest
Started
F
Finished in 0.079 seconds.
1) Failure:
test_hookup(MyTest) [rubyunittest.rb:4]:
<false> is not true.
1 tests, 1 assertions, 1 failures, 0 errors
The Ruby plugin for Eclipse gives a nice little GUI, however, where you can see the green bar (assuming
your code passes all the tests). I also have a classmate who is writing a Ruby unit testing framework based on NUnit for his thesis, so it is supposed to be the bollocks. I'll let you all know more when I know more.
Last modified on Aug 31, 2006 at 10:50 AM UTC - 5 hrs
Posted by Sam on Aug 31, 2006 at 10:20 AM UTC - 5 hrs
In case you haven't bought the 2nd Edition Pickaxe or found the 1st Edition of Programming Ruby: The Pragmatic Programmer's Guide, I'll be covering some of the basics of Ruby here. I've got both, but I haven't looked at the first edition in a couple of months, and haven't yet found the time to open the second edition and give it the attention it deserves.
But, I have been in class, so I thought I might go over some of the simple things in Ruby, with no real method to my madness. I'll just
be going through different things as I remember them. Enjoy the lack of structure. You could actually copy and paste that into an IDE or .rb file and run it as-is if you wanted.
# the hash/pound/number symbol gives us a comment
# set a variable
val = 10;
#semicolons are optional per line. if you want more than one statement
#per line, you'll have to use it
something = 1; something_else = 2
puts something, something_else
puts '--------------------------'
# while loop putting 9 down to 0
while val > 0
#'puts' puts a string to the console
puts val = val-1
end
puts '--------------------------'
# or you can do
val = 10
puts val = val -1 while val > 0
puts '--------------------------'
val = 10
puts val = val -1 until val < 1
puts '--------------------------'
for i in 1..10 # .. shows us the range object
puts i
end
puts '--------------------------'
9.upto(10) { |v| puts v }
puts '--------------------------'
9.downto(1) { |v| puts v }
puts '--------------------------'
condition = true
if condition
puts "yes"
puts "yoho"
else
puts "no"
end
puts '--------------------------'
puts "yes" if condition
puts "no" unless condition
puts '--------------------------'
class Car #define a class called Car. Must begin with an uppercase letter
attr_reader :miles, :fuel_level #like getMiles but auto-done for you
attr_writer :fuel_level #like setFuelLevel, but can use on LHS of equation
# you could also use:
# def fuel_level=(lvl)
# @fuel_level = lvl
# end
def initialize (year)# is called when an object is created
@year = year # @varname lets us know that it is a member variable
@miles = 0
@fuel_level = 100
end
def drive #define a method called drive
puts "we are driving the car for one mile"
@miles += 1
@fuel_level -= 1
end
end
c1=Car.new(2006)
c1.drive
puts c1.fuel_level
# attr_writer example
puts c1.fuel_level=29
# the last statement is the one returned from a method
puts c1.drive
#attr_reader example
puts c1.miles.to_s + " miles driven" #to_s = toString
# one of my only beefs so far is that you cant simply do
# puts 1 + "sam"
puts '--------------------------'
# inheritance is done via the less than symbol <
class SoupedUpCar < Car
def drive # will drive 3 times as fast with only 2 times the gas consumption
@miles+=2
@fuel_level -= 1
super
end
end
c2 = SoupedUpCar.new(2007)
puts c2.inspect #gives us info on the object (puts is there for output only)
puts c2.class #tells us the class of the object
#add a method to SoupedUpCar
class SoupedUpCar
def burnout
puts "smell the rubber?"
end
end
#notice c2 has not been reinstantiated or anything
c2.burnout
Thats all for now. I'm starting to think I should have organized the code a little better. Maybe next time. I certainly need a colorizer for it.
Last modified on Aug 31, 2006 at 10:51 AM UTC - 5 hrs
Posted by Sam on Aug 25, 2006 at 04:02 PM UTC - 5 hrs
In class on Wednesday Venkat explained so well,
yet so succinctly, what I'm loving so much about Ruby: the signal to noise ratio is higher
in Ruby than in most languages.
One of his examples was to take a program that does absolutely nothing in Java:
public class DoNothing
{
public static void main(String[] args)
{
}
}
And compare it to this one in Ruby:
Notice the difference?
Incidentally, the high signal to noise ratio is also what I like so much about Coldfusion. To run a query, you just
do it. You don't have to go through the hassle of creating connections, statements, and the like. Just type
in your query and go. Of course the drawback in Coldfusion is that in many cases, there is a lot of noise.
For example, to create an object I have to write <cfset someObj = createObject("component", "long.Path.To.CFC")>,
and let's not mention the tag syntax (at least I can use <cfscript>, though I rarely do).
In any case, I find Java's database access so hard to work with, the last time I used it in any significant context I
created a façade to do all the work for me. I'd just create an object of it, and pass in a query to run.
But, there's also a problem with building the queries in languages like Java and C#:
String theQueryString="select columnName from table" +
" where someColumn = " + someValue +
" and anotherColumn = " + anotherValue + " ... " +
" order by " + orderBy;
Horrible! For long queries, that can get extremely unreadable. In Coldfusion if you need to create
a multi-line string to keep it readable, you can simply do the following:
<cfsavecontent variable="theQueryString">
put any text you want in here
and as many lines as you
want
</cfsavecontent>
And I was happy to find out you can do something similar in Ruby:
someVariable = <<DELIMITER_FOR_WHEN_YOUR_STRING_IS_DONE
put any text you want in here
and as many lines as you
want
DELIMITER_FOR_WHEN_YOUR_STRING_IS_DONE
The next great surprise from Ruby? You can add methods to a class at run-time (there is no compilation)
quite easily. Suppose I wanted the absolute value method to work on a string. I could just do:
class String
def abs
"absolute value of string"
end
end
And no, it didn't overwrite the String class. So far, I am amazed. I know you can
do the same thing in Coldfusion, but that doesn't make it any less awesome.
Last modified on Aug 25, 2006 at 04:11 PM UTC - 5 hrs
|
Me

|